RDD编程
一、词频统计
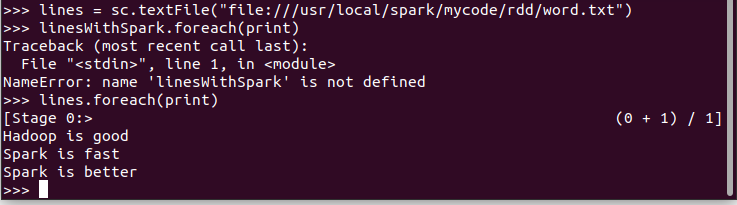
1.读文本文件生成RDD lines
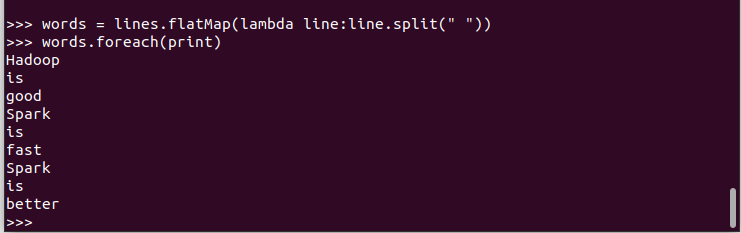
2.将一行一行的文本分割成单词 words flatmap()
3.全部转换为小写 lower()
4.去掉长度小于3的单词 filter()
5.去掉停用词
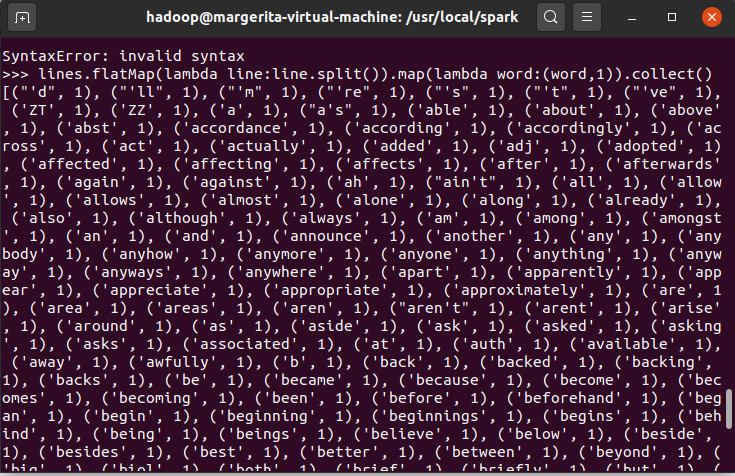
6.转换成键值对 map()
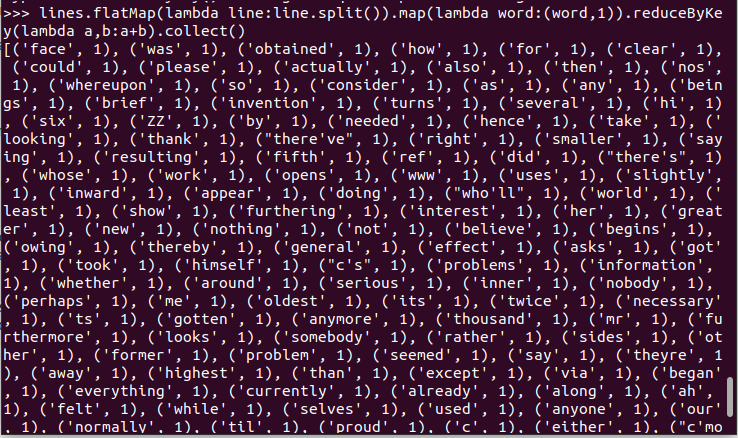
7.统计词频 reduceByKey()
8.按字母顺序排序 sortBy(f)
9.按词频排序 sortByKey()





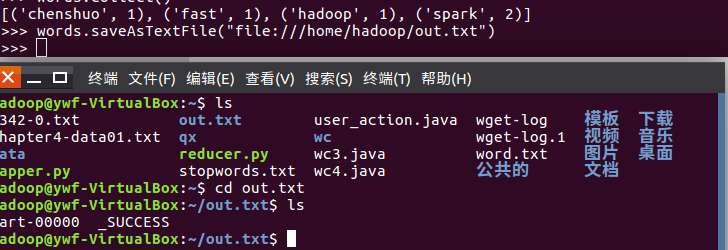
10.结果文件保存 saveAsTextFile(out_url)
words.saveAsTextFile("file:///home/hadoop/out.txt")
11.词频结果可视化charts.WordCloud()

#11.词频结果可视化charts.WordCloud()
from pyecharts.charts import WordCloud
url='D:/1342-0.txt'
with open(r'D:/stopwords.txt') as f:
stops=f.read().split()
wc=sc.textFile(url).flatMap(lambda line:line.lower().replace(',','').split()).filter(lambda word:word not in stops).filter(lambda word:len(word)>2).map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],False).take(100) mywordcloud=WordCloud()
mywordcloud.add("",wc,shape='circle')
mywordcloud.render()

二、学生课程分数案例
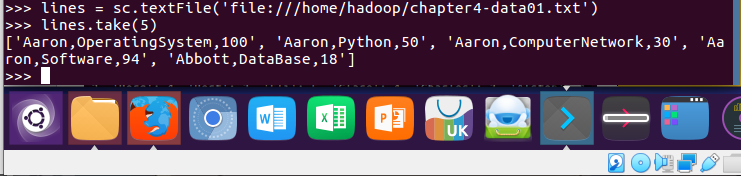
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
lines.take(5)
1.总共有多少学生?map(), distinct(), count()
lines.map(lambda line : line.split(',')[0]).distinct().count()

2.开设了多少门课程?
lines.map(lambda line : line.split(',')[1]).distinct().count()

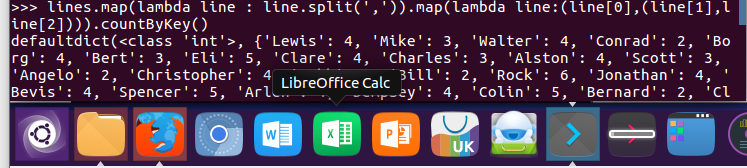
3.每个学生选修了多少门课?map(), countByKey()
lines.map(lambda line : line.split(',')).map(lambda line:(line[0],(line[1],line[2]))).countByKey()
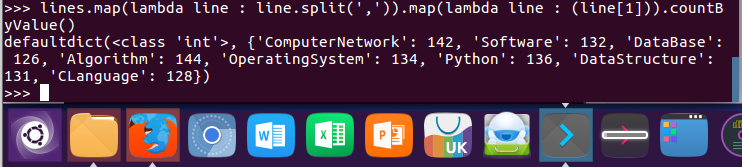
4.每门课程有多少个学生选?map(), countByValue()
lines.map(lambda line : line.split(',')).map(lambda line : (line[1])).countByValue()
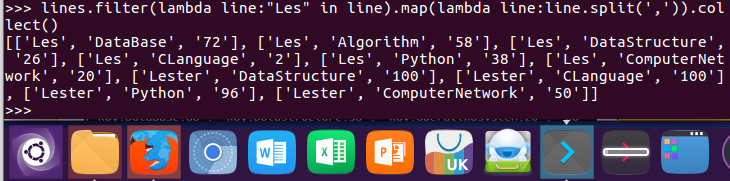
5.Les选修了几门课?每门课多少分?filter(), map() RDD
lines.filter(lambda line:"Les" in line).map(lambda line:line.split(',')).collect()
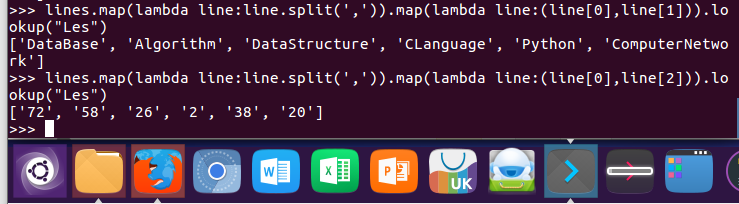
6.Les选修了几门课?每门课多少分?map(),lookup() list
lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[1])).lookup("Les")
lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup("Les")
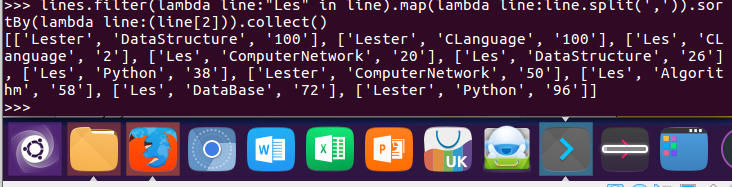
7.Les的成绩按分数大小排序。filter(), map(), sortBy()
lines.filter(lambda line:"Les" in line).map(lambda line:line.split(',')).sortBy(lambda line:(line[2])).collect()
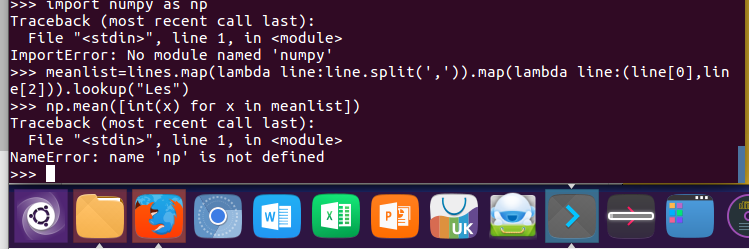
8.Les的平均分。map(),lookup(),mean()
import numpy as np
meanlist=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup("Les")
np.mean([int(x) for x in meanlist])
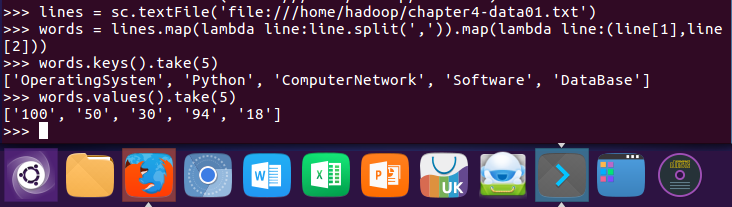
9.生成(课程,分数)RDD,观察keys(),values()
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
words = lines.map(lambda line:line.split(',')).map(lambda line:(line[1],line[2]))
words.keys().take(5)
words.values().take(5)
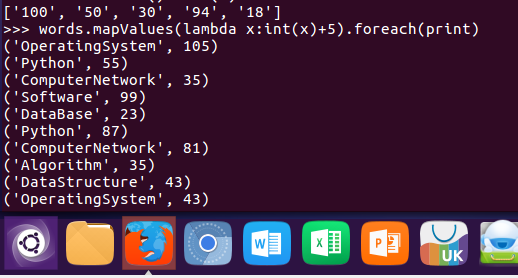
10.每个分数+5分。mapValues(func)
words.mapValues(lambda x:int(x)+5).foreach(print)
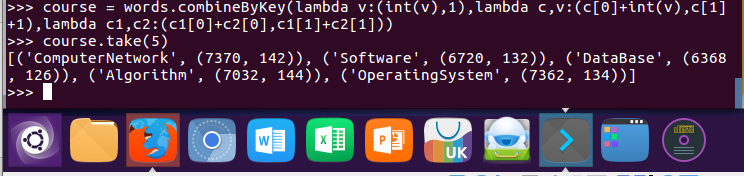
11.求每门课的选修人数及所有人的总分。combineByKey()
course = words.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1]))
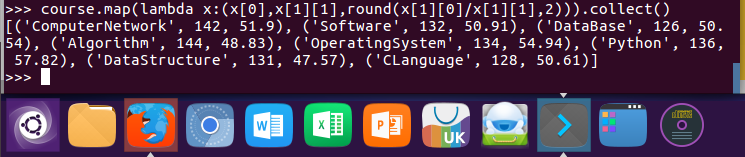
12.求每门课的选修人数及平均分,精确到2位小数。map(),round()
course.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1],2))).collect()
13.求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1])).foreach(print)

14.结果可视化。charts,Bar()
from pyecharts.charts import Bar
from pyecharts import options as opts bar = Bar()
bar.add_xaxis(cs.keys().collect())
bar.add_yaxis('avg',cs.map(lambda x:x[2]).collect())
#bar.set_global_opts(title_opts=opts.TitleOpts(title="各课程",subtitle="平均分"),xaxis_opts=opts.AxisOpts(axislabel_opt=opts.LabelOpts(rotate=30)))
bar.set_global_opts() bar.render_notebook()
X轴设置斜体的方法忘记了不会写

RDD编程的更多相关文章
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
随机推荐
- 【闲话】Vscode+PlatformIO+esp-idf+esp32物联网开发小记之环境搭建
Vscode作为一款优秀的代码编辑器,具有极为方便快捷的代码辅助与拓展功能,使用熟练后开发效率大大提高,且作为典型的IDE,不需要花费大量的时间成本即可上手,Vscode结合各种插件,可以搭建出大部分 ...
- 17.SQLite数据库存储
Android系统内置一个SQLite数据库,SQLite是一款轻量级的关系型数据库,它的运算速度非常快,占用资源很少,通常只需要几百K的内存就足够了. SQLite不仅支持标准的SQL语法,还遵循了 ...
- beego入门
beego的官方仓库地址是 https://github.com/beego/beego 为什么要特别说明这个事情呢?因为我们引入的包地址,有可能是从官方fork的,特别是beego,有的教程上通过g ...
- Springboot 和hutool文件上传下载
1.放开上传限制 servlet: multipart: enabled: true #默认支持文件上传 max-file-size: -1 #不做限制 max-request-size: -1 #不 ...
- 剑指 Offer II 回溯法
086. 分割回文子字符串 用substr枚举 因为是连续的 不是放与不放的问题 class Solution { public: vector<vector<string>> ...
- Ubuntu20.04安装PEA软件
PEA软件可用于实时精密卫星钟差估计,精密卫星定轨,精密单点定位,电离层建模以及DCB估计等. Ginan开发人员推荐使用Ubuntu18.04或Ubuntu20.04搭建,本文使用Ubuntu20. ...
- 如何用python脚本采集某网图片
一.前言: 今天学了两个工具urlopen 和etree,这两个小工具至关重要.urllib.request模块提供了最基本的构造HTTP请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还 ...
- html的table多级表头表格的代码
1,两级表头的代码 <html> <head> <title>多层表头</title> <link rel="stylesheet&qu ...
- 央行DR007在哪里查看
1.中国外汇交易中心,点击官网进入 https://www.chinamoney.com.cn/chinese/ 2.点击数据选项,接着选择货币市场行情 3.点击质押式回购
- Oracle 存储过程5:PL/SQL异常处理
PL/SQL异常处理是PL/SQL块中对执行部分出现异常进行处理的部分.PL/SQL采用的是统一异常处理机制,当异常发生时,程序会自动跳转到异常处理部分,交给异常处理程序进行异常匹配,再调用对应的处理 ...