【学习笔记】 Adaboost算法
前言
之前的学习中也有好几次尝试过学习该算法,但是都无功而返,不仅仅是因为该算法各大博主、大牛的描述都比较晦涩难懂,同时我自己学习过程中也心浮气躁,不能专心。
现如今决定一口气肝到底,这样我明天就可以正式开始攻克阿里云天池大赛赛题,所以今天一天必须把Adaboost算法拿下!!!
Adaboost
boosting与bagging
- boosting
个体学习器间存在强依赖关系、必须串行生成的序列化方法,提高那些在前一轮被弱分类器分错的样本的权值,减小那些在前一轮被弱分类器分对的样本的权值,
使误分的样本在后续受到更多的关注。
体现了串行
加法模型将弱分类器进行线性组合
代表模型:Adaboost,GBDT,XGBoost,LightGBM - bagging
个体学习器不存在强依赖系,可同时生成的并行化方法
Adaboost算法
关于adaboost,我找到了一段非常易懂的描述,具体说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
所谓的弱学习器,其实就是之前学的一些模型,比如逻辑斯蒂回归模型,决策树模型,都可以称之为弱学习器。而强学习器,就是以后会接触到的一些神经网络模型,而集成学习的思想,就使用多个弱学习器组合来达成强学习器的思想
算法流程
首先确定一个二分类的训练数据集,然后定义基分类器(弱分类器),例如回归就用cart里的回归树,分类就用cart里的分类树等等,然后开始循环
- 第一步,分为初始化和更新两种可能
1.初始化当前训练数据的权值分布
2.更新,首先是当前分类器所算出的每个样本的权值赋给Dm
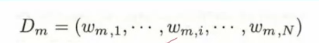
而这里的w(m,i)实际是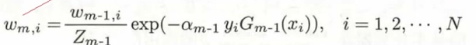
逐步解释一下,首先是分母部分的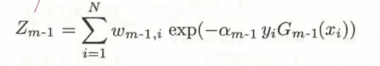 ,看上去复杂的不得了,实际上是一个归一化操作,为的是让整个分布变成一个概率分布
,看上去复杂的不得了,实际上是一个归一化操作,为的是让整个分布变成一个概率分布
而对于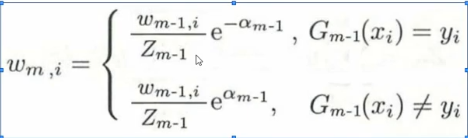 ,这个式子他简单来说就是一个具有我们所需要的功能的函数,因为我们要的功能很复杂,所以函数设计的很吓人,但是其实我只需要记住她,然后知道他具有能够在分类正确时降低函数值,分类错误时提高函数值,从而达到更新权重的目的
,这个式子他简单来说就是一个具有我们所需要的功能的函数,因为我们要的功能很复杂,所以函数设计的很吓人,但是其实我只需要记住她,然后知道他具有能够在分类正确时降低函数值,分类错误时提高函数值,从而达到更新权重的目的 - 第二步,训练当前基分类器
- 第三步,确定权值
1.权值的计算公式简单来说就是如果分类正确就不计入统计,分类错误的话其权值就会被累加计算,而最后算出来的结果记为em,有0≤em≤0.5
2.根据em,计算基分类器的权重系数,给出的公式可以保证当em越小,基分类器的权值越大
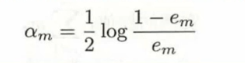
- 第四步,把权值和训练好的分类器放入加法模型
- 第五步,判断是否满足循环条件
1.分类器个数是否达到M
2.总分类器误差率是否满足要求
AdaBoost分类问题的损失函数优化
正如刘老师博客中所说:刚才上一节我们讲到了分类Adaboost的弱学习器权重系数公式和样本权重更新公式。但是没有解释选择这个公式的原因,让人觉得是魔法公式一样。其实它可以从Adaboost的损失函数推导出来。
通过视频 https://www.bilibili.com/video/BV1x44y1r7Zc?p=6 的讲解,自己推了三遍,终于成功!附上稿纸

Adaboost小结
Adaboost的主要优点有:
- Adaboost作为分类器时,分类精度很高
- 在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
- 作为简单的二元分类器时,构造简单,结果可理解。
- 不容易发生过拟合
Adaboost的主要缺点有:
- 对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
小结
下一篇我会具体的学习GBDT和XgBoost
【学习笔记】 Adaboost算法的更多相关文章
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 学习笔记 - Manacher算法
Manacher算法 - 学习笔记 是从最近Codeforces的一场比赛了解到这个算法的~ 非常新奇,毕竟是第一次听说 \(O(n)\) 的回文串算法 我在 vjudge 上开了一个[练习],有兴趣 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 学习笔记-KMP算法
按照学习计划和TimeMachine学长的推荐,学习了一下KMP算法. 昨晚晚自习下课前粗略的看了看,发现根本理解不了高端的next数组啊有木有,不过好在在今天系统的学习了之后感觉是有很大提升的了,起 ...
- Java学习笔记——排序算法之快速排序
会当凌绝顶,一览众山小. --望岳 如果说有哪个排序算法不能不会,那就是快速排序(Quick Sort)了 快速排序简单而高效,是最适合学习的进阶排序算法. 直接上代码: public class Q ...
- Java学习笔记——排序算法之进阶排序(堆排序与分治并归排序)
春蚕到死丝方尽,蜡炬成灰泪始干 --无题 这里介绍两个比较难的算法: 1.堆排序 2.分治并归排序 先说堆. 这里请大家先自行了解完全二叉树的数据结构. 堆是完全二叉树.大顶堆是在堆中,任意双亲值都大 ...
随机推荐
- AI 企业多云存储架构实践 | 深势科技分享
2020 年末,谷歌旗下 DeepMind 研发的 AI 程序 AlphaFold2 在国际蛋白质结构预测竞赛上取得惊人的准确度,使得" AI 预测蛋白质结构"这一领域受到了空前的 ...
- 线程池的概念&原理和线程池的代码实现
线程池:一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作, 无需反复创建线程而消耗过多资源.工作原理:可以用一张图来简洁明了说明: 合理利用线程池能够带来三个好处∶1.降低 ...
- 面试突击65:为什么要用HTTPS?它有什么优点?
说到 HTTPS 相信大部分人都是不陌生,因为目前我们使用的绝大数网站都是基于 HTTPS 的,比如以下这些: 那么问题来了,他们为什么要使用 HTTPS 呢?HTTPS 有哪些过人之处呢? 1.HT ...
- GET 请求和 POST 请求的区别和使用
作为前端开发, HTTP 中的 POST 请求和 GET 请求是经常会用到的东西,有的人可能知道,但对其原理和如何使用并不特别清楚,那么今天来浅谈一下两者的区别与如何使用. GET请求和POST请求的 ...
- 06 app分享功能
通过某一个点击事件触发confirm弹窗 确定后正式进行分享功能处理 这是一个封装好的分享功能插件 https://ext.dcloud.net.cn/plugin?id=4860 如果自己写的话会很 ...
- Jmeter-记一次自动化造数引发的BeanShell写入excel实例
一.前言 最近工作和生活说忙也忙,说不忙也不忙,但就是已经感觉很长时间没有get新的技术技能了,就是一丢丢的那种也没有,哈哈哈,今天就来讲一下最近get到的小技能吧. 工作中,由于某个需求需要几百条数 ...
- CSDN垃圾的没有底线!
平时写代码,经常需要百度. 今天我输入搜索关键词"access sql字符串转日期"进行百度搜索: 然后点开第一条: 这个加粗的标题可以点的,再点开: 这个内容跟我的搜索关键词有什 ...
- 使用Three.js实现炫酷的赛博朋克风格3D数字地球大屏 🌐
声明:本文涉及图文和模型素材仅用于个人学习.研究和欣赏,请勿二次修改.非法传播.转载.出版.商用.及进行其他获利行为. 背景 近期工作有涉及到数字大屏的需求,于是利用业余时间,结合 Three.js ...
- PostgreSQL 备份
# WAL日志: # 我们对数据库的增删改查创建之前先是将sql语句记录在WAL日志中, # 只有日志记录刷新到磁盘后,才能写入数据库文件. # 遵从这个过程,不需要在每个事务提交时都刷新数据页到数据 ...
- Nginx Lua拓展模块操作Redis、Mysql
# Nginx的拓展模块 # ngx_lua模块 # 淘宝开发的ngx_lua模块通过lua解释器集成近Nginx,可以采用lua脚本实现业务逻辑,由于lua的紧凑.快速以及内建协程,所以在保证宝兵法 ...