火山引擎 A/B 测试产品——DataTester 私有化架构分享
作为一款面向 ToB 市场的产品——火山引擎A/B测试(DataTester)为了满足客户对数据安全、合规问题等需求,探索私有化部署是产品无法绕开的一条路。
在面向 ToB 客户私有化的实际落地中,火山引擎A/B测试(DataTester)也遇到了字节内部服务和企业 SaaS 服务都不容易遇到的问题。在解决这些问题的落地实践中,火山引擎 A/B 测试团队沉淀了一些流程管理、性能优化等方面的经验。
本文主要分享火山引擎A/B测试当前的私有化架构,遇到的主要问题以及从业务角度出发的解决思路。
火山引擎 A/B 测试私有化架构
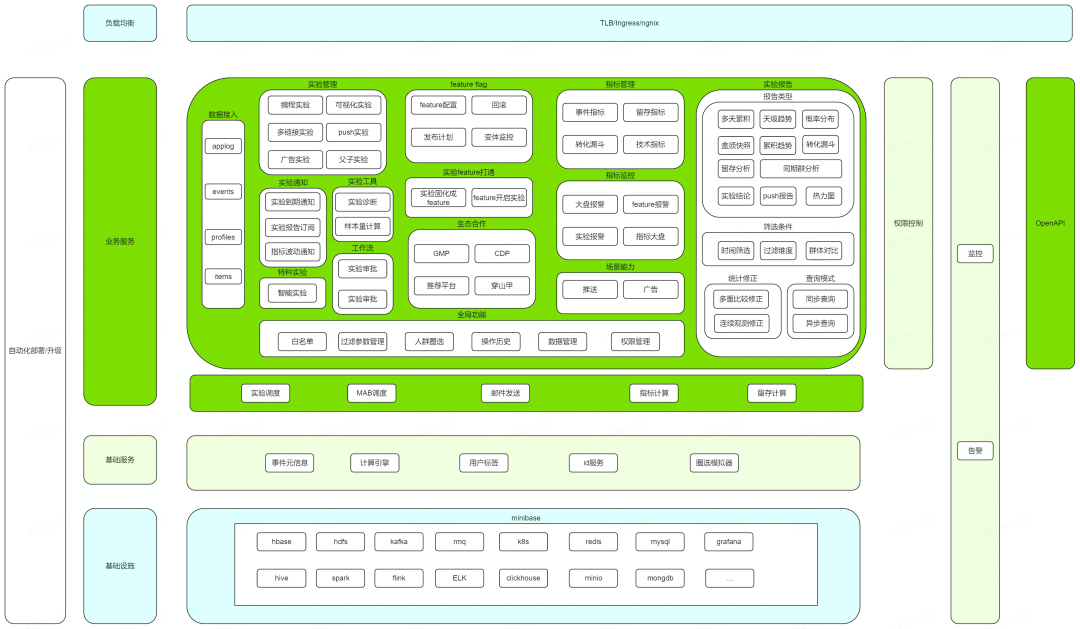
架构图整套系统采用 Ansible+Bash 的方式构建,为了适应私有化小集群部署,既允许各实例对等部署,复用资源,实现最小三节点交付的目标,,又可以做在线、离线资源隔离提高集群稳定性。集群内可以划分为三部分:
业务服务: 主要是直接向用户提供界面或者功能服务的, 例如实验管理、实验报告、OpenAPI、数据接入等。
基础服务: 不直接面向用户,为上层服务的运行提供支撑,例如支持实验报告的计算引擎、为指标创建提供元信息的元信息服务;基础服务同时还会充当一层对基础设施的适配,用来屏蔽基础设施在 SaaS 和私有化上的差异, 例如 SaaS 采用的实时+离线的 Lambda 架构, 私有化为了减少资源开销,适应中小集群部署只保留实时部分, 计算引擎服务向上层屏蔽了这一差异。
基础设施: 内部团队提供统一私有化基础设施底座 minibase,采用宿主机和 k8s 结合的部署方式,由 minibase 适配底层操作系统和硬件, 上层业务直接对接 minibase。
私有化带来的挑战
挑战 1:版本管理
传统 SaaS 服务只需要部署维护一套产品供全部客户使用,因此产品只需要针对单个或几个服务更新,快速上线一个版本特性,而不需要考虑从零开始搭建一套产品。SaaS 服务的版本发布周期往往以周为单位,保持每周 1-2 个版本更新频率。但是,在私有化交付中,我们需要确定一个基线版本并且绑定每个服务的小版本号以确保相同版本下每套环境中的交付物等价,以减轻后续升级运维成本。通常,基线版本的发布周期往往以双月为单位。
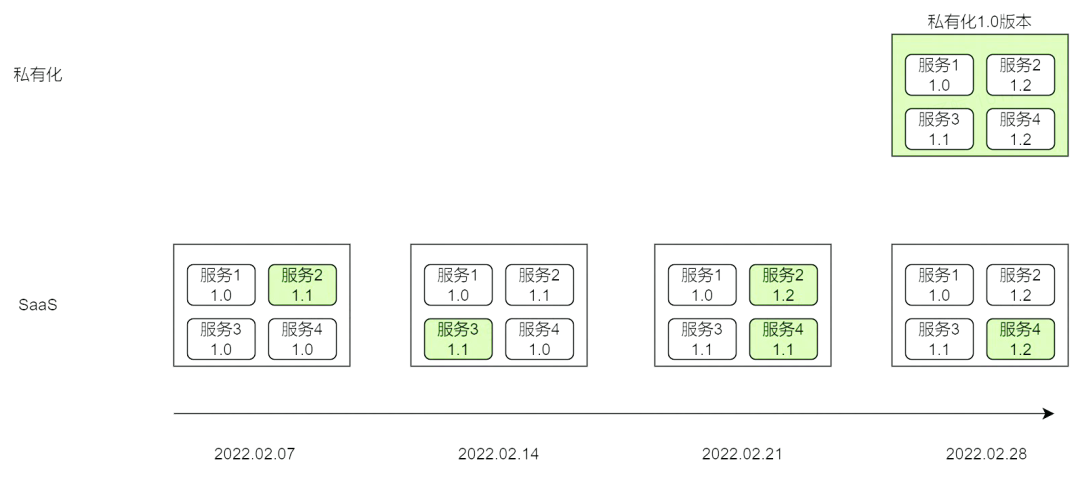
版本发布周期
由于私有化和 SaaS 服务在架构、实现、基础底座上均存在不同,上述的发布节奏会带来一个明显的问题:
团队要投入大量的开发和测试人力集中在发版周期内做历史 Feature 的私有化适配、私有化特性的开发、版本发布的集成测试,挤占其他需求的人力排期。
为了将周期内集中完成的工作分散到 Feature 开发阶段,重新规范了分支使用逻辑、完善私有化流水线和上线流程,让研发和测试的介入时间前移。
解法:
1、分支逻辑
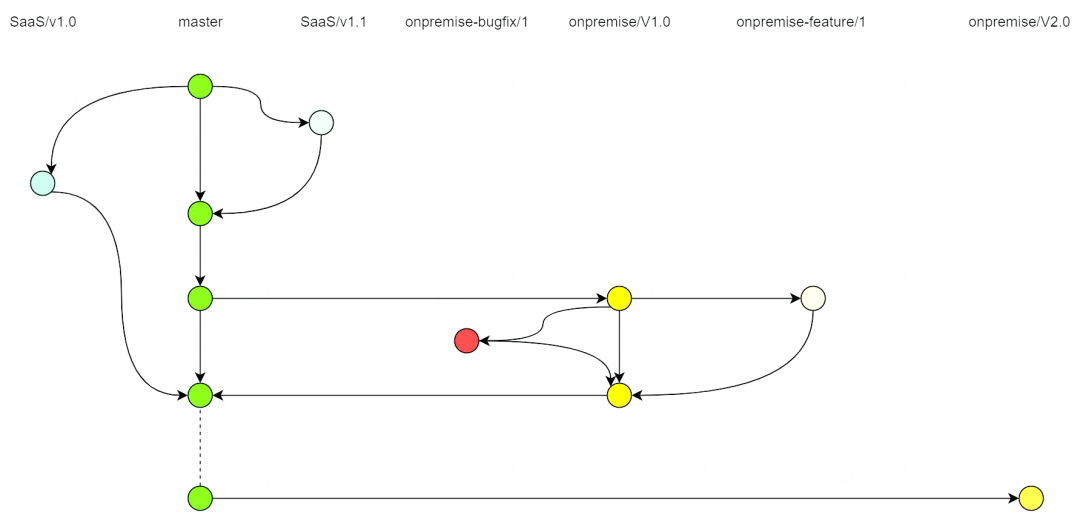
分支管理
SaaS 和私有化均基于 master 分支发布,非私有化版本周期内不特别区分 SaaS 和私有化。
私有化发布周期内单独创建对应版本的私有化分支,发布完成后向 master 分支合并。这样保证了 master 分支在任何情况下都应当能同时在 SaaS 环境和私有化环境中正常工作。
2、发布流水线
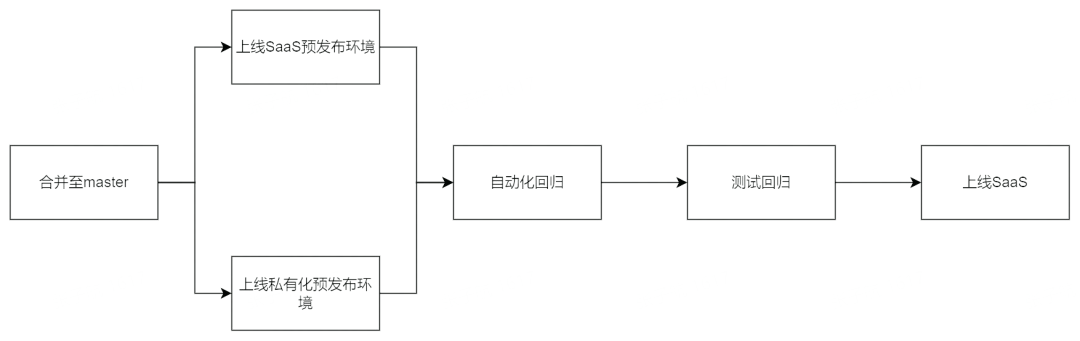
功能上线流程

发布流水线
内部搭建一套私有化预发布环境,建设了一套流水线,对 master 分支的 mr 会触发流水线同时在 SaaS 预发布环境和私有化预发布环境更新最新 master 分支代码,并执行自动化回归和人工回归测试。这样做的好处在于:
推动了具体 Feature 的研发从技术方案设计层面考虑不同环境的 Diff 问题,减少了后期返工的成本
测试同学的工作化整为零,避免短时间内的密集测试
减少研发和测试同学的上下文切换成本,SaaS 和私有化都在 Feature 开发周期内完成
挑战 2:性能优化
火山引擎 A/B 测试工具的报告计算是基于 ClickHouse 实现的实时分析。SaaS 采用多租户共用多个大集群的架构,资源弹性大,可以合理地复用不同租户之间的计算资源。
私有化则大部分为小规模、独立集群,不同客户同时运行的实验个数从几个到几百个不等,报告观测时间和用户习惯、公司作息相关,有明显的峰谷现象。因此实验报告产出延迟、实时分析慢等现象在私有化上更加容易暴露。
解法:
1、 实验报告体系
首先,介绍下火山引擎 A/B 测试产品的实验报告体系。以下图的实验报告为例:
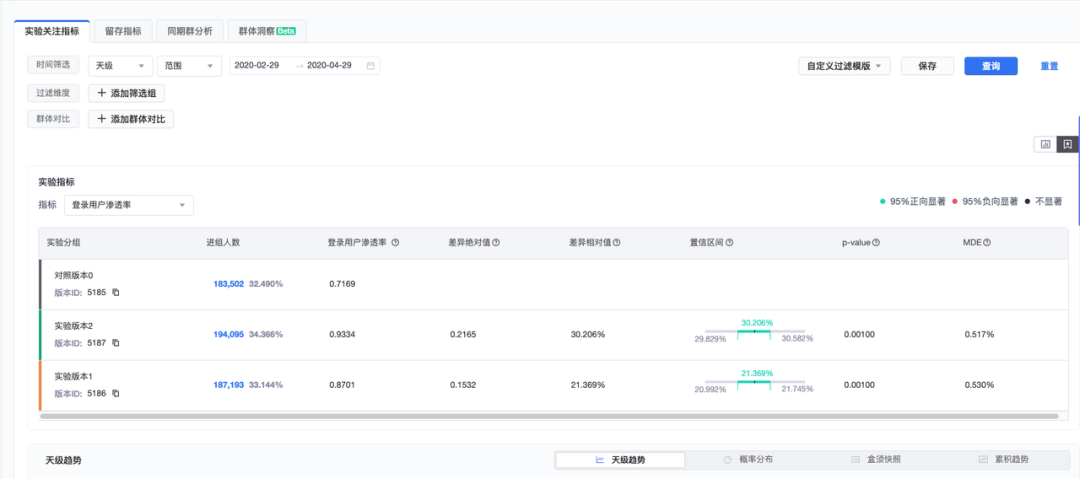
从上往下看产出一个实验报告必要的输入包含:
分析的日期区间及过滤条件
选择合适的指标来评估实验带来的收益
实验版本和对照版本
报告类型, 例如:做多天累计分析、单天的趋势分析等
指标如何定义呢?
组成指标的核心要素包括:
由用户行为产生的事件及属性
预置的算子
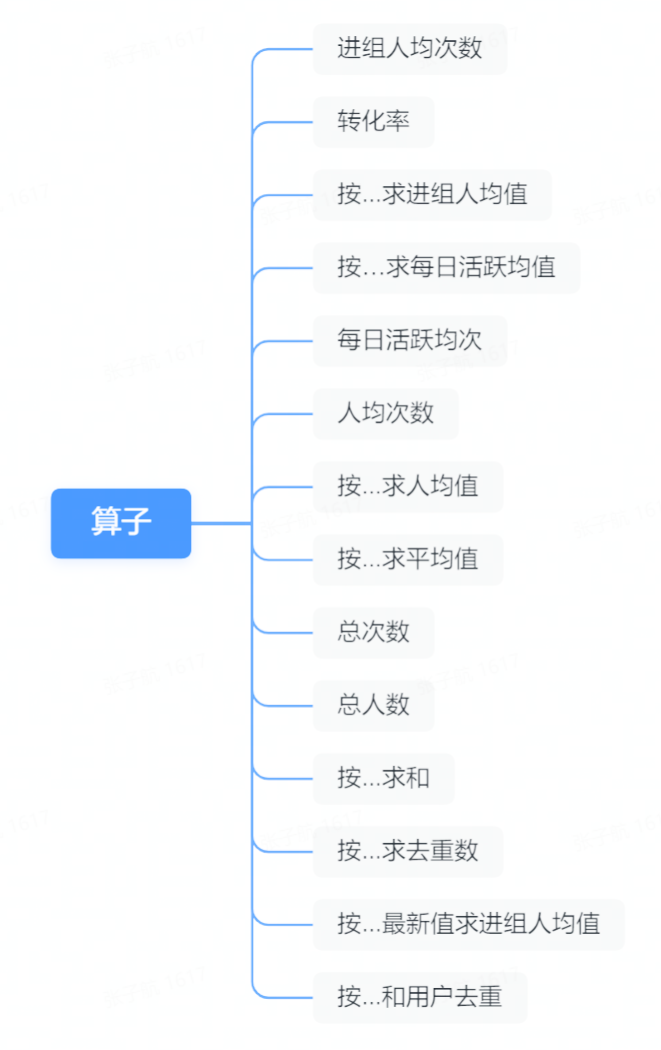
四则运算符
即对于一个用户的某几个行为按照算子的规则计算 value 并使用四则运算组合成一个指标。
由此,我们可以大概想象出一个常规的 A/B 实验报告查询是通过实验命中情况圈出实验组或对照组的人群,分析这类群体中在实验周期内的指标值。
由于 A/B 特有的置信水平计算需求,统计结果中需要体现方差等其他特殊统计值,所有聚合类计算如:求和、PV 数均需要聚合到人粒度计算。
2、 模型优化
如何区分用户命中哪一组呢?
集成 SDK 调用 A/B 分流方法的同时会上报一条实验曝光事件记录用户的进组信息,后续指标计算认为发生在进组之后的事件受到了实验版本的影响。举个例子:
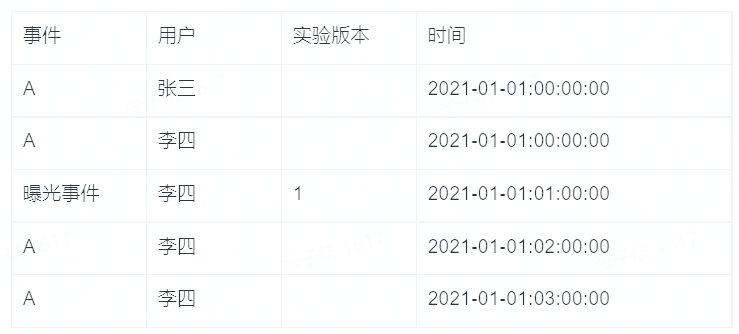
进入实验版本 1 的事件 A 的 PV 数是 2,UV 数是 1,转化为查询模型是:
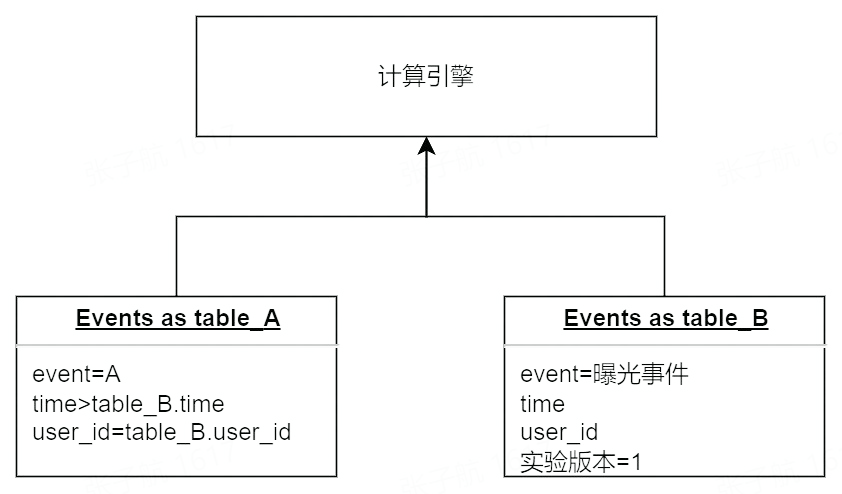
上述模型虽然最符合直觉,但是存在较多的资源浪费:
曝光事件和普通事件存储在一张事件表中量级大
曝光事件需要搜索第一条记录,扫描的分区数会随着实验时间的增加而增加
曝光事件可能反复上报,计算口径中仅仅第一条曝光为有效事件
针对上述问题对计算模型做出一些优化,把曝光事件转化为属性记录在用户表中,新的模型变化为:
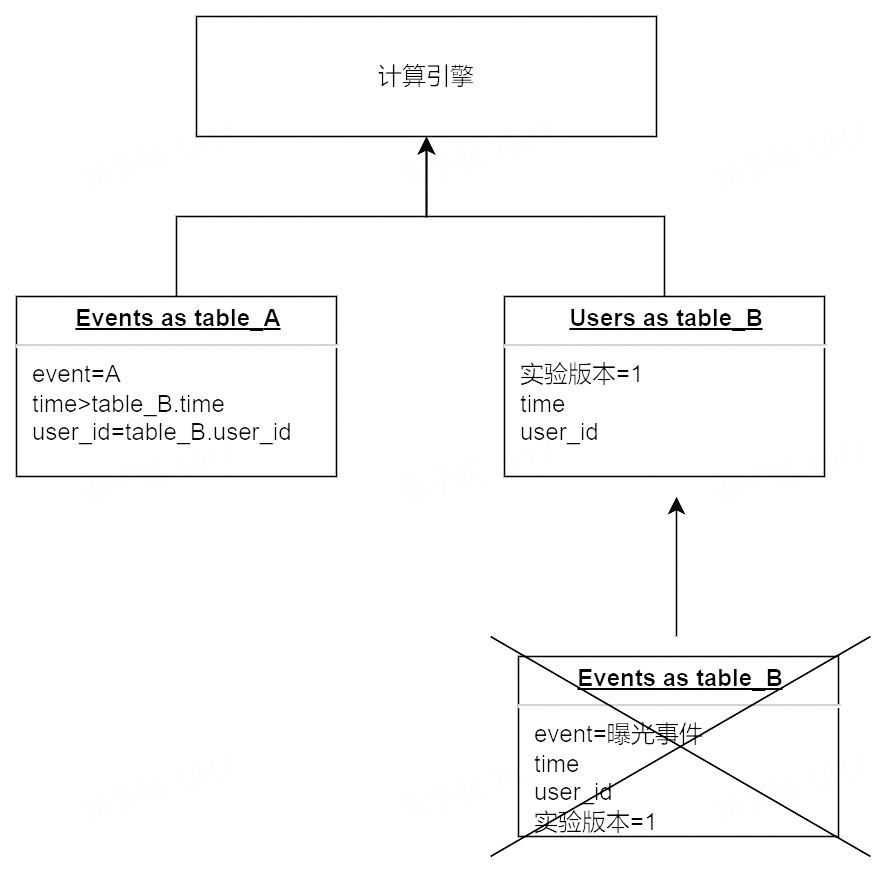
这么做带来的优点是:
用户表不存在时间的概念,数据增长=新用户增速,规模可控
用户表本身会作为维度表在原模型中引入,这类情况下减少一次 join 运算 模型优化后经测试 14 天以上实验指标多天累计报告查询时长减少 50%以上,且随实验时长增加提升。
3、 预聚合
私有化部署实施前会做前期的资源预估,现阶段的资源预估选择了“日活用户”和“日事件量”作为主要输入参数。这里暂时没有加入同时运行的实验数量是因为:
一是,我们希望简化资源计算的模型。
二是,同时运行的实验数量在大多数情况下无法提前预知。
但是该公式会引入一个问题:相同资源的集群在承载不同数量级的实验时计算量相差较大。实验数量少的场景下,当下数据处理架构轻量化,计算逻辑后置到查询侧,,指标计算按需使用,大大减轻了数据流任务的压力。
但是假设集群中同时运行 100 个实验,平均每个实验关注 3 个指标加上实验的进组人数统计,在当前查询模型下每天至少扫描事件表 100*(3+1)次,如果再叠加使用自定义过滤模板等预计算条件,这个计算量会被成倍放大,直到导致查询任务堆积数据产出延迟。
重新观察实验报告核心元素以及指标构成能发现:
指标、报告类型、实验版本是可枚举且预先知晓的
实验命中和人绑定,版本对比先划分出进入对照组和实验组的人,然后做指标比较
基于假设检验的置信水平计算需要按人粒度计算方差
现有的指标算子均可以先按人粒度计算(按....去重除外)
是否能够通过一次全量数据的扫描计算出人粒度的所有指标和实验版本?
答案是可以的:扫描当天的事件数据,根据实验、指标配置计算一张人粒度的指标表 user_agg。
通过 user_agg 表可以计算出指标计算需要的 UV 数、指标的统计值、指标的方差。如果对 user_agg 表的能力做进一步拓展,几乎可以代替原始表完成实验报告中 80%以上的指标计算,同时也很好地支持了天级时间选择切换、用户属性标签过滤等。
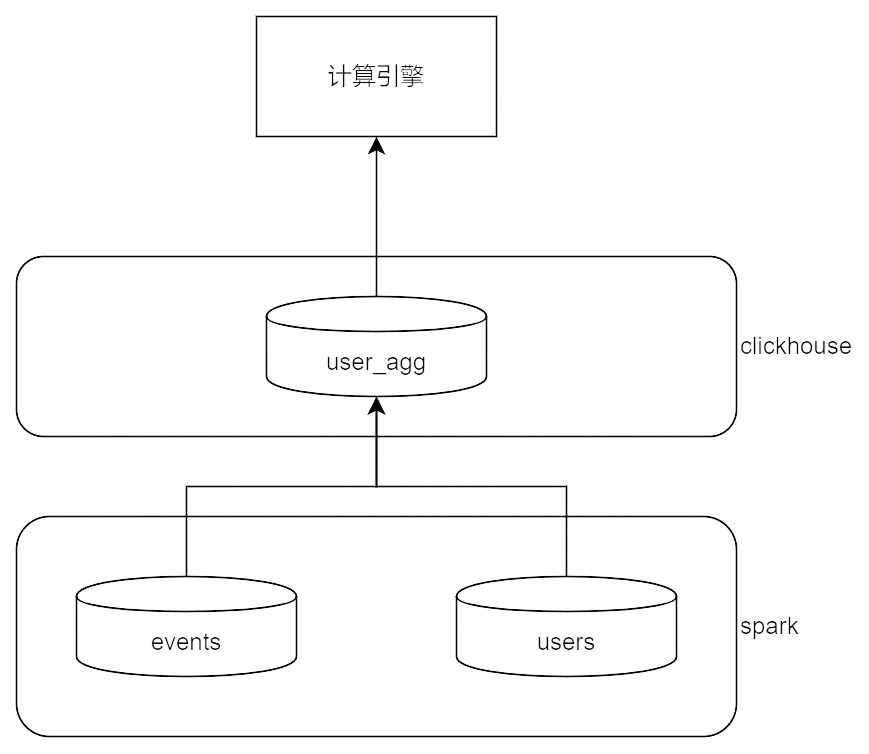
修改后的指标计算模型
通过经验数据,一个用户平均每天产生的事件量在 100-500 条不等,聚合模型通过少数几次对当天数据的全表扫描得到一张 1/100-1/500 大小的中间表,后续的指标计算、用户维度过滤均可以使用聚合表代替原始表参与运算。当然考虑到聚合本身的资源开销,收益会随着运行实验数增加而提高,而实验数量过少时可能会造成资源浪费,是否启用需要在两者之间需求平衡点。
挑战 3:稳定性
私有化服务的运维通道复杂、运维压力大,因此对服务的可用性要求更加严格。A/B 测试稳定性要求最高的部分是分流服务,直接决定了线上用户的版本命中情况。
分流服务本身面向故障设计, 采用降级的策略避免调用链路上的失败影响全部实验结果,牺牲一部分实时性使用多级缓存保障单一基础设施离线的极端情况下分流结果依然稳定。
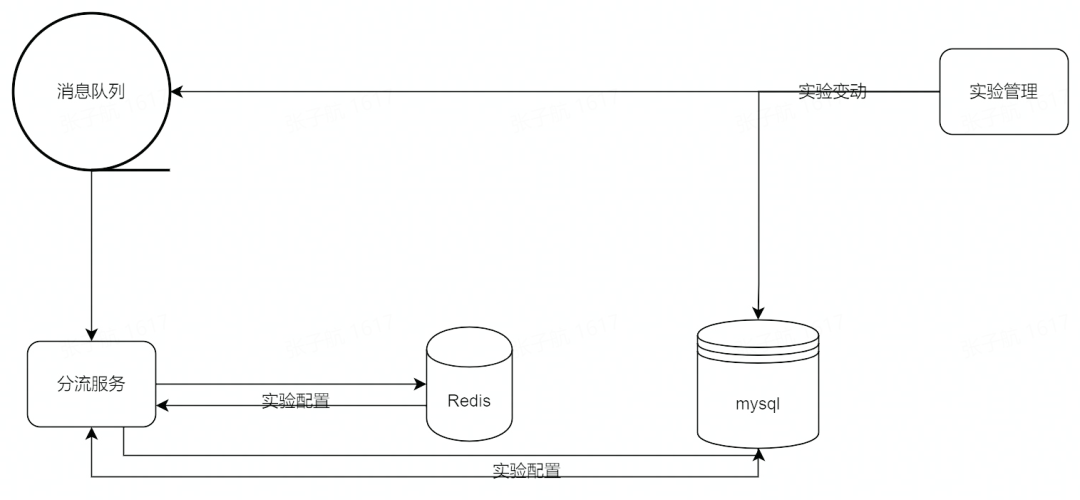
分流服务总体架构
我们将分流服务作为一个整体,一共使用了 3 级存储,分别是服务内存、Redis 缓存、关系型数据库。实验变动落库的同时,将变动消息写入消息队列,分流服务消费消息队列修改内存和 Redis 缓存中的实验配置,保证多节点之间的一致性和实时性。同时分流服务开启一个额外协程定期全量更新实验配置数据作为兜底策略,防止因为消息队列故障导致的配置不更新;将 Redis 视作 Mysql 的备组件,任意失效其中之一,这样分流服务即使重启依然可以恢复最新版本的分流配置,保障客户侧分流结果的稳定。
总结
火山引擎 A/B 测试(DataTester)脱胎于字节跳动内部工具,集成了字节内部丰富的业务场景中的 A/B 测实验经验;同时它又立足于 B 端市场,不断通过 ToB 市场的实践经验沉淀打磨产品来更好为内外部客户创造价值。
本文是火山引擎 A/B 测试(DataTester)团队在当前面向 ToB 客户的私有化实践中的实践分享,文中所遇到的私有化问题的破解过程也是这一产品不断打磨成熟,从 0-1 阶段走向 1-N 阶段的过程。
点击跳转 火山引擎A/B测试DataTester 了解更多
火山引擎 A/B 测试产品——DataTester 私有化架构分享的更多相关文章
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 火山引擎MARS-APM Plus x 飞书 |降低线上OOM,提高App性能稳定性
通过使用火山引擎MARS-APM Plus的memory graph功能,飞书研发团队有效分析定位问题线上case多达30例,线上OOM率降低到了0.8‰,降幅达到60%.大幅提升了用户体验,为飞书的 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- Slickflow.NET 开源工作流引擎高级开发(六) -- WebTest 引擎接口模拟测试工具集
前言:引擎组件的接口测试不光是程序测试人员使用,而且也是产品负责人员需要用到的功能,因为在每一步流转过程中,就会完整模拟实际用户发生的场景,也就容易排查具体是程序问题还是业务问题,从而快速定位问题,及 ...
- 引擎渲染速度测试--我js代码写得少你不要骗我
上一张图,很多人都看过的 地址:http://aui.github.io/artTemplate/test/test-speed.html 这个地址是在看artTemplate的时候看到的,很早都看过 ...
- php Smarty模板引擎配置与测试
Smarty简介 smarty是一个使用PHP写出来的模板PHP模板引擎,它提供了逻辑与外在内容的分离,简单的讲,目的就是要使用PHP程序员同美工分离,使用的程序员改变程序的逻辑内容不会影响到美工的页 ...
- MySQL中MyISAM引擎与InnoDB引擎性能简单测试
[硬件配置]CPU : AMD2500+ (1.8G)内存: 1G/现代硬盘: 80G/IDE[软件配置]OS : Windows XP SP2SE : PHP5.2.1DB : MySQL5.0.3 ...
随机推荐
- wampserver APACHE配置文件 和 单独安装APACHE 的配置文件 的区别
wampserver APACHE配置文件: 单独安装APACHE 的配置文件
- SpingBoot面试大汇总
1.什么是SpringBoot? 1)用来优化Spring应用的初始搭建以及开发过程,使用特定的方式来配置(properties和yml文件) 2)嵌入式的内置服务器tomcat无需部署war文件简化 ...
- vm 16 player安装与网络配置
1.密钥: FA1M0-89YE3-081TQ-AFNX9-NKUC0 2.安装步骤: xshell6,要先右键管理员运行绿化.bat,再双击.exe 3.一般的虚拟机,需要win上的v8适配器的ip ...
- react修改静态文件根目录
.env(项目根目录环境变量文件) PUBLIC_URL:http://cdn.com/
- Day03_Class01
用户交互Scanner Scanner对象 基本语法 Scanner sc = new Scanner(System.in); 通过Scanner类的next()与nextLine()方法获取输入的字 ...
- mysql explain 优化
explain的使用 使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈.在select语句之前增加explain关键字,Mysql会在查询上设置一个标记,执行查 ...
- PHP操作MySQL批量Update的写法,各框架通用防注入版
使用别人的扩展遇到了问题,发现没有做SQL注入的处理.我又写了个轮子,根据自己需求扩展了下,有需要的小伙伴可以直接取用. 这里就直接粘贴源码了,会用PHPD ,基本都会如何把它运用到各个框架里的. 本 ...
- js字符串常用的方法
1. charAt( ) 获取指定下标处的字符 let str = 'hello' console.log(str.charAt(0));//h 2. charCodeAt 获取下标出的字符的Un ...
- C# 自定义控件如何正确的继承父类
C# 自定义控件可以分为三类: 复合控件:基本控件组合而成.应当继承自 UserControl 扩展控件:继承基本控件,扩展一些属性和事件.比如继承 Button 自定义控件:直接继承自 Contro ...
- HTTP 协议相关
一. HTTP常见请求头 1. Host (主机和端口号) 2. Connection (连接类型) 3.Upgrade-Insecure-Requests (升级为HTTPS请求) 4. User- ...