GRU简介
一、GRU介绍
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
GRU的参数较少,因此训练速度更快,GRU能够降低过拟合的风险。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
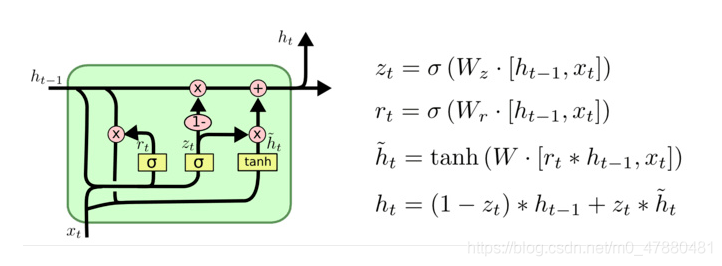
·
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 h~t


二、GRU与LSTM的比较
- GRU相比于LSTM少了输出门,其参数比LSTM少。
- GRU在复调音乐建模和语音信号建模等特定任务上的性能和LSTM差不多,在某些较小的数据集上,GRU相比于LSTM表现出更好的性能。
- LSTM比GRU严格来说更强,因为它可以很容易地进行无限计数,而GRU却不能。这就是GRU不能学习简单语言的原因,而这些语言是LSTM可以学习的。
- GRU网络在首次大规模的神经网络机器翻译的结构变化分析中,性能始终不如LSTM。
三、GRU的API
rnn = nn.GRU(input_size, hidden_size, num_layers, bias, batch_first, dropout, bidirectional)
初始化:
input_size: input的特征维度
hidden_size: 隐藏层的宽度
num_layers: 单元的数量(层数),默认为1,如果为2以为着将两个GRU堆叠在一起,当成一个GRU单元使用。
bias: True or False,是否使用bias项,默认使用
batch_first: Ture or False, 默认的输入是三个维度的,即:(seq, batch, feature),第一个维度是时间序列,第二个维度是batch,第三个维度是特征。如果设置为True,则(batch, seq, feature)。即batch,时间序列,每个时间点特征。
dropout:设置隐藏层是否启用dropout,默认为0
bidirectional:True or False, 默认为False,是否使用双向的GRU,如果使用双向的GRU,则自动将序列正序和反序各输入一次。
输入:
rnn(input, h_0)
输出:
output, hn = rnn(input, h0)
形状的和LSTM差不多,也有双向
四、情感分类demo修改成GRU
1 import torch
2 import torch.nn as nn
3 import torch.nn.functional as F
4 from torch import optim
5 import os
6 import re
7 import pickle
8 import numpy as np
9 from torch.utils.data import Dataset, DataLoader
10 from tqdm import tqdm
11
12
13 dataset_path = r'C:\Users\ci21615\Downloads\aclImdb_v1\aclImdb'
14 MAX_LEN = 500
15
16 def tokenize(text):
17 """
18 分词,处理原始文本
19 :param text:
20 :return:
21 """
22 fileters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>', '\?', '@'
23 , '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”', '“', ]
24 text = re.sub("<.*?>", " ", text, flags=re.S)
25 text = re.sub("|".join(fileters), " ", text, flags=re.S)
26 return [i.strip() for i in text.split()]
27
28
29 class ImdbDataset(Dataset):
30 """
31 准备数据集
32 """
33 def __init__(self, mode):
34 super(ImdbDataset, self).__init__()
35 if mode == 'train':
36 text_path = [os.path.join(dataset_path, i) for i in ['train/neg', 'train/pos']]
37 else:
38 text_path = [os.path.join(dataset_path, i) for i in ['test/neg', 'test/pos']]
39 self.total_file_path_list = []
40 for i in text_path:
41 self.total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)])
42
43 def __getitem__(self, item):
44 cur_path = self.total_file_path_list[item]
45 cur_filename = os.path.basename(cur_path)
46 # 获取标签
47 label_temp = int(cur_filename.split('_')[-1].split('.')[0]) - 1
48 label = 0 if label_temp < 4 else 1
49 text = tokenize(open(cur_path, encoding='utf-8').read().strip())
50 return label, text
51
52 def __len__(self):
53 return len(self.total_file_path_list)
54
55
56 class Word2Sequence():
57 UNK_TAG = 'UNK'
58 PAD_TAG = 'PAD'
59 UNK = 0
60 PAD = 1
61
62 def __init__(self):
63 self.dict = {
64 self.UNK_TAG: self.UNK,
65 self.PAD_TAG: self.PAD
66 }
67 self.count = {} # 统计词频
68
69 def fit(self, sentence):
70 """
71 把单个句子保存到dict中
72 :return:
73 """
74 for word in sentence:
75 self.count[word] = self.count.get(word, 0) + 1
76
77 def build_vocab(self, min=5, max=None, max_feature=None):
78 """
79 生成词典
80 :param min: 最小出现的次数
81 :param max: 最大次数
82 :param max_feature: 一共保留多少个词语
83 :return:
84 """
85 # 删除词频小于min的word
86 if min is not None:
87 self.count = {word:value for word,value in self.count.items() if value > min}
88 # 删除词频大于max的word
89 if max is not None:
90 self.count = {word:value for word,value in self.count.items() if value < max}
91 # 限制保留的词语数
92 if max_feature is not None:
93 temp = sorted(self.count.items(), key=lambda x:x[-1],reverse=True)[:max_feature]
94 self.count = dict(temp)
95 for word in self.count:
96 self.dict[word] = len(self.dict)
97 # 得到一个反转的字典
98 self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys()))
99
100 def transform(self, sentence, max_len=None):
101 """
102 把句子转化为序列
103 :param sentence: [word1, word2...]
104 :param max_len: 对句子进行填充或裁剪
105 :return:
106 """
107 if max_len is not None:
108 if max_len > len(sentence):
109 sentence = sentence + [self.PAD_TAG] * (max_len - len(sentence)) # 填充
110 if max_len < len(sentence):
111 sentence = sentence[:max_len] # 裁剪
112 return [self.dict.get(word, self.UNK) for word in sentence]
113
114 def inverse_transform(self, indices):
115 """
116 把序列转化为句子
117 :param indices: [1,2,3,4...]
118 :return:
119 """
120 return [self.inverse_dict.get(idx) for idx in indices]
121
122 def __len__(self):
123 return len(self.dict)
124
125
126 def fit_save_word_sequence():
127 """
128 从数据集构建字典
129 :return:
130 """
131 ws = Word2Sequence()
132 train_path = [os.path.join(dataset_path, i) for i in ['train/neg', 'train/pos']]
133 total_file_path_list = []
134 for i in train_path:
135 total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)])
136 for cur_path in tqdm(total_file_path_list, desc='fitting'):
137 sentence = open(cur_path, encoding='utf-8').read().strip()
138 res = tokenize(sentence)
139 ws.fit(res)
140 # 对wordSequesnce进行保存
141 ws.build_vocab(min=10)
142 # pickle.dump(ws, open('./lstm_model/ws.pkl', 'wb'))
143 return ws
144
145
146 def get_dataloader(mode='train', batch_size=20, ws=None):
147 """
148 获取数据集,转换成词向量后的数据集
149 :param mode:
150 :return:
151 """
152 # 导入词典
153 # ws = pickle.load(open('./model/ws.pkl', 'rb'))
154 # 自定义collate_fn函数
155 def collate_fn(batch):
156 """
157 batch是list,其中是一个一个元组,每个元组是dataset中__getitem__的结果
158 :param batch:
159 :return:
160 """
161 batch = list(zip(*batch))
162 labels = torch.LongTensor(batch[0])
163 texts = batch[1]
164 # 获取每个文本的长度
165 lengths = [len(i) if len(i) < MAX_LEN else MAX_LEN for i in texts]
166 # 每一段文本句子都转换成了n个单词对应的数字组成的向量,即500个单词数字组成的向量
167 temp = [ws.transform(i, MAX_LEN) for i in texts]
168 texts = torch.LongTensor(temp)
169 del batch
170 return labels, texts, lengths
171 dataset = ImdbDataset(mode)
172 dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
173 return dataloader
174
175
176 class ImdbLstmModel(nn.Module):
177
178 def __init__(self, ws):
179 super(ImdbLstmModel, self).__init__()
180 self.hidden_size = 64 # 隐藏层神经元的数量,即每一层有多少个LSTM单元
181 self.embedding_dim = 200 # 每个词语使用多长的向量表示
182 self.num_layer = 1 # 即RNN的中LSTM单元的层数
183 self.bidriectional = True # 是否使用双向LSTM,默认是False,表示双向LSTM,也就是序列从左往右算一次,从右往左又算一次,这样就可以两倍的输出
184 self.num_directions = 2 if self.bidriectional else 1 # 是否双向取值,双向取值为2,单向取值为1
185 self.dropout = 0.5 # dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropout
186 # 每个句子长度为500
187 # ws = pickle.load(open('./model/ws.pkl', 'rb'))
188 print(len(ws))
189 self.embedding = nn.Embedding(len(ws), self.embedding_dim)
190 # self.lstm = nn.LSTM(self.embedding_dim,self.hidden_size,self.num_layer,bidirectional=self.bidriectional,dropout=self.dropout)
191 self.gru = nn.GRU(input_size=self.embedding_dim, hidden_size=self.hidden_size, bidirectional=self.bidriectional)
192
193 self.fc = nn.Linear(self.hidden_size * self.num_directions, 20)
194 self.fc2 = nn.Linear(20, 2)
195
196 def init_hidden_state(self, batch_size):
197 """
198 初始化 前一次的h_0(前一次的隐藏状态)和c_0(前一次memory)
199 :param batch_size:
200 :return:
201 """
202 h_0 = torch.rand(self.num_layer * self.num_directions, batch_size, self.hidden_size)
203 return h_0
204
205 def forward(self, input):
206 # 句子转换成词向量
207 x = self.embedding(input)
208 # 如果batch_first为False的话转换一下seq_len和batch_size的位置
209 x = x.permute(1,0,2) # [seq_len, batch_size, embedding_num]
210 # 初始化前一次的h_0(前一次的隐藏状态)和c_0(前一次memory)
211 h_0 = self.init_hidden_state(x.size(1)) # [num_layers * num_directions, batch, hidden_size]
212 output, h_n = self.gru(x, h_0)
213
214 # 只要最后一个lstm单元处理的结果,这里多去的hidden state
215 out = torch.cat([h_n[-2, :, :], h_n[-1, :, :]], dim=-1)
216 out = self.fc(out)
217 out = F.relu(out)
218 out = self.fc2(out)
219 return F.log_softmax(out, dim=-1)
220
221
222 train_batch_size = 64
223 test_batch_size = 5000
224
225 def train(epoch, ws):
226 """
227 训练
228 :param epoch: 轮次
229 :param ws: 字典
230 :return:
231 """
232 mode = 'train'
233 imdb_lstm_model = ImdbLstmModel(ws)
234 optimizer = optim.Adam(imdb_lstm_model.parameters())
235 for i in range(epoch):
236 train_dataloader = get_dataloader(mode=mode, batch_size=train_batch_size, ws=ws)
237 for idx, (target, input, input_length) in enumerate(train_dataloader):
238 optimizer.zero_grad()
239 output = imdb_lstm_model(input)
240 loss = F.nll_loss(output, target)
241 loss.backward()
242 optimizer.step()
243
244 pred = torch.max(output, dim=-1, keepdim=False)[-1]
245 acc = pred.eq(target.data).numpy().mean() * 100.
246 print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\t ACC: {:.6f}'.format(i, idx * len(input), len(train_dataloader.dataset),
247 100. * idx / len(train_dataloader), loss.item(), acc))
248 torch.save(imdb_lstm_model.state_dict(), 'model/gru_model.pkl')
249 torch.save(optimizer.state_dict(), 'model/gru_optimizer.pkl')
250
251
252 def test(ws):
253 mode = 'test'
254 # 载入模型
255 lstm_model = ImdbLstmModel(ws)
256 lstm_model.load_state_dict(torch.load('model/lstm_model.pkl'))
257 optimizer = optim.Adam(lstm_model.parameters())
258 optimizer.load_state_dict(torch.load('model/lstm_optimizer.pkl'))
259 lstm_model.eval()
260 test_dataloader = get_dataloader(mode=mode, batch_size=test_batch_size, ws=ws)
261 with torch.no_grad():
262 for idx, (target, input, input_length) in enumerate(test_dataloader):
263 output = lstm_model(input)
264 test_loss = F.nll_loss(output, target, reduction='mean')
265 pred = torch.max(output, dim=-1, keepdim=False)[-1]
266 correct = pred.eq(target.data).sum()
267 acc = 100. * pred.eq(target.data).cpu().numpy().mean()
268 print('idx: {} Test set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(idx, test_loss, correct, target.size(0), acc))
269
270
271 if __name__ == '__main__':
272 # 构建字典
273 ws = fit_save_word_sequence()
274 # 训练
275 train(10, ws)
276 # 测试
277 # test(ws)
结果展示:
GRU简介的更多相关文章
- 深度学习四从循环神经网络入手学习LSTM及GRU
循环神经网络 简介 循环神经网络(Recurrent Neural Networks, RNN) 是一类用于处理序列数据的神经网络.之前的说的卷积神经网络是专门用于处理网格化数据(例如一个图像)的神经 ...
- Gated Recurrent Unit (GRU)公式简介
update gate $z_t$: defines how much of the previous memory to keep around. \[z_t = \sigma ( W^z x_t+ ...
- RNN 入门教程 Part 1 – RNN 简介
转载 - Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs Recurrent Neural Networks (RN ...
- AI - 机器学习常见算法简介(Common Algorithms)
机器学习常见算法简介 - 原文链接:http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/ 应 ...
- 初见-TensorRT简介<转>
下面是TensorRT的介绍,也可以参考官方文档,更权威一些:https://developer.nvidia.com/tensorrt 关于TensorRT首先要清楚以下几点: 1. TensorR ...
- 十 | 门控循环神经网络LSTM与GRU(附python演练)
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 门控循环神经网络简介 长短期记忆网络(LSTM) 门控制循环单元(GRU) ...
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- ASP.NET Core 1.1 简介
ASP.NET Core 1.1 于2016年11月16日发布.这个版本包括许多伟大的新功能以及许多错误修复和一般的增强.这个版本包含了多个新的中间件组件.针对Windows的WebListener服 ...
- MVVM模式和在WPF中的实现(一)MVVM模式简介
MVVM模式解析和在WPF中的实现(一) MVVM模式简介 系列目录: MVVM模式解析和在WPF中的实现(一)MVVM模式简介 MVVM模式解析和在WPF中的实现(二)数据绑定 MVVM模式解析和在 ...
- Cassandra简介
在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法.而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介 ...
随机推荐
- 半成品 java 身份证校验
public static Boolean is18Card(String idCard18) { //证件省份 HashMap<String, String> aCity = new H ...
- SaaS、PaaS、IaaS的区别
我们从SaaS.PaaS.IaaS的定义.工业应用以及具体案例几方面来介绍他们之间的区别 一.定义层面的区别 SaaS.PaaS.IaaS简单的说都属于云计算服务,也就是云计算+服务. 我们对于云计算 ...
- Oracle存储过程 Call使用
在 Oracle 中,可以将存储过程(PROCEDURE)定义在一个包(PACKAGE)中. 要调用包中的存储过程,需要使用包名和存储过程名来引用它们.以下是一个示例: 假设我们有一个名为 my_pa ...
- 【pytest】执行测试不输出logging日志问题
[一] 今天更新了一波pytest,4.50 -> 6.2.3.执行了一波测试发现之前的logging输出不见了. 看了下启动参数 --log-cli-level=LOG_CLI_LEVEL 加 ...
- Flink笔记
高可用(HA):直白来说就是系统不会因为某台机器,或某个实例挂了,就不能提供服务了.高可用需要做到分布式.负载均衡.自动侦查.自动切换.自动恢复等. 高吞吐: 单位时间内,能传输的数据量,对应指标就是 ...
- JAVA pta 前三次大作业回顾与分析
一.前言:总结三次题目集的知识点.题量.难度等情况 今年初次接触java,通过这三次大作业的练习,我对java有了一定的认识,相比于其他编程语言来说,java更复杂,要求也更严谨,需要掌握的知识也更多 ...
- Android studio的使用2
运行按钮First activity: package com.example.activity;import androidx.appcompat.app.AppCompatActivity;imp ...
- 如何解决7z: command not found问题
7z是一种常见的压缩文件格式,如果你想要压缩或解压缩7z文件,你需要在你的系统上安装p7zip和p7zip-full.但是,有时候你会发现当你尝试运行7z或7za命令时,它会显示"bash: ...
- Java流程控制1
Scanner对象 java.util.Scanner 通过Scanner类来获取用户输入 next()和nextline()来获取输入的字符串,读取前我们一般需要使用hasnext()和hasnex ...
- heimaJava-网络编程
Java 网络编程 概念 网络编程可以让程序与网络上的其他设备中的程序进行数据交互 网络通信基本模式 常见的通信模式有如下两种形式,Client-Server(CS),Browser/Server(B ...