nodejs学习总结01
主流渲染引擎
介绍
1.渲染引擎又叫 排版引擎 或 浏览器内核 。(双内核:执行html和css的)
2,主流的渲染引擎有
**Chrome浏览器**:Blink引壁(WebKit的一个分支)
**Safari浏览器**:WebKit引擎,windows版本2008年3月18日推出正式版,但苹果已于2012年7月25日停止开发Windows版的Safari.
**FireFox浏览器**:Gecko引擎,
**Operai浏览器**:Blink引擎(早期版使用Presto引擎)。
**Internet Explorer浏览器**:Trident引擎.
**Microsoft Edgei浏览器**:EdgeHTML引孳(Trident的一个分支),
浏览器的主要组件包括:
- 用户界面 (User Interface) - 包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
- 浏览器引擎 (Browser engine) - 用来查询及操作渲染引擎的接口。
- 渲染引擎 (Rendering engine) - 负责解析用户请求的内容(如 HTML 或 XML,渲染引擎会解析 HTML 或 XML,以及相关 CSS,然后返回解析后的内容)
- 网络(Networking)- 用来完成网络调用,例如 http 请求,它具有平台无关的接口,可以在不同平台上工作。
- UI 后端(UI backend) - 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
- JS 解释器(JavaScript interpreter) - 用来解释执行 JS 代码。
- 数据存储 (Data storage) - 属于持久层,浏览器需要在硬盘中保存类似 cookie 的各种数据,HTML5 定义了 web database 技术,这是一种轻量级完整的客户端存储技术。
最新的Chrome浏览器包括:
1个浏览器主进程,一个GPU进程,一个网络进程,多个渲染进程和多个插件进程。
浏览器进程:
主要负责界面显示、用户交互、子进程管理、同时提供存储等功能
渲染进程:
核心任务将HTML、CSS和JavaScript转化为用户可以交互的网页,排版引擎Blink和JavaScript引擎V8都是运行在该线程。默认情况下,Chrome浏览器为每个标签页创建一个渲染进程,但从一个页面打开另一个页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染流程。
GPU进程:
GPU的初衷是为了使用3D CSS效果,随后网页、Chrome的UI界面都采用了GPU来绘制,使得GPU成为浏览器普遍的需求,Chrome在其多进程架构上也引入了GPU进程。
网络进程:
主要负责页面的网络资源加载。
插件进程:
主要负责插件的运行,因插件容易崩溃,所以需要通过插件进程来隔离,保证插件进程崩溃不会对浏览器和页面造成影响。
①解析HTML生成DOM树。
②解析CSS生成CSSOM规则树。
③将DOM树与CSSOM规则树合并在一起生成渲染树。
④遍历渲染树开始布局,计算每个节点的位置大小信息。
⑤ 将渲染树每个节点绘制到屏幕。
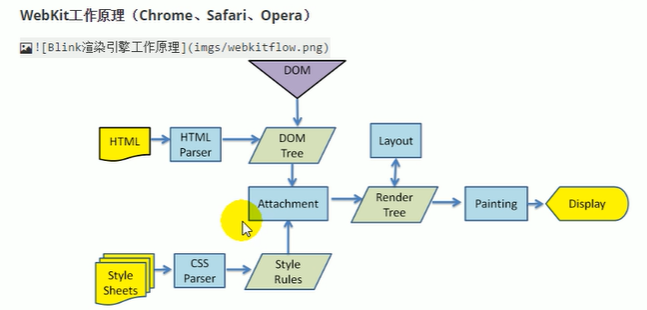
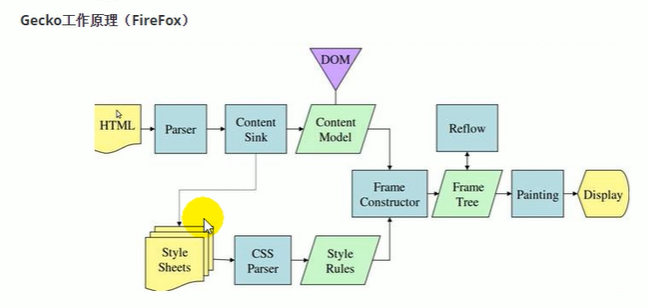
###工作原理
1.
解析HTML构建Dom树(Document Object Model,文档对象模型),DOM是W3C组织推荐的处理可扩展置标语言的标准编程接口。
2.构建*渲染,*渲染*并不等同于*Dom,因为像`head标签或display:none`这样的元素就没有必要放到*渲染
中了,但是它们在*Dom*中。
3.对*渲染*进行布局,定位坐标和大小、确定是否换行、确定position、overflow、z-index等等,这个过程叫"layout"或
"reflow'"。
4.绘制*渲染*,调用操作系统底层API进行绘图操作。

解析dom树——根据dom树生成渲染树——对渲染树里面的所有标签进行layout操作——把最终结果绘制一下。
浏览器访问网站过程
①在浏览器地址栏中输入网址后②浏览器对我们的url网址进行了http请求报文的封装。(把地址封装成很多信息交给服务器)③根据用户输入的域名(姓名)进行DNS解析(浏览器发起DNS解析请求),找到域名对应的ip地址(身份证号)将域名转化为ip地址。④浏览器直接把请求报文的数据都发给服务器(ip地址)。⑤服务器接收请求报文,并解析。⑥服务处理用户请求,并将处理结果封装成HTP响应报文。(结果也是一大堆数据)⑦服务器将HTTP响应报文发送给浏览器。⑧浏览器接收服务器响应的HTTP报文,并解析⑨浏览器解析HTML页面(生成dom树render树)并展示,在解析HTML页面时遇到新的资源需要再次发起请求。⑩最终浏览器展示出了页面。
Web开发本质
牢记以下三点
1.请求,客户端发起请求。
2.处理,服务器处理请求。
3.响应,服务器将处理结果发送给客户端
对比一个单机版计算器和Web版计算器
客户端处理响应
。服务器响应完毕后,客户端继续处理:
。浏览器:解析服务器返回的数据
。iOS、Android客户端,解析服务器返回的数据,并且通过iOS或Android的Ul技术实现界面的展示功能
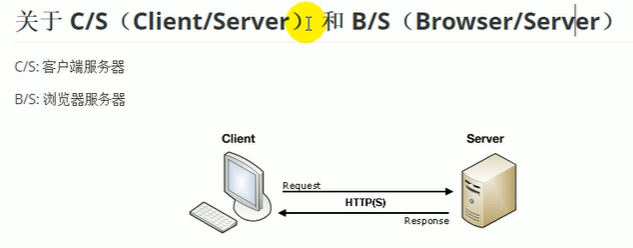
开发的时候看需求选择bs和cs
BS优点:不需要为每个用户开发独立客户端,只要把后台网站服务器搭建好后,只要有浏览器就可以使用应用程序,开发以后部署和维护非常方便,
BS缺点:用户使用起来可能不是特别流畅(很多都是cs和bs共同架构的,一套数据库)
手机app就是cs独立客户端,用浏览器的就是bs。
node.js是什么?
1.node.js是一个开发平台,就像]ava开发平台、.Net开发平台、PHP开发平台、Apple开发平台一样.
-何为开发平台?有对应的编程语言、有语言运行时有能实现特定功能的API(SDK:Software Development Kit)
2.该平台使用的编程语言是]avaScript语言。用js调用api
3.node.js平台是基于Chrome V8 JavaScript引幸构建,
4.基于node.js可以开发控制台程序(命令行程序、CLI程序)、桌面应用程序(GUI)(借助node-webkit、electron等框架实现)、Web应用程序(网站)
可以随时随地开发软件。
PHP开发技术栈:LAMP-Linux Apache MySQL PHP
node.js全栈开发技术栈:MEAN(前端的技术栈) MongoDB(数据库,不是mysql) Express(基于nodejs的web开发框架) Angular(前台) Node.js(后台)
node.js有哪些特点?
1.事件驱动(当事件被触发时,执行传递过去的回调函数)
2.非阻塞I/O模型(当执行I/O操作时,不会阻塞线程,不会阻塞主程序的运行,主程序开启io后继续向后面执行,io执行完毕后在通知主程序直接io运行结果)(I/O模型(比较耗时,进行输入输出后消耗后才能执行):输入输出input,output,I/O操作可能是磁盘I/O(从磁盘上写文件读取文件),也可能是网络I/O(从网络中发送数据从网络中接收数据))
3.单线程(本身JavaScript语言就是单线程语言)
4.拥有世界最大的开源库生态系统一npm.(js开源代码仓库,别人写好的代码直接用,类似于jQuery的插件,可拓展这些功能)
学习目标
1.了解服务器开发过程(当用户的一个请求过来的时候服务器是怎么处理的)
2.会使用node.js开发基本的http服务程序(Web应用程序)
配置环境变量的原因:让这个应用程序在任何一个路径下,某个exe文件在任何一个目录下,都能通过命令行启动它。
4.通过nvm-windows管理一台计算机上的多个node版本(可以随时切换nodejs各种版本)
Node.js开发Web应用程序和PHP、Java、ASP.Net等传统模式开发web应用程序区别
1.传统模式
有Web容器(eg:apache服务器 )(web服务器的作用就是监听用户的请求,并且根据不同请求做出不同处理,静态资源直接读取,动态资源直接交给对应的模块处理)
[有Web容器开发模型]
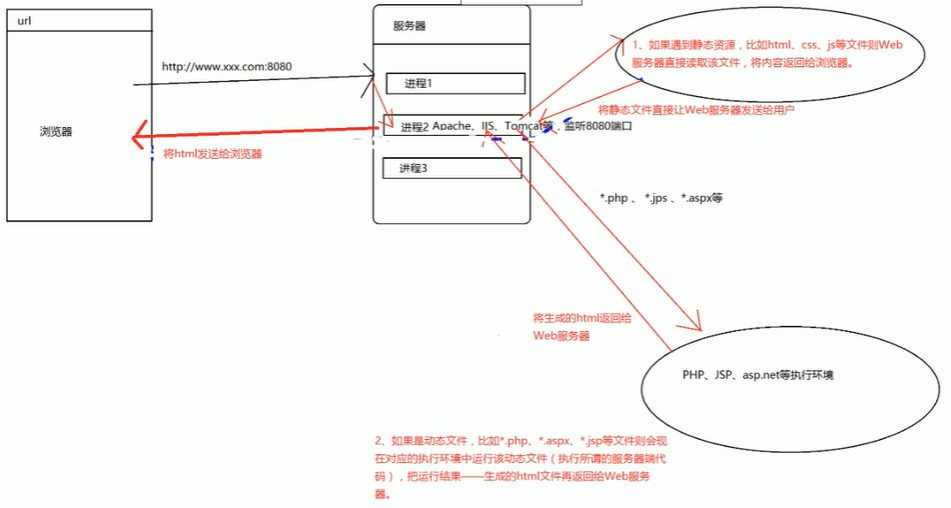
2.Node.js开发Web应用程序
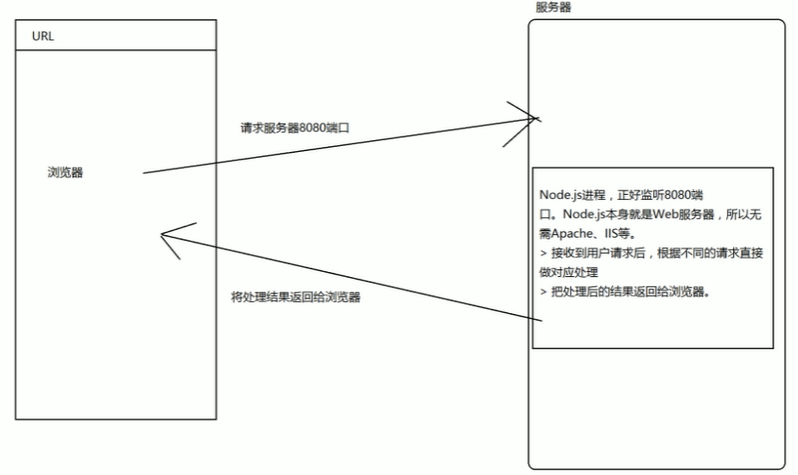
没有Web容器
[Node.js无web容器开发模型]
nodejs本身就可以创建一个HTTP服务器(本身就是基于最底层的HTTP协议开始的)
无论请求静态资源还是动态资源,都是由nodejs,我们自己写代码在nodejs处理这个请求,如果有apache的话就会自动帮我们处理。
所以用nodejs来开发一个网站的话,效率会很低,所以npm上有人帮我们写好了很多框架,web开发框架express
3.补充提问:
-什么是动态网页?什么是静态网页?
在node.js上编写程序
REPL介绍
1.REPL全称:Read-Eval-Print-Loop(交互式解释器)
R读取·读取用户输入,解析输入了Javascript数据结构并存储在内存中。
E执行·执行输入的数据结构
P打印-输出结果
L循环·循环操作以上步骤直到用户两次按下ctrl-c按钮退出。
2.在REPL中编写程序(类似于浏览器开发人员工具中的控制台console功能)
直接在控制台输入node命令进入REPL环境
3.按两次Control+C退出REPL界面或者输入. exit退出REPL界面
按住control键不要放开,然后按两下c键
**创建js文件编写程序
js文件就是源代码文件,用sublime软件
JavaScript文件名命名规则
①不要用中文
②不要包含空格
③不要出现node关键字
④建议以 '-' 分割单词
文件操作:
process模块在使用的时候无需通过require()函数来加载该模块,可以直接使用
fs模块,在使用的时候,必须通过require()函数来加载该模块,方可使用。var fs=require('fs');
原因:process模块是全局的模块,而fs模块不是全局模块,全局模块可以直接使用,而非全局模块需要先通过require('')加载该模块。
怎么判断模块是否加载?
①直接打开nodejs官方文档api,文档中告诉你了需要require加载,说没有的就不用加载。
②点击左边模块的global选项,就会列出全局模块。(console模块不是ecmascript自带的,是浏览器帮我们实现的对象,但是nodejs里也有自带的console模块来帮我们实现控制台功能)
<buffer>就是一堆字节数组。
文件读写案例
使用到的模块var.fs=require('fs');
(fs :file system)
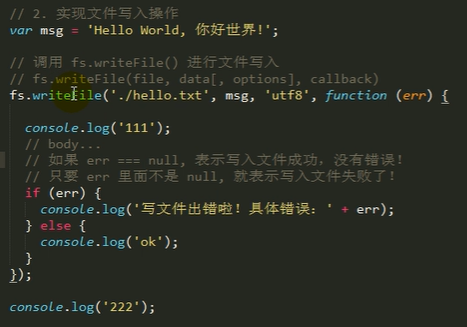
1、写文件:fs.writeFile(file,data[,options],callback);
参数1:要写入的文件路径,**必填**。
参数2:要写入的数据,**必填**。
参数3:写入文件时的选项,比如:文件编码,选填。
参数4:文件写入完毕后的回调函数,*必填**。
写文件注意:
该操作采用异步执行
如果文件已经存在则替换掉
*默认写入的文件编码为utf8
回调函数有1个参数:err,表示在写入文件的操作过程中是否出错了。果出错了errI=null,否则err==null
js中单线程-非阻塞IO模型解释
不管是nodejs下还是浏览器下运行js,js始终是单线程
在nodejs下的js既是单线程又是异步的非阻塞IO模型。
(执行完外面的在回头执行函数里面的)
若是同步又阻塞,栈里该怎么执行?
异步的话就必须返回一个回调函数。
异步操作(实现代码)
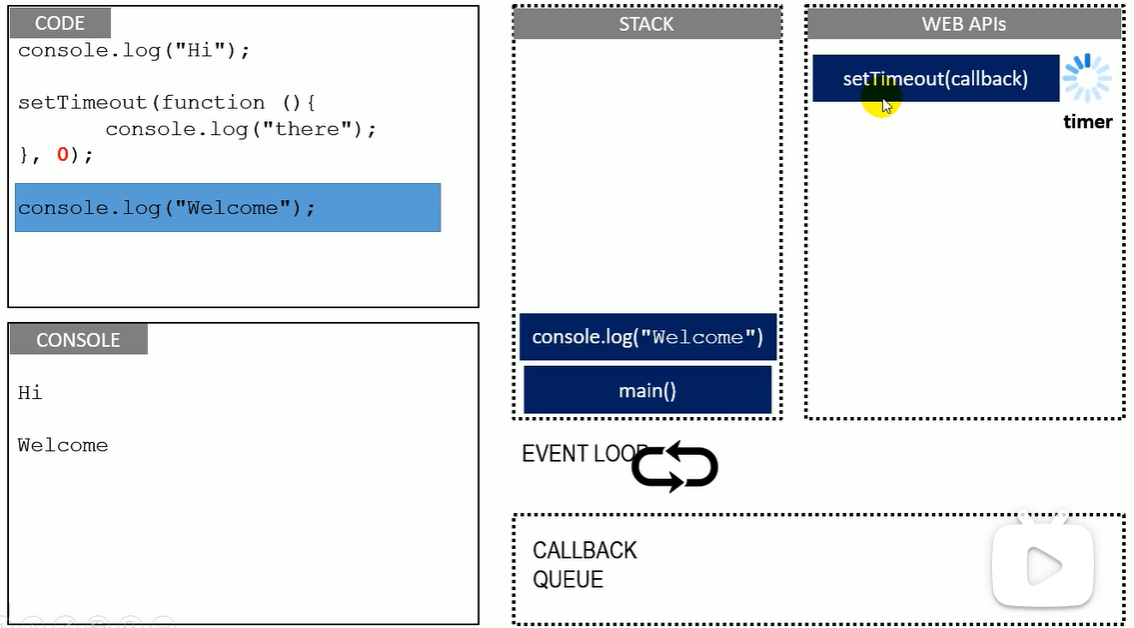
并行&事件循环
there被异步处理。就算是零毫秒,也是立刻放在队列中等待,而不是在栈里被执行。

实现文件读取工作
(也是异步方法)
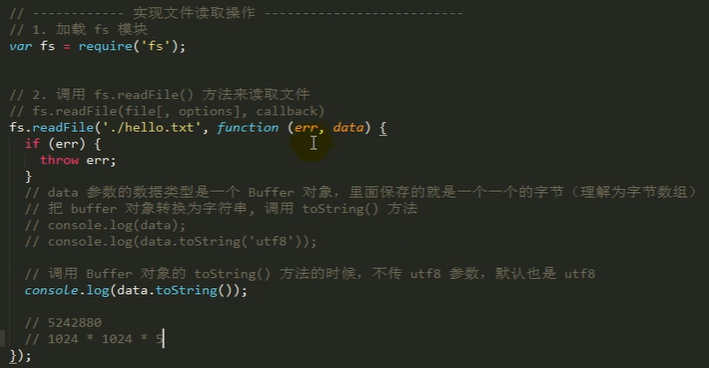
假设还要读取文件,传第二个参数utf8,不传,就默认buffer
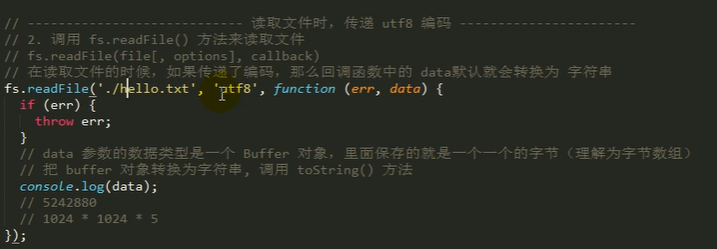
__dirname和__filename获取 正在执行的js文件的路径

解决在文件读取中,./相对路径的问题
解决:__dirname、__filename
__dirname:表示,当前正在执行的js文件所在的目录
__filename:表示,当前正在执行的js文件的完整路径
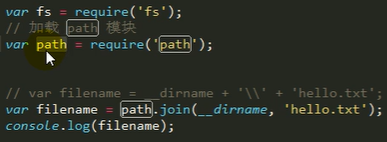
内置模块:path
通过path模块进行路径拼接
创建目录案例:
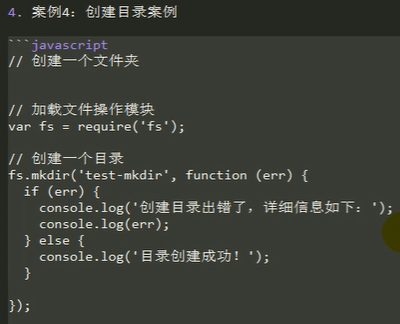
注意:
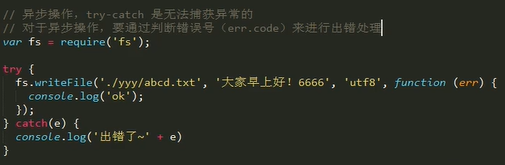
1.异步操作无法通过try-catch来捕获异常,要通过判断error来判断是否出错。
2.同步操作可以通过try-catch来捕获异常。
3.不要使用fs.exists(path,callback)来判断文件是否存在,直接判断error即可
4.文件操作时的路径问题
--在读写文件的时候 '. /' 表示的是当前执行node命令的那个路径,不是被执行的js文件的路径
__dirname,表示的永远是"当前被执行的js的目录”
__filename,表示的是"被执行的js的文件名(含路径)"
5.error-first介绍(错误优先)(第一个参数都是错误对象,(err,data))
以后设计API的时候也可以把第一个参数对象始终设置为错误对象。
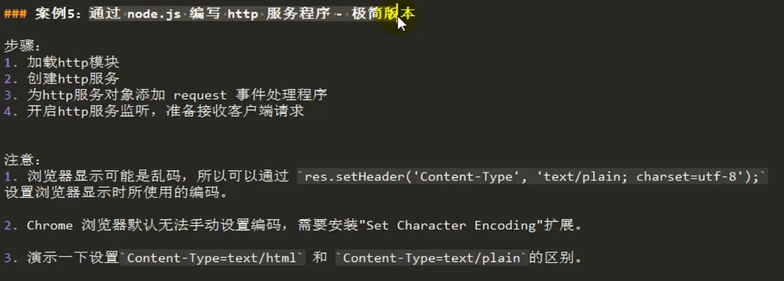
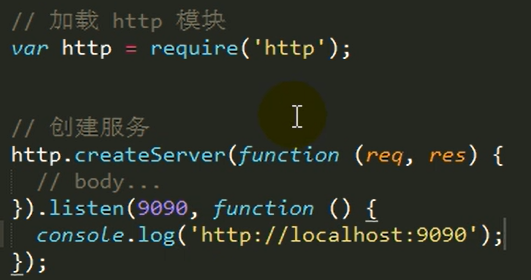
##案例5:通过node.js编写http服务程序-极简版本
步骤:
1.加载http模块(要用到这个内置模块)
2.创建http服务对象
3.为http服务对象添加request事件处理程序
server.on('request',function(argument){//argument回调函数里面有两个参数,request,response,简写成req和res
//body...
});
(request里有很多要解析的请求报文的所有东西)
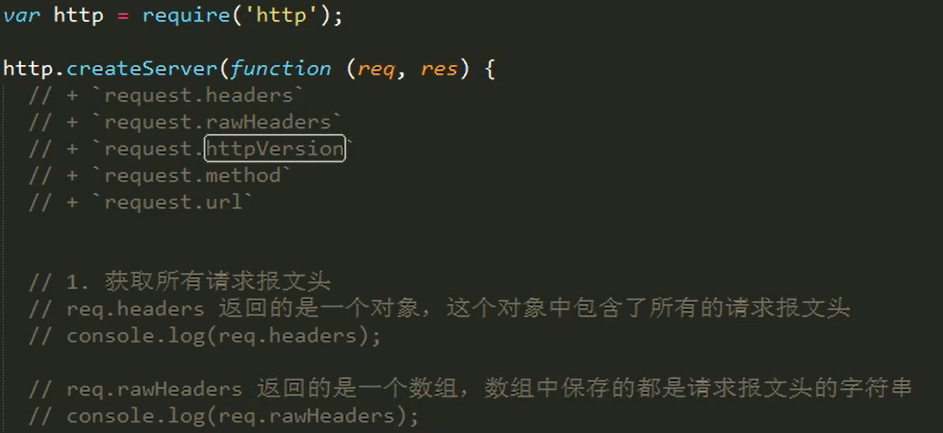
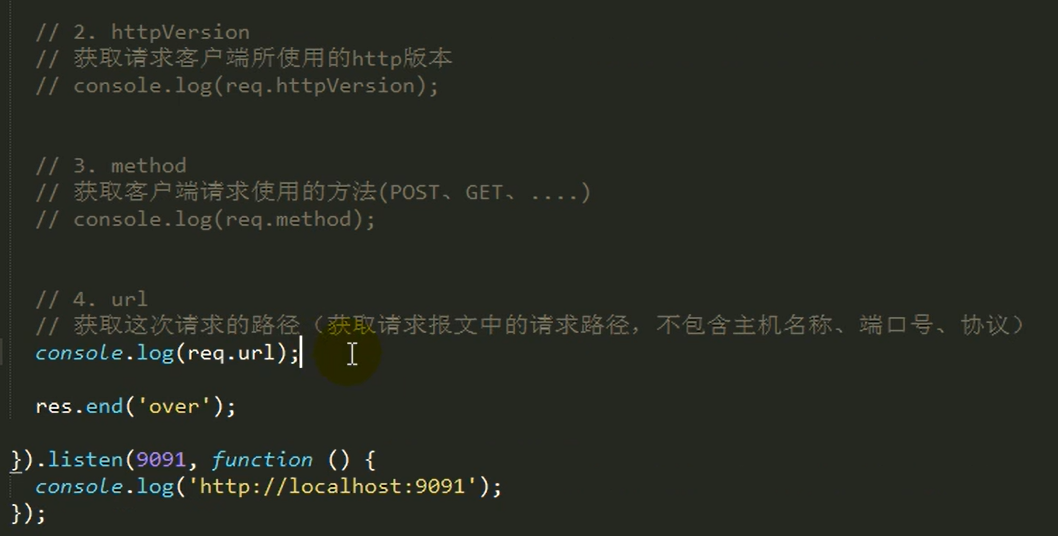
①request对象包含了用户请求报文中的所有内容,通过request对象可以获取所有用户提交过来的数据。
②response对象用来向用户响应一些数据,当服务器要向客户端响应数据的时候必须使用response对象。
③有了request对象和response对象,就既可以获取用户提交的数据,也可以向用户响应数据了。
4.开启http服务监听,准备接收客户端请求

但是也必须要结束响应。
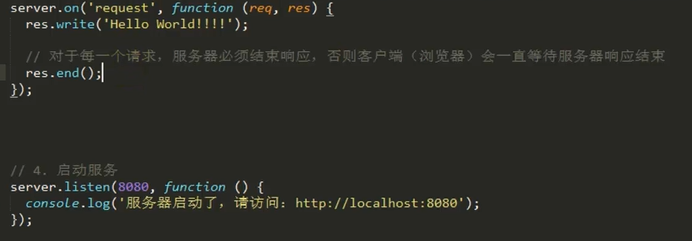
解决乱码问题。

http响应报文头的作用,要以html的方式展示就是HTML(<h></h>)以文本就是文本。
注意:
1.浏览器显示可能是乱码,所以可以通过`res.setHeader('Content-Type', 'text/plain; charset=utf-8');
设置浏览器显示时所使用的编码。
2.Chrome浏览器默认无法手动设置编码,需要安装"Set Character Encoding"扩展。
3.演示一下设置`Content-Type=text/html 和 Content-Type=text/plain的区别。
构建http服务:
1.加载http模块
2.创建http服务
3.监听request事件
4.启动服务
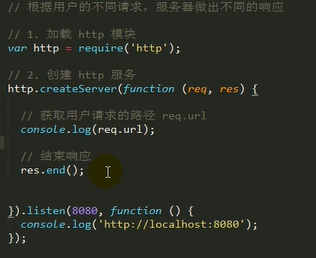
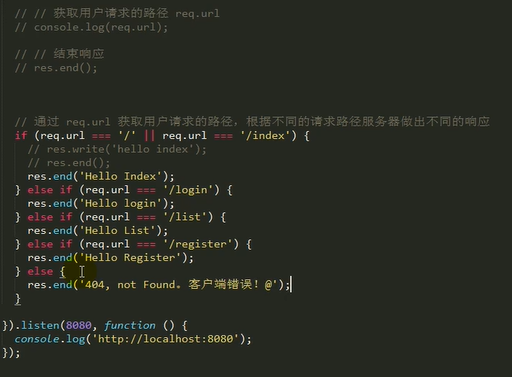
!!! 还要注意解决乱码问题
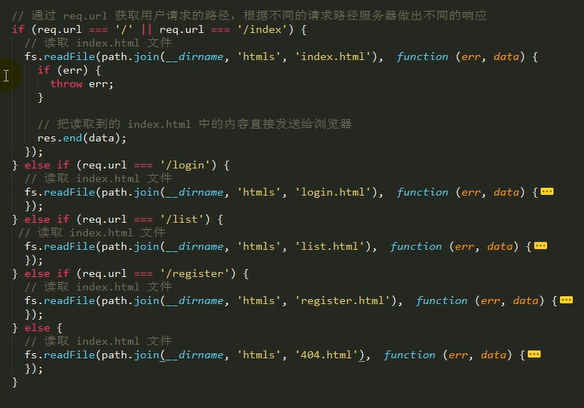
根据不同请求,做出不同响应(响应先有的HTML文件)
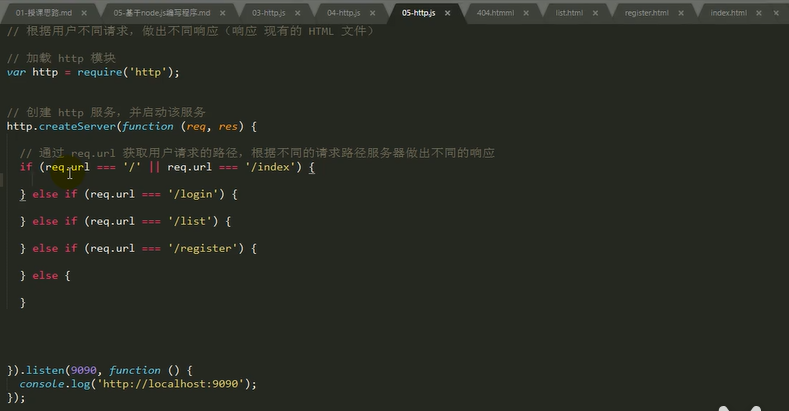
只要做两件事:一,读取网页内容,(加载fs模块)二,把网页响应。
也要对路径进行拼接(path模块)
不用传参utf8,直接是buffer,反正都要变成二进制在网络中传输,完全不需要先把它转成字符串,再转成二进制,在发送。直接把buffer字节通过网络发给浏览器,浏览器再把它解析成字符串再显示。浏览器读到的本来就是二进制。
而且 html文件中也有了charset=“UTF-8”了,浏览器就知道了要用utf8来解析了,所以不会乱码。

编写简单的http服务程序,无论请求当前网站下哪个路径,都返回hello world
乱码间题。res.setHeader('Content-Type','text/plain;charset=utf-8');
设置显示HTML内容。res.setHeader('Content-Type','text/html;charset=utf-8');
补充:
1.文件操作时,无需先判断文件是否存在,直接操作即可,如果文件不存在会反应在error对象中。
2. try-catch的使用
try-catch与异步操作(因为nodejs里面有大量的异步语调,但是try catch只能捕获同步的异常)
try-catch是用来捕获异常的,如果程序发生异常,执行完catch里面的代码,整个程序依然照常运行的。
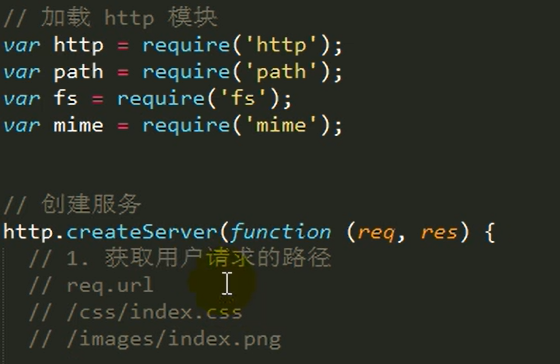
模拟apache服务器
一个index.html里带了一张图片和一个css文件 ,如果一个html里要带很多个图片和css 等静态资源,就很麻烦,步骤繁琐。
解决方法:只要是静态资源,可以把当前网站的所有静态资源(js,css,jQuery,图片)都放到同一个目录下,(创建一个文件夹), 直接请求这个目录拼上(path)要请求的资源文件路径, 这样就省去了一大堆if,else判断。
要实现以上解决方法的需求,就要模拟apache服务器:启动模拟apache服务器后,把所有静态资源放在一个目录下,就会自动帮我们返回。
其中要加载mime的第三方模块。npm install mime

知识点:在请求服务器的时候,请求的url就是一个标识!(就是一个后缀而已)
我们看到的请求什么就返回什么,是web容器和apache服务器已经帮我们转换好,请求html文件就返回html。请求css就返回css,请求.jpg就返回.jpg。但事实不是这样的,在请求服务器的时候,请求的url就是一个标识。具体返回什么,完全是由服务器决定的。(apache对.php文件,可以启用php模块运行)比如请求index.do时给你返回什么。
仅仅是个标识,可做判断
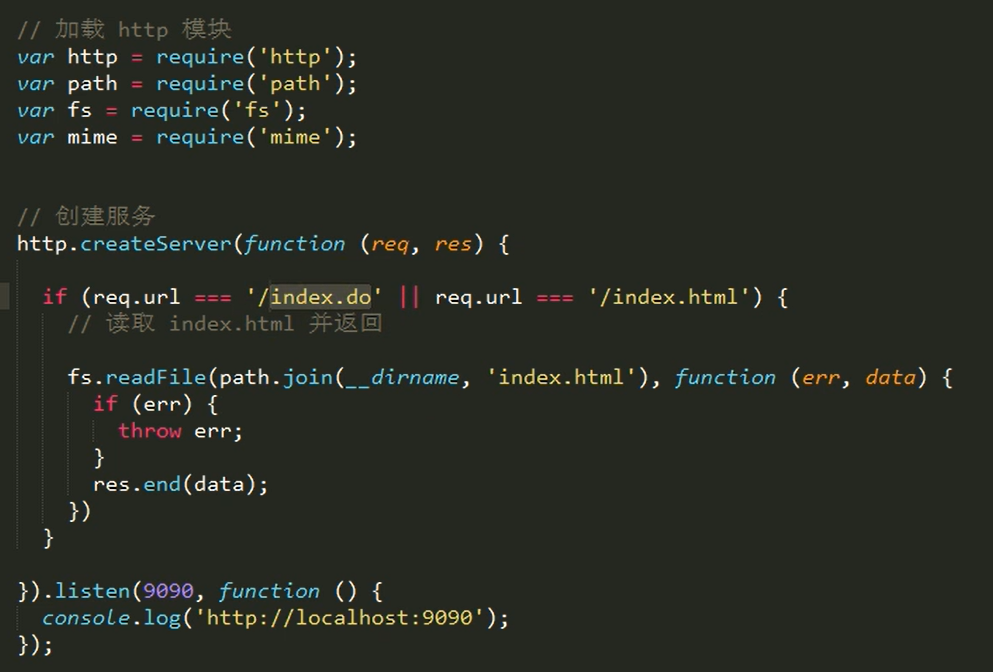
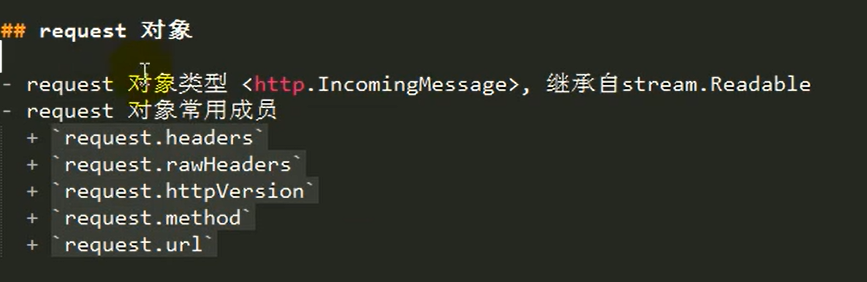
request(http.IncomingMessage) 和 response (ServerResponse) 对象介绍
request: 服务器解析用户提交的http请求报文,将结果解析到request对象中。凡是要获取和用户请求相关的数据都可以通过request对象获取。
response: 在服务器端用来向用户做出响应的对象。凡是需要向用户(客户端)响应的操作,都需要通过response对象来进行。
request对象常用的api
nodejs学习总结01的更多相关文章
- NodeJS 学习总结 01 安装配置
1 安装NodeJS 具体参考已发布的文章Ubuntu学习总结-07 Nodejs和npm的安装 2 使用淘宝 NPM 镜像 国内直接使用 npm 的官方镜像是非常慢的,这里推荐使用淘宝 NPM 镜像 ...
- 【NodeJS 学习笔记01】不学就老了
前言 再不学nodeJs,我们就老了......在HTML5大浪袭来的时候,很多先辈就开始了NodeJs之旅,而那时我还在做服务器端的程序后来转成前端,和梯队的距离已经很大了,因为我会服务器端语言,还 ...
- nodejs学习以及SSJS漏洞
0x01 简介 什么是nodejs,it's javascript webserver! JS是脚本语言,脚本语言都需要一个解析器才能运行.对于写在HTML页面里的JS,浏览器充当了解析器的角色.而对 ...
- NodeJS学习笔记 进阶 (12)Nodejs进阶:crypto模块之理论篇
个人总结:读完这篇文章需要30分钟,这篇文章讲解了使用Node处理加密算法的基础. 摘选自网络 Nodejs进阶:crypto模块之理论篇 一. 文章概述 互联网时代,网络上的数据量每天都在以惊人的速 ...
- 软件测试之loadrunner学习笔记-01事务
loadrunner学习笔记-01事务<转载至网络> 事务又称为Transaction,事务是一个点为了衡量某个action的性能,需要在开始和结束位置插入一个范围,定义这样一个事务. 作 ...
- Nodejs学习路线图
前言 用Nodejs已经1年有余,陆陆续续写了48篇关于Nodejs的博客文章,用过的包有上百个.和所有人一样,我也从Web开发开始,然后到包管 理,再到应用系统的开发,最后开源自己的Nodejs项目 ...
- Nodejs学习笔记(四)——支持Mongodb
前言:回顾前面零零碎碎写的三篇挂着Nodejs学习笔记的文章,着实有点名不副实,当然,这篇可能还是要继续走着离主线越走越远的路子,从简短的介绍什么是Nodejs,到如何寻找一个可以调试的Nodejs ...
- Nodejs学习笔记(三)——一张图看懂Nodejs建站
前言:一条线,竖着放,如果做不到精进至深,那就旋转90°,至少也图个幅度宽广. 通俗解释上面的胡言乱语:还没学会爬,就学起走了?! 继上篇<Nodejs学习笔记(二)——Eclipse中运行调试 ...
- Nodejs学习笔记(二)——Eclipse中运行调试Nodejs
前篇<Nodejs学习笔记(一)——初识Nodejs>主要介绍了在搭建node环境过程中遇到的小问题以及搭建Eclipse开发Node环境的前提步骤.本篇主要介绍如何在Eclipse中运行 ...
随机推荐
- .net 项目使用 JSON Schema
.net 项目使用 JSON Schema 最近公司要做配置项的改造,要把appsettings.json的内容放到数据库,经过分析还是用json的方式存储最为方便,项目改动性最小,这就牵扯到一个问题 ...
- 基于SqlSugar的开发框架的循序渐进介绍(1)--框架基础类的设计和使用
在实际项目开发中,我们可能会碰到各种各样的项目环境,有些项目需要一个大而全的整体框架来支撑开发,有些中小项目这需要一些简单便捷的系统框架灵活开发.目前大型一点的框架,可以采用ABP或者ABP VNex ...
- EditText简单登陆界面制作
- node包的降版本
1.安装版本更高的node包直接到官网去安装. 2.从版本高的node包,降低到版本低的node包. 要先卸载现在的node包,在菜单栏中可以删除. 然后通过https://nodejs.org/zh ...
- Spring Authorization Server 0.3.0 发布,官方文档正式上线
基于OAuth2.1的授权服务器Spring Authorization Server 0.3.0今天正式发布,在本次更新中有几大亮点. 文档正式上线 Spring Authorization Ser ...
- DirectX11 With Windows SDK--19(Dev) 编译Assimp并加载模型、新的Effects框架
前言 注意:这一章进行了重写,对应教程Dev分支第19章的项目,在更新完后面的项目后会替换掉原来第19章的教程 在前面的章节中我们一直使用的是由代码生成的几何模型,但现在我们希望能够导入模型设计师生成 ...
- distroless 镜像介绍及 基于cbl-mariner的.NET distroless 镜像的容器
1.概述 容器改变了我们看待技术基础设施的方式.这是我们运行应用程序方式的一次巨大飞跃.容器编排和云服务一起为我们提供了一种近乎无限规模的无缝扩展能力. 根据定义,容器应该包含 应用程序 及其 运行时 ...
- Django-使用nginx部署
本地部署 uWSGI 在部署之前,我们得先了解几个概念 wsgi web应用程序之间的接口.它的作用就像是桥梁,连接在web服务器和web应用框架之间. uwsgi 是一种传输协议,用于定义传输信息的 ...
- 使用c++爬取股市数据,获取最新行情
最近自己动手写个小软件(界面原生态,还没来得及加样式哈).每天看看潜力股懒人做法,不介意推荐.资源有限,只能观察一下低价股,分析一下运动规律,什么时候拉升,惯性如何 主要功能:读取网络数据:保存本地数 ...
- gslb(global server load balance)技术的一点理解
gslb(global server load balance)技术的一点理解 前言 对于比较大的互联网公司来说,用户可能遍及海内外,此时,为了提升用户体验,公司一般会在离用户较近的地方建立机房,来服 ...