CoLAKE: 如何实现非结构性语言和结构性知识表征的同步训练
原创作者 | 疯狂的Max
论文CoLAKE: Contextualized Language and Knowledge Embedding 解读
01 背景与动机
随着预训练模型在NLP领域各大任务大放异彩,一系列研究都致力于将外部知识融入大规模预训练模型,比如ERNIE[1]和KnowBERT[2],然而这些模型的局限性可以总结为以下三个方面:
(1)entity embedding都是通过一些knowledge embedding(KE) models,比如用TransE[3],预先提前训练好的。因此模型并不是一个真正的同步训练知识表征和语言表征的综合模型;
(2)只利用了知识图谱中的entity embedding来提升预训练模型,很难完全获取的知识图谱中一个实体丰富的上下文信息。因此对应的效能增益也就局限于预先训练好的 entity embedding的质量。
(3)预训练好的entity embedding是固定的,并且在知识图谱稍作改变时都需要重新训练。针对这三点局限,本文作者提出一种CoLAKE模型,通过改造模型的输入和结构,沿用预训练模型的MLM目标,对语言和知识的表征同时进行同步训练,将其统一在一个一致的表征空间中去。不同于前人的模型,CoLAKE根据知识的上下文和语言的上下文动态的表征一个实体。
为了解决非结构化文本与知识之间的异构性冲突,CoLAKE将两者以一种统一的数据结果将两者整合起来,形成word-knowledge graph,将其作为预训练数据在改造后的Transformer encoder模型上进行预训练。
除此之外,CoLAKE拓展了原始BERT的MLM训练任务,也就是将掩码策略应用的word,entity,relation节点上,通过WK graph未被掩盖的上下文和知识来预测掩盖的节点。
作者在GLUE和一些知识导向的下游任务上进行了实验,结果证明CoLAKE在大多数任务上都超越了原始的预训练模型和其他融合知识图谱的预训练模型。
总结起来,CoLAKE有以下三个亮点:
(1)通过扩展MLM训练任务同步学习到了带有上下文的语言表征和知识表征。
(2)采用WK graph的方法融合了语言和知识的异构性。
(3)本质上是一个预训练的GNN网络,因此其结构性可扩展。
02 模型方法
CoLAKE在结构化的、无标签的word-knowledge graphs的数据上对结合了上下文的语言和知识表征进行联合的、同步的预训练。其实现方法是先构造出输入句子对应的WK graphs,然后对模型结构和训练目标稍作改动。具体实现如下:
①构造WK graphs
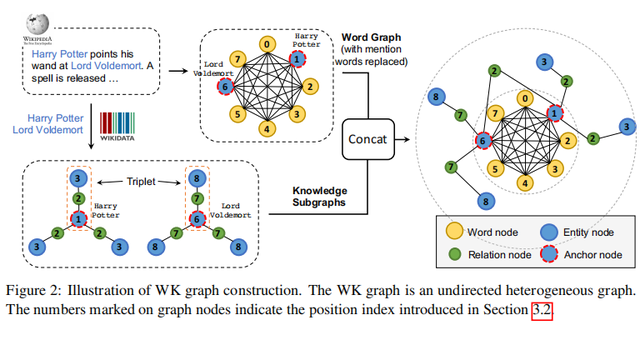
先对输入的句子中的mention进行识别,然后通过一个entity linker找到其在特定知识图谱中对应的entity。Mention结点被替换为相应的entity,被称作anchor nodes。
以这个anchor node为中心,可以提取到多种三元组关系来形成子图,提取到的这些子图和句子中的词语,以及anchor node一起拼接起来形成WK graph,如下图 Figure 2所示。
实际上,对于每个anchor node,作者随机玄奇最多15个相邻关系和实体来构建WK graph,并且只考虑anchor node在三元组中是head的情况。
②模型结构改动
接下来构建好的WK graph进入Transformer Encoder,CoLAKE对embedding层和encoder层都做了相应的改造。
Embedding Layer:输入的embedding是token embedding,type embedding和position embedding的加和。
其中,token embedding,需要构建word、relation和entity三种类型的查找表。
对于word embedding,采用Roberta一样的BPE的分词方法,将词语切割为字词用以维护大规模的词典。相应的,对每一个entity和relation就沿用一般的知识嵌套方法一样来获取对应的embedding。
然后输入中token embedding则是由word embedding,entity embedding, relation embedding拼接起来,这三者是同样维度的向量。
因为WK graph会将原本的输入以token为单位进行重组,因此输入的token序列会看起来像是一段错乱的序列,因此需要对应修正其type input和position input。
其中对于每个token,其同一对应的type会用来表征该token对应的node的类型,比如是word,entity或者是relation;对应的position也是根据WK graph赋予的。下图给出了一个具体的例子进行说明:
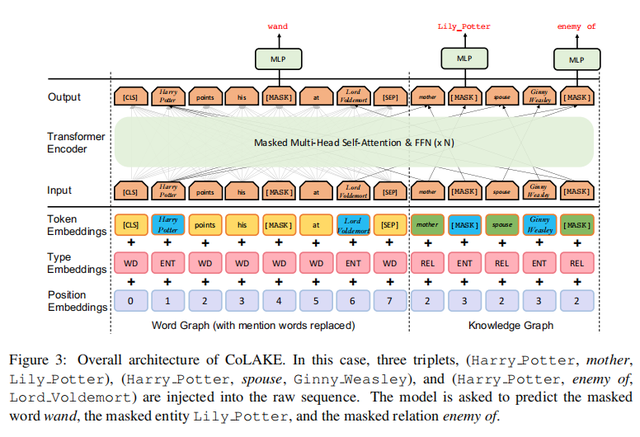


可以看出,模型的改动就是在计算注意力矩阵的时候,对于没有关联的节点加上了负无穷,使得两者不可见,以这种方式体现出WK graph的结构。
③训练目标
MLM是指随机的掩盖掉输入中的某些词,让模型预测掩盖掉的词是什么。而CoLAKE就是将MLM从词序列拓展到了WK graphs。
作者随机掩盖15%的节点,80%的时间用[MASK]替代,10%的时间随机替换成同类型的其他节点,10%时间不做任何改变。
通过掩盖词语,关系和实体三种不同的结点,能从不同角度帮助模型更好的同时学习到语言本身和知识图谱中的知识,并且对齐语言和知识的表征空间。
同时,作者提到在预测anchor node的时候,模型可能会更容易借助知识上下文而不是语言上下文,因为后者的多样性和学习难度更大。为了规避这个问题,作者在预训练时在50%的时间里丢弃了anchor nodes的相邻节点,从而减少来自知识图谱的帮助。
03 实验结果
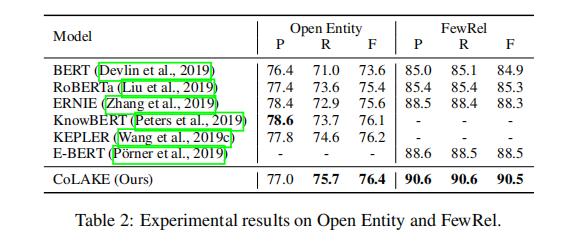
CoLAKE模型在知识导向类任务(entity typing和relation extraction任务)上表现都超越了其他融合知识图谱的预训练模型,实验结果如下图所示:
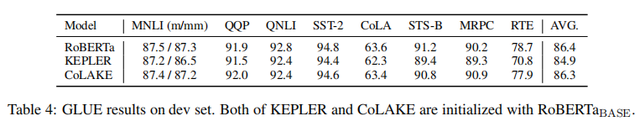
同时,CoLAKE在语言理解类的任务(GLUE)[4]上表现与未加入知识图谱的Roberta模型相当,且优于同样用Roberta初始化训练KEPLER模型效果(加入了知识图谱的KEPLER在语言理解类任务上效果会变差的更为明显),实验结果如下图所示。
因此由此得出结论,CoLAKE可以通过异构的WK graph同时模型化文本和知识。
总而言之,文中的实验结果表明CoLAKE可以在知识导向的任务上提升模型性能,并且在语言理解类任务上获得与原本的预训练模型相当的效果。
另外,作者还设计了一个word-knowledge graph completion的任务来探索CoLAKE在模型化结构特征上的能力,分别通过直推式的设定和归纳式的设定来进行任务训练,输出是三元组中的实体或者关系。简单来说就是,通过输入三元组
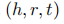
直推式的设定指h,r,t都分别出现在训练集中,但是这个三元组组合没有出现在训练集中;归纳式的设定是指h和t至少有一个实体并未出现在训练集中。
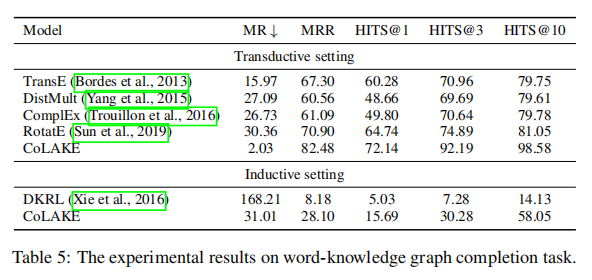
作者也将CoLAKE与常见的集中知识图谱嵌套训练的模型进行了效果比较,如下图所示,效果也是赶超了其他知识图谱嵌套模型。
04 结论和未来研究方向
CoLAKE模型实现了非结构化的语言表征和结构化的知识表征同步综合训练。其通过一种统一化的数据结构word-knowledge graph实现了语言上下文和知识上下文的融合。实验结构表明CoLAKE模型在知识导向类NLP任务上的有效性。
除此之外,作者还通过设计一种WK graph complication的任务来探索了WK graph的应用潜力和未来的研究方向:
(1)CoLAKE可以用于关系抽取中远距离标注样例的去噪。
(2)CoLAKE可以用于检测graph-to-text模板的效果。
参考文献
[1] Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. ERNIE: enhanced language representation with informative entities. In ACL, pages 1441–1451
[2]Matthew E. Peters, Mark Neumann, Robert L. Logan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A.
Smith. 2019. Knowledge enhanced contextual word representations. In EMNLP-IJCNLP, pages 43–54.
[3]Antoine Bordes, Nicolas Usunier, Alberto Garc´ıa-Dur´an, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In NIPS.
[4]Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019a. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In ICLR.
CoLAKE: 如何实现非结构性语言和结构性知识表征的同步训练的更多相关文章
- Spring Cloud Netflix多语言/非java语言支持之Spring Cloud Sidecar
Spring Cloud Netflix多语言/非java语言支持之Spring Cloud Sidecar 前言 公司有一个调研要做,调研如何将Python语言提供的服务纳入到Spring Clou ...
- Dynamics CRM2015 非基础语言环境下产品无法新建的问题
该现象出现在2015版本上,之前从没注意过这个问题不知道以前的版本是否存在. 我的安装包的基础语言是中文,第一张图有添加产品的按钮,切换到英文环境下后就没有了,一开始以为是系统做了隐藏处理,但用工具查 ...
- 解释性语言和非解释性语言,GIL锁
解释性语言:python写的代码就被称为程序,cpu硬件能运行二进制代码指令.demo.py需要经过python解释器编译才做才能执行. 非解释性语言:例如c语言程序,同样需要写代码.demo.c这个 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- Java学习-033-JavaWeb_002 -- 网页标记语言JSP基础知识
JSP 是 Sun 公司提倡的一门网页技术标准.在 HTML 文件中,加入 Java 代码就构成了 JSP 网页,当 Web 服务器访问 JSP 请求的时候,首先执行其中的 Java 程序源码,然后以 ...
- C语言指针入门知识
C语言指针往往是C语言学习过程中最困难的地方, 最近重新理解了一下C语言的指针知识, 在此整理一下, 如果有错误请留言指正. 对于刚入门的人来说, 指针涉及方方面面, 从简单的数组到结构体, 都会用到 ...
- 传统Java Web(非Spring Boot)、非Java语言项目接入Spring Cloud方案
技术架构在向spring Cloud转型时,一定会有一些年代较久远的项目,代码已变成天书,这时就希望能在不大规模重构的前提下将这些传统应用接入到Spring Cloud架构体系中作为一个服务以供其它项 ...
- 传统Java Web(非Spring Boot)、非Java语言项目接入Spring Cloud方案--temp
技术架构在向spring Cloud转型时,一定会有一些年代较久远的项目,代码已变成天书,这时就希望能在不大规模重构的前提下将这些传统应用接入到Spring Cloud架构体系中作为一个服务以供其它项 ...
- 与非java语言使用RSA加解密遇到的问题:algid parse error, not a sequence
遇到的问题 在一个与Ruby语言对接的项目中,决定使用RSA算法来作为数据传输的加密与签名算法.但是,在使用Ruby生成后给我的私钥时,却发生了异常:IOException: algid parse ...
随机推荐
- Argo 安装和 workflow 实例配置文件解析
一.Argo 安装配置 1.1 Argo 安装 $ kubectl create ns argo $ kubectl apply -n argo -f https://raw.githubuserco ...
- Idea Error:java: System Java Compiler was not found in classpath:
前言 这个问题和IDEA的版本有关系,或者有时不小心把项目错误操作了一步,导致出现,这个属于常见错误 解决办法 1:关闭项目,找一个正常运行的项目,将其.idea..mvn文件夹拷贝出来,替换到不能运 ...
- laravel操作Redis排序/删除/列表/随机/Hash/集合等方法全解
Song • 3563 次浏览 • 0 个回复 • 2017年10月简介 Redis模块负责与Redis数据库交互,并提供Redis的相关API支持: Redis模块提供redis与redis.con ...
- 编写PHP扩展
转载请注明来源:https://www.cnblogs.com/hookjc/ PHP 5.2 环境的扩展(PHP Extension) 需求:比如开发一个叫做 heiyeluren 的扩展,扩展里 ...
- CentOS 6.4x64安装部署zabbix-2.4.5
以下内容来自于http://www.iyunv.com/thread-62087-1-1.html 补充一点,按照原文安装万之后zabbix页面会提示 zabbix server is not run ...
- array_intersect_key 取得需要字段 用法
$need_key = [ 'hash' => 0 ]; $parma = array_intersect_key( $parmas, $need_key );
- Java线程--CyclicBarrier使用
原创:转载需注明原创地址 https://www.cnblogs.com/fanerwei222/p/11867687.html Java线程--CyclicBarrier使用, 代码里头有详细注释: ...
- Spring中声明式事务的几个属性的解释
声明式事务 @Transactional (通常用在service层)事务属性:传播行为,隔离级别,回滚,只读,过期 1,spring支持事务传播行为:propagation(常用以下两个) ① ...
- OSI七层协议&TCP协议(三次握手四次挥手)
今日内容 python 基础回顾 软件开发架构 网络理论前戏 OSI 七层协议(五层) TCP协议 三次握手与四次挥手 UDP协议 内容详细 一.python 基础回顾 1.基本数据类型 整型 int ...
- python迭代器对象及异常处理
内容概要 内置函数(可与匿名函数一起使用) 可迭代对象 迭代器对象 for循环内部原理 异常处理 内容详细 一.内置函数 # 1. map() 映射 l1 = [1, 3, 5, 7, 9] res ...