Mysql通过Canal同步Elasticsearch
版本管理
mysql: 8.0
Elasticsearch 7.9.2
Canal v1.1.5
Canal-Adapter v1.1.5
Canal 参考官网: https://github.com/alibaba/canal
Mysql 设置
在MySQL配置文件my.cnf设置:
- 应该是 vi 或者 vim 无法使用,使用 docker copy 来解决
docker exec -it [id] /bin/bash // 进入容器
# 本地创建
vim mysqld.cnf // 修改mysql配置
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
docker copy /root/mysqld.cnf 容器id/etc/mysql/
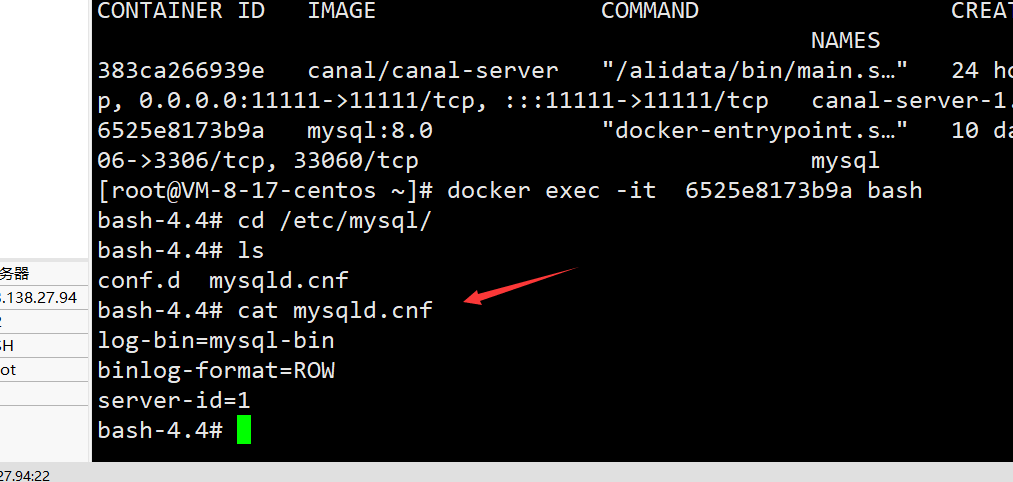
检查是否开启
# 查看是否开启binlog模式
show variables like 'log_bin%';
# 查看binlog日志文件列表
show variables like 'binlog_format%';
# 查看当前正在写入的binlog文件:
SHOW master STATUS;
# 重置
reset master;
增加新用户:
CODE
# 添加用户并设置密码
CREATE USER canal IDENTIFIED BY 'canal';
# 授权
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
#重新加载权限
FLUSH PRIVILEGES;
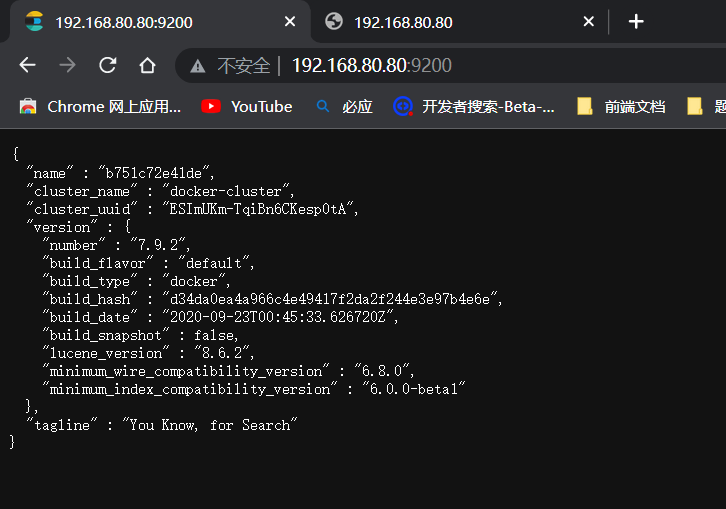
安装 Elasticsearch
# 下载elasticsearch镜像
docker pull elasticsearch:7.9.2
# //启动elasticsearch
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx1g" elasticsearch:7.9.2
# //进入elasticsearch容器
docker exec -it elasticsearch /bin/bash
# 安装ik分词器(服务器下载失败可能是内存炸了)
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.2/elasticsearch-analysis-ik-7.9.2.zip
es 跨域问题
docker exec -it elasticsearch /bin/sh
vi config/elasticsearch.yml
cluster.name: "docker-cluster"
network.hosts:0.0.0.0
# 跨域
http.cors.allow-origin: "*"
http.cors.enabled: true
目录挂载
# 授予权限,不然启动失败
chmod 777 /home/haha/mydata/elasticsearch/data
docker run -d --name elasticsearch --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx1g" -v /home/haha/mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -v /home/haha/mydata/elasticsearch/data:/usr/share/elasticsearch/data elasticsearch:7.9.2
安装 Elasticsearch-Head
解决 es 跨域连接问题
docker exec -it elasticsearch /bin/sh
vi config/elasticsearch.yml
cluster.name: "docker-cluster"
network.hosts:0.0.0.0
# 跨域
http.cors.allow-origin: "*"
http.cors.enabled: true
启动 es-head
docker run -d \
--name=elasticsearch-head \
-p 9100:9100 \
mobz/elasticsearch-head:5-alpine
解决 es-head 无法创建索引
进入elasticsearch-head容器内
docker exec -it elasticsearch-head /bin/sh
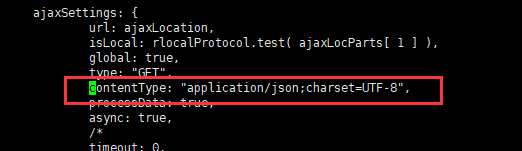
vi _site/vendor.js
将第6886行
contentType: "application/x-www-form-urlencoded",
改为
contentType: "application/json;charset=UTF-8",
将第7574行
var inspectData = s.contentType === "application/x-www-form-urlencoded" &&
改为
var inspectData = s.contentType === "application/json;charset=UTF-8" &&

重启,可以清一下浏览器缓存
exit
docker restart elasticsearch-head
安装 Canal
可以参考:
https://blog.csdn.net/qq_32836247/article/details/116561732
- 2 G的服务器搞不来
安装镜像
# 拉取镜像
$ docker pull canal/canal-server:v1.1.5
# 随便启动一个,用于拉取配置文件
$ docker run --name canal -p 11111:11111 -d canal/canal-server:v1.1.5
# 挂载配置文件
$ docker cp canal:/home/admin /home/haha/docker-canal
# 删除容器
$ docker stop canal
$ docker rm canal
# 启动新的容器
$ docker run --name canal -p 11111:11111 -v /home/haha/docker-canal:/home/admin -d canal/canal-server:v1.1.5
编写配置文件
# 切换到挂载目录
$ cd /usr/kang/docker-canal
# 切换到需要修改的配置文件所在目录
$ cd canal-server/conf/example/
# 修改文件
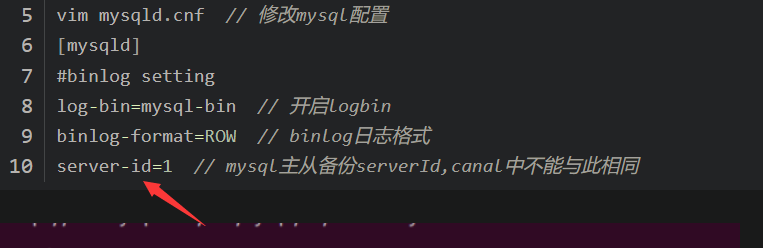
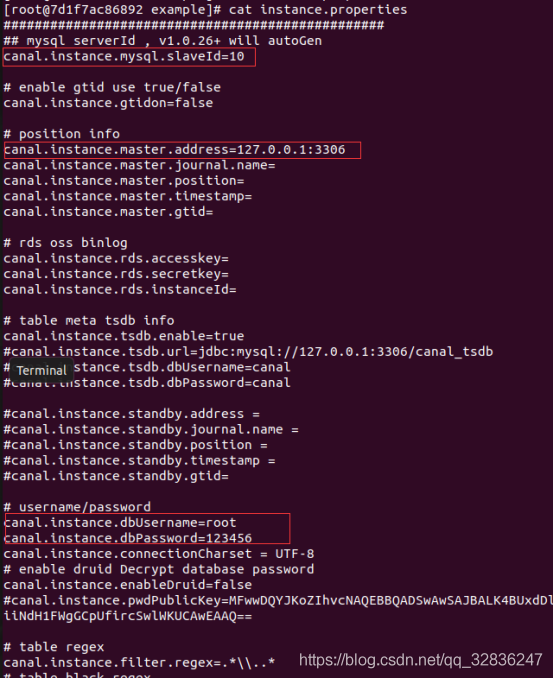
$ vim instance.properties
更改 slaveId=10 ,记得和数据库的 server-id 不一样
更改数据库地址
canal.instance.mysql.slaveId=0
canal.instance.master.address=192.168.80.80:3306
canal.instance.dbUsername=root
canal.instance.dbPassword=123456789
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
# 数据库地址
canal.instance.master.address=192.168.118.130:3306
# 当前正在写入的 binlog文件,第二部分中mysql命令可查询
canal.instance.master.journal.name=binlog.000001
# 正在写入的偏移量
canal.instance.master.position=156
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
# mysql 用户,若之前创建过可不用修改
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
问题:
# 下面是挂在的目录,需要授权,不然挂在出来,里面拒绝访问
chmod 777 /home/haha/docker-canal/

PUT /area_city
{
"mappings": {
"properties": {
"id":{
"type": "long"
},
"pid":{
"type": "integer"
},
"deep":{
"type": "integer"
},
"name":{
"type": "text"
},
"pinyin_prefix":{
"type": "text"
},
"pinyin":{
"type": "text"
},
"ext_id":{
"type": "text"
},
"ext_name":{
"type": "text"
}
}
}
}
安装 Canal-Adapter
安装镜像
BASH
# 拉取镜像
$ docker pull slpcat/canal-adapter:v1.1.5
# 随意启动,用于挂载配置文件
$ docker run --name canal-adapter -p 8081:8081 -d slpcat/canal-adapter:v1.1.5
# 创建存储挂载的目录
$ mkdir /usr/kang/docker-canal-adapter
# 挂载文件
$ docker cp canal-adapter:/opt/canal-adapter /home/haha/docker-canal-adapter
# 删除容器
$ docker stop canal-adapter
$ docker rm canal-adapter
# 建议添加权限
chmod 777 /home/haha/docker-canal-adapter
# 启动新的容器
$ docker run --name canal-adapter -p 8081:8081 -v /home/haha/docker-canal-adapter/canal-adapter:/opt/canal-adapter -d slpcat/canal-adapter:v1.1.5
配置canal-adapter 文件'
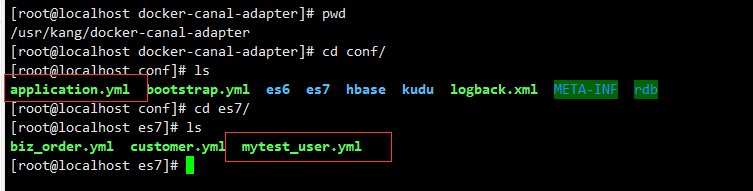
需要修改的是,conf目录下的 applicatiopn.yml 、es7目录下的 mytest_user.yml
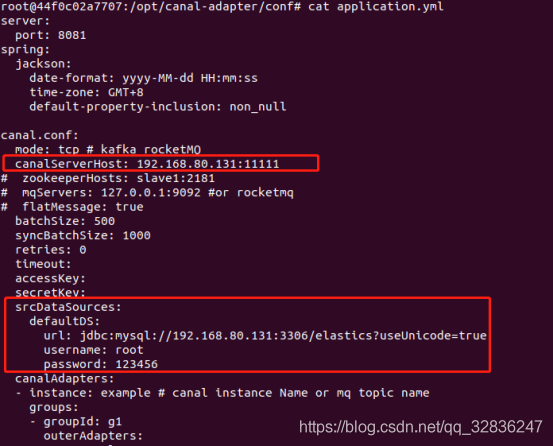
编辑 application.yml:

BASH
# 切换到挂载目录
$ cd /home/haha/docker-canal-adapter/canal-adapter
$ cd conf/
$ vim application.yml
YAML
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer 编辑此处为 canal.deployer 的地址,canal.deployer的默认端口为 11111
# 用于获取 canal 的数据进行实时同步
canal.tcp.server.host: 192.168.80.80:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
# kafka.bootstrap.servers: 127.0.0.1:9092
# kafka.enable.auto.commit: false
# kafka.auto.commit.interval.ms: 1000
# kafka.auto.offset.reset: latest
# kafka.request.timeout.ms: 40000
# kafka.session.timeout.ms: 30000
# kafka.isolation.level: read_committed
# kafka.max.poll.records: 1000
# rocketMQ consumer
# rocketmq.namespace:
# rocketmq.namesrv.addr: 127.0.0.1:9876
# rocketmq.batch.size: 1000
# rocketmq.enable.message.trace: false
# rocketmq.customized.trace.topic:
# rocketmq.access.channel:
# rocketmq.subscribe.filter:
# rabbitMQ consumer
# rabbitmq.host:
# rabbitmq.virtual.host:
# rabbitmq.username:
# rabbitmq.password:
# rabbitmq.resource.ownerId:
srcDataSources:
defaultDS: # 修改此处为 数据库信息
url: jdbc:mysql://192.168.80.80:3306/estest?useUnicode=true
username: root
password: 123456789
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
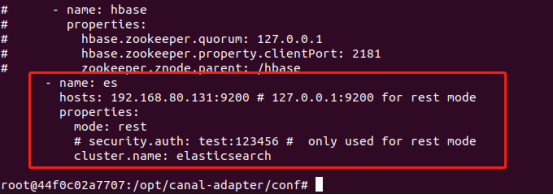
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
- name: es7 # es7文件夹配置,还有es6
# key: fgnKey
hosts: 192.168.80.80:9200 # 127.0.0.1:9200 for rest mode es 集群地址, 逗号分隔
properties:
mode: rest # or rest 可指定transport模式或者rest模式
# # security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch #指定es的集群名称
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
修改mytest_user.yml 文件
- 在 es7 文件夹
dataSourceKey: defaultDS #源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # cannal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: area_city # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
upsert: true
pk: id # 如果不需要_id, 则需要指定一个属性为主键属性
# sql映射
sql: "SELECT id AS _id, pid, deep, name, pinyin_prefix, pinyin, ext_id, ext_name FROM area_city"
# objFields:
# _labels: array:;
etlCondition: "where a.c_time>={}" # etl 的条件参数
commitBatch: 3000 # 提交批大小
sql 映射中的 sql语句,为 id 其别名为 _id 不然在同步时为出错
sql 字段不要写 `` 不然会有问题,这个折磨我好久,
编写完成重启容器:
BASH
$ docker restart canal-adapter
测试
同步全量数据
postman 或者 xshell
curl http://localhost:8081/etl/es7/mytest_user.yml -X POST
创建表
CREATE TABLE `area_city` (
`id` bigint(20) NOT NULL COMMENT '城市编号',
`pid` int(11) NOT NULL COMMENT '上级ID',
`deep` int(11) NOT NULL COMMENT '层级深度;0:省,1:市,2:区,3:镇',
`name` varchar(255) NOT NULL COMMENT '城市',
`pinyin_prefix` varchar(255) NOT NULL COMMENT 'name的拼音前缀',
`pinyin` varchar(255) NOT NULL COMMENT 'name的完整拼音',
`ext_id` varchar(50) NOT NULL COMMENT '数据源原始的编号;如果是添加的数据,此编号为0\r\n',
`ext_name` varchar(255) NOT NULL COMMENT '数据源原始的名称,为未精简的名称\r\n'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
表要创建在 application.yml 所设置的数据库中
创建 es 索引
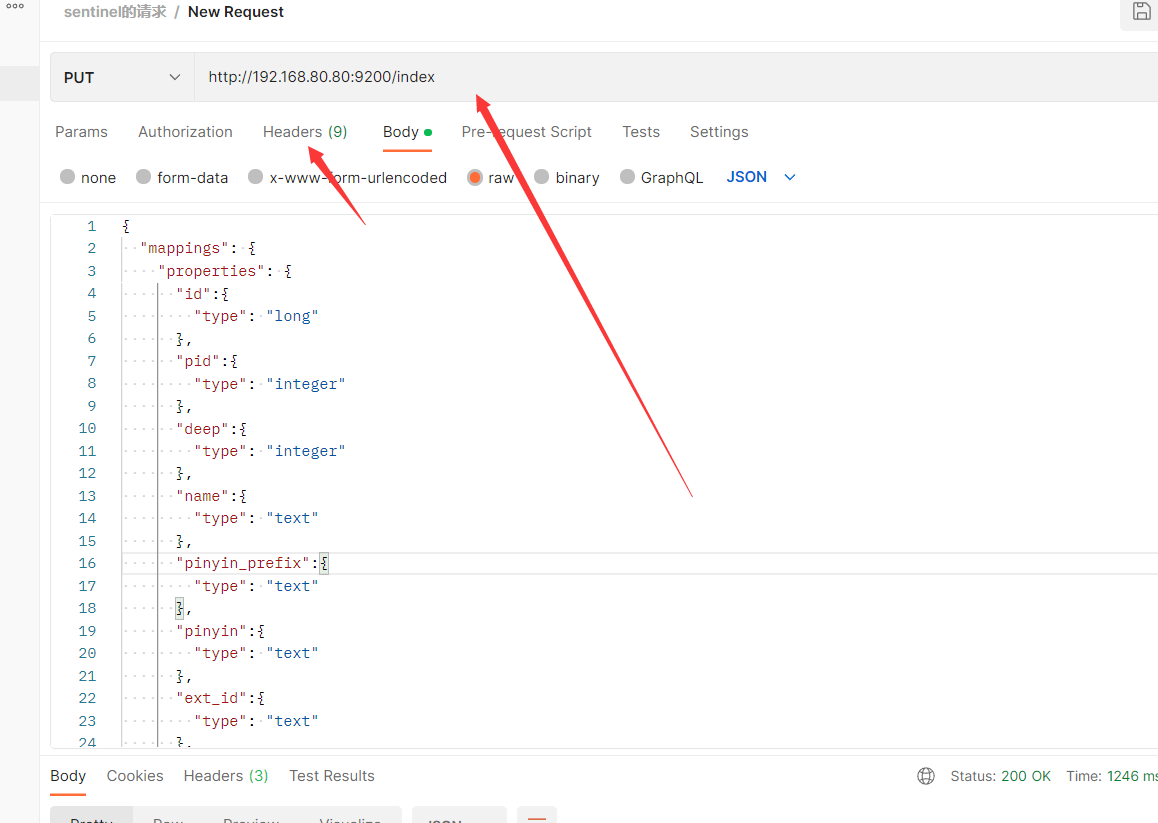
PUT /index
{
"mappings": {
"properties": {
"id":{
"type": "long"
},
"pid":{
"type": "integer"
},
"deep":{
"type": "integer"
},
"name":{
"type": "text"
},
"pinyin_prefix":{
"type": "text"
},
"pinyin":{
"type": "text"
},
"ext_id":{
"type": "text"
},
"ext_name":{
"type": "text"
}
}
}
}
Mysql通过Canal同步Elasticsearch的更多相关文章
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
- 使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
本文介绍如何使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch. 1.go-mysql-elasticsearch简介 go-mysql-elasti ...
- 使用logstash同步mysql数据库信息到ElasticSearch
本文介绍如何使用logstash同步mysql数据库信息到ElasticSearch. 1.准备工作 1.1 安装JDK 网上文章比较多,可以参考:https://www.dalaoyang.cn/a ...
- Mysql数据同步Elasticsearch方案总结
Mysql数据同步Elasticsearch方案总结 https://my.oschina.net/u/4000872/blog/2252620
- canal整合springboot实现mysql数据实时同步到redis
业务场景: 项目里需要频繁的查询mysql导致mysql的压力太大,此时考虑从内存型数据库redis里查询,但是管理平台里会较为频繁的修改增加mysql里的数据 问题来了: 如何才能保证mysql的数 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第四篇:使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
文章转载自: https://www.cnblogs.com/dalaoyang/p/11018541.html 1.go-mysql-elasticsearch简介 go-mysql-elastic ...
- mysql+canal+kafka+elasticsearch构建数据查询平台
1. 实验环境 CPU:4 内存:8G ip:192.168.0.187 开启iptables防火墙 关闭selinux java >=1.5 使用yum方式安装的java,提前配置好JAVA_ ...
- Canal 同步异常分析:Could not find first log file name in binary log index file
文章首发于[博客园-陈树义],点击跳转到原文Canal同步异常分析:Could not find first log file name in binary log index file. 公司搜索相 ...
- Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾 ...
随机推荐
- Docker Compose之容器编排开发初探
1.前言 Docker Compose 是 Docker 官方编排(Orchestration)项目之一,负责快速在集群中部署分布式应用. Compose 是一个用于定义和运行多个 Docker 应用 ...
- LuoguP2523 [HAOI2011]Problem c(概率DP)
傻逼概率\(DP\),熊大坐这,熊二坐这,两熊体积从右往左挤,挤到\(FFF\)没座位了就不合理了 否则就向左歇斯底里爬,每个\(FFF\)编号就组合一下,完闭 #include <iostre ...
- ceph 007 双向池同步 rgw对象网关配置 s3对象存储
增量导入导出要基于快照 导出的过程当中害怕镜像被修改所以打快照.快照的数据是不会变化的 镜像级别的双向同步 镜像主到备,备到主.一对一 就算是池模式的双向同步,镜像也具有主备关系 双向同步,池模式 [ ...
- poi生成表格自动合并单元格
直接复制这个工具类即可使用: /** * 合并单元格 * @author tongyao * @param sheet sheet页 * @param titleColumn 标题占用行 * @par ...
- Matery主题添加Pjax
如何给matery主题添加Pjax? Pjax优点 1.减轻服务端压力 2.按需请求,每次只需加载页面的部分内容,而不用重复加载一些公共的资源文件和不变的页面结构,大大减小了数据请求量,以减轻对服务器 ...
- HTML+JS+CSS 实现随机跳转到一个网址
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta http ...
- centOS7.x修改root密码
方法一: 在开机的时候选中这一行(注意光标要进入虚拟机),然后按下e键 然后找到这一行(linux 16开头的)其中的ro,将其改为 rw init=sysroot/bin/sh 按ctrl+x执行 ...
- 第九十六篇:恶补JS基础
好家伙,来补基础啦,补JS的基础 先来一些概念性的东西 1.什么是JavaScript? javaScript的简写形式就是JS,一种广泛用于客户端Web开发的脚本语言,常用来给HTML网页添加动态 ...
- 第二十四篇:对于dom的理解
好家伙, HTML CSS JS structure style function 结构体 样式 功能 <> ...
- KDB_Database_Link 使用介绍
kdb_database_link 是 KingbaseES 为了兼容oracle 语法而开发的跨数据库访问扩展,可用于访问KingbaseES, Postgresql , Oracle .以下分别介 ...