即兴小探华为开源行业领先大数据虚拟化引擎openLooKeng
@
概述
定义
openLooKeng 官网地址 https://openlookeng.io
openLooKeng 官网中文文档 https://docs.openlookeng.io/zh/docs/docs/overview.html
openLooKeng GitHub源码地址 https://github.com/openlookeng
openLooKeng是业界著名由华为开源的、开箱即用、面向大数据库的数据虚拟化引擎,支持在任何地点、数据进行原位分析的,其宗旨是让数据治理、大数据使用更简单。最新版本为v1.8.0
- openLooKeng提供统一 SQL 接口:具备跨数据源/数据中心分析能力以及面向交互式、批、流等融合查询场景,常用于用于数据探索、即席查询;其处理性能在同等条件下对标 Presto、Impala、Spark都处于明显优势。
- 高性能交互式查询能力:底层借助于开源 SQL 引擎 Presto 来提供交互式查询分析基础能力,源自开源而领先开源,无需移动数据,具有100+毫秒至分钟级的近实时时延。
- openLooKeng具有高可用性、自动伸缩、内置缓存和索引支持。
- openLooKeng支持层次化部署,使地理上远程的openLooKeng集群能够参与相同的查询。利用其跨区域查询计划优化能力,涉及远程数据的查询可以达到接近“本地”的性能。

背景
RDBMS(如MySQL、Oracle等)、NoSQL(如HBase、ES、Kafka等)等数据管理系统广泛用于客户的各种应用系统中。随着数据量的增加,数据管理越来越完善,客户逐步基于Hive或MPPDB建立数据仓库。这些数据存储系统往往相互隔离,形成相互独立的数据孤岛。数据分析师经常遇到以下问题:
- 面对海量数据,如果不知道数据用在哪里,怎么用,就无法基于海量数据构建新的业务模型。
- 查询不同的数据源,需要不同的连接方式或客户端,运行不同的SQL方言。这些差异导致额外的学习成本和复杂的应用开发逻辑。
- 如果数据没有聚合,则无法对不同系统的数据执行联合查询。
异构数据源多,语法差异大,使用不方便;数据ETL费时费力,降低分析效率;
大部分的企业在面向大数据应用面临的用数难、找数难、取数难的痛点:
- 用数难:在大数据的生态下会有很多的引擎、框架或组件,比如说有面向OLTP、 OLAP 、ROLAP、MOLAP,同时 Hadoop分布式文件系统和基于 NoSQL 分布式数据库,开发的组件越多、导致使用和开发成本明显增加。
- 找数难:大部分企业没有做完整数据治理前的数据都是比较分散、管理复杂高、流动性差,查询效率低。
- 取数难:在跨源分析场景经常要从一个数据源导到另一个数据源,导致数据存在多份拷贝,数据迁移效率也较低。
openLooKeng的出现正是为了打破数据壁垒、数据孤岛的僵局并快速实现数据的价值,实现用数极简,找数极速,取数高效的目的。

特点
- 跨数据中心数据分析:统一的SQL接口访问跨数据中心、跨云的数据源。
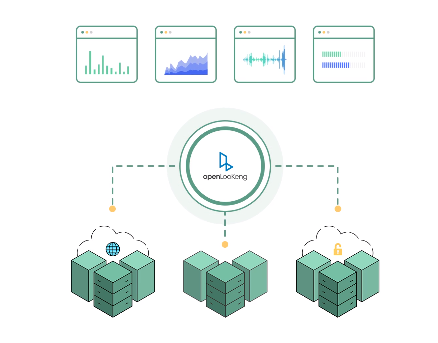
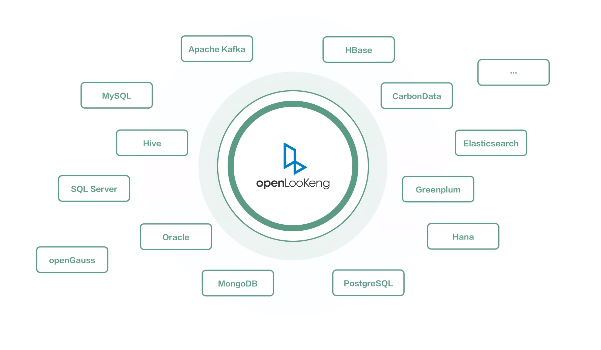
- 极简的跨源数据分析体验:统一的SQL接口访问多种数据源。
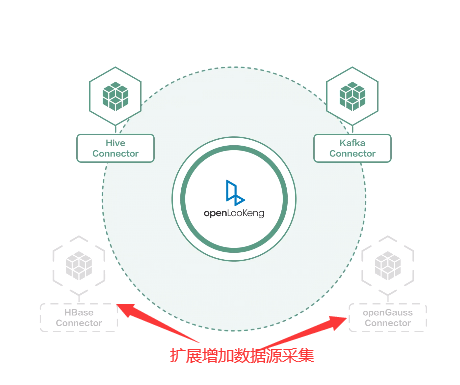
- 易扩展数据源:可以通过增加Connector来增加数据源采集变连接、数据零搬迁。
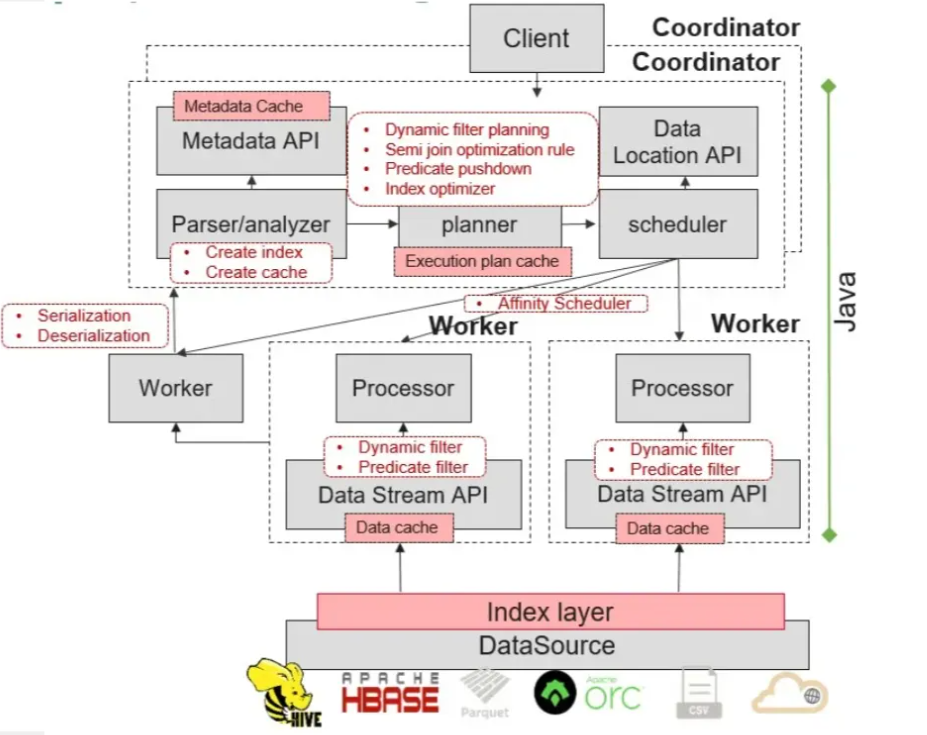
架构
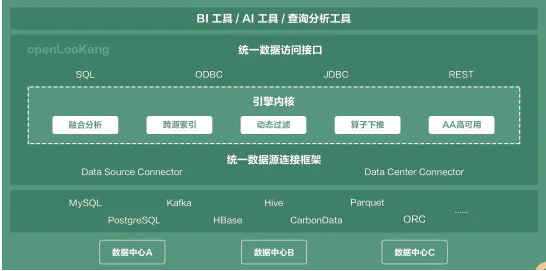
openLooKeng与数据源、客户端的承接架构如下:

openLooKeng内部的核心架构如下:

openLooKeng是一个向量化的存储引擎,基于内存的流水线处理。
openLooKeng与Impala类似为典型的MPP数据库架构,主要由 Coordinator 和 Worker 组成,每个openLooKeng集群安装必须有一个openLooKeng Coordinator节点,以及一个或多个openLooKeng Worker节点。
- Coordinator (协调节点):负责解析语句、规划查询和管理openLooKeng工作节点的服务器。其是openLooKeng的“大脑”,也是客户端连接以提交语句执行的节点。协调节点跟踪每个Worker节点上的活动,并协调查询的执行。协调节点创建了一个查询的逻辑模型,其中包含一系列阶段,然后将其转换为在openLooKeng工作节点集群上运行的一系列相互连接的任务。协调节点使用REST API与工作节点和客户端进行通信。
- Worker (工作节点):负责执行任务和处理数据。Worker节点从连接器获取数据,并相互交换中间数据。Coordinator 节点负责从Worker节点获取结果,并将最终结果返回给客户端。当openLooKeng Worker节点进程启动时,它会将自己通告给Coordinator 节点中的发现服务器,这样openLooKeng Coordinator 节点就可以使用它来执行任务。Worker节点使用REST API与其他Worker节点和openLooKeng Coordinator 进行通信。
openLooKeng引入了高可用的AA特性,支持Coordinator AA双活机制,能够保持多个Coordinator之间的负载均衡,同时也保证了openLooKeng在高并发下的可用性。
openLooKeng的弹性伸缩特性支持将正在执行任务的服务节点平稳退服,同时也能将处于不活跃状态的节点拉起并接受新的任务。openLooKeng通过提供“已隔离”与“隔离中”等状态接口供外部资源管理者(如Yarn、Kubernetes等)调用,从而实现对Coordinator和Worker节点的弹性扩缩容。
openLooKeng统一目录、跨域跨DC查询:通过Data Source Connector和Data Center Connector两大统一数据源连接框架来实现。
- 并行数据访问:Worker可以并发访问数据源以提高访问效率, 客户端也可以并发从服务端获取数据以加快数据获取速度。
- 数据压缩:在数据传输期间进行序列化之前,先使用GZIP压缩算法对数据进行压缩,以减少通过网络传输的数据量。
- 跨DC动态过滤:过滤数据以减少从远端提取的数据量,从而确保网络稳定性并提高查询效率。
关键技术
- 索引:openLooKeng提供基于openLooKeng启发式索引、Bitmap Index、Bloom Filter、Min-max Index、BTree、HIndex、new-index等索引。通过在现有数据上创建索引,并且把索引结果存储在数据源外部,在查询计划编排时便利用索引信息过滤掉不匹配的文件,减少需要读取的数据规模,从而加速查询过程。
- Cache:openLooKeng提供丰富多样的Cache,包括元数据cache、执行计划cache、ORC行数据cache等。通过这些多样的cache,可加速用户多次对同一SQL或者同一类型SQL的查询时延响应。
- 动态过滤:动态过滤是指是在运行时(run time)将join一侧表的过滤信息的结果应用到另一侧表的过滤器的优化方法,openLooKeng不仅提供了多种数据源的动态过滤优化特性,还将这一优化特性应用到了DataCenter Connector,从而加速不同场景关联查询的性能。
- 算子下推:openLooKeng通过Connector框架连接到RDBMS等数据源时,由于RDBMS具有较强的计算能力,一般情况下将算子下推到数据源进行计算可以获取到更好的性能。openLooKeng目前支持多种数据源的算子下推,包括Oracle、HANA等,特别地,针对DC Connector也实现了算子下推,从而实现了更快的查询时延响应。
应用场景
openLooKeng常用于如下几种场景:
- 跨源异构查询场景:使用openLooKeng实现RDBMS、NoSQL、Hive、MPPDB等数据仓库的联合查询。利用openLooKeng的跨源异构查询能力,数据分析师可以快速分析海量数据。
- 跨域跨DC查询:在二级或多级数据中心场景中,例如省-市数据中心或总部-分部数据中心,用户经常需要从省(总部)数据中心或市(分部)数据中心查询数据。跨域查询的瓶颈是多个数据中心之间的网络问题(例如带宽不足、高时延、丢包等)。因此,查询时延高,性能不稳定。openLooKeng是专为跨域查询设计的跨域跨DC解决方案。openLooKeng集群部署在多个DC中。DC2中的openLooKeng集群完成计算后,通过网络将结果传递给DC1中的openLooKeng集群,在DC1中的openLooKeng集群完成聚合计算。在openLooKeng跨域跨DC方案中,计算结果在openLooKeng集群之间传递。这避免了网络带宽不足和丢包带来的网络问题,在一定程度上解决了跨域查询的问题。
- 存储计算分离:openLooKeng本身没有存储引擎,但可以查询存储在不同数据源中的数据。因此,该系统是一个典型的存储计算分离系统,有利于独立扩展计算和存储系统。openLooKeng存储计算分离架构适用于动态扩展集群,实现资源快速弹性伸缩。
- 快速数据探索:客户拥有大量数据。为了使用这些数据,他们通常会构建专用的数据仓库。但是,这将带来额外的数据仓库维护人力成本和数据ETL时间成本。对于需要快速探索数据,但又不想建设专用数据仓库的客户,复制数据并加载到数据仓库费时费力。openLooKeng可以使用标准SQL定义一个虚拟数据市场,通过跨源异构查询能力连接各个数据源。这样,在虚拟数据市场的语义层中就可以定义出用户需要探索的各种分析任务。借助openLooKeng的数据虚拟化能力,客户可以快速构建基于多种数据源的探索分析服务,无需建设复杂、专用的数据仓库。
相反的由于openLooKeng设计其不适用对实时性要求很高如秒级响应的系统和针对并发要求很高的系统。
安装
openLooKeng支持单机一键部署、手动部署、自动部署,自动部署又包含在线部署、离线部署。下面离线单台集群部署和多台集群部署
单台部署
# 下载 https://download.openlookeng.io/auto-install/openlookeng.tar.gz 并将其内容解压到 /opt 目录。
wget --no-check-certificate https://download.openlookeng.io/auto-install/openlookeng.tar.gz
tar -xvf openlookeng.tar.gz -C /opt/
# 创建目录 /opt/openlookeng/resource 并保存 openLooKeng 执行文件 https://download.openlookeng.io/<version>/hetu-server-<version>.tar.gz 和 https://download.openlookeng.io/<version>/hetu-cli-<version>-executable.jar,其中<version>对应于正在安装的版本,例如1.0.0。
mkdir -p /opt/openlookeng/resource
wget --no-check-certificate https://download.openlookeng.io/1.8.0/hetu-server-1.8.0.tar.gz
wget --no-check-certificate https://download.openlookeng.io/1.8.0/hetu-cli-1.8.0-executable.jar
# 同时将第三方依赖保存在 /opt/openlookeng/resource 目录下。根据本机的架构,下载 https://download.openlookeng.io/auto-install/third-resource/x86/ 或 https://download.openlookeng.io/auto-install/third-resource/aarch64/ 下面的全部文件。这应该包括一个 OpenJDK 文件和两个 sshpass 文件。
wget --no-check-certificate https://download.openlookeng.io/auto-install/third-resource/aarch64/OpenJDK8U-jdk_aarch64_linux_hotspot_8u222b10.tar.gz
wget --no-check-certificate https://download.openlookeng.io/auto-install/third-resource/aarch64/sshpass-1.06-1.el7.aarch64.rpm
wget --no-check-certificate https://download.openlookeng.io/auto-install/third-resource/aarch64/sshpass-1.06.tar.gz
# 执行离线
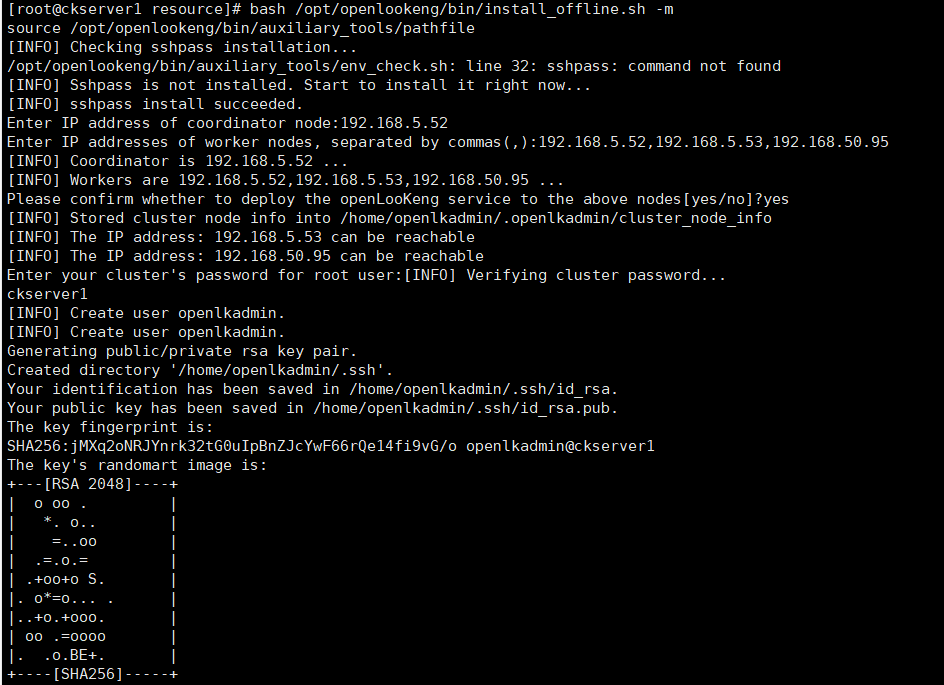
bash /opt/openlookeng/bin/install_offline.sh

集群部署
集群部署裕单台部署类似
# 将openlookeng.tar.gz文件和资源文件分发到其他服务器
scp -r /opt/openlookeng server2:/opt/
scp -r /opt/openlookeng server3:/opt/
# 执行离线,等待几分钟时间待三个节点完成部署
bash /opt/openlookeng/bin/install_offline.sh -m
命令行接口
# openLooKeng CLI提供了一个基于终端的交互shell,用于运行查询。CLI是一个可执行的JAR文件,可以通过java -jar ./hetu-cli-*.jar执行。下载于服务器对应版本的 CLI 文件,例如:hetu-cli-1.0.0-executable.jar,运行:
java -jar ./hetu-cli-1.0.0-executable.jar --server localhost:8080 --catalog hive --schema default
# 也可以直接运行openlk-cli,相当于java -jar /opt/openlookeng/resource/hetu-cli-*-executable.jar --server localhost:8090
/opt/openlookeng/bin/openlk-cli
# 使用--help选项运行CLI,查看可用选项。
# 默认情况下,使用less程序将查询结果分页,该程序配置了一组精心选择的选项。可以通过将环境变量OPENLOOKENG_PAGER设置为其他程序的名称(如more)或将其设置为空值来完全禁用分页来覆盖此行为
连接器
openLooKeng中可用的连接器,用于访问不同数据源的数据。官方提供非常丰富连接器供使用

MySQL连接器
MySQL连接器允许在外部MySQL数据库中查询和创建表。可用于在MySQL和Hive等不同系统之间或在两个不同的MySQL实例之间联接数据。
要配置MySQL连接器,在/opt/openlookeng/data/etc/catalog目录下创建一个目录属性文件,将MySQL连接器挂载为mysql目录。使用以下内容创建文件,并根据设置替换连接属性。
vim mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://192.168.50.100:3306
connection-user=root
connection-password=12345678
#true表示打开下推,false表示关闭。默认是打开的
jdbc.pushdown-enabled=true
#FULL_PUSHDOWN,表示全部下推;BASE_PUSHDOWN,表示部分下推,其中部分下推是指filter/aggregation/limit/topN/project这些可以下推。
jdbc.pushdown-module=FULL_PUSHDOWN
# 重启openlookeng
bash /opt/openlookeng/bin/restart.sh
# 退出cli
quit
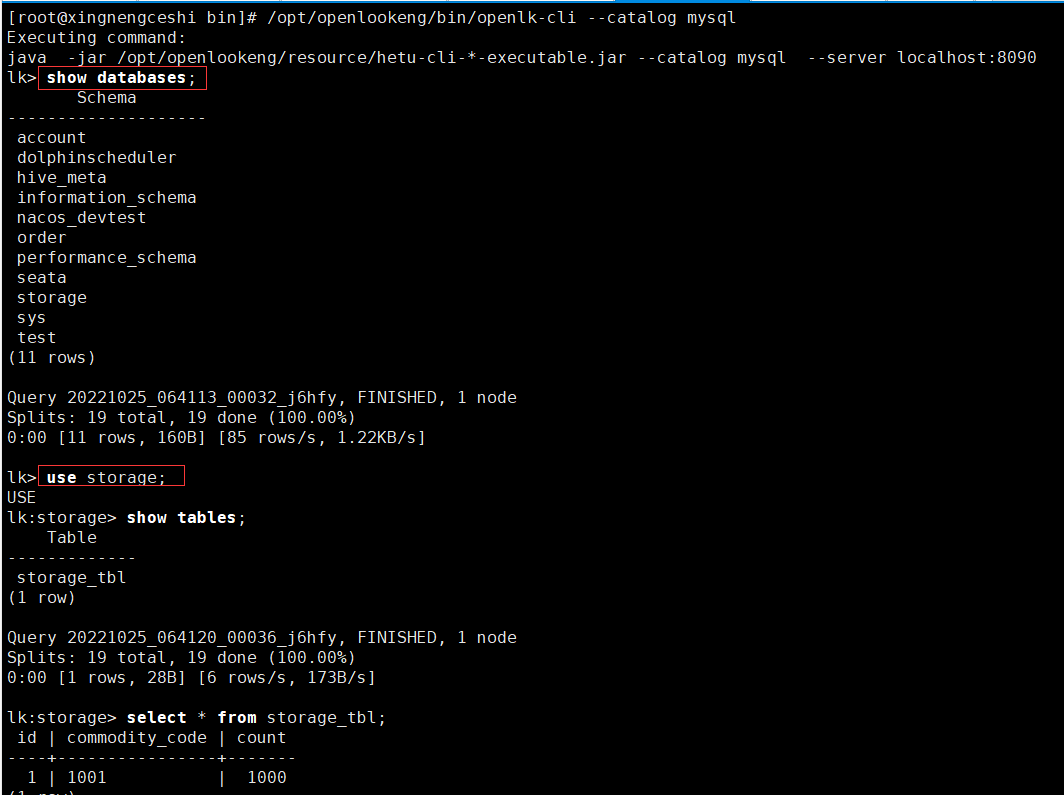
# 指定--catalog mysql连接cli
/opt/openlookeng/bin/openlk-cli --catalog mysql
# 显示数据库,已经为配置的mysql数据库信息
show databases;
# 显示数据表
show tables;
ClickHouse连接器
与MySQL连接器相似,在/opt/openlookeng/data/etc/catalog目录下创建vim clickhouse.properties,
connector.name=clickhouse
connection-url=jdbc:clickhouse://192.168.50.100:8123
connection-user=default
connection-password=
# 是否允许连接器删除表
allow-drop-table=true
# 是否开启查询下推功能。连接器的下推功能默认打开,也可以如下设置:
clickhouse.query.pushdown.enabled=true
# 是否区分表名大小写,与openLooKeng不同,ClickHouse的语法是大小写敏感的,如果您的数据库表中存在大写字段,可以按如下设置。
case-insensitive-name-matching=true
# 重启openlookeng
bash /opt/openlookeng/bin/restart.sh
# 指定--catalog mysql连接cli
/opt/openlookeng/bin/openlk-cli
# 通过SHOW SCHEMAS来查看可用的ClickHouse数据库:
SHOW SCHEMAS FROM clickhouse
# 如果有一个名为test的ClickHouse数据库,可以通过执行SHOW TABLES查看数据库中的表:
SHOW TABLES FROM clickhouse.test;
# 若要查看数据模式中名为table1的表中的列的列表,请使用以下命令中的一种:
DESCRIBE clickhouse.test.table1;
SHOW COLUMNS FROM clickhouse.test.table1;
# 查询表数据
SELECT * FROM clickhouse.test.table1;
**本人博客网站 **IT小神 www.itxiaoshen.com
即兴小探华为开源行业领先大数据虚拟化引擎openLooKeng的更多相关文章
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 开发一个不需要重写成Hive QL的大数据SQL引擎
摘要:开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL. 本文分享自华为云社区< ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 大数据计算引擎之Flink Flink CEP复杂事件编程
原文地址: 大数据计算引擎之Flink Flink CEP复杂事件编程 复杂事件编程(CEP)是一种基于流处理的技术,将系统数据看作不同类型的事件,通过分析事件之间的关系,建立不同的时事件系序列库,并 ...
- Hadoop是一种开源的适合大数据的分布式存储和处理的平台
"Hadoop能做什么?" ,概括如下: 1)搜索引擎:这也正是Doug Cutting设计Hadoop的初衷,为了针对大规模的网页快速建立索引: 2)大数据存储:利用Hadoop ...
- 大数据OLAP引擎对比
Presto:内存计算,mpp架构 PB级别数据 presto适合pb级的海量数据查询分析,不是说把pb的数据放进内存,比如一张pb表,查询count,vag这种有个特点,虽然数据很多,但是最终的 ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 爬虫小探-Python3 urllib.request获取页面数据
使用Python3 urllib.request中的Requests()和urlopen()方法获取页面源码,并用re正则进行正则匹配查找需要的数据. #forex.py#coding:utf-8 ' ...
随机推荐
- Apache DolphinScheduler 使用文档(5/8):使用与测试
本文章经授权转载,原文链接: https://blog.csdn.net/MiaoSO/article/details/104770720 目录 5. 使用与测试 5.1 安全中心(Security) ...
- SpringCloud之Sentinel
一. sentinel是什么? 1.概念: 分布式服务架构的流量治理组件. 2.sentinel有什么作用? 2.1 流控:QPS.线程数 2.2 熔断降级:降级-->熔断策略.时长.请求数等 ...
- JUC源码学习笔记5——线程池,FutureTask,Executor框架源码解析
JUC源码学习笔记5--线程池,FutureTask,Executor框架源码解析 源码基于JDK8 参考了美团技术博客 https://tech.meituan.com/2020/04/02/jav ...
- 如何保证遍历parent的时候的task的存在性
在一次crash的排查过程中,有这么一个内核模块,他需要往上遍历父进程, 但是在拿父进程task_struct中的一个成员的时候,发现为NULL了, 具体查看父进程,原来它收到信号退出中. 那么怎么保 ...
- CCPC比赛与算法学习的个人分享
大赛简介 中国大学生程序设计竞赛(China Collegiate Programming Contest,简称CCPC)是工业和信息化部教育与考试中心主办的 "强国杯"技术技能大 ...
- [RootersCTF2019]I_<3_Flask-1|SSTI注入
1.打开之后很明显的提示flask框架,但是未提供参数,在源代码中发现了一个git地址,打开之后也是没有啥用,结果如下: 2.这里我们首先需要爆破出来参数进行信息的传递,就需要使用Arjun这一款工具 ...
- String vs StringBuffer vs StringBuilder
String vs StringBuffer vs StringBuilder 本文翻译自:https://www.digitalocean.com/community/tutorials/strin ...
- luogu [ZJOI2007] 矩阵游戏
[ZJOI2007] 矩阵游戏 题目描述 小 Q 是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏――矩阵游戏.矩阵游戏在一个 \(n \times n\) 黑白方阵进行(如同国际象棋 ...
- Vmware虚拟主机访问外网设置
本手册使用10.4.7.0/24网段 重点在于虚拟主机的网关和宿主机上的Vmnet8的IP和虚拟网络编辑器的NET网关保持一致 1.设置宿主机网络适配器 选择允许Vmware网络共享 配置VMnet8 ...
- Nginx超时问题解决
在 nginx.conf 中配置以下内容 ... http { ... server { # 这里表示upstream 的连接.读取.发送超时时间都是300秒 proxy_connect_timeou ...