核函数(kernel function)
在接触反演、算法等方面的知识后,经常听到“核”这个字,它不像对原始变量的线性变换,也不像类似于机器学习中激活函数那样的非线性变换,对原始数据进行变换,就可以将复杂的问题简单化。接下来,就让我们了解了解“核”这个东西。
参考链接:
注,kernel function 与kernel function指的是同一个东西,可以这样理解:核方法只是一种处理问题的技巧,低维空间线性不可分可以在高维空间线性可分,但是高维空间的计算复杂度又很大,那么我们就把高维空间的计算通过低维空间的计算外加一些线性变换来完成。
还有,都说核方法与映射无关,怎么理解呢?核方法是一种技巧,不管怎么映射,我们都是用低维空间的计算来解决高维空间计算复杂的问题。
1. 问题描述
给定两个向量(x_i)和(x_j),我们的目标是要计算他们的内积\(I\) = <\(x_i\), \(x_j\)>。现在假设我们通过某种非线性变换:\(\Phi : x \rightarrow \phi(x)\)把他们映射到某一个高维空间中去,那么映射后的向量就变成:\(\phi(x_i)\)和\(\phi(x_j)\),映射后的内积就变成:\(I’\) = <\(\phi(x_j)\),\(\phi(x_j)\)>。
现在该如何计算映射后的内积呢?
传统方法是先计算映射后的向量\(\phi(x_i)\)和\(\phi(x_j)\),然后再计算它俩的内积。但是这样做计算很复杂,因为映射到高维空间后的数据维度很高。比如,假设\(x_i\)和\(x_j\)在映射之后都是一个( \(1 \times 10000\))维的向量,那么他们的内积计算就需要做10000次加法操作和10000次乘法操作,显然复杂度很高。
于是,数学家们就想出一个办法:能不能在原始空间找到一个函数\(K(x_i,x_j)\)使得\(K(x_i,x_j) = <\phi(x_j),\phi(x_j)>\)呢? 如果这个函数存在,那么我们只需要在低维空间里计算函数\(K(x_i,x_j)\)的值即可,而不需要先把数据映射到高维空间,再通过复杂的计算求解映射后的内积了。庆幸的是,这样的函数是存在的。这样一来计算的复杂度就大大降低了,这种简化计算的方法被称为核技巧(The Kernel Trick),而函数(K)就是核函数(Kernel Function)。
2. 与SVM的关系
之前的一篇介绍支持向量机的文章里我们说过:支持向量机为了解决数据在低维度不容易线性分割的情况下,会通过某非线性变换 \(\phi(x)\),将输入空间映射到高维特征空间。于是,就得到如下求解公式:
\]
观察上面的公式你会发现里面有一个内积运算
\]
于是,为了降低计算复杂度,解决映射后可能产生的维度爆炸问题,我们在求解的时候引入了核技巧。核技巧并不仅仅应用在SVM中,在其他需要处理高维映射计算的问题中也有很多应用。
3. 常用的核函数
主要有以下几种:
线性核,其实就是没有映射
\[\kappa \left ( x_{1},x_{2} \right ) = \left \langle x{1},x{2} \right \rangle
\]高斯核函数,使用最为广泛,它能够把原始特征映射到无穷维。
\[\kappa \left ( x_{1},x_{2} \right ) = \exp \left ( -\frac{\left | x_{1}-x_{2} \right |^{2}}{2\sigma ^{2}} \right )
\]多项式核函数,它能把数据映射到\(C_{n+d}^{n}\)维。
\[\kappa \left ( x_{1},x_{2} \right ) = \left ( \left \langle x_{1},x_{2} \right \rangle +R\right )^{d}
\]
由此可见:选择什么样的核函数将会决定你把数据映射到什么样的维度。
4. 核函数的满足条件
Mercer 定理:任何半正定的函数都可以作为核函数。所谓半正定的函数\(f(x_i,x_j)\),是指拥有训练数据集合\(x_1,x_2,…x_n\),我们定义一个矩阵的元素\(a_{ij} = f(x_i,x_j)\),这个矩阵是\(n \times n\)的,如果这个矩阵是半正定的,那么\(f(x_i,x_j\))就称为半正定的函数。
这个mercer定理不是核函数必要条件,只是一个充分条件,即还有不满足mercer定理的函数也可以是核函数。
5. 核函数的计算
在上面了解了核函数是什么后,我们已经知道了核函数与内积之间的关系,接下来,从理论上看一看。
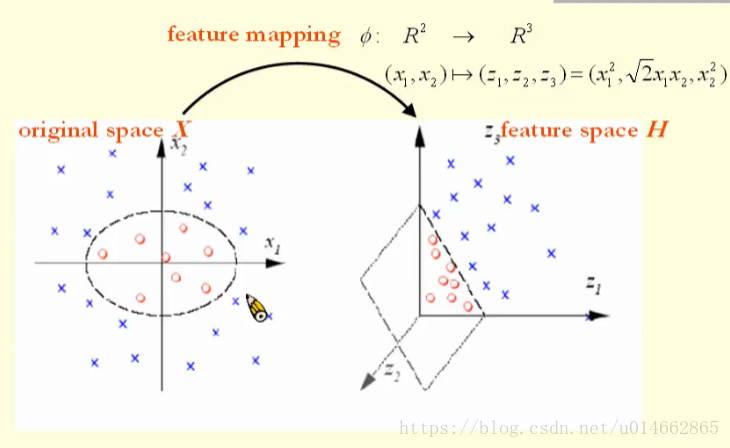
从图中可以看出,在original space的数据,其带有两种标签,如果要将这两种数据分开,必须通过一个椭圆来分开,也就是说,它不是线性可分的;
那么,有什么办法呢?
如图所示,对original space的数据进行feature mapping,从而把数据从\((x_1,x_2)\)的二维空间映射到\((z_1,z_2,z_3)\)的三维空间中,很明显,在三维空间的数据能够很容易的通过一个超平面将数据进行分类,也就是说,该数据在更加高维的空间变得线性可分了。
但是,这和内积有啥关系呢?
比如,在\((x_1,x_2)\)的二维空间中,
\]
也就是说,\(x\)和\(x'\)表示\((x_1,x_2)\)二维空间中的两个点,\(\phi(\cdot)\)表示从二维空间到三维空间的映射函数,则\(x\)和\(x'\)对应的三维空间的点分别为\(\phi(x)\)和\(\phi(x')\)。

接下来,我们从计算上看看线性可分与线性不可分的区别?
如上图所示,对于可以线性可分的数据,数据的类别之间可以由一个超平面分隔开,从图中可以看出来,超平面有很多个满足将数据的两种类别分隔开的条件,因此,我们可以取两种类别数据的质点,对应图中的\(c_-\)和\(c_+\),这两点连线\(\overrightarrow{c_-c_+}\)(对应图中红线),那么最优的超平面就可以取为以\(\overrightarrow{c_-c_+}\)为法向量、过\(\overrightarrow{c_-c_+}\)的中点\(c=\frac{1}{2}(c_-+c_+)\)的那个平面,即\(H(x)=\overrightarrow{c_-c_+}(\phi(x)-c)=w^T(\phi(x)-c)\)。
但是,对于线性不可分的情况,就没有这么好了,我们可以通过机器学习中的激活函数(非线性表示)来学习二分类的边界,学个椭圆不是问题,但是,如果要通过线性可分这样的内积方式获得,显然是不现实的。
内积的具体应用如何?
\(\phi(x)\)和\(\phi(x')\)是低维空间的点\(x\)和\(x'\)映射到高维空间的表示,两点之间的距离为
\]
对于其中的\(<\phi(x),\phi(x')>\)项,可做如下方式展开:
\]
这样,我们就可以得到高维空间两个点的距离、夹角信息,从而可以计算出超平面。
内积在核函数中的应用?
根据上面的分析可知,理论超平面为\(H(x)=\overrightarrow{c_-c_+}(\phi(x)-c)=w^T(\phi(x)-c)\)
转换成内积形式:
\]
其中的\(\kappa(x,x_i)\)表示核函数,即高维空间中两个点的内积。
所谓核函数,就是在原空间上两个点内积的一个函数得到的。
举例如下,
\((x_1,x_2) \rightarrow (z_1,z_2,z_3)=(x_1^2,\sqrt{2}{x_1x_2},x_2^2)\)
\]
从上述公式可以看出,核函数是一个用原有特征空间上点内积的方式通过运算转换成高维空间点内积,而不必完全有高维空间上的点进行计算,从而到达降低运算复杂度的作用。
6. 常用核函数的理解
以高斯核函数为例,
\]
我们假设\(\sigma = 1\),则
\]
这不,已经有了定义的那种形式,对于\(\phi(x)\),由于
\]
所以,可以映射到任何一个维度上。
核函数(kernel function)的更多相关文章
- 核函数(kernel function)
百度百科的解释: 常用核函数: 1.线性核(Linear Kernel): 2.多项式核(Polynomial Kernel): 3.径向基核函数(Radial Basis Function),也叫高 ...
- [转]核函数K(kernel function)
1 核函数K(kernel function)定义 核函数K(kernel function)就是指K(x, y) = <f(x), f(y)>,其中x和y是n维的输入值,f(·) 是从n ...
- Kernel Methods (2) Kernel function
几个重要的问题 现在已经知道了kernel function的定义, 以及使用kernel后可以将非线性问题转换成一个线性问题. 在使用kernel 方法时, 如果稍微思考一下的话, 就会遇到以下几个 ...
- 统计学习方法:核函数(Kernel function)
作者:桂. 时间:2017-04-26 12:17:42 链接:http://www.cnblogs.com/xingshansi/p/6767980.html 前言 之前分析的感知机.主成分分析( ...
- 机器学习——支持向量机(SVM)之核函数(kernel)
对于线性不可分的数据集,可以利用核函数(kernel)将数据转换成易于分类器理解的形式. 如下图,如果在x轴和y轴构成的坐标系中插入直线进行分类的话, 不能得到理想的结果,或许我们可以对圆中的数据进行 ...
- kernel function
下面这张图位于第一.二象限内.我们关注红色的门,以及“北京四合院”这几个字下面的紫色的字母.我们把红色的门上的点看成是“+”数据,紫色字母上的点看成是“-”数据,它们的横.纵坐标是两个特征.显然,在这 ...
- svm核函数的理解和选择
https://blog.csdn.net/leonis_v/article/details/50688766 特征空间的隐式映射:核函数 咱们首先给出核函数的来头:在上文中,我们已经了解到了S ...
- coursera机器学习-支持向量机SVM
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Stanford机器学习笔记-8. 支持向量机(SVMs)概述
8. Support Vector Machines(SVMs) Content 8. Support Vector Machines(SVMs) 8.1 Optimization Objection ...
- 支持向量机通俗导论(理解SVM的三层境界)
原文链接:http://blog.csdn.net/v_july_v/article/details/7624837 作者:July.pluskid :致谢:白石.JerryLead 出处:结构之法算 ...
随机推荐
- WPF 使用Path(自定义控件,圆形进度条)
原文:https://www.cnblogs.com/tsliwei/p/5609035.html 原文链接:https://blog.csdn.net/johnsuna/article/detail ...
- UCOS-III笔记
1.单片机程序分类:轮询程序,前后台程序,多任务系统程序 2.多任务系统伪代码 1 int flag1 = 0; 2 int flag2 = 0; 3 int flag3 = 0; 4 5 int m ...
- (03-14) synopsys中工具介绍,VCS,DC,PT等
https://blog.csdn.net/fangxiangeng/article/details/80981536 (1)Nlint 检查,spyglass (2)PT 静态时序检查 (3)Icc ...
- Java pom阿里云插件
<pluginRepositories> <pluginRepository> <id>alimaven spring plugin</id> < ...
- flannel提供的3种后端实现
UDP(flanneld封装和解封装UDP) 实现原理 缺点(性能最差) UDP模式,封装和解封装的对象是三层IP包,提供三层的Overlay网络,是Flannel最早支持的一种方式,也是性能最差的一 ...
- IDEA使用fastjson1时maven引入依赖没报错,但是用不了JSONObject工具类
删除项目下的.idea文件夹重新打开项目就行, 不知道为什么
- jabc连接数据库
Java数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法.JD ...
- PyTables学习 (数据保存形式,对象树结构)
参考自http://www.pytables.org/usersguide/introduction.html PyTables的主要目的是提供一个好的操作HDF5文件的方法. HDF文件是分层数据格 ...
- yaml 文件的读取写
yaml 是一种数据格式, 它可以和json数据相互转化 . 自动化测试中一般用于做配置文件或是测试用例. 数据的组成, 两种格式: 1. 字典 2. 列表 Eg. config.yaml serve ...
- 清空buff/cache
https://blog.csdn.net/qq_34246965/article/details/109258656 1)清理pagecache(页面缓存)echo 1 > /proc/sys ...