在集群上运行Spark应用
初识Spark真的存在很多疑问:Spark需要部署在集群里的每个节点上吗?Spark怎么有这么多依赖,这些依赖分别又有什么用?官网里边demo是用sbt构建的,难道还有再学一下sbt吗? ……就是这么多的问题令人对使用Spark望而生畏,最近总算认真刷了一下官方文档,在这篇blog里汇总整理一下这些问题。
1.如何提交Spark应用
1.1 将应用与依赖打包在一起
如果自己的Spark项目里依赖其他的项目,官方文档建议把项目代码和依赖打包在一起,称为assembly jar(Spark与Hadoop的依赖由于集群中已经有了,所以可以在maven依赖设置的scope中设为provided)。
1.2 使用spark-submit脚本执行应用
[bash] ./bin/spark-submit \ --class <main-class> \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments] [/bash]
- class:作为应用入口的main函数所在的类
- master:集群的URL
- deploy-mode:部署模式分为:cluster与client,在下一节会详细介绍
- conf:key=value格式的Spark配置属性,如果value中包含空格,用引号包起来"key=value"
- application-jar:1.1中打包好的assembly jar,jar包必须是整个集群都可以访问到的,可以是hdfs://或者每个节点上都有的本地文件file://
- application-arguments:可选的传给main函数的参数
1.3 从文件中读取Spark配置
Spark会从主目录下的conf/spark-defaults.conf读取property配置,这样可以避免在1.2中写过于冗长的submit脚本。读取的优先级是:代码中的SparkConf > spark-submit中的配置 > spark-defaults.conf配置文件。
1.4 高级依赖管理
当使用spark-submit时,还可以使用--jars参数添加依赖的jar包,application-jar参数与--jars参数中的jar都需要是整个集群可见的,这里主要推荐使用hdfs的格式。 额外添加的JARs与files将被复制到executor的工作目录下,时间长了将会占用不少空间,好在YARN集群会自动进行清理,而Spark standalone模式也可通过配置spark.worker.cleanup.appDataTtl属性实现自动清理。 spark-shell可以被用来“打草稿”,接受的参数与spark-submit几乎一样,也可添加依赖。
2.Spark应用在集群上是如何运行的?
这里用官方的demo来举例: [bash] # 1.创建如下的目录: $ find . . ./build.sbt ./src ./src/main ./src/main/scala # 2.编辑项目的build.sbt文件(类似于maven的.pom): name := "SparkTest" version := "1.0" scalaVersion := "2.10.6" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.1" # 3.在项目的./src/main/scala/下新建Scala类,SimpleApp: /* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "hdfs://n1:8020/user/spark/share/README.md" // 把spark主目录下的README文档放进hdfs里 val conf = new SparkConf().setAppName("Simple Application") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) } } # 4.打包:进入项目目录,运行sbt package # 打好的包在./target/scala-2.10/sparktest_2.10-1.0.jar # 5.将jar包提交到集群上运行 $SPARK_HOME/bin/spark-submit \ --class "SimpleApp" \ --master yarn \ --deploy-mode client \ sparktest_2.10-1.0.jar [/bash]
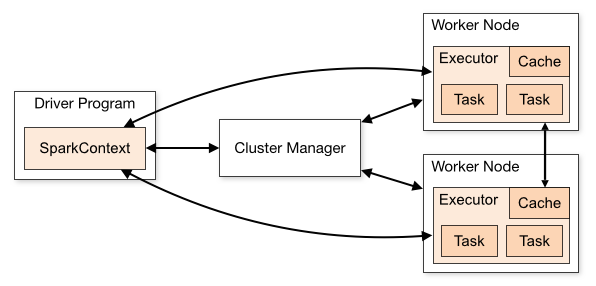
2.1 SparkContext尝试连接集群管理器(cluster managers)
在上面的应用提交脚本中我们将--master参数设置为yarn尝试连接集群,为了使得yarn集群能够被正确地连接,需确保环境变量HADOOP_CONF_DIR指向包含Hadoop集群配置文件的目录(如:$HADOOP_HOME/etc/hadoop)。这些配置将被用于读写HDFS以及连接YARN资源管理器。这些配置文件将被分发到YARN集群中,确保Spark应用相关的节点使用相同的配置文件。
2.2 如果连接成功,Spark将获得集群节点上的executors
运行main()函数并且创建SparkContext的进程被称为Driver Program(参考上面SimpleApp的源代码);为Spark执行计算与数据存储的进程被称为executors,运行executors进程的节点是worker节点。 此外,还有两种部署模式:如果driver运行在YARN集群管理的一个进程中为cluster模式;如果driver运行在提交脚本的客户端进程中则为client模式。
2.3 接下来,Spark会将应用代码(jar或者python文件)发送给executors
这样看来,我们只需要在client上部署Spark即可,而不需要在集群的每个节点上都部署。
2.4 SparkContext将task发送给executors开始任务的执行
3.Spark与Hive
在上一篇博客《通过 Spark R 操作 Hive》中,我介绍了如何编译安装带有hive与R支持的Spark,当时没搞懂配置文件的意义,现在可以梳理一下了:
3.1 带有hive支持的spark assembly jar
编译好带有hive支持的assembly jar之后,这个jar包需要在集群中的每个worker node上都存在,官网中解释的原因是:as they will need access to the Hive serialization and deserialization libraries (SerDes) in order to access data stored in Hive.这就是spark-defaults.conf配置文件中需要有 [bash] spark.yarn.jar=hdfs://n1:8020/user/spark/share/lib/spark-assembly-1.6.1-hadoop2.5.0.jar [/bash] 这一行的原因,其中spark.yarn.jar是yarn集群专有的配置,指定Spark jar文件的路径。这样设置还有一个好处是:YARN可以把这个重达一两百兆的jar包缓存在每个节点上。
3.2 datanucleus jars
当以cluster模式在YARN集群上运行query时,lib目录下的datanucleus开头的jar包也需要在整个YARN集群中可见,由于我的工作环境一般会使用client模式所以就不把它们写到默认的配置文件里了,需要时可以通过spark-submit的--jars参数把它们添加进来。
3.3 hive-site.xml
为了能够正确连接hive,hive-site.xml这个配置文件也需要全集群可见,在2.1节我们将到hadoop的配置文件将存放在环境变量HADOOP_CONF_DIR指定的目录下,把hive-site.xml也放在这个目录下即可。
4.用Maven构建Spark项目
Maven的知识还是值得深入学习的,这里就不介绍基本概念了,直接上pom文件: [xml] <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.hupu.inform</groupId> <artifactId>inform-recognition</artifactId> <version>1.0-SNAPSHOT</version> <properties> <java.version>1.7</java.version> <scala.binary.version>2.10</scala.binary.version> <scala.version>2.10.6</scala.version> <spark.version>1.6.1</spark.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>${java.version}</source> <target>${java.version}</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.1</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <source>${java.version}</source> <target>${java.version}</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <keepDependenciesWithProvidedScope>false</keepDependenciesWithProvidedScope> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.hupu.inform.SimpleApp</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project> [/xml] 这里用scala-maven-plugin来编译scala代码,用maven-shade-plugin打包assembly jar,然后把spark相应的依赖都添加进来,这样就可以在IDE里写Scala代码了。 万事俱备,总算可以开始敲代码了! 转载请注明出处:http://logos.name/
在集群上运行Spark应用的更多相关文章
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 《Spark快速大数据分析》—— 第七章 在集群上运行Spark
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
随机推荐
- 昇腾AI新技能,还能预防猪生病?
摘要:日前,由华为与武汉伯生科技基于昇腾AI合作研发的"思符(SiFold)蛋白质结构预测平台"正式推出,并成功应用于国药集团动物保健股份有限公司的猪圆环病毒疫苗研发中. 本文分享 ...
- 理论+实战,详解Sharding Sphere-jdbc
摘要:Apache ShardingSphere 是一款分布式的数据库生态系统,它包含两大产品:ShardingSphere-Proxy和ShardingSphere-JDBC. 本文分享自华为云社区 ...
- cximage总括功能讲解
CxImage的功能 Constructors 构造函数 Initialization 初始化 File 文件操作,主要是编解码 Generic 图像基本变化 DSP 图像处理操作 Paintin ...
- aop切面记日志
package com.netauth.utils.component; import java.lang.annotation.ElementType; import java.lang.annot ...
- 快速构建用户xlwings环境
一.安装python python-3.8.3-amd64.exe 二.准备文件requirements.txt 内容如下 安装失败需要切换国内镜像源 numpy==1.22.1 openpyxl== ...
- C++程序设计实验三 类和对象Ⅱ
动态int型数组类Vector_int的定义实现源码(vector_int.hpp) #include <iostream> #include <cassert> using ...
- 1163:阿克曼(Ackmann)函数
我的博客: https://www.cnblogs.com/haoningdeboke-2022/ 1163:阿克曼(Ackmann)函数 时间限制: 1000 ms 内存限制: 65 ...
- Windos下 java后台软件服务化(举例)-WinSW
WinSW-软件服务化 1.1 举例:ApiWintool可执行jar ApiWintool.exe ApiWintool.jar ApiWintool.xml install.cmd uninsta ...
- 2022-05-09内部群每日三题-清辉PMP
1.项目经理面对一个由两个合资企业组成的指导委员会,他们拥有对立的优先级.一个伙伴希望加快进度:而第二个合作伙伴想要高质量,并且愿意接受更长时间的进度.若要解决这个冲突,项目经理应该怎么做? A.将该 ...
- 正则过滤http|https地址
let reg = /(\w+):\/\/([^/:]+)(:\d*)?/; let s = http.match(reg); let s1 = http1.match(reg); console.l ...