XML入门介绍
XML 简介
什么是 xml?
xml 是可扩展的标记性语言。
xml 的作用?
xml 的主要作用有:
1、用来保存数据,而且这些数据具有自我描述性
2、它还可以做为项目或者模块的配置文件
3、还可以做为网络传输数据的格式(现在 JSON 为主)。
xml 语法
- 文档声明。
- 元素(标签)
- xml 属性
- xml 注释
- 文本区域(CDATA 区)
文档声明
我们先创建一个简单 XML 文件,用来描述图书信息
(1)创建一个 xml 文件

文件名:

<?xml version="1.0" encoding="UTF-8"?> xml 声明。
<!-- xml 声明 version 是版本的意思 encoding 是编码 -->
而且这个<?xml 要连在一起写,否则会有报错
属性
| version | 是版本号 |
| encoding | 是 xml 的文件编码 |
| standalone="yes/no" | 表示这个 xml 文件是否是独立的 xml 文件 |
(2)图书有 id 性 属性 一 表示唯一 标识,书名,有作者,价格的信息
books.xml文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<!-- xml 声明 version 是版本的意思 encoding 是编码 -->
<books> <!-- 这是 xml 注释 -->
<book id="SN9787302575443"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 -->
<name>Java 2实用教程(第6版)</name> <!-- name 标签描述 的是图书 的信息 -->
<author>耿祥义、张跃平</author> <!-- author 单词是作者的意思 ,描述图书作者 -->
<publisher>清华大学出版社</publisher> <!--publisher 单词是出版社的意思,描述图书的出版社-->
<price>65</price> <!-- price 单词是价格,描述的是图书 的价格 -->
</book>
<book id="SN9787020122172"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 -->
<name>骆驼祥子</name> <!-- name 标签描述 的是图书 的信息 -->
<author>老舍</author> <!-- author 单词是作者的意思 ,描述图书作者 -->
<publisher>人民文学出版社</publisher> <!--publisher 单词是出版社的意思,描述图书的出版社-->
<price>20.20</price><!-- price 单词是价格,描述的是图书 的价格 -->
</book>
</books>
在浏览器中可以查看到文档:


xml 注释
html 和 XML 注释 一样 :
<!-- html 注释 -->
元素(标签)
html 标签:
| 格式 | <标签名>封装的数据</标签名> |
| 单标签 | <标签名 /> <br /> 换行 <hr />水平线 |
| 双标签 | <标签名>封装的数据</标签名> |
1. 标签名大小写不敏感
2. 标签有属性,有基本属性和事件属性
3. 标签要闭合(不闭合 ,html 中不报错。但我们要养成良好的书写习惯。闭合)
1)什么是 xml 元素
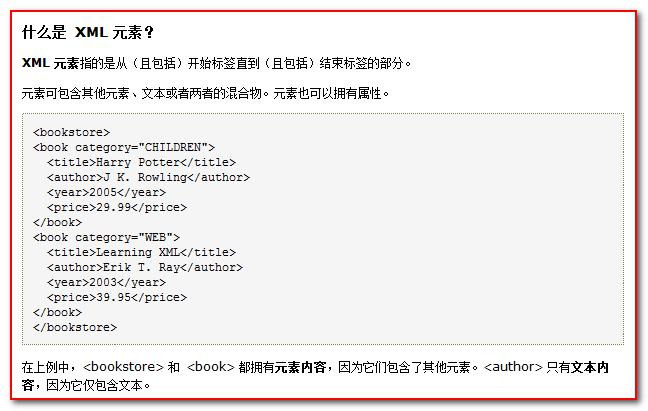
元素是指从开始标签到结束标签的内容。
例如:
<title>java2实用教程</title>
元素 我们可以简单的理解为是 标签。
Element 翻译 元素
2)XML 命名规则
XML 元素必须遵循以下命名规则:
- 名称可以含字母、数字以及其他的字符
例如:
<book id="SN9787302575443"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 -->
<name>Java 2实用教程(第6版)</name> <!-- name 标签描述 的是图书 的信息 -->
<author>耿祥义、张跃平</author> <!-- author 单词是作者的意思 ,描述图书作者 -->
<publisher>清华大学出版社</publisher> <!--publisher 单词是出版社的意思,描述图书的出版社-->
<price>65</price> <!-- price 单词是价格,描述的是图书 的价格 -->
- 名称不能以数字或者标点符号开始

- 尽管以“xml”(或者 XML、Xml)是可以的、不报错的,但是不建议名称以字符 “xml”(或者 XML、Xml)开始

- 名称不能包含空格

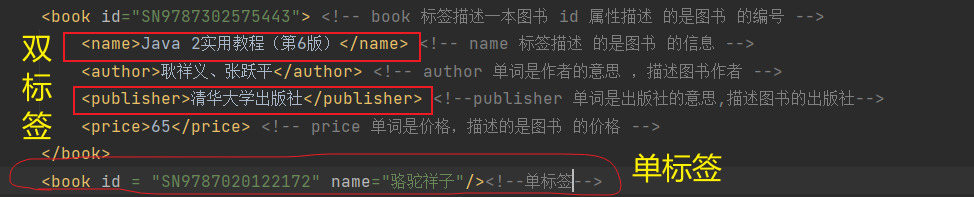
3)xml 也 中的元素(标签)也 成 分成 单标签和双标签:
单标签
格式:
<标签名 属性=”值” 属性=”值” ...... />
双标签
格式:
< 标签名 属性=”值” 属性=”值” ......>文本数据或子标签</标签名>
xml 属性
xml 的标签属性和 html 的标签属性是非常类似的, 属性可以提供元素的额外信息
在标签上可以书写属性:
一个标签上可以书写多个属性。每个属性的值必须使用 引号 引起来。
的规则和标签的书写规则一致。
API文档截图:

- 属性必须使用引号引起来,不引起来会报错
示例:

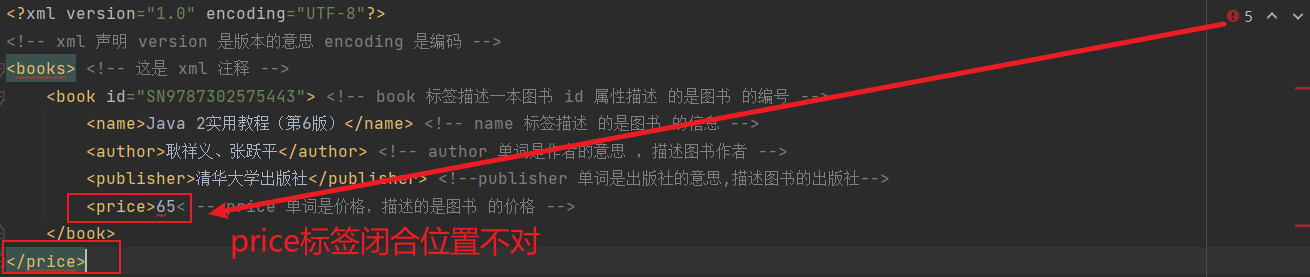
语法规则
- 所有 XML 元素都须有关闭标签

XML 标签对大小写敏感

XML 必须正确地嵌套
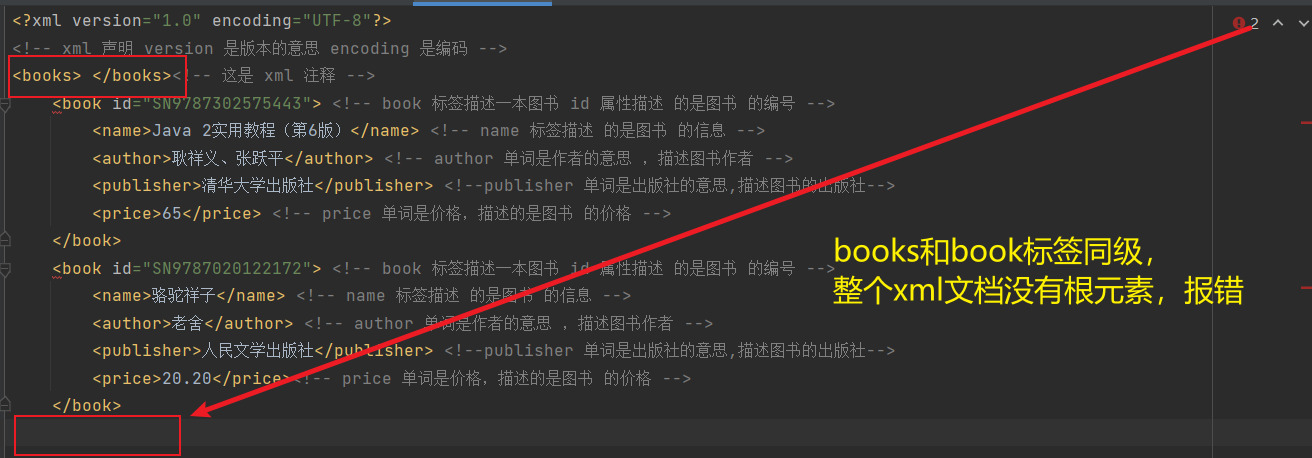
XML 文档必须有根元素
根元素就是顶级元素,
没有父标签的元素,叫顶级元素。
根元素是没有父标签的顶级元素,而且是唯一一个才行。
XML 的属性值须加引号
XML 中的特殊字符
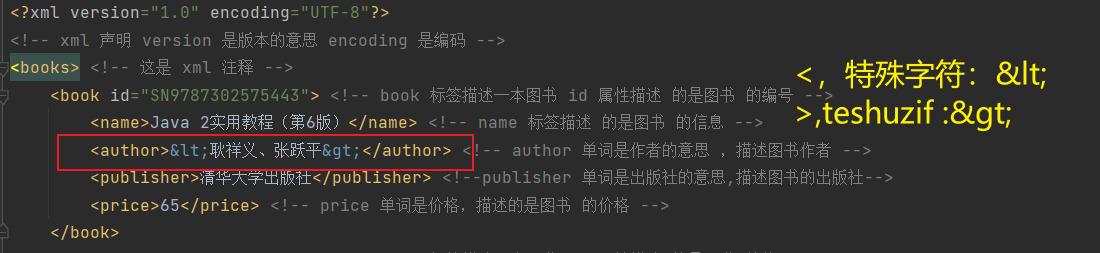

7. 文本区域(CDATA 区)
CDATA 语法可以告诉 xml 解析器,我 CDATA 里的文本内容,只是纯文本,不需要 xml 语法解析
CDATA 格式:
<![CDATA[ 这里可以把你输入的字符原样显示,不会解析 xml ]]>
示例:
<book id="SN9787302575443"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 -->
<name>Java 2实用教程(第6版)</name> <!-- name 标签描述 的是图书 的信息 -->
<author><![CDATA[<<<耿祥义、张跃平>>>]]></author> <!-- author 单词是作者的意思 ,描述图书作者 -->
<publisher>清华大学出版社</publisher> <!--publisher 单词是出版社的意思,描述图书的出版社-->
<price>65</price> <!-- price 单词是价格,描述的是图书 的价格 -->
</book>

xml 解析技术介绍
xml 可扩展的标记语言。
不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的 dom 技术来解析。

document 对象表示的是整个文档(可以是 html 文档,也可以是 xml 文档)
早期 JDK 为我们提供了两种 xml 解析技术 DOM 和 和 Sax 简介( 已经过时,但需要知道这两种技术 )
dom 解析技术是 W3C 组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。
Java 对 dom 技术解析标记也做了实现。
sun 公司在 JDK5 版本对 dom 解析技术进行升级:SAX( Simple API for XML )
SAX 解析,它跟 W3C 制定的解析不太一样。它是以类似事件机制通过回调告诉用户当前正在解析的内容。
它是一行一行的读取 xml 文件进行解析的。不会创建大量的 dom 对象。
所以它在解析 xml 的时候,在内存的使用上。和性能上。都优于 Dom 解析。
第三方的解析:
jdom 在 dom 基础上进行了封装 、dom4j 又对 jdom 进行了封装。
pull 主要用在 Android 手机开发,是在跟 sax 非常类似都是事件机制解析 xml 文件。
这个 Dom4j 它是第三方的解析技术。我们需要使用第三方给我们提供好的类库才可以解析 xml 文件。
dom4j 解析技术
Dom4j 类库的使用
Dom4j包下载:https://kohler.lanzouv.com/iv8R207qmvkh
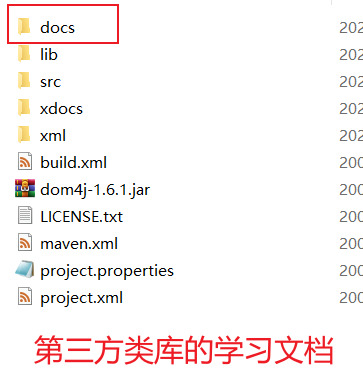
解压后:

dom4j 目录的介绍
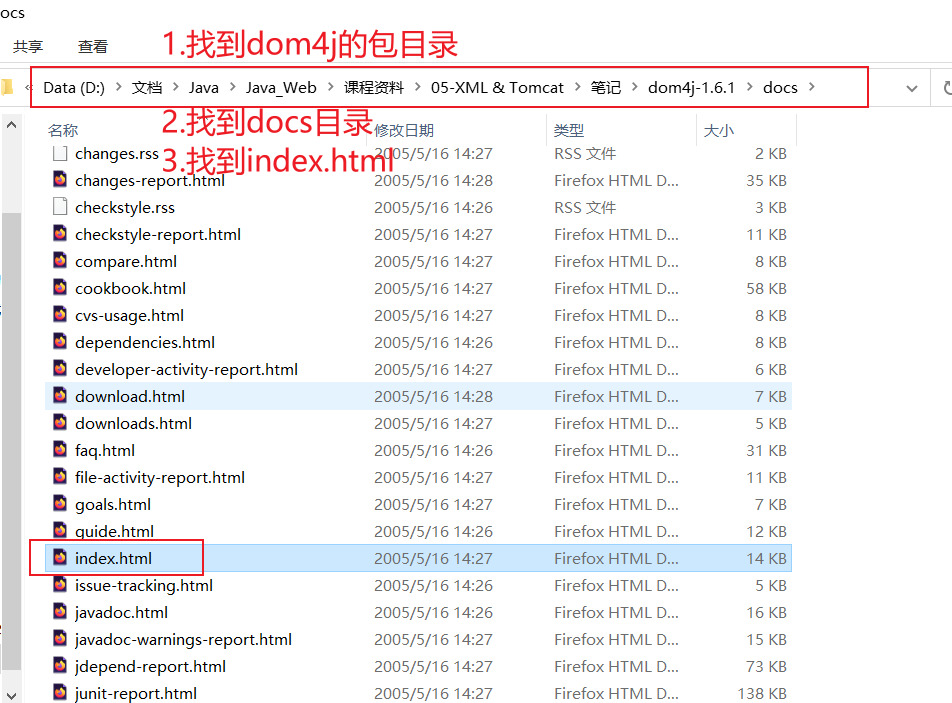
- docs 是文档目录
- 查 如何查 Dom4j 的文档
- Dom4j 快速入门

- lib 目录

5. src 目录是第三方类库的源码目录
dom4j 编程步骤
第一步: 先加载 xml 文件创建 Document 对象
第二步:通过 Document 对象拿到根元素对象
第三步:通过根元素.elelemts(标签名); 可以返回一个集合,这个集合里放着。所有你指定的标签名的元素对象
第四步:找到你想要修改、删除的子元素,进行相应在的操作
第五步,保存到硬盘上
获取 document 对象
创建一个 lib 目录,并添加 dom4j 的 jar 包。并添加到类路径。
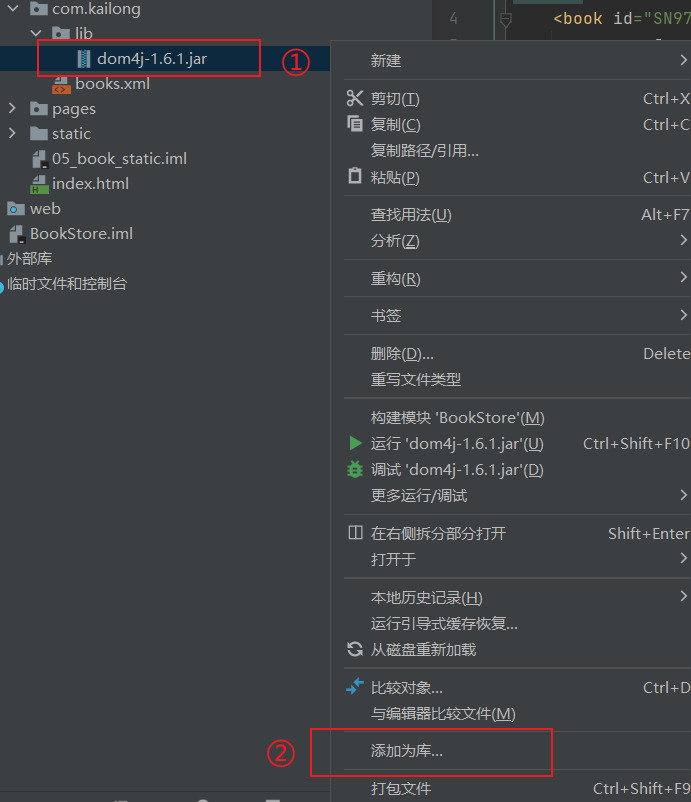
需要解析的 books.xml 文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<!-- xml 声明 version 是版本的意思 encoding 是编码 -->
<books> <!-- 这是 xml 注释 -->
<book id="SN9787302575443"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 -->
<name>Java 2实用教程(第6版)</name> <!-- name 标签描述 的是图书 的信息 -->
<author><![CDATA[<<<耿祥义、张跃平>>>]]></author> <!-- author 单词是作者的意思 ,描述图书作者 -->
<publisher>清华大学出版社</publisher> <!--publisher 单词是出版社的意思,描述图书的出版社-->
<price>65</price> <!-- price 单词是价格,描述的是图书 的价格 -->
</book>
<book id="SN9787020122172"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 -->
<name>骆驼祥子</name> <!-- name 标签描述 的是图书 的信息 -->
<author>老舍</author> <!-- author 单词是作者的意思 ,描述图书作者 -->
<publisher>人民文学出版社</publisher> <!--publisher 单词是出版社的意思,描述图书的出版社-->
<price>20.20</price><!-- price 单词是价格,描述的是图书 的价格 -->
</book>
</books>
解析获取 Document 对象的代码
第一步,先创建 SaxReader 对象。这个对象,用于读取 xml 文件,并创建
Document
/*
* dom4j 获取 Documet 对象
*/
@Test
public void getDocument() throws DocumentException {
// 要创建一个 Document 对象,需要我们先创建一个 SAXReader 对象
SAXReader reader = new SAXReader();
// 这个对象用于读取 xml 文件,然后返回一个 Document。
Document document = reader.read("src/books.xml");
// 打印到控制台,看看是否创建成功
System.out.println(document);
}
遍历 、遍历 签 标签 获取所有标签中的内容
/*
* 读取 xml 文件中的内容(xml文件即上一步的books.xml)
*/
@Test
public void readXML() throws DocumentException {
// 需要分四步操作:
// 第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
// 第二步,通过 Document 对象。拿到 XML 的根元素对象
// 第三步,通过根元素对象。获取所有的 book 标签对象
// 第四小,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
// 第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
SAXReader reader = new SAXReader();
//在Junit测试中,相对路径是从模块名开始算
Document document = reader.read("src/books.xml");
//第二步,通过 Document 对象。拿到 XML 的根元素对象
Element rootElement = document.getRootElement();
//System.out.println(rootElement);
//第三步,通过根元素对象。获取所有的 book 标签对象
//Element.elements(标签名)它可以拿到当前元素下的指定的子元素的集合
//element()和elements()都是通过标签名查找子元素
List <Element> books = rootElement.elements("book");
//第四步,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,
for (Element book : books) {
// 拿到 book 下面的 name 元素对象
Element nameElement = book.element("name");
// 拿到 book 下面的 price 元素对象
Element priceElement = book.element("price");
// 拿到 book 下面的 author 元素对象
Element authorElement = book.element("author");
// 拿到 book 下面的 publisher 元素对象
Element publisherElement = book.element("publisher");
// 再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
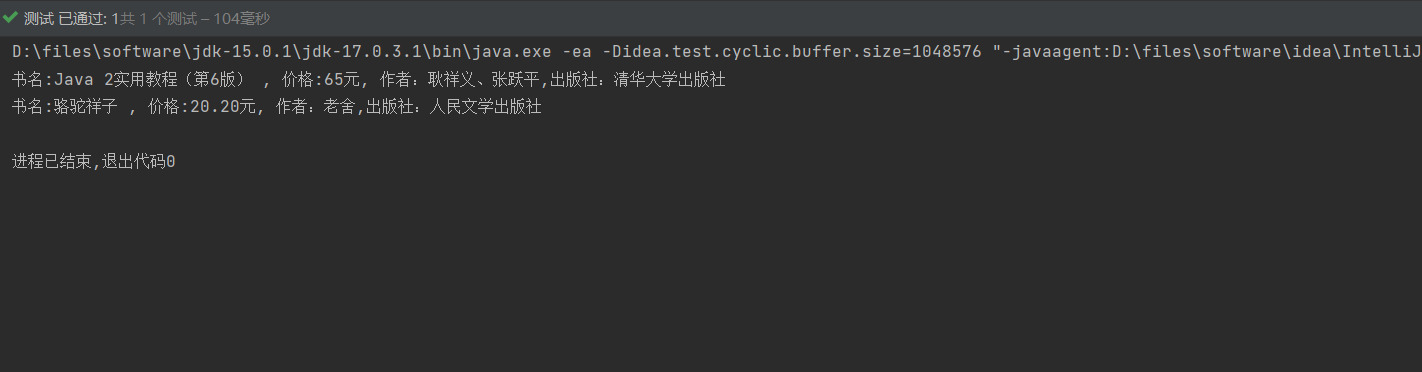
System.out.println("书名:" + nameElement.getText() + " , 价格:"
+ priceElement.getText() + "元, 作者:" + authorElement.getText() + ",出版社:" + publisherElement.getText());
}
}
}
打印内容:
如图片失效等情况请参阅公众号文章:https://mp.weixin.qq.com/s/T4tsUg4_YRiDRPEF7fhOtQ
欢迎关注公众号:“愚生浅末”,一起学习交流。
XML入门介绍的更多相关文章
- XMl入门介绍及php操作XML
一.什么是XML XML全称:Extensible Markup Language 中文名:可扩展标记语言 用于标记电子文件使其具有结构性的标记语言,可以用来标记数据,定义数据类型,允许用户对自己的标 ...
- XML入门介绍(什么是XML及XML格式)
什么是 XML? XML 指可扩展标记语言(EXtensible Markup Language). XML 是一种很像HTML的标记语言. XML 的设计宗旨是传输数据,而不是显示数据. XML 标 ...
- .NET读写Excel工具Spire.Xls使用(1)入门介绍
原文:[原创].NET读写Excel工具Spire.Xls使用(1)入门介绍 在.NET平台,操作Excel文件是一个非常常用的需求,目前比较常规的方法有以下几种: 1.Office Com组件的方式 ...
- mybatis入门介绍一
首先介绍一下Mybatis是什么?mybatis是Java的持久层框架, JAVA操作数据库是通过jdbc来操作的,而mybatis是对jdbc的封装. 使用mybatis之后,开发者只需要关注sql ...
- mybatis入门介绍二
相信看过我的上一篇博客的同学都已经对mybatis有一个初步的认识了.这篇博客主要是对mybatis的mapper代理做一下简单的介绍,希望能够帮助大家共同学习. 我的上一篇博客:mybatis入门介 ...
- Android CoordinatorLayout 入门介绍
Android CoordinatorLayout 入门介绍 CoordinatorLayout View 知道如何表现 在 2015 年的 I/O 开发者大会上,Google 介绍了一个新的 And ...
- XML基础介绍【一】
XML基础介绍[一] 1.XML简介(Extensible Markup Language)[可扩展标记语言] XML全称为Extensible Markup Language, 意思是可扩展的标记语 ...
- XML基础介绍【二】
XML基础介绍[二] 1.schema约束dtd语法: <!ELEMENT 元素名称 约束>schema符合xml的语法,xml语句.一个xml中可以有多个schema,多个schema使 ...
- (转)MQTT 入门介绍
原文链接:https://blog.csdn.net/qq_2887... MQTT 入门介绍 一.简述 MQTT(Message Queuing Telemetry Transport,消息队列遥测 ...
随机推荐
- 动态SQL常用标签
动态 SQL 目的:为了摆脱在不同条件拼接 SQL 语句的痛苦 在不同条件在生成不同的SQL语句 本质上仍然是SQL语句,不过是多了逻辑代码去拼接SQL,只要保证SQL的正确性按照格式去排列组合 可以 ...
- Jenkins Build step 'Execute shell' marked build as failure
问题出现: Jenkins一直都构建成功,今天突然报错:Jenkins Build step 'Execute shell' marked build as failure 问题原因: By defa ...
- Hadoop(四)C#操作Hbase
Hbase Hbase是一种NoSql模式的数据库,采用了列式存储.而采用了列存储天然具备以下优势: 可只查涉及的列,且列可作为索引,相对高效 针对某一列的聚合及其方便 同一列的数据类型一致,方便压缩 ...
- 面渣逆袭:Redis连环五十二问,图文详解,这下面试稳了!
大家好,我是老三,面渣逆袭系列继续,这节我们来搞定Redis--不会有人假期玩去了吧?不会吧? 基础 1.说说什么是Redis? Redis是一种基于键值对(key-value)的NoSQL数据库. ...
- 好客租房13-在jsx中使用javascript表达式
嵌入js表达式 数据存储在js中 语法{javascript表达式} 注意语法中是单大括号 不是双大括号 //导入react import React from "react&quo ...
- break、continue、return中选择一个,我们结束掉它
在平时的开发过程中,经常会用到循环,在写循环的过程中会有很多判断条件及逻辑,你知道如何结束一个循环吗?在java中有break.continue.reture三个关键字都可以结束循环,我们看下他们 ...
- 管理订单状态,该上状态机吗?轻量级状态机COLA StateMachine保姆级入门教程
前言 在平常的后端项目开发中,状态机模式的使用其实没有大家想象中那么常见,笔者之前由于不在电商领域工作,很少在业务代码中用状态机来管理各种状态,一般都是手动get/set状态值.去年笔者进入了电商领域 ...
- vue组件data函数
vue组件data通常定义为一个函数并return一个对象,对象中定义的就是组件数据,当然定义数据还有props.computed等方式. data如果直接定义为对象data: {message: ' ...
- KALI2020忘记用户名和密码
时隔半年,打开kali发现忘记了自己精心研制的用户名密码......... 第一步 在开机的时候就按e键进入如下界面 第二步 用键盘上的上下箭头↑↓进行屏幕滚动,滑到最后一行发现修改目标 倒数第四行: ...
- 在Winform开发中,使用Async-Awati异步任务处理代替BackgroundWorker
在Winform开发中有时候我们为了不影响主UI线程的处理,以前我们使用后台线程BackgroundWorker来处理一些任务操作,不过随着异步处理提供的便利性,我们可以使用Async-Awati异步 ...