Tapdata肖贝贝:实时数据引擎系列(三) - 流处理引擎对比
摘要:本文将选取市面上一些流计算框架包括 Flink 、Spark 、Hazelcast,从场景需求出发,在核心功能、资源与性能、用户体验、框架完整性、维护性等方面展开分析和测评,剖析实时数据框架的特色。
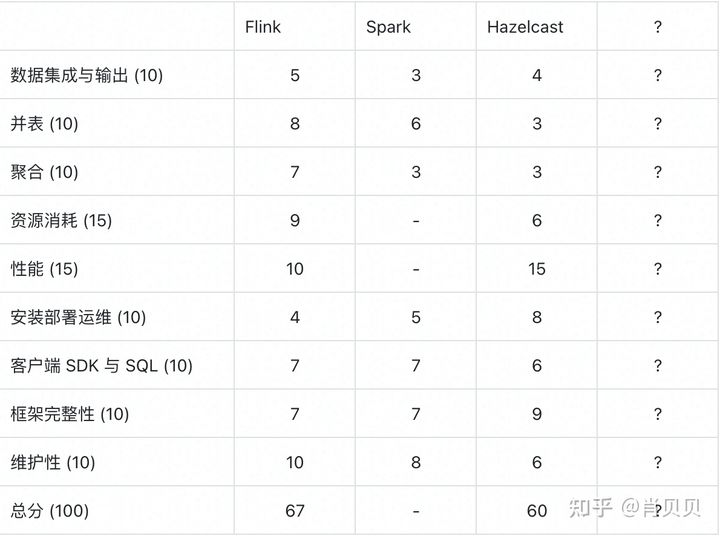
- 核心功能: 数据集成与输出, 并表, 聚合
- 资源与性能: 不同场景下的资源消耗与性能
- 用户体验: 安装部署运维是否方便, 是否包含可视化任务构建与管理, 是否提供了客户端 SDK 与 SQL 接口
- 框架完整性: 是否包含任务调度, 分布式, 高可用, 是否提供了编程框架
- 维护性: 是否还在发展与维护
评测选手
- Flink: 流计算框架顶流选手, 流数据第一公民开创者
- Spark: 大数据计算传统选手, Stream 框架支持流计算
- Hazelcast: 一个可以内嵌开发的轻量流计算框架, 以自带分布式内存作为亮点
详细测试内容
- 数据集成与输出: 10分, 测试对接的数据源与目标的类型, 是否是批流, 是否方便二次开发
- 并表: 10 分, 在我们的场景下, 对窗口的要求并不高, 要求对全数据进行并表, 同时, 每张表都可能是来自不同类型数据库的流数据, 并且每张表的更新不保证有序, 在这个场景下, 要求并表的结果与批量的结果能够最终一致
- 聚合: 10 分, 与并表的数据场景类似, 要求聚合的结果与批量计算的结果能够最终一致
- 资源消耗: 15分, 每个场景下的 CPU 与 内存, IO 消耗, 测试 case 有三个, 10G 文本单词计数, 千万表 JOIN 百万表, 千万表增量聚合, 以最大的内存 RES 为准, 得分我们以最低为满分, 每个场景 5 分满分, 其余按比例给分
- 性能: 15分, 吞吐与延迟, 测试 case 有三个, wordcount, 千万表数据 JOIN 百万表数据, 千万表聚合, 为测量延迟, 我们增加一个表同步, 通过数据库表字段的当前时间来判断延迟, 执行硬件环境为
MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports), 处理器 2.3 GHz 双核Intel Core i5, 内存 8 GB 2133 MHz LPDDR3, 数据库测试环境为:16C 64G SSD 环境, 网卡为千兆网卡, 任务开 4 并发, 性能的得分我们以最高为满分, 每个场景 5 分满分, 其余按比例给分 - 安装部署运维: 10分, 安装部署是否方便, 运维是否方便, 是否提供可视化界面
- 客户端 SDK 与 SQL 接口: 10分, 客户端是否使用方便, 是否支持 SQL 计算
- 框架完整性: 10分, 是否可嵌入, 是否包含任务调度, 分布式, 高可用
- 维护性: 10分, 是否还在发展与维护
对比结果
Flink
数据集成与输出
- 具备基本的功能与框架 (3)
- 常见的开源数据库对接尚可, 种类不足 (1)
- 商业数据库对接能力不足 (1)
并表
- 支持基本的两表 INNER JOIN, 支持乱序 (3)
- LEFT JOIN , 与数据流更新需要自己实现状态存储与事件逻辑 (2)
- Table SQL 接口对常见的并表接口几乎完美实现 (3)
聚合
资源消耗
性能
安装部署运维
客户端 SDK 与 SQL
框架完整性
维护性
Spark
数据集成与输出
并表
聚合
资源消耗
性能
安装部署运维
客户端 SDK 与 SQL
框架完整性
维护性
Hazelcast
数据集成与输出
并表
聚合
资源消耗
性能
安装部署运维
客户端 SDK 与 SQL
框架完整性
维护性
总结
Tapdata肖贝贝:实时数据引擎系列(三) - 流处理引擎对比的更多相关文章
- {MySQL存储引擎介绍}一 存储引擎解释 二 MySQL存储引擎分类 三 不同存储引擎的使用
MySQL存储引擎介绍 MySQL之存储引擎 本节目录 一 存储引擎解释 二 MySQL存储引擎分类 三 不同存储引擎的使用 一 存储引擎解释 首先确定一点,存储引擎的概念是MySQL里面才有的,不是 ...
- Tapdata 肖贝贝:实时数据引擎系列(四)-关于 Oracle 与 Oracle CDC
摘要:想实现 Oracle 的 CDC,排除掉一些通用的比如全量比对, 标记字段获取之外, 真正的增量形式获取变更, 有三种办法: Logminer .XStream .裸日志解析,但不管哪种方法 ...
- Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题.Tapdata 在解决 Pos ...
- leaflet-webpack 入门开发系列三地图分屏对比(附源码下载)
前言 leaflet-webpack 入门开发系列环境知识点了解: node 安装包下载webpack 打包管理工具需要依赖 node 环境,所以 node 安装包必须安装,上面链接是官网下载地址 w ...
- 基于 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(二)
我们上一篇<基于 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(一)>主要讲解了如何搭建一个实时数据通讯服务器,客户端与服务端是如何通讯的,相信通过上一篇的讲解,再配 ...
- 通过 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(二)
我们上一篇<基于 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(一)>主要讲解了如何搭建一个实时数据通讯服务器,客户端与服务端是如何通讯的,相信通过上一篇的讲解,再配 ...
- 实时数据引擎系列(五): 关于 SQL Server 与 SQL Server CDC
摘要:在企业客户里, SQL Server 在传统的制造业依然散发着持久的生命力,SQL Server 的 CDC 复杂度相比 Oracle 较低, 因此标准的官方派做法就是直接使用这个 CDC ...
- Tapdata 实时数据融合平台解决方案(三):数据中台的技术需求
作者介绍:TJ,唐建法,Tapdata 钛铂数据 CTO,MongoDB中文社区主席,原MongoDB大中华区 首席架构师,极客时间MongoDB视频课程讲师. 我们讲完了这个中台的一个架构和它的逻 ...
- Tapdata 实时数据中台在智慧教育中的实践
摘要:随着教育信息化的推进,智慧校园建设兴起,但在实施过程中面临数据孤岛.应用繁多.数据再利用等方面挑战,而 Tapdata 的实时数据中台解决方案,能够高效地解决智慧校园实施中的基础数据问题. ...
随机推荐
- 数据传输POST心法分享,做前端的你还解决不了这个bug?
背景 随时随地给大家提供技术支持的葡萄又来了.这次的事情是这样的,提供demo属于是常规操作,但是前两天客户突然反馈压缩传输模块抛出异常,具体情况是压缩内容传输到服务端后无法解压. 由于代码没有发生任 ...
- .NET宝藏API之:OutputFormatter,格式化输出对象
相信大家在项目中都用过统一响应参数模板. 先声明一个响应模板类: public class ResponseDto { public int code { get; set; } public str ...
- 深度优先搜索 DFS 学习笔记
深度优先搜索 学习笔记 引入 深度优先搜索 DFS 是图论中最基础,最重要的算法之一.DFS 是一种盲目搜寻法,也就是在每个点 \(u\) 上,任选一条边 DFS,直到回溯到 \(u\) 时才选择别的 ...
- Linux -4-作业练习
1.编写脚本实现登陆远程主机.(使用expect和shell脚本两种形式). expect脚本格式 expect总结点击查看 登录直接远程控制主机 #!/usr/bin/expect # # set ...
- 在vue-cli中安装scss,且可以全局引入scss的步骤
简历魔板__个人简历模板在线生成 在写vue的css样式时,觉得需要css预处理器让自己的css更加简洁.适应性更强.可读性更佳,更易于代码的维护,于是在vue-cli脚手架采用scss.写过的人都知 ...
- iOS全埋点解决方案-时间相关
前言 我们使用"事件模型( Event 模型)"来描述用户的各种行为,事件模型包括事件( Event )和用户( User )两个核心实体.我们在描述用户行为时,往往只需要描述 ...
- Golang:将日志以Json格式输出到Kafka
在上一篇文章中我实现了一个支持Debug.Info.Error等多个级别的日志库,并将日志写到了磁盘文件中,代码比较简单,适合练手.有兴趣的可以通过这个链接前往:https://github.com/ ...
- 【Java面试】Redis存在线程安全问题吗?为什么?
一个工作了5年的粉丝私信我. 他说自己准备了半年时间,想如蚂蚁金服,结果第一面就挂了,非常难过. 问题是: "Redis存在线程安全问题吗?" 关于这个问题,看看普通人和高手的回答 ...
- 905. Sort Array By Parity - LeetCode
Question 905. Sort Array By Parity Solution 题目大意:数组排序,偶数放前,奇数在后,偶数的数之间不用管顺序,奇数的数之间也不用管顺序 思路:建两个list, ...
- linux篇-linux mysql5.6.27源码安装和错误解决
centos mysql5.6.27 1编译安装 先进入到文件放置的路径下 创建一个个文件 #mkdir–p /data/mysql/mysql #mkdir–p /data/mysql/mysqld ...