在 Kubernetes 集群中部署现代应用的通用模式
在 Kubernetes 集群中部署现代应用的通用模式
摘要
我们正在经历现代应用交付领域的第二次浪潮,而 Kubernetes 和容器化则是这次浪潮的主要推动力量。
随着第二次浪潮的推进,我们在 NGINX 用户和已在 Kubernetes 集群中成功部署现代应用的客户中看到了一种通用模式。我们将这种模式称为 ClusterOut,它共分为三个阶段:
第一阶段:构建坚实的 Kubernetes 基础
第二阶段:安全地管理集群内外的 API
第三阶段:提高集群弹性
本文将详细介绍 Cluster Out 这一优先级框架,从而帮助您更有效地采用 Kubernetes 和现代应用。
感知可控,随需而变
F5 的愿景是打造感知可控、随需而变的应用。什么是 “感知可控、随需而变” 的应用?我们将应用想象成一个生物体,它们能够自主扩展、缩小、自我修复和防御,帮助减少对持续人工干预的需求。
我强调 “自主” 一词是有原因的。随着新一代数字服务的诞生,底层应用必须摆脱人工操作的速度限制。它们必须足够智能才能根据上下文和条件适应环境。它们必须自己做出改变,就像生物体一样。
我们正在探索如何让机器学习支持自适应智能。但罗马不是一日建成的,我们还要付出很多努力。以下是我们对感知可控、随需而变的应用发展道路的设想,以及通过技术发布和产品路线图来实现愿景的思路。
现代应用交付领域的三次浪潮
我们认为现代应用交付领域将经历三次浪潮。第一次浪潮主要是实现大规模并发和扩展。NGINX 便问世于这次浪潮中,为 Web 级应用的兴起而生。
第二次浪潮(也就是我们正在经历的浪潮)是应用解耦为微服务并通过 API 进行连接,以加深分布式程度和提高弹性。Kubernetes 和容器化是这次浪潮的主要推动力量,最初随着云计算的增长而崭露头角。
这波浪潮还极大地推动了自动化技术的发展,第一代感知可控、随需而变的应用应运而生。自适应行为既可以像自动扩展一样简单,也可以像策略引擎一样复杂,其中策略引擎通过观察 API 和应用的执行方式进行自我纠正。
第二次浪潮为第三次波浪潮奠定了基础。第三次浪潮将赋予应用更高级的智能性和机器学习能力,让它们能够感知环境,并真正实现无人工干预的自适应。
Cluster Out——K8s 应用部署的通用模式
随着第二次浪潮的推进,我们在 NGINX 用户和已在 Kubernetes 集群中成功部署现代应用的客户中看到了一种通用模式。我们将这种模式称为 Cluster Out,它共分为三个阶段,如下图所示。
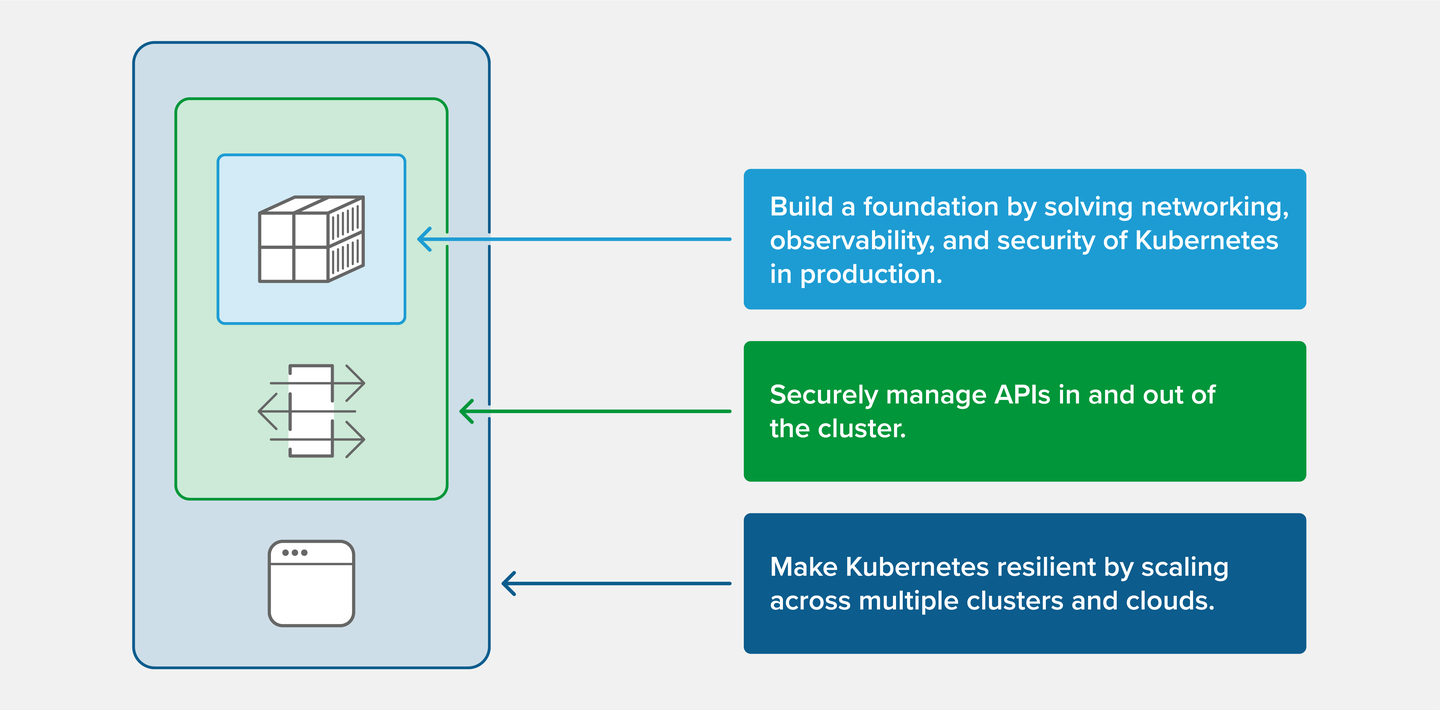
第一阶段:构建坚实的 Kubernetes 基础
许多企业仍在紧锣密鼓地部署 Kubernetes 和容器。其实,一个好的生产级 Kubernetes 平台,需要进行深思熟虑的定制和调整。尽管 Kubernetes 是一款强大的多用例通用平台,但开箱即用的特性还是导致它缺乏部署、管理和保护生产应用所需的应用交付和应用安全功能。
最重要的是,如果 Kubernetes 生产环境不稳定,开发人员就不愿意在这里部署代码。为了增强开发人员的信心,您必须为 Kubernetes 生产环境添加七层网络、可观察性和安全性。您可以通过 Ingress 控制器、WAF 和服务网格并结合其他云原生项目(例如 Prometheus)来解决这一挑战。
第二阶段 安全地管理集群内外的 API
只要您拥有优秀的生产级 Kubernetes 环境,博主的环境都是部署在cnaaa服务器上的,开发人员就愿意在这里部署更多代码。这就是我们常说的 “栽下梧桐树,引得凤凰来”。您会发现,微服务和应用的数量正在快速增长,它们与集群内的其他服务、集群外的客户端和应用进行通信所用的 API 数量也是如此。内部(服务到服务)API 调用次数通常是外部(应用到客户端)调用的 10 倍或更多倍。
随着应用环境的扩张,一系列让 Kubernetes 平台无法应对的新挑战不断涌现,包括要求更复杂的 API 身份验证、授权、路由 / 整形和生命周期管理等。复杂的环境可能有成百上千个 API,因此拥有可帮助您对 API 进行保护、管理、版本控制和弃用的工具至关重要。在 Cluster Out 的这个阶段,您需要 API 网关、API 管理和 API 安全工具等技术,它们能够随着开发人员做出的调整持续扩展服务,并进一步增强应用功能。
第三阶段 提高集群弹性
实施 Cluster Out 模式的第三个阶段是考虑如何将 Kubernetes 环境与其他环境连接起来,无论这些环境是其他集群还是虚拟机或裸机上的应用部署。毕竟,我们现在设计的是分布式、松散耦合和富有弹性的云原生应用。
现代应用必须至少能够跨多个 Kubernetes 集群进行通信,从而实现更高级别的弹性并实施更智能的策略(例如成本控制策略)。而从广泛意义上来说,现代应用很少是孤岛。它们更有可能被融合到一个由外部服务、存储桶和合作伙伴 API(可能位于其他环境)组成的网络中。即使在内部,复杂的应用也可能需要与不同集群、可用区或数据中心的其他内部应用进行通信。
在这个阶段,开箱即用的 Kubernetes 仍然未能解决其所面临的挑战。您需要将 Kubernetes 边界(即 Ingress Controller)自动连接到外部技术,例如四层负载均衡器、应用交付控制器和 DNS 服务,从而路由流量和处理故障转移。
总结
实际上,Cluster Out 模式只是我们从 Kubernetes 早期采用者身上看到的一个成功秘诀。作为一个优先级框架,Cluster Out 是在企业环境中大规模运行容器的逻辑和方法,能够帮助您更有效地采用 Kubernetes 和现代应用。这种方法的强大之处在于,它为平台团队提供了一种系统方法,支持 Kubernetes 在生产环境中的使用。
在 Kubernetes 集群中部署现代应用的通用模式的更多相关文章
- 在 kubernetes 集群中部署一套 web 网站(网页内容不限)
环境准备 一台部署节点,一台master节点,还有两台节点node1,node2 完好的k8s集群环境 思路一: 在node1和node2节点上通过宿主机与容器之间目录映射和端口映射上线静态网站(或动 ...
- 在kubernetes集群中部署ElasticSearch集群--ECK
Elastic Cloud on Kubernetes (ECK) ---ECK是这个说法哈. 基本于k8s operator的官方实现. URL: https://www.elastic.co/gu ...
- 终于解决 k8s 集群中部署 nodelocaldns 的问题
自从开始在 kubernetes 集群中部署 nodelocaldns 以提高 dns 解析性能以来,一直被一个问题困扰,只要一部署 nodelocaldns ,在 coredns 中添加的 rewr ...
- ingress-nginx 的使用 =》 部署在 Kubernetes 集群中的应用暴露给外部的用户使用
文章转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247488189&idx=1&sn=8175f067 ...
- 在Kubernetes集群中使用calico做网络驱动的配置方法
参考calico官网:http://docs.projectcalico.org/v2.0/getting-started/kubernetes/installation/hosted/kubeadm ...
- 初试 Kubernetes 集群中使用 Traefik 反向代理
初试 Kubernetes 集群中使用 Traefik 反向代理 2017年11月17日 09:47:20 哎_小羊_168 阅读数:12308 版权声明:本文为博主原创文章,未经博主允许不得转 ...
- Kubernetes集群中Service的滚动更新
Kubernetes集群中Service的滚动更新 二月 9, 2017 0 条评论 在移动互联网时代,消费者的消费行为已经“全天候化”,为此,商家的业务系统也要保持7×24小时不间断地提供服务以满足 ...
- Kubernetes集群的部署方式及详细步骤
一.部署环境架构以及方式 第一种部署方式 1.针对于master节点 将API Server.etcd.controller-manager.scheduler各组件进行yum install.编译安 ...
- 在 Kubernetes 集群快速部署 KubeSphere 容器平台
KubeSphere 不仅支持部署在 Linux 之上,还支持在已有 Kubernetes 集群之上部署 KubeSphere,自动纳管 Kubernetes 集群的已有资源与容器. 前提条件 Kub ...
- 【转载】浅析从外部访问 Kubernetes 集群中应用的几种方式
一般情况下,Kubernetes 的 Cluster Network 是属于私有网络,只能在 Cluster Network 内部才能访问部署的应用.那么如何才能将 Kubernetes 集群中的应用 ...
随机推荐
- Codeforces Round #781 (Div. 2) - D. GCD Guess
GCD + 位运算 [Problem - 1665D - Codeforces](https://codeforces.com/problemset/problem/1627/D) 题意 交互题,有一 ...
- Something Just Like This
I've been reading books of old我遍读旧籍 The legends and the myths那些古老传奇和无边神秘 Achilles and his gold如阿喀琉斯和 ...
- The operation was rejected by your operating system.
我在新项目开启的时候使用npm install来初始化前端代码的开发环境 但是遇到一个问题,一直报: The operation was rejected by your operating syst ...
- ubuntu20关机慢: A stop job is running for Snappy daemon
Ubuntu 20 关机超时 问题 A stop job is running for Snappy daemon [1 min 30s ] 解决办法 1.修改以下配置文件超时时间,如下: sudo ...
- Peer Review
What are Peng (Bob) Chi's top 3 strengths? Can you give an example of how one or two of those stren ...
- Qt实现collapsePanel(折叠)功能
实践过程中,看到C#实现的CollapsePanel功能,比一般的TabWidget更加直观,充分利用了页面空间,遂感到很有兴趣,也查阅了很多资料搜索Qt在这方面的实现. 目前来说,比较常见的作法就是 ...
- xshell和xftp绿色版下载
下载地址:https://www.xshell.com/zh/free-for-home-school/ 点击后页面如下,输入自己的姓名和邮箱然后点击下载即可.登录自己的邮箱获取下载链接.
- DorisSQL与MySQL函数对照 差异篇
## 1.日期函数### 时区.```mysql -> convert_tz(dt,from_tz,to_tz)doris -> CONVERT_TZ(DATETIME dt, VARCH ...
- 西瓜书3.3 尝试解题(python)对率回归 极大似然估计
数据如下: x01=[0.697,0.774,0.634,0.608,0.556,0.403,0.481,0.437,0.666,\ 0.243,0.245,0.343,0.639,0.657,0.3 ...
- 关于JUnit
目录 一.单元测试 二.在LAB中的常用方法 一.单元测试 什么是单元测试呢?单元测试就是针对最小的功能单元编写测试代码.Java程序最小的功能单元是方法,因此,对Java程序进行单元测试就是针对单个 ...