NeurIPS 2022:基于语义聚合的对比式自监督学习方法
摘要:该论文将同一图像不同视角图像块内的语义一致的图像区域视为正样本对,语义不同的图像区域视为负样本对。
本文分享自华为云社区《[NeurIPS 2022]基于语义聚合的对比式自监督学习方法》,作者:Hint 。

1.研究背景
近些年来,利用大规模的强标注数据,深度神经网络在物体识别、物体检测和物体分割任务中取得巨大进展。然而,强标注数据耗时又耗力。为此,自监督学习方法提出从大量的无标注数据中学习出高效的特征编码器,然后利用该特征编码器在小规模数据上进行强监督训练,以此达到和在大规模强标注数据上训练的模型相当的性能。基于对比式自监督学习方法的出发点为:从不同视角来观察图像,将来自同一图像的不同视角的图像块视为正样本对,来自不同图像的图像块视为负样本对,通过拉近正样本对的特征的距离,拉远负样本对的特征的距离来监督特征编码器的学习。
然而,以上方法的基本假设(正样本对,即同一图像的不同视角的图像块,具有相同的语义)在以物体为中心的数据集(ImageNet)中成立,在以场景为中心的数据集(同一图像中包含多个物体,如COCO)中难以成立。为此,该论文将同一图像不同视角图像块内的语义一致的图像区域视为正样本对,语义不同的图像区域视为负样本对。
2.方法
本文方法和MoCo的框架类似,不同的是,本文将每类物体定义为一个可学习的类别向量S,根据类别向量S和图像特征图的每个位置计算相识度,聚合图像中同一类别的特征,然后将聚合后的类别特征构成正负样本对来进行对比训练学习。具体的网络结构如图1所示,其步骤包括:
- 同一图像经过数据增强得到不同的视角图像块,并分别输入图像编码器得到特征图;
- 将类别特征向量S和图像特征图计算每个位置的相似度,并根据相似度聚合得到图像中每个类别的特征;
- 得到两个视角下的聚合的类别特征后,拉近同类别特征间的距离,拉远不同类别特征之间的距离;
- 与此同时,拉近两个视角下,重叠图像区域的特征间的距离。
经过迭代训练后,图像特征编码器能够建模不同类别之间的语义特征,使得图像编码器更鲁棒。
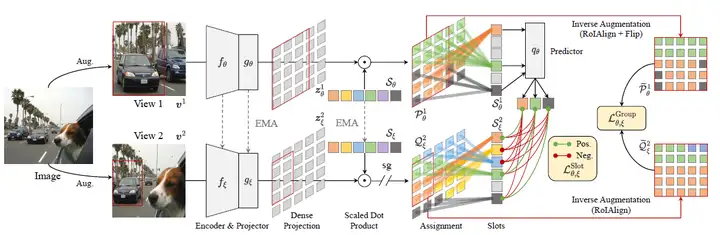
图1:SlotCon的流程图
3.实验结果:
主要实验结果如下表所示,可以看出,无论在目标检测还是分割任务上,该方法高出当前Image-level和Pixel-level的方法许多,证明了基于Object/Group-level的方法的优越性。另外,和Object/Group-level的方法相比,能够高出SOTA方法1.0%左右,表明了本文中可学习语义聚合方法的优势。
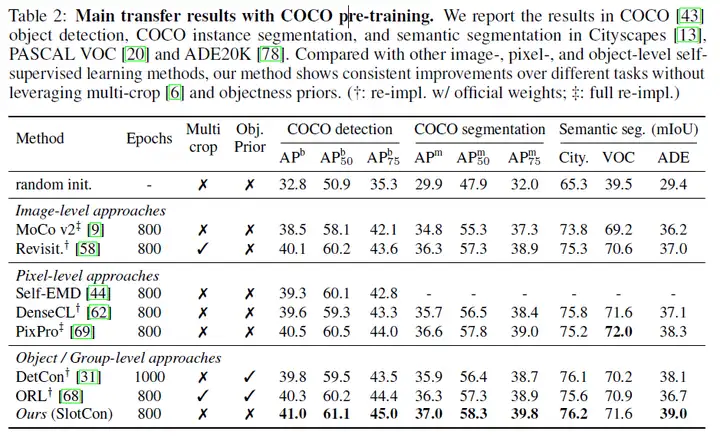
图2展示了无监督分割的定量和定性结果,该方法在此任务上取得不错性能。其mIoU值高出当前无监督分割方法3.92%。
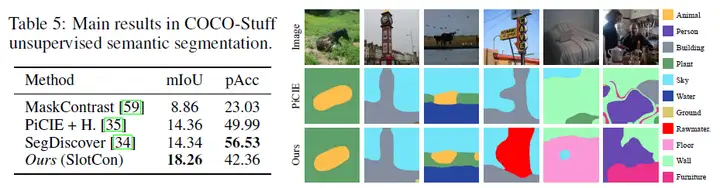
图2:无监督语义分割
图3展示了类别向量S和图像特征之间的相似度。可以看出,学习出的类别向量和图像中相应类别物体具有较高的相似度,说明图像特征编码器编码了较高的语义特征。

图3:类别特征向量S和图像特征间的相似度,红色区域为相似度较高区域
论文链接:[2205.15288] Self-Supervised Visual Representation Learning with Semantic Grouping (arxiv.org)
NeurIPS 2022:基于语义聚合的对比式自监督学习方法的更多相关文章
- 知识图谱顶会论文(ACL-2022) ACL-SimKGC:基于PLM的简单对比KGC
12.(2022.5.4)ACL-SimKGC:基于PLM的简单对比KGC 12.(2022.5.4)ACL-SimKGC:基于PLM的简单对比KGC 摘要 1.引言 2.相关工作 2.1 知识图补全 ...
- 基于语义感知SBST的API场景测试智能生成
摘要:面对庞大服务接口群,完备的接口测试覆盖和业务上下文场景测试看护才有可能保障产品服务的质量和可信.如果你想低成本实现产品和服务的测试高覆盖和高质量看护,这篇文章将为你提供你想要的. 本文分享自华为 ...
- 基于NodeJS的全栈式开发
前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们重新思考了“前后端”的定义,引入前端同学都熟悉的 NodeJS,试 ...
- (转)也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
原文链接:http://ued.taobao.org/blog/2014/04/full-stack-development-with-nodejs/ 随着不同终端(pad/mobile/pc)的兴起 ...
- 也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们重新思考了“前后端”的定义,引入前端同学都熟悉的NodeJS,试图 ...
- 任务驱动,Winform VS WEB对比式学习.NET开发系列第一篇------身份证解析(不断更新的WEB版本及Winform版本源码)
一 本系列培训随笔适用人群 1. 软件开发初学者 2. 有志于转向Web开发的Winform程序员 3. 想了解桌面应用开发的Web程序员 二 高效学习编程的办法 1 任务驱动方式学习软件开发 大部分 ...
- 基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离) 前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们 ...
- 任务驱动,对比式学习.NET开发系列之开篇------开源2个小框架(一个Winform框架,一个Web框架)
一 源码位置 1. Winform框架 2. web框架 二 高效学习编程的办法 1 任务驱动方式学习软件开发 大部分人学习软件开发技术是通过看书,看视频,听老师上课的方式.这些方式有一个共同点即按知 ...
- 从基于 SQL 的 CURD 操作转移到基于语义 Web 的 CURD 操作
中文名称 CURD 含义 数据库技术中的缩写词 操作对象 一般的项目开发的各种参数 作用 用于处理数据的基本原子操作 它代表创建(Create).更新(Update).读取(Retrieve) ...
- 基于GPS数据建立隐式马尔可夫模型预测目的地
<Trip destination prediction based on multi-day GPS data>是一篇在2019年,由吉林交通大学团队发表在elsevier期刊上的一篇论 ...
随机推荐
- Docker MySql 查看版本的三种方法
目录 Docker MySql 查看版本的三种方法 1.mysql -V命令查看版本 2.status命令查看版本 3.version命令查看版本 Docker MySql 查看版本的三种方法 1.m ...
- echarts中setOption没有重新渲染表格
setOption是merge,而非赋值,所以第二次setOption后,实际是更新了option setOption支持notMerge为true的方案,但是需要全量更新option(性能不好): ...
- 前端程序员学习 Golang gin 框架实战笔记之一开始玩 gin
原文链接 我是一名五六年经验的前端程序员,现在准备学习一下 Golang 的后端框架 gin. 以下是我的学习实战经验,记录下来,供大家参考. https://github.com/gin-gonic ...
- Libgdx游戏开发(2)——接水滴游戏实现
原文:Libgdx游戏开发(2)--接水滴游戏实现 - Stars-One的杂货小窝 本文使用Kotlin语言开发 通过本文的学习可以初步了解以下基础知识的使用: Basic file access ...
- 记一次 .NET 某电子病历 CPU 爆高分析
一:背景 1.讲故事 前段时间有位朋友微信找到我,说他的程序出现了 CPU 爆高,帮忙看下程序到底出了什么情况?图就不上了,我们直接进入主题. 二:WinDbg 分析 1. CPU 真的爆高吗? 要确 ...
- .NET 采用 SkiaSharp 生成二维码和图形验证码及图片进行指定区域截取方法实现
在最新版的 .NET 平台中,微软在逐步放弃 System.Drawing.Imaging ,给出的理由如下: System.Drawing命名空间对某些操作系统和应用程序类型有一些限制. 在Wind ...
- doecker---制作DockerFile并上传Hub
一.DockerFile基础知识 FROM #基础镜像,一切从这里开始构建 MAINTAINER #镜像是谁写的,姓名+邮箱 RUN #镜像构建的时候需要运行的命令 ADD #添加内容,步骤,tomc ...
- FJOI2007轮状病毒 行列式递推详细证明
题目链接 题目给了你一个奇怪的图,让你求它的生成树个数. 开始写了一个矩阵树: #include<cstdio> #include<cstdlib> #include<c ...
- golang中经常会犯的一些错误
0.1.索引 https://waterflow.link/articles/1664080524986 1.未知的枚举值 我们现在定义一个类型是unit32的Status,他可以作为枚举类型,我们定 ...
- Android 13 新特性及适配指南
Android 13(API 33)于 2022年8月15日 正式发布(发布时间较往年早了一些),正式版Release源代码也于当日被推送到AOSP Android开源项目. 截止到笔者撰写这篇文章时 ...