Java 流处理之收集器
Java 流(Stream)处理操作完成之后,我们可以收集这个流中的元素,使之汇聚成一个最终结果。这个结果可以是一个对象,也可以是一个集合,甚至可以是一个基本类型数据。
以记录 Record 为例:
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Record {
private String col1;
private String col2;
private int col3;
}
记录 Record 包含三个属性:列1(col1)、列2(col2)和 列3(col3)。
创建四个记录实例:
Record r1 = new Record("a", "1", 1);
Record r2 = new Record("a", "2", 2);
Record r3 = new Record("b", "3", 3);
Record r4 = new Record("c", "4", 4);
添加到列表:
List<Record> records = new ArrayList<>();
records.add(r1);
records.add(r2);
records.add(r3);
records.add(r4);
收集所有记录的 列1 值,以列表形式存储结果
List<String> col1List = records.stream()
.map(Record::getCol1)
.collect(Collectors.toList());
log.info("col1List: {}", Json.toJson(col1List));
输出结果:
col1List: ["a","a","b","c"]
收集所有记录的 列1 值,且去重,以集合形式存储
Set<String> col1Set = records.stream()
.map(Record::getCol1)
.collect(Collectors.toSet());
log.info("col1Set: {}", Json.toJson(col1Set));
输出结果:
col1Set: ["a","b","c"]
收集记录的 列2 值和 列3 值的对应关系,以字典形式存储
Map<String, Integer> col2Map = records.stream()
.collect(Collectors.toMap(Record::getCol2, Record::getCol3));
log.info("col2Map: {}", Json.toJson(col2Map));
输出结果:
col2Map: {"1":1,"2":2,"3":3,"4":4}
记录的 列2 不能有重复值,否则会抛出 Duplicate key 异常。
收集所有记录中 列3 值最大的记录
Record max = records.stream()
.collect(Collectors.maxBy(Comparator.comparing(Record::getCol3)))
.orElse(null);
log.info("max: {}", Json.toJson(max));
输出结果:
max: {"col1":"c","col2":"4","col3":4}
收集所有记录中 列3 值的总和
int sum = records.stream()
.collect(Collectors.summingInt(Record::getCol3));
log.info("sum: {}", sum);
输出结果:
sum: 10
流的收集需要通过 Stream.collect() 方法完成,方法的参数是一个 Collector(收集器);收集结果时,需要根据收集结果的目标类型,传递特定的收集器实例,如上:
- Collectors.toList()
- Collectors.toSet()
- Collectors.toMap()
- Collectors.maxBy()
- Collectors.summingInt()
Collectors(java.util.stream.Collectors) 是一个工具类,内置若干收集器,我们可以通过调用不同的方法快速获取相应的收集器实例。
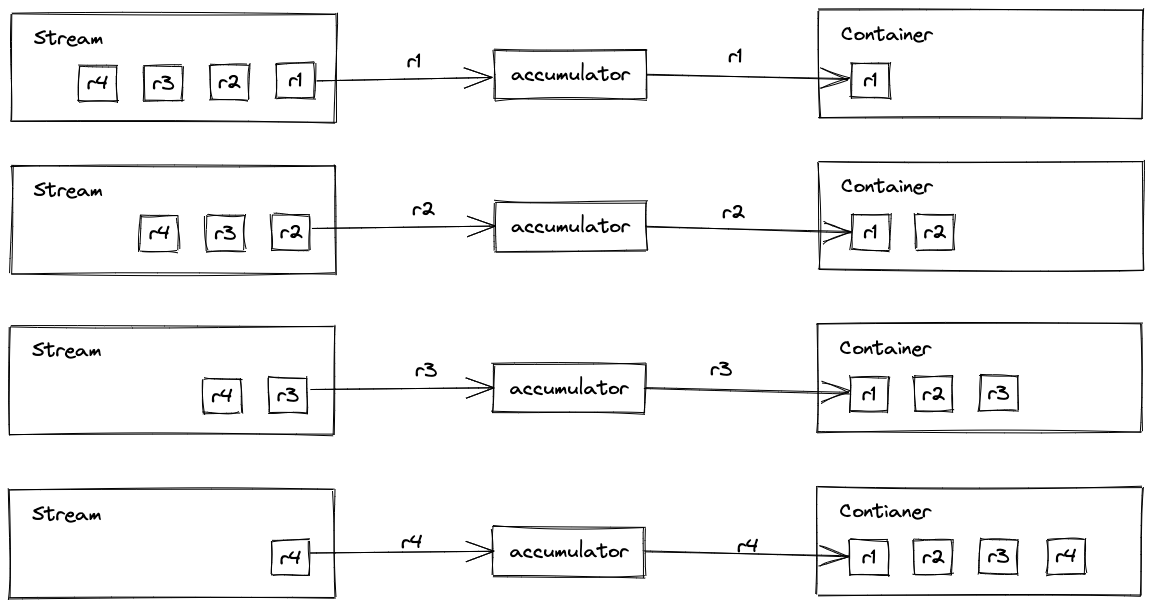
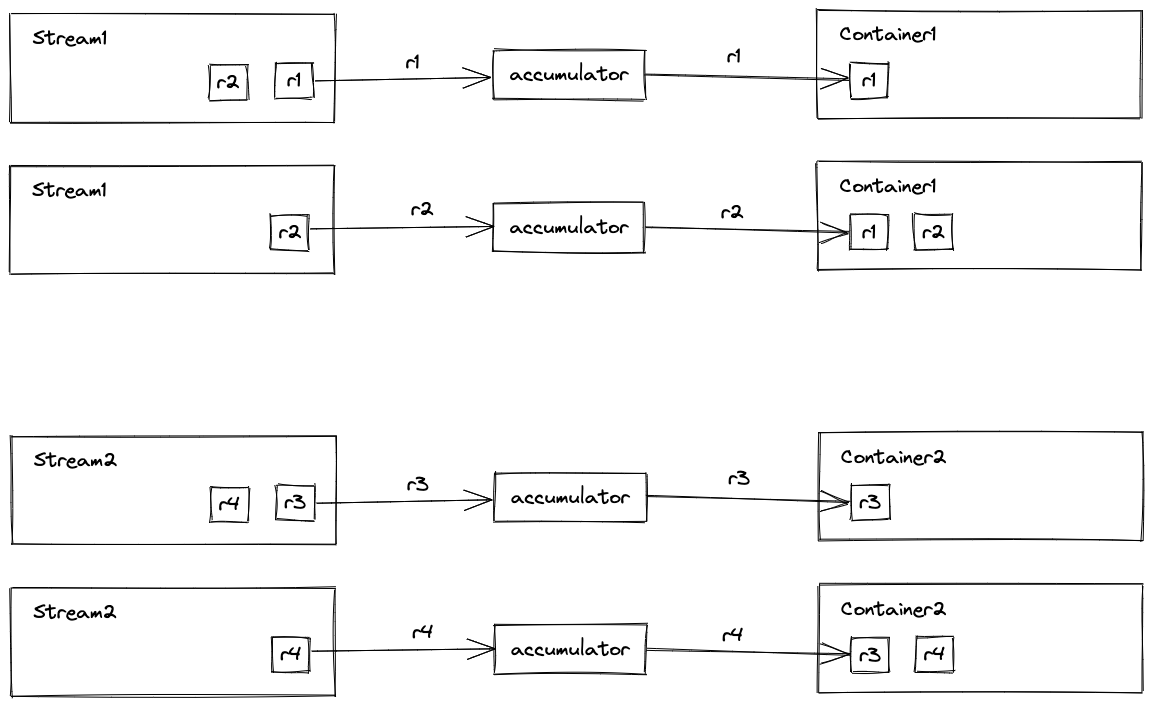
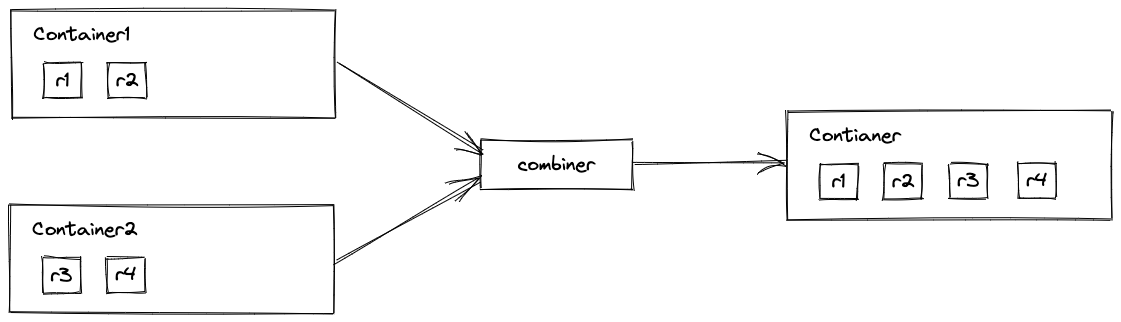
收集器(java.util.stream.Collector)本质是一个 接口,包含以下五个方法:


Java 流处理之收集器的更多相关文章
- JAVA流式布局管理器--JAVA基础
JAVA流式布局管理器的使用: FlowLayoutDeme.java: import java.awt.*;import javax.swing.*;public class FlowLayoutD ...
- JAVA 流式布局管理器
//流式布局管理器 import java.awt.*; import javax.swing.*; public class Jiemian2 extends JFrame{ //定义组件 JBut ...
- 深入理解Java虚拟机03--垃圾收集器与内存分配策略
一.概述 哪些内存需要回收? 什么时候回收? 如何回收? 二.对象已死吗 1.引用计数算法 定义:给对象添加一个引用计数器,当增加一个引用时,加1,当一个引用时,减1; 缺陷:当对象之间互相循环 ...
- [一] java8 函数式编程入门 什么是函数式编程 函数接口概念 流和收集器基本概念
本文是针对于java8引入函数式编程概念以及stream流相关的一些简单介绍 什么是函数式编程? java程序员第一反应可能会理解成类的成员方法一类的东西 此处并不是这个含义,更接近是数学上的 ...
- JAVA8给我带了什么——流的概念和收集器
到现在为止,笔者不敢给流下定义,从概念来讲他应该也是一种数据元素才是.可是在我们前面的代码例子中我们可以看到他更多的好像在表示他是一组处理数据的行为组合.这让笔者很难去理解他的定义.所以笔者不表态.各 ...
- Stream01 定义、迭代、操作、惰性求值、创建流、并行流、收集器、stream运行机制
1 Stream Stream 是 Java 8 提供的一系列对可迭代元素处理的优化方案,使用 Stream 可以大大减少代码量,提高代码的可读性并且使代码更易并行. 2 迭代 2.1 需求 随机创建 ...
- Java GC收集器配置说明
根据Java GC收集器具体分类,我们可以看出JVM根据需求不同提供了三种选择:串行收集器.并行收集器.并发收集器. 串行收集器只适用于小数据量的情况,我们主要了解一下并行收集器和并发收集器.默认情况 ...
- JAVA G1收集器 第11节
JAVA G1收集器 第11节 上两章我们讲了新生代和年老代的收集器,那么这一章的话我们就要讲一个收集范围涵盖整个堆的收集器——G1收集器. 先讲讲G1收集器的特点,他也是个多线程的收集器,能够充分利 ...
- JAVA 年老代收集器 第10节
JAVA 年老代收集器 第10节 上一章我们讲了新生代的收集器,那么这一章我们要讲的就是关于老年代的一些收集器.老年代的存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域 ...
随机推荐
- python做小游戏——做个马里奥分分钟解决
一.前言 嗨喽,大家好呀!这里是小熊猫 在你的童年记忆里,是否有一个蹦跳.顶蘑菇的小人已经被遗忘? 马里奥是靠吃蘑菇成长,闻名世界的超级巨星.特征是大鼻子.头戴帽子.身穿背带工作服.还留着胡子.帽子加 ...
- python写个前端,这不是轻轻松松~
前端除了用js++css+html,还有没有其它办法?其实python也可以 1. 安装与基本流程 Python学习交流Q群:660193417### 安装 PyWebIO 和其他的第三方库一样使用p ...
- 本地拉取服务器上的项目,SVN 由于目标计算机积极拒绝 无法连接失败
下面几种解决方案一定一定一定都要试一下哈, 比如,如果你的SVN没有启动,并且防火墙也开启了,那么你即便启动了SVN,也是无法拉取项目的,需要把防火墙也关闭. 1.是否启动了svn 输入命令查看是否启 ...
- Linux for CentOS 下的 nginx 绿色安装-超省心安装
1.我这里是nginx-1.13.0-1.x86_64 .rpm(点击下载)版本的. 2.安装nginx的相应环境.有些环境可能不必须,但是安装了,确保以防万一,多多益善 yum install gd ...
- 5.RDD操作综合实例
一.词频统计 A. 分步骤实现 1.准备文件 (1)下载小说或长篇新闻稿 (2)上传到hdfs上 2.读文件创建RDD 3.分词 4. ·排除大小写lower(),map() ·标点符号re.spli ...
- SVM简要介绍
SVM 支持向量机(SVM),是一个用于解决二分类问题的有监督机器学习模型. 1.SVM的两个优点 更高的速度 在有一定的样本数量支持下(成千上万张),具有比其他模型有更好的效果 2.SVM的工作过程 ...
- 运行Flutter时连接超时
这个墙不知道浪费了开发者多少的时间!!!!!!!!!!!!!!!!!!! 1.修改仓库地址为阿里仓库: 编辑android/build.gradle,把文件中的两处: google() jcenter ...
- SQLZOO练习(一)SELECT BASICS,SELECT form world
name continent area population gdp Afghanistan Asia 652230 25500100 20343000000 Albania Europe 28748 ...
- 基于SqlSugar的开发框架循序渐进介绍(12)-- 拆分页面模块内容为组件,实现分而治之的处理
在早期的随笔就介绍过,把常规页面的内容拆分为几个不同的组件,如普通的页面,包括列表查询.详细资料查看.新增资料.编辑资料.导入资料等页面场景,这些内容相对比较独立,而有一定的代码量,本篇随笔介绍基于V ...
- Mybatis源码解读-SpringBoot中配置加载和Mapper的生成
本文mybatis-spring-boot探讨在springboot工程中mybatis相关对象的注册与加载. 建议先了解mybatis在spring中的使用和springboot自动装载机制,再看此 ...