Python数据科学手册-机器学习: 支持向量机
support vector machine SVM
是非常强大、 灵活的有监督学习算法, 可以用于分类和回归。
贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签。是属于 生成分类 方法。
判别分类:不再为每类数据建模,而是用一条分割线 或者 流形体 将各种类型分开。
原始数据:
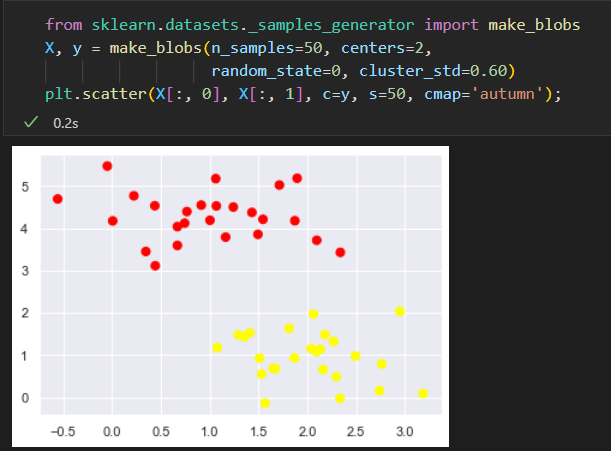
线性判别分类器 尝试 化一条 将数据 分成 俩部分的直线,这样就构成了一个分类模型。
可以发现不止一条直线可以将它们完美分割。
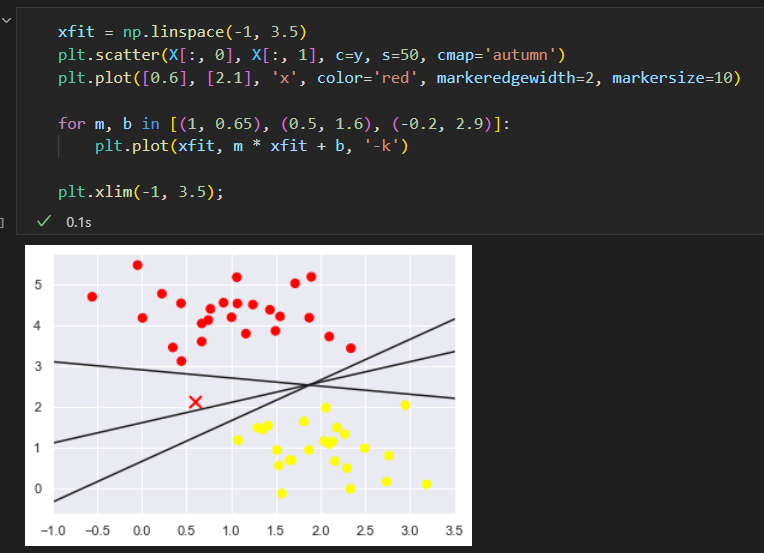
不同的分割线,会让新数据分配到不同的标签。
支持向量机:边界最大化
不是画一条细线来区分,而是画一条到最近点 边界 、有宽度 的线条。
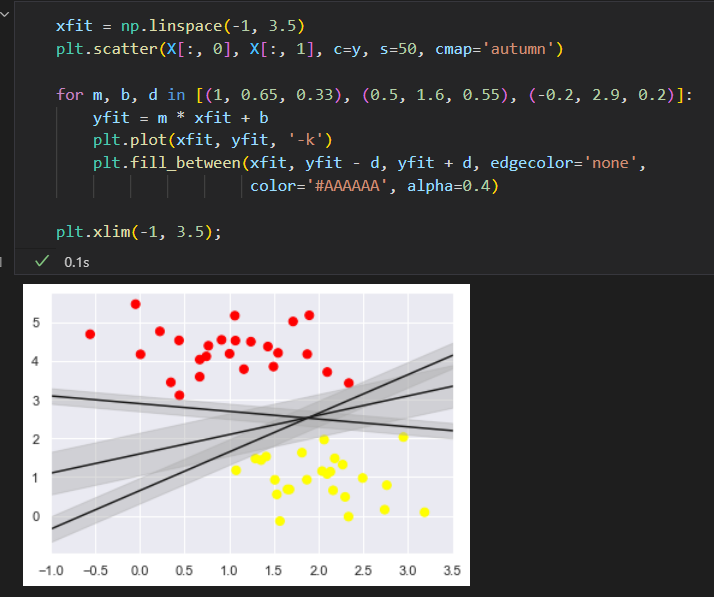
在支持向量机中,选择边界最大的那条线,是模型最优解。 边界最大化评估器。
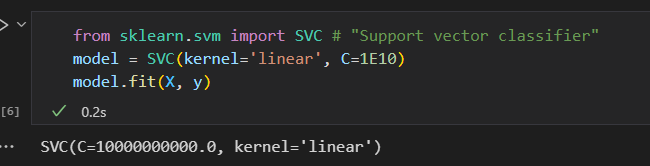
拟合支持向量机
训练一个SVM模型,用一个线性核函数。并将参数C设置为一个很大的数。
创建一个辅助函数画出SVM的决策边界。
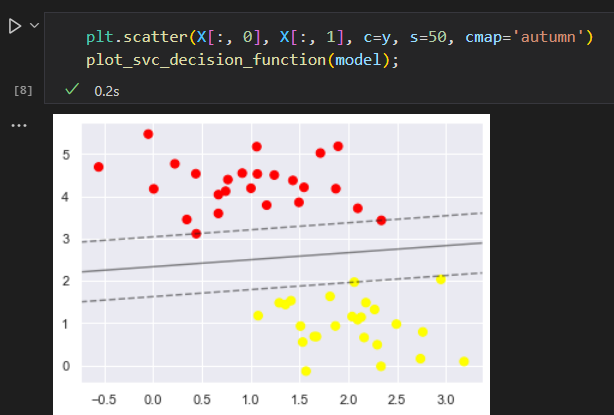
一些点正好在边界线上,这些点是拟合的关键支持点。被称为支持向量
支持向量的左边存放在分类器的support_vectors_ 属性中。
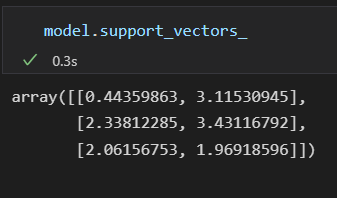
说明:任何在正确分类一侧远离边界线的点都不影响拟合结果。 因为这些点不会对拟合模型的损失函数产生任何影响,只要它们没跨越边界线,位置和数量就都无关紧要。
超越线性边界:核函数 SVM模型
将SVM模型 与 核函数 组合使用。功能会非常强大。
为了应用核函数,引入一些非线性可分数据。
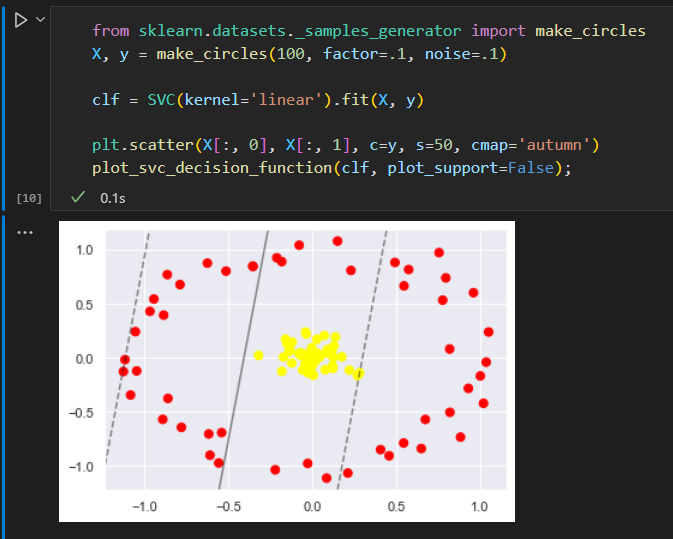
前面学到过,把数据投影到高维空间。从而使线性分割器派上用场。
一个简单的投影方法就是计算一个以 数据圆圈 为中心的径向基函数:
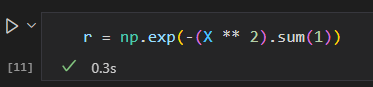
用三维图来可视化新增的维度
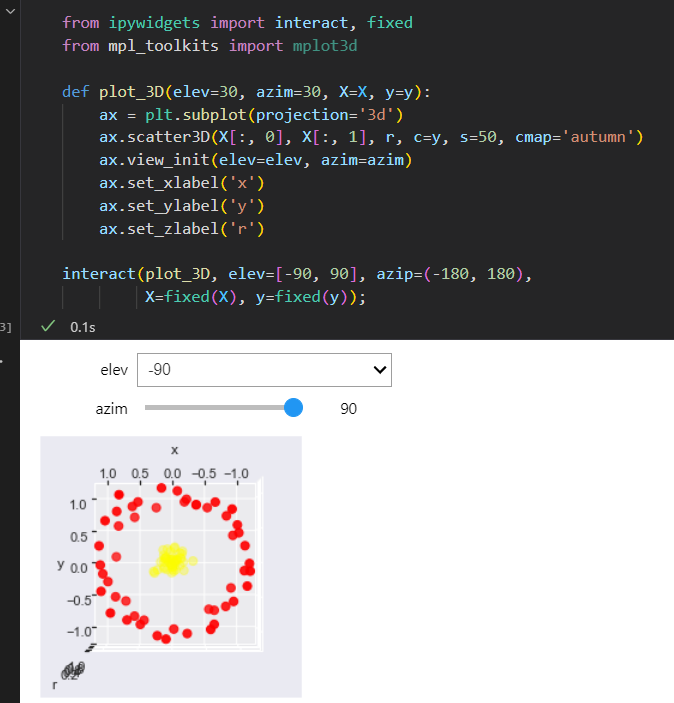
增加新的维度后,数据变成了线性可分状态,
通常选择基函数比较困难,我们需要让模型自动 指出 最合适的基函数。
一种 策略是计算基函数在数据集 上每个点的 变换结果,让SVM算法从所有结果中筛选出最优解。
这种基函数变换方式被称为 核变换
问题是:当N不断增大的时候,就会出现维度灾难。计算量巨大,
由于核函数技巧提供的小程序可以隐式计算 核变换数据的拟合。
在Scikit-Learn里面,我们可以应用核函数化的SVM模型,将线性核转变为 RBF (径向基函数)核。 设置kernel模型超参数即可。
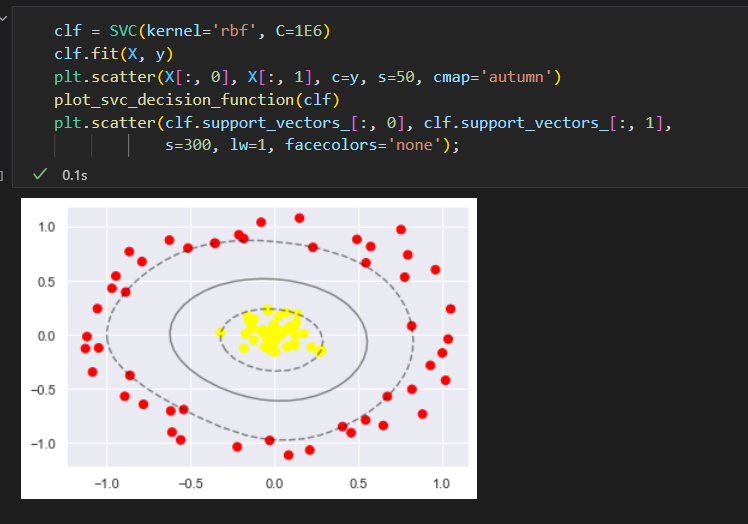
SVM优化:软化边界
如果数据有重叠,SVM实现了一些修正因子来“软化”边界,为了取得更好的拟合效果,允许一些点位于边界线之内。
边界线的硬度可以通过超参数进行控制,通常是C,
如果C很大,边界就会很硬,数据点便不能在边界内生存,
如果C比较小,边界就会较软,有一些数据点就可以穿越边界线。
案例:人脸识别
支持向量机总结
优点:
- 模型依赖的支持向量比较少,说明它们都是非常精致的模型,消耗内存少。
- 一旦模型训练完成,预测阶段速度非常快
- 由于模型只收边界线附近 的 点的影响,因此它们对于高维数据的学习效果非常好
- 与核函数方法的配合 极具通用性,能够适用不同类型的数据
缺点: - 随着样本量N的不断增加,最差的训练时间复杂度会达到O[N^3] .大样本学习的计算成本高
- 训练效果非常依赖于边界软化参数C的选择是否合理,这需要通过交叉检验自行搜索
Python数据科学手册-机器学习: 支持向量机的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- 最小生成树 链式前向星 Prim&Kruskal
Prim: Prim的思想是将任意节点作为根,再找出与之相邻的所有边(用一遍循环即可),再将新节点更新并以此节点作为根继续搜,维护一个数组:dis,作用为已用点到未用点的最短距离. 证明:Prim算法 ...
- Halcon 模板匹配实战代码(一)
模板图片:目标是获取图像左上角位置的数字 直接想法,直接用一个框将数字框出来,然后对图片进行模板匹配(不可行,因为图像中的数字不是固定的) 所以需要选择图像中的固定不变的区域来作为模板,然后根据模板区 ...
- 静态static关键字修饰成员方法和静态static的内存图
当 static 修饰成员方法时,该方法称为类方法 .静态方法在声明中有 static ,建议使用类名来调用,而不需要 创建类的对象.调用方式非常简单 ~类方法:使用 static关键字修饰的成员方法 ...
- Solution -「树上杂题?」专练
主要是记录思路,不要被刚开始错误方向带偏了 www 「CF1110F」Nearest Leaf 特殊性质:先序遍历即为 \(1 \to n\),可得出:叶子节点编号递增或可在不改变树形态的基础上调整为 ...
- day04_数组
数组 学习目标: 1. jvm内存图入门 2. 一维数组的使用 3. 二维数组的使用 4. 数组的内存结构 5. 数组中常见算法 6. 数组中常见的异常 一.JVM内存图入门 java程序运行在jvm ...
- P4289 【一本通提高篇广搜的优化技巧】[HAOI2008]移动玩具
[HAOI2008]移动玩具 题目描述 在一个 4 × 4 4\times4 4×4 的方框内摆放了若干个相同的玩具,某人想将这些玩具重新摆放成为他心中理想的状态,规定移动时只能将玩具向上下左右四个方 ...
- 安卓系统使用USB转串口
概述 安卓系统支持多种 USB 外围设备,提供两种模式来支持实现 USB 外设接入系统:USB 配件模式和 USB 主机模式. 在 USB 配件模式下,接入的 USB 设备充当 USB 主机,并为 U ...
- python不同平台进程的启动与终止
Liunx进程的启动与终止 在使用subprocess创建进程时需要将所有进程设置为一个进程组 preexec_fn:只在 Unix 平台下有效,用于指定一个可执行对象(callable object ...
- mosquitto使用的基本流程以及一些遇见的问题
改配置文件 以记事本的方式打开mosquitto.conf更改部分内容,找到# listener port-number [ip address/host name/unix socket path] ...
- 【JAVA UI】HarmonyOS 如何使用TinyPinyin类库
参考资料 前言:TinyPinYin是一个适用于Java和Android.HarmonyOS的快速,低内存的汉字转拼音库.码云地址TinyPinYin,其使用方法已在API讲解中有详细介绍,本文 ...