详解MySQL分区表
当数据库数据量涨到一定数量时,性能就成为我们不能不关注的问题,如何优化呢? 常用的方式不外乎那么几种:
1、分表,即把一个很大的表达数据分到几个表中,这样每个表数据都不多。
优点:提高并发量,减小锁的粒度
缺点:代码维护成本高,相关sql都需要改动
2、分区,所有的数据还在一个表中,但物理存储数据根据一定的规则存放在不同的文件中,文件也可以放到另外磁盘上
优点:代码维护量小,基本不用改动,提高IO吞吐量
缺点:表的并发程度没有增加
3、拆分业务,这个本质还是分表。
优点:长期支持更好
缺点:代码逻辑重构,工作量很大
当然,每种情况都有合适的应用场景,需要根据具体业务具体选择。由于分表和拆分业务和mysql本身关系不大属于业务层面,我们只说和数据库关系最紧密的方式:表分区。不过使用表分区有个前提就是你的数据库必须支持。那么,怎么知道我的数据库是否支持表分区呢 ? 请执行下面命令
show plugins; ---在mysql控制台中执行
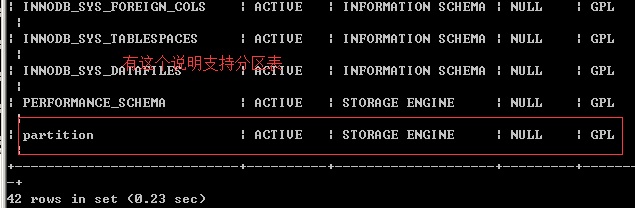
据说5.4一下的版本是另外一个命令,不过我没有测试
show variables like '%part%';
数据库的表分区一般有两种方式:纵向和横向。纵向就是把表中不同字段分到不同数据文件中。横向是把表中前一部分数据放到一个文件中,另一部分数据放到一个文件中。mysql只支持后后一种方式,横向拆分。
根据所使用的不同分区规则可以分成几大分区类型。
RANGE 分区:
基于属于一个给定连续区间的列值,把多行分配给分区。
LIST 分区:
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
HASH分区:
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式。
KEY
分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
复合分区:
基于RANGE/LIST 类型的分区表中每个分区的再次分割。子分区可以是 HASH/KEY 等类型。
三、 mysql分区表常用操作示例
以部门员工表为例子:
1) 创建range分区
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date,
salary int
)
partition by range(salary)
(
partition p1 values less than (1000),
partition p2 values less than (2000),
partition p3 values less than maxvalue
);
以员工工资为依据做范围分区。
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by range(year(birthdate))
(
partition p1 values less than (1980),
partition p2 values less than (1990),
partition p3 values less than maxvalue
);
以year(birthdate)表达式(计算员工的出生日期)作为范围分区依据。这里最值得注意的是表达式必须有返回值。
2) 创建list分区
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by list(deptno)
(
partition p1 values in (10),
partition p2 values in (20),
partition p3 values in (30)
);
以部门作为分区依据,每个部门做一分区。
3) 创建hash分区
HASH分区主要用来确保数据在预先确定数目的分区中平均分布。在RANGE和LIST分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中;而在HASH分区中,MySQL 自动完成这些工作,你所要做的只是基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by hash(year(birthdate))
partitions 4;
4) 创建key分区
按照KEY进行分区类似于按照HASH分区,除了HASH分区使用的用户定义的表达式,而KEY分区的哈希函数是由MySQL 服务器提供,服务器使用其自己内部的哈希函数,这些函数是基于与PASSWORD()一样的运算法则。“CREATE TABLE ...PARTITION BY KEY”的语法规则类似于创建一个通过HASH分区的表的规则。它们唯一的区别在于使用的关键字是KEY而不是HASH,并且KEY分区只采用一个或多个列名的一个列表。
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by key(birthdate)
partitions 4;
5) 创建复合分区
range - hash(范围哈希)复合分区
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by range(salary)
subpartition by hash(year(birthdate))
subpartitions 3
(
partition p1 values less than (2000),
partition p2 values less than maxvalue
);
range- key复合分区
create table emp
(empno varchar(20) not null ,
empname varchar(20),
deptno int,
birthdate date not null,
salary int
)
partition by range(salary)
subpartition by key(birthdate)
subpartitions 3
(
partition p1 values less than (2000),
partition p2 values less than maxvalue
);
list - hash复合分区
CREATE TABLE emp (
empno varchar(20) NOT NULL,
empname varchar(20) ,
deptno int,
birthdate date NOT NULL,
salary int
)
PARTITION BY list (deptno)
subpartition by hash(year(birthdate))
subpartitions 3
(
PARTITION p1 VALUES in (10),
PARTITION p2 VALUES in (20)
)
;
list - key 复合分区
CREATE TABLE empk (
empno varchar(20) NOT NULL,
empname varchar(20) ,
deptno int,
birthdate date NOT NULL,
salary int
)
PARTITION BY list (deptno)
subpartition by key(birthdate)
subpartitions 3
(
PARTITION p1 VALUES in (10),
PARTITION p2 VALUES in (20)
)
;
6) 分区表的管理操作
删除分区:
alter table emp drop partition p1;
不可以删除hash或者key分区。
一次性删除多个分区,alter table emp drop partition p1,p2;
增加分区:
alter table emp add partition (partition p3 values less than (4000));
alter table empl add partition (partition p3 values in (40));
分解分区:
Reorganizepartition关键字可以对表的部分分区或全部分区进行修改,并且不会丢失数据。分解前后分区的整体范围应该一致。
alter table te
reorganize partition p1 into
(
partition p1 values less than (100),
partition p3 values less than (1000)
); ----不会丢失数据
合并分区:
Merge分区:把2个分区合并为一个。
alter table te
reorganize partition p1,p3 into
(partition p1 values less than (1000));
----不会丢失数据
重新定义hash分区表:
Alter table emp partition by hash(salary)partitions 7;
----不会丢失数据
重新定义range分区表:
Alter table emp partitionbyrange(salary)
(
partition p1 values less than (2000),
partition p2 values less than (4000)
); ----不会丢失数据
删除表的所有分区:
Alter table emp removepartitioning;--不会丢失数据
重建分区:
这和先删除保存在分区中的所有记录,然后重新插入它们,具有同样的效果。它可用于整理分区碎片。
ALTER TABLE emp rebuild partitionp1,p2;
优化分区:
如果从分区中删除了大量的行,或者对一个带有可变长度的行(也就是说,有VARCHAR,BLOB,或TEXT类型的列)作了许多修改,可以使用“ALTER TABLE ... OPTIMIZE PARTITION”来收回没有使用的空间,并整理分区数据文件的碎片。
ALTER TABLE emp optimize partition p1,p2;
分析分区:
读取并保存分区的键分布。
ALTER TABLE emp analyze partition p1,p2;
修补分区:
修补被破坏的分区。
ALTER TABLE emp repairpartition p1,p2;
检查分区:
可以使用几乎与对非分区表使用CHECK TABLE 相同的方式检查分区。
ALTER TABLE emp CHECK partition p1,p2;
这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。
【mysql分区表的局限性】
1. 在5.1版本中分区表对唯一约束有明确的规定,每一个唯一约束必须包含在分区表的分区键(也包括主键约束)。
CREATE TABLE emptt (
empno varchar(20) NOT NULL ,
empname varchar(20),
deptno int,
birthdate date NOT NULL,
salary int ,
primary key (empno)
)
PARTITION BY range (salary)
(
PARTITION p1 VALUES less than (100),
PARTITION p2 VALUES less than (200)
);
这样的语句会报错。MySQL Database Error: A PRIMARY KEY must include allcolumns in the table's partitioning function;
CREATE TABLE emptt (
empno varchar(20) NOT NULL ,
empname varchar(20) ,
deptno int(11),
birthdate date NOT NULL,
salary int(11) ,
primary key (empno,salary)
)
PARTITION BY range (salary)
(
PARTITION p1 VALUES less than (100),
PARTITION p2 VALUES less than (200)
);
在主键中加入salary列就正常。
2. MySQL分区处理NULL值的方式
如果分区键所在列没有notnull约束。
如果是range分区表,那么null行将被保存在范围最小的分区。
如果是list分区表,那么null行将被保存到list为0的分区。
在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。
3. 分区键必须是INT类型,或者通过表达式返回INT类型,可以为NULL。唯一的例外是当分
区类型为KEY分区的时候,可以使用其他类型的列作为分区键( BLOB or TEXT 列除外)。
4. 对分区表的分区键创建索引,那么这个索引也将被分区,分区键没有全局索引一说。
5. 只有RANG和LIST分区能进行子分区,HASH和KEY分区不能进行子分区。
6. 临时表不能被分区。
四、 获取mysql分区表信息的几种方法
1. show create table 表名
可以查看创建分区表的create语句
2. show table status
可以查看表是不是分区表
3. 查看information_schema.partitions表
select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='test';
可以查看表具有哪几个分区、分区的方法、分区中数据的记录数等信息
4. explain partitions select语句
通过此语句来显示扫描哪些分区,及他们是如何使用的.
五、 分区表性能比较
1. 创建两张表: part_tab(分区表),no_part_tab(普通表)
CREATE TABLEpart_tab
( c1 int defaultNULL, c2 varchar2(30) default NULL, c3 date not null)
PARTITION BYRANGE(year(c3))
(PARTITION p0VALUES LESS THAN (1995),
PARTITION p1 VALUESLESS THAN (1996) ,
PARTITION p2 VALUESLESS THAN (1997) ,
PARTITION p3 VALUESLESS THAN (1998) ,
PARTITION p4 VALUES LESS THAN (1999) ,
PARTITION p5 VALUESLESS THAN (2000) ,
PARTITION p6 VALUESLESS THAN (2001) ,
PARTITION p7 VALUESLESS THAN (2002) ,
PARTITION p8 VALUESLESS THAN (2003) ,
PARTITION p9 VALUESLESS THAN (2004) ,
PARTITION p10VALUES LESS THAN (2010),
PARTITION p11VALUES LESS THAN (MAXVALUE) );
CREATE TABLE no_part_tab
( c1 int defaultNULL, c2 varchar2(30) default NULL, c3 date not null);
2. 用存储过程插入800万条数据
CREATE PROCEDUREload_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end;
insert into no_part_tab select * frompart_tab;
3. 测试sql性能
查询分区表:
selectcount(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----------+
| count(*) |
+----------+
| 795181 |
+----------+
1 row in set (2.62 sec)
查询普通表:
selectcount(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----------+
| count(*) |
+----------+
| 795181 |
+----------+
1 row in set (7.33 sec)
分区表的执行时间比普通表少70%。
4. 通过explain语句来分析执行情况
mysql>explain select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----+-------------+----------+------+---------------+------+---------+------+---------+-------------+
| id |select_type | table | type |possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+------+---------+------+---------+-------------+
| 1 | SIMPLE | part_tab | ALL | NULL | NULL | NULL | NULL | 7980796 | Using where |
+----+-------------+----------+------+---------------+------+---------+------+---------+-------------+
1 rowin set
mysql>explain select count(*) from no_part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----+-------------+-------------+------+---------------+------+---------+------+---------+-------------+
| id |select_type | table | type |possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+------+---------------+------+---------+------+---------+-------------+
| 1 | SIMPLE | no_part_tab | ALL | NULL | NULL | NULL | NULL | 8000206 | Using where |
+----+-------------+-------------+------+---------------+------+---------+------+---------+-------------+
1 rowin set
mysql >
分区表执行扫描了7980796行,而普通表则扫描了8000206行。
详解MySQL分区表的更多相关文章
- [深入学习Web安全](5)详解MySQL注射
[深入学习Web安全](5)详解MySQL注射 0x00 目录 0x00 目录 0x01 MySQL注射的简单介绍 0x02 对于information_schema库的研究 0x03 注射第一步—— ...
- MySQL数据类型 int(M) 表示什么意思?详解mysql int类型的长度值问题
MySQL 数据类型中的 integer types 有点奇怪.你可能会见到诸如:int(3).int(4).int(8) 之类的 int 数据类型.刚接触 MySQL 的时候,我还以为 int(3) ...
- Mysql常用show命令,show variables like xxx 详解,mysql运行时参数
MySQL中有很多的基本命令,show命令也是其中之一,在很多使用者中对show命令的使用还容易产生混淆,本文汇集了show命令的众多用法. 详细: http://dev.mysql.com/doc/ ...
- MySQL存储过程详解 mysql 存储过程
原文地址:MySQL存储过程详解 mysql 存储过程作者:王者佳暮 mysql存储过程详解 1. 存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储 ...
- 【文章阅读】详解MySQL数据类型
详解MySQL数据类型 - 五月的仓颉 - 博客园 http://www.cnblogs.com/xrq730/p/8446246.html 注:对于MySQL的数据类型做了详细的讲解,这是我看过的最 ...
- 详解Mysql分布式事务XA(跨数据库事务)
详解Mysql分布式事务XA(跨数据库事务) 学习了:http://blog.csdn.net/soonfly/article/details/70677138 mysql执行XA事物的时候,mysq ...
- 详解MySQL索引
原文链接详解MySQL索引 索引介绍 索引是帮助MySQL高效获取数据的数据结构.在数据之外,数据库系统还维护着一个用来查找数据的数据结构,这些数据结构指向着特定的数据,可以实现高级的查找算法. 本文 ...
- 详解MySQL中EXPLAIN解释命令
Explain 结果解读与实践 基于 MySQL 5.0.67 ,存储引擎 MyISAM . 注:单独一行的"%%"及"`"表示分隔内容,就象分开“第一 ...
- MySQL存储过程详解 mysql 存储过程(二)
mysql存储过程详解 1. 存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL ...
随机推荐
- Sqlmap脱库之“你的数据我所见”
废话不多说,介绍和理论啥的网上一搜一大把,一次只为tuoku. 实战操作: 1.在网上找个index.php?id=1的站点 2.很明显看到了脱下裤子的希望,sqlmap走一把.查看数据库 3.怎么看 ...
- Java集合框架源码(二)——hashSet
注:本人的源码基于JDK1.8.0,JDK的版本可以在命令行模式下通过java -version命令查看. 在前面的博文(Java集合框架源码(一)——hashMap)中我们详细讲了HashMap的原 ...
- apache设置无缓存
打开httpd.conf 开启扩展 确保开启 LoadModule headers_module modules/mod_headers.so 添加配置项 并添加以下配置,跟据文件类型来让浏览器每次都 ...
- zabbix企业应用之windows系统安装omsa硬件监控
具体请参考 作者:dl528888http://dl528888.blog.51cto.com/2382721/1421335 大致 1.安装OMSA http://zh.community.de ...
- 数据库系统概论(1)——Chap. 1 Introduction
数据库系统概论--Introduction 一.数据库的4个基本概念 数据(data):数据是数据库中存储的基本单位.我们把描述事物的符号记录称为数据.数据和关于数据的解释是不可分的,数据的含义称为数 ...
- Bootstrap modal使用及点击外部不消失的解决方法
这篇文章主要为大家详细介绍了Bootstrap modal使用及点击外部不消失的解决方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 本文实例为大家分享了Bootstrap modal使用及点击 ...
- python_函数的可变参数
def test(*args,**kwargs): print(args) print(kwargs) test(1,2,3,x=1,y=2) 运行结果: *args称为positional argu ...
- Linux内核中TCP SACK机制远程DoS预警通告
漏洞描述 2019年6月18日,RedHat官网发布报告:安全研究人员在Linux内核处理TCP SACK数据包模块中发现了三个漏洞,CVE编号为CVE-2019-11477.CVE-2019-114 ...
- JS的type类型为 text/template
JS标签中有时候会看见<script type="text/tmplate" >,大概就是一个放置模板的地方,而这些东西并不显示在页面 在js里面,经常需要使用js往页 ...
- P2347 砝码称重(动态规划递推,背包,洛谷)
题目链接:P2347 砝码称重 参考题解:点击进入 纪念我第一道没理解题意的题 ''但不包括一个砝码也不用的情况'',这句话我看成了每个砝码起码放一个 然后就做不出来了 思路: 1.这题数据很小,10 ...