再谈spark部署搭建和企业级项目接轨的入门经验(博主推荐)
进入我这篇博客的博友们,相信你们具备有一定的spark学习基础和实践了。
先给大家来梳理下。spark的运行模式和常用的standalone、yarn部署。这里不多赘述,自行点击去扩展。
2、Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
3、Spark standalone简介与运行wordcount(master、slave1和slave2)
4、Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
5、Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
正文开始
想说的是,对于spark的配置文件,即spark-env.sh。压根可以不做任何修改和配置。(当然我指的是常用和固定的那些参数)


#!/bin/sh home=$(cd `dirname $0`; cd ..; pwd)
bin_home=$home/bin
conf_home=$home/conf
logs_home=$home/logs
data_home=$home/data
lib_home=$home/lib #服务器配置文件
configFile=${conf_home}/my1.properties spark_submit=/home/hadoop/spark/bin/spark-submit

#!/bin/sh
deleteCheckpoint=$1
home=$(cd `dirname $0`; cd ..; pwd)
. ${home}/bin/common.sh
hdfs dfs -rm -r /spark-streaming/behavior/stop
if [ "$deleteCheckpoint" == "delck" ]; then
hdfs dfs -rm -r /spark-streaming/checkpoint/behavior
fi
${spark_submit} \
--master yarn \
--deploy-mode cluster \
--name behavior \
--driver-memory 512M \
--executor-memory 512M \
--class com.djt.spark.streaming.UserBehaviorStreaming \
${lib_home}/behavior-stream-jar-with-dependencies.jar ${configFile} \
>> ${logs_home}/behavior.log 2>&1 &
echo $! > ${logs_home}/behavior_stream.pid

#!/bin/sh
home=$(cd `dirname $0`; cd ..; pwd)
. ${home}/bin/common.sh
hdfs dfs -mkdir -p /spark-streaming/behavior/stop

然后,直接将这个本地写好的目录,上传到集群
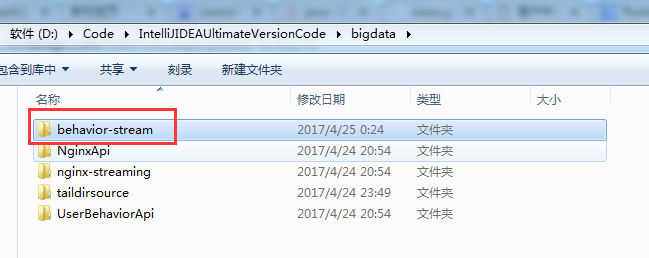
后续很简单,不多说。
藏经阁技术资料分享群二维码
再谈spark部署搭建和企业级项目接轨的入门经验(博主推荐)的更多相关文章
- 用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
不多说,直接上干货! 为什么要写这篇博客? 首先,对于spark项目,强烈建议搭建,用Intellij IDEA(Ultimate版本),如果你还有另所爱好尝试Scala IDEA for Eclip ...
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
- CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- 大数据搭建各个子项目时配置文件技巧(适合CentOS和Ubuntu系统)(博主推荐)
不多说,直接上干货! 很多同行,也许都知道,对于我们大数据搭建而言,目前主流,分为Apache 和 Cloudera 和 Ambari. 后两者我不多说,是公司必备和大多数高校科研环境所必须的! 分别 ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- 基于CentOS6.5下snort+barnyard2+base的入侵检测系统的搭建(图文详解)(博主推荐)
为什么,要写这篇论文? 是因为,目前科研的我,正值研三,致力于网络安全.大数据.机器学习研究领域! 论文方向的需要,同时不局限于真实物理环境机器实验室的攻防环境.也不局限于真实物理机器环境实验室的大数 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
- Ubuntu16.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu LTS \n \l r ...
- Ubuntu14.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu 14.04.4 LTS ...
随机推荐
- 携程Apollo(阿波罗)配置中心Spring Boot迁移日志组件,使用配置中心进行管理的思路
说明: 1.Spring Boot项目默认使用logback进行日志管理 2.logback在启动时默认会自动检查是否有logback.xml文件,如果有时会有限加载这个文件. 3.那么如果是用配置中 ...
- zookeeper客户端
查看具体结点信息 bash zkServer.sh status 查看哪个结点被选作leader或者followerecho stat|nc 127.0.0.1 2181 测试是否启动了该Server ...
- sublime text 3(Build 3103)最新注冊码
原来注冊过的sublime text 3近期更新了.没想到原来的注冊码就失效了,只是我找到了最新的注冊码(Build 3103),与大家分享一下(第一个亲測可用). -– BEGIN LICENSE ...
- HOST绑定和VIP映射
今天上线需要配置RAL,处理半天,发现是需要HOST和IP分开来配. 比如: curl -H "Host: ktvin.nuomi.com" "http://10.207 ...
- 【转】海量数据处理算法-Bloom Filter
1. Bloom-Filter算法简介 Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.它是一个判断元素是否存在于 ...
- 纠结的链接——ln、ln -s、fs.symlink、require
纠结的链接--ln.ln -s.fs.symlink.require 提交 我的留言 加载中 已留言 inode 我们首先来看看 linux 系统里面的一个重要概念:inode. 我们知道,文件存储在 ...
- UILable怎样加入单击事件
//初始化UILable UILabel *lable = [[UILabel alloc] initWithFrame:CGRectMake(60, 0, 320, 40)]; //设置其能够接收用 ...
- MySQL基础笔记(一) SQL简介+数据类型
MySQL是一个关系型数据库管理系统(RDBMS),它是当前最流行的 RDBMS 之一.MySQL分为社区版和企业版,由于其体积小.速度快.总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发 ...
- STM32 USB复合设备编写
目的 完成一个CDC + MSC的复合USB设备 可以方便在CDC,MSC,复合设备三者间切换 可移植性强 预备知识 cube中USB只有两个入口. main函数中的MX_USB_DEVICE_Ini ...
- MySQL 温故而知新--Innodb存储引擎中的锁
近期碰到非常多锁问题.所以攻克了后,细致再去阅读了关于锁的书籍,整理例如以下:1,锁的种类 Innodb存储引擎实现了例如以下2种标准的行级锁: ? 共享锁(S lock),同意事务读取一行数据. ? ...