Auto-Scaling Web Applications in Clouds: A Taxonomy and Survey读书笔记
这篇文章是发在2018年CSUR上的一篇文章,主要是讲虚拟机上web应用的auto-scaling技术的分类
近年来许多web 应用服务商将他们的应用迁移到云数据中心,为什么要迁移到云上呢?其中一个重要的原因就是云数据中心的资源的弹性伸缩,这可以让他们根据实时的需求获取或者释放计算资源,降低运营成本。为了更高效地实现弹性伸缩,就引出本文讨论的一种技术:auto-scaling
那什么是auto-scaling呢?
Auto-scaling是一种在无需人工干预的情况下,根据实时工作负载自动调整资源供给的技术,它能够实现在满足服务质量(QoS)需求的同时最小化云资源使用成本。
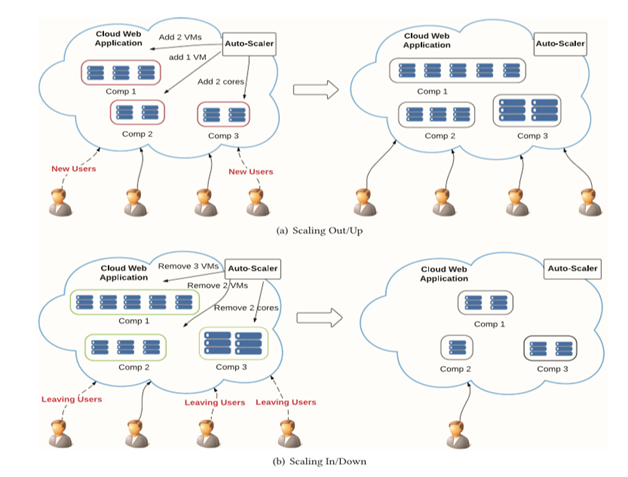
目前auto-scaling技术主要有四个阶段来完成

因此在分类的时候在这四个阶段的基础上进行分类
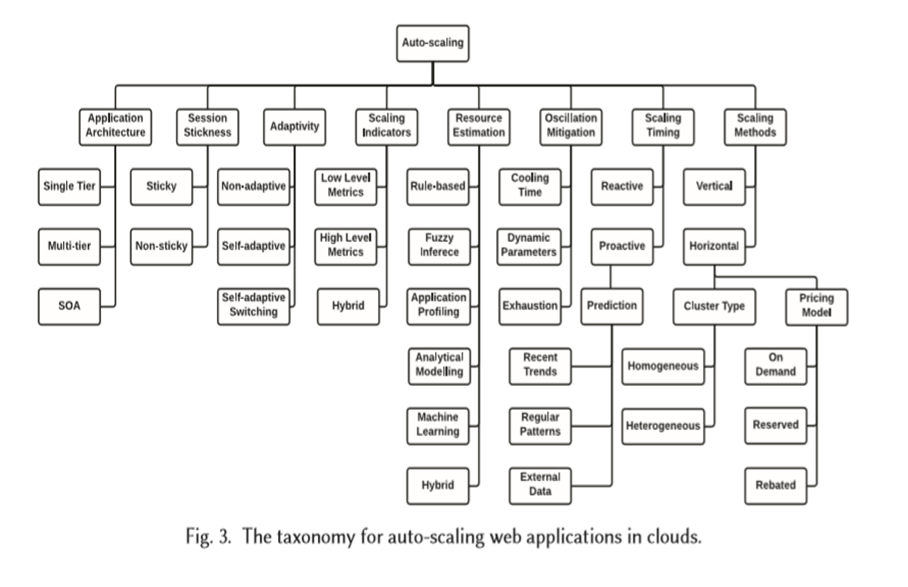
Scaling Indicators
Auto-scaler的行为基于监控阶段获得的应用该性能指标
① Low-level Metrics (physical/hypervisor)
- 监控CPU利用率、内存、缺页率
- 仅仅看一些物理上的指标难以精确推断应用程序性能
② High-Level Metrics(application)
- 监控平均响应时间、会话创建率、吞吐量、服务时间、请求组合
- 难以精确推断需要的资源总数
③ Hybrid Metrics
同时监控Low-level Metrics 和High-Level Metrics
Scaling Timing
① Reactive Scaling
- 仅依据当前的应用和负载状态进行伸缩
- 适用于工作负载变化比较小的应用
② Proactive Scaling
- 在伸缩时考虑应用未来的资源需求
- 适用于有规律的工作负载变化较大的应用
- 除考虑历史工作负载外,还可考虑外部因素,如户外应用需考虑天气情况
如果工作负载没有规律,Proactive无法进行预测,还是要用Reactive,因此auto-scaler无论支持不支持Proactive,都应该能进行Reactive Scaling
Scaling Methods
① Vertical Scaling
- 以虚拟机内部资源为单位(CPU,存储)
- 大多数厂商不支持
- 扩展速度比垂直扩展快
- 适用于一些不适合垂直扩展的部分
② Horizontal Scaling
- 以虚拟机为单位
- 价格模型
- On-demand:固定价格
- Reserved:交一部分定金以获得更便宜的价格
- Rebated:售卖空闲资源,非常优惠,随时可以回收
③ Hybrid
只有在水平扩展收到限制时才使用垂直扩展
Application Architectures
① Single Tier / Single Service
- 分层软件栈中最小可部署组件
- 可管理的最小粒度
实际应用中只有一层或只有一个服务的web应用是很少的,因此Single Tier常被当做是可管理的最小粒度,现今大多数的auto-scaling系统都是分别管理web应用的每一层,而不是以一个整体管理。这就有一个问题,虽然每层是最佳的资源配置,但从整体来看不一定是最佳的资源配置
② Multitier
- Front-end
- Application logic
- Database( 忽视)
多层应用通常包括以上三层,各层之间顺序连接,可以将总体的SLA划分成每一层的SLA。因为大多数云服务提供商都不支持不支持水平扩展,通常database不会进行auto-scaling
③ Service-Based Architectures
- Service-Oriented Architecture (SOA)
- Microservices Architecture
Service-based在大型的web应用中已占据主导地位,各独立的服务通过各自预先定义的接口进行交互。服务之间不是顺序连接的,那它怎么做auto-scaling呢?
它要求每一个服务都要估计一个实例被添加或删除时的响应时间的变化。在此之后,系统会聚合估计,并选择将最小总体响应时间的操作。
Session Stickiness
会话(Session):用户与应用之间的一系列交互行为
在每一次操作之后,用户都要等待应用的应答,然后继续执行。
粘性(Stickiness):如果会话数据存储在服务器中,每次在会话中提交请求时,迫使用户连接到同一台服务器
① Sticky
② Non-sticky
粘性会限制auto-scaling系统的能力。因为如果如果有未完成的会话时,它们会限制auto-scaler终止没有充分利用资源的实例
那要怎么解决这个问题呢?一个方法是可以把会话数据存储在用户端,或者存储在一个共享的虚拟机上
Adaptivity
对生产环境、工作负载变化的适应能力
① Nonadaptive
- 预先确定控制模型,不允许在生产时自动调整
- 需要做大量的线下测试才能获取合适的控制模型
- 要求用户定义一组伸缩的条件和离线操作,并且Nonadaptive它只根据即时的输入进行决策,只有当满足预先设定的条件时,才进行伸缩操作
② Self-Adaptive
- 预先确定核心控制模型(线性\非线性),具体操作自动调整
- 自动调整需要比较长的时间,前期表现较差
③ Self-Adaptive Switching
连接多个Nonadaptive和Self-Adaptive,根据性能选择控制模型
Resource Estimation
① Rule-Based Approaches
- 一组包含触发条件和对应行为的预定义规则
- 难以设置合适阈值和对应行为,无法适应应用的动态变化
例如CPU利用率超过70%,增加两个实例,如果CPU利用率低于40%,减少一个实例
比如说一开始一个应用由四个实例提供资源,那这时候增加一个实例就可以提升25%的能力提升。之后因为工作负载的激增,由十个实例来提供资源,这时增加一个实例只能带来10%的能力提升。
此外固定的阈值也可能会带来低效的资源呢利用,70%和40%的资源利用率可能适合于只有实例较少的云,但是对于实例比较多的云,一个单独的实例的增减可能对整体的资源利用率并不明显,因此在资源利用率低于40%之前就可能要移除比较多的实例
② Fuzzy Inference
触发条件语义化(高,中,低)
输入首先使用定义的成员函数进行模糊化;然后,模糊化的输入被用来在所有规则中同时触发动作部分;然后将规则的结果组合在一起,最后将其作为控制决策的输出
③ Application Profiling
寻找资源的饱和点
l Offline :每次应用更新都需要手动重新执行一次
l Online :禁止细粒度的性能分析,要求尽可能快
从每一应用层中获得资源估计模型。当对一层进行性能分析时,给其他层足够的资源,一个接一个,最后得到模型
④ Analytical Modeling
Analytical Modeling是根据理论和分析建立数学模型的过程
基于排队理论/排队网络
A:到达队列的时间间隔分布 Markov/General
S:处理工作所需要的时间分配 Markov/Deterministic/General
C:服务器的数量
⑤ Machine Learning
- Reinforcement Learning(Q-learning)
- Regression(Linear)
学习的时间长,初期表现差,并且收敛的时间难以预测
强化学习目的是让软件系统学习如何在特定的环境中进行自适应的反应,以最大化其收益。学习算法选择一个单独的操作,然后观察结果。如果结果是正的,那么在遇到类似情况时,自动定标器将更有可能采取相同的动作。
回归估计变量之间的关系。它根据观察到的数据生成一个函数然后用它来进行预测,要求用户决定函数类型,
⑥ Hybrid Approaches
- Machine Learning + Fuzzy rules-based inference
- Machine Learning + Analytical model
- 选择不同的指标和不同的机器学习算法
对web应用来说以上的几种都有他的优点和缺点,因此一些工作将多种方式整合在一起用来资源预测Rule在应用发生变化时不灵活,并且需要专业知识来进行设计和测试,如果rules由机器学习算法来动态生成一些分析队列模型需要一些难以直接测量的性能指标请求服务时间,请求组合,在机器学习的收敛前用其他算法代替
Oscillation Mitigation
波动(Oscillation):auto-scaler不断地执行相反的操作,当监控或缩放操作过于频繁时,或者规则配置不当(区间太小)有可能会发生
① Cooling Time
- 固定等待时间
- 延长等待时间
② Dynamic Parameters
当大多数资源被用来降低目标的使用率时,提高它的下降的阈值
③ Exhaustion
如果可以找到造成波动的设定,那就可以在这些设定上做限制
Environment
① Single Cloud
上面讲的都是single云的情况
② Multiple Coluds
① 在每一个数据中心都部署一整个应用
② 在不同的数据中心分别部署应用的某个部分
③ 优势:
- 降低延迟,在距离用户最近的云中心进行服务
- 提高可靠性,多个云同时备份
- 在auto-scaling时考虑地区选择和请求路径
未来的发展方向
① Service-Based Architectures
缺少精确的资源估计模型,实时计算出每一个服务应该被提供的资源
② Monitoring Tools for Hidden Parameters.
计算一些不能直接获得的数据:平均服务时间,请求组合
③ Resource Estimation Models
需要提高现在的资源估计模型的精确度,通用性和易用性。认为将分析模型和机器学习相结合最有前景
④ Provisioning Using Rebated Pricing Models
星云
⑤ Better Vertical Scaling Support
同一个物理机内部延迟比较低,可以对database进行auto-scaliing
⑥ Event-Based Workload Prediction
考虑天气,双十一等事件
⑦ Energy and Carbon-Aware Auto-Scaling
⑧ Container-Based Auto-Scalers
Auto-Scaling Web Applications in Clouds: A Taxonomy and Survey读书笔记的更多相关文章
- 《web全栈工程师的自我修养》读书笔记
有幸读了yuguo<web全栈工程师的自我修养>,颇有收获,故在此对读到的内容加以整理,方便指导,同时再回顾一遍书中的内容. 概览 整本书叙述的是作者的成长经历,通过经验的分享,给新人或者 ...
- 《Web全栈工程师的自我修养》读书笔记(转载)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/5 ...
- System Operations on AWS - Lab 6W - Using Auto Scaling (Windows)
创建你的一个web server,然后将这个实例制成你的AMI,通过启动配置生成一个Auto Scaling组(包括scale-in/scale-out策略),配置一台Load Balancer指向你 ...
- 如何使用 AWS Auto Scaling 按需动态增加和减少实例
目录 一.背景需求 二.配置步骤 2.1.创建 AMI 2.2.创建负载均衡目标组 2.3.创建 Classic Load Balancer 2.4.创建启动配置 2.5.创建 Auto Scalin ...
- Model-View-Controller(MVC) is an architectural pattern that frequently used in web applications. Which of the following statement(s) is(are) correct?
Model-View-Controller(MVC) is an architectural pattern that frequently used in web applications. Whi ...
- Progressive Web Applications
Progressive Web Applications take advantage of new technologies to bring the best of mobile sites an ...
- Developing RIA Web Applications with Oracle ADF
Developing RIA Web Applications with Oracle ADF Purpose This tutorial shows you how to build a ric ...
- Setting up Scatter for Web Applications
[Setting up Scatter for Web Applications] If you are still using scatter-js please move over to scat ...
- [Windows Azure] Developing Multi-Tenant Web Applications with Windows Azure AD
Developing Multi-Tenant Web Applications with Windows Azure AD 2 out of 3 rated this helpful - Rate ...
随机推荐
- RHEL 6.5----SCSI存储
主机名 IP master 192.168.30.130 node-1 192.168.30.131 node-2 192.168.30.132 安装并启动 [root@master ~]# ll / ...
- Suricata里的规则与Snort区别之处
不多说,直接上干货! 见官网 https://suricata.readthedocs.io/en/latest/rules/differences-from-snort.html
- [转]2010 Ruby on Rails 書單 與 練習作業
原帖:http://wp.xdite.net/?p=1754 ========= 學習 Ruby on Rails 最快的途徑無非是直接使用 Rails 撰寫產品.而這個過程中若有 mentor 指導 ...
- poj2377 Bad Cowtractors
思路: 最大生成树. 实现: #include <iostream> #include <cstdio> #include <vector> #include &l ...
- 程序员必须知道FTP命令
程序员必须知道FTP命令 文件传输软件的使用格式为:FTP<FTP地址>,若连 接成功,系统将提示用户输入 ...
- c++正则表达式模板库GRETA的使用
GRETA是微软研究院的一位前员工开发并开源的一个C++正则表达式库,兼容perl正则语法 官方介绍:“A fast, flexible, perl-compliant regular express ...
- 深入解析Web Services
SOA,面向服务器建构,是一款架构,这几年虽然没前几年那么流行,但是还是有很多企业在用,而Web Services是目前适合做SOA的主要技术之一,通过使用Web Services,应用程序可以对外发 ...
- 推荐一个以动画效果显示github提交记录的黑科技工具:Gource
程序员每天都会使用到git的一系列命令.其中用git log命令可以查看提交历史记录: 今天Jerry给大家推荐一款视觉效果非常酷炫的工具,名叫Gource,是一个能够将git代码仓库的提交历史以动画 ...
- Android(java)学习笔记186:多媒体之视频播放器
1. 这里我们还是利用案例演示视频播放器的使用: (1)首先,我们看看布局文件activity_main.xml,如下: <RelativeLayout xmlns:android=" ...
- Python小记-- 读取当前目录下所有文件名
# -*- coding: utf-8 -*- import os def file_name(file_dir): with open("SelectAllFiles.txt", ...