Spark 大数据文本统计
此程序功能:
1.完成对10.4G.csv文件各个元素频率的统计
2.获得最大的统计个数
3.对获取到的统计个数进行降序排列
4.对各个元素出现次数频率的统计
import org.apache.spark.{SparkConf, SparkContext}
/**
*/
object 大数据统计 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("大数据").setMaster("local[4]")
val sc=new SparkContext(conf)
// val text= sc.textFile("/home/soyo/桌面/shell编程测试/1.txt")
val text= sc.textFile("/home/soyo/下载/Hadoop+Spark+Hbase/all2.csv")
//text.foreach(println)
val wordcount= text.flatMap(line=>line.split(",")).map(word=>(word,))
.reduceByKey((a,b)=>a+b)
wordcount.collect().foreach(println)
// wordcount.saveAsTextFile("/home/soyo/桌面/shell编程测试/1-1-1.txt")
println("单独文件中各个数的统计个数")
// wordcount.map(_._2).foreach(println)
println("获取统计的最大数")
// wordcount.map(_._2).saveAsTextFile("/home/soyo/下载/Hadoop+Spark+Hbase/77.txt")
println(wordcount.map(_._2).max())
println("对获取到的数降序排列")
wordcount.map(_._2).sortBy(x=>x,false).foreach(println) //false:降序 true:升序
println("转变为key-value形式")
wordcount.map(_._2).map(num=>(num,)).reduceByKey((a,b)=>a+b).foreach(println)
println("对key-value按key再排序,获得结果表示:假设文件中'soyo5'总共出现10次,可文件'soyo1'也出现10次,最后整个排序获得的是(10,2)10次的共出现2次")
wordcount.map(_._2).map(num=>(num,)).reduceByKey((a,b)=>a+b).sortByKey().foreach(println)
}
}
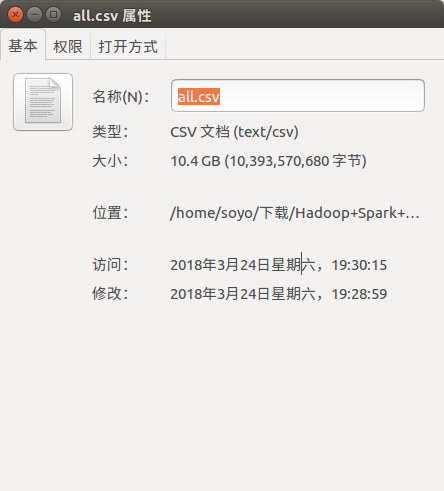
数据内容:
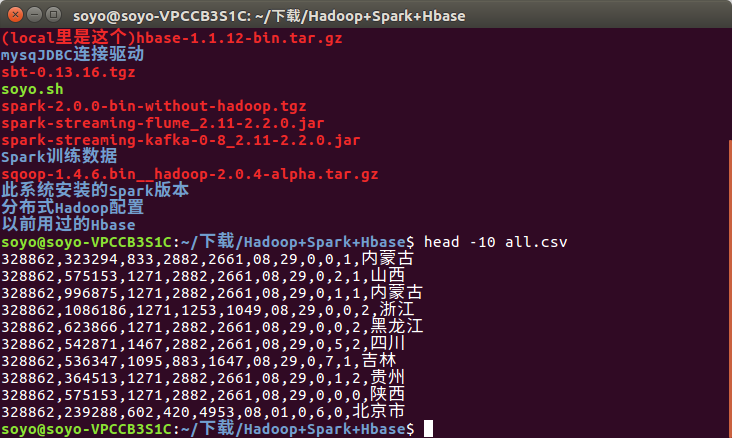
Spark 保存的文件是这样的:
这里可以用一个脚本将这么多的文件进行合并:
#!/bin/bash
cat * >>soyoo.txt
结果太多只写一个:
获取统计的最大数
294887496 (数据中有一个元素出现了这么多次)
Spark 大数据文本统计的更多相关文章
- C#大数据文本高效去重
C#大数据文本高效去重 转载请注明出处 http://www.cnblogs.com/Huerye/ TextReader reader = File.OpenText(@"C:\Users ...
- SQL大数据操作统计
SQL大数据操作统计 1:select count(*) from table的区别SELECT object_name(id) as TableName,indid,rows,rowcnt FROM ...
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- 教你如何成为Spark大数据高手?
教你如何成为Spark大数据高手? Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么如何成为Spark大数据高手?下面就来个深度教程. Spark ...
- Spark大数据针对性问题。
1.海量日志数据,提取出某日访问百度次数最多的那个IP. 解决方案:首先是将这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中.注意到IP是32位的,最多有个2^32个IP.同样可以采 ...
- Azure HDInsight 和 Spark 大数据实战(一)
What is HDInsight? Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Stor ...
- Spark大数据的学习历程
Spark主要的编程语言是Scala,选择Scala是因为它的简洁性(Scala可以很方便在交互式下使用)和性能(JVM上的静态强类型语言).Spark支持Java编程,但对于使用Java就没有了Sp ...
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 小试牛刀ElasticSearch大数据聚合统计
ElasticSearch相信有不少朋友都了解,即使没有了解过它那相信对ELK也有所认识E即是ElasticSearch.ElasticSearch最开始更多用于检索,作为一搜索的集群产品简单易用绝对 ...
随机推荐
- hdu 2845简单dp
/*递推公式dp[i]=MAX(dp[i-1],dp[i-2]+a[j])*/ #include<stdio.h> #include<string.h> #define N 2 ...
- [CodePlus2017]晨跑
Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 166 Solved: 125 Description "无体育,不清华".&qu ...
- 《TCP/IP详解卷1:协议》——第3章 IP:网际协议(转载)
1.引言 IP是TCP/IP协议族中最核心的协议.所有的TCP.UDP.ICMP及IGMP数据都以IP数据报格式传输.IP提供不可靠. 无连接的数据报传送服务. (1)不可靠 它不能保证IP数据报能成 ...
- cobbler ks文件解释--转载
cobbler中ks.cfg文件配置详解 许多系统管理员宁愿使用自动化的安装方法来安装红帽企业 Linux.为了满足这种需要,红帽创建了kickstart安装方法.使用kickstart ...
- [Bzoj1297][Scoi2009 ]迷路 (矩阵乘法 + 拆点)
1297: [SCOI2009]迷路 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1385 Solved: 993[Submit][Status] ...
- Java描述符(修饰符)的类型
以下内容引用自http://wiki.jikexueyuan.com/project/java/modifier-types.html: 描述符(修饰符)是添加到那些定义中来改变他们的意思的关键词.J ...
- CSS3 水波纹
css3 动画设置水波纹,效果如下图: 源码: <!DOCTYPE html> <html lang="en"> <head> <meta ...
- maven生命周期和依赖的范围
转载:http://blog.csdn.net/J080624/article/details/54692444 什么是依赖? 当 A.jar 包用到了 B.jar 包时,A就对B产生了依赖: 在项目 ...
- poj 3468 A Simple Problem with Integers(线段树、延迟更新)
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 74705 ...
- 数据库分表和分库的原理及基于thinkPHP的实现方法
为什么要分表,分库: 当我们的数据表数据量,訪问量非常大.或者是使用频繁的时候,一个数据表已经不能承受如此大的数据訪问和存储,所以,为了减轻数据库的负担,加快数据的存储,就须要将一张表分成多张,及将一 ...