4.3 Writing a Grammar
4.3 Writing a Grammar
Grammars are capable of describing most, but not all, of the syntax of programming languages. For instance, the requirement that identifiers be declared before they are used, cannot be described by a context-free grammar. Therefore, the sequences of tokens accepted by a parser form a superset of the programming language; subsequent phases of the compiler must analyze the output of the parser to ensure compliance with rules that are not checked by the parser.
This section begins with a discussion of how to divide work between a lexical analyzer and a parser. We then consider several transformations that could be applied to get a grammar more suitable for parsing. One technique can eliminate ambiguity in the grammar, and other techniques | left-recursion elimination and left factoring | are useful for rewriting grammars so they become suitable for top-down parsing. We conclude this section by considering some programming language constructs that cannot be described by any grammar.
4.3.1 Lexical Versus Syntactic Analysis
As we observed in Section 4.2.7, everything that can be described by a regular expression can also be described by a grammar. We may therefore reasonably ask: “Why use regular expressions to define the lexical syntax of a language?” There are several reasons.
1. Separating the syntactic structure of a language into lexical and non-lexical parts provides a convenient way of modularizing the front end of a compiler into two manageable-sized components.
2. The lexical rules of a language are frequently quite simple, and to describe them we do not need a notation as powerful as grammars.
3. Regular expressions generally provide a more concise and easier-to-understand notation for tokens than grammars.
4. More efficient lexical analyzers can be constructed automatically from regular expressions than from arbitrary grammars.
There are no firm guidelines as to what to put into the lexical rules, as opposed to the syntactic rules. Regular expressions are most useful for describing the structure of constructs such as identifiers, constants, keywords, and white space. Grammars, on the other hand, are most useful for describing nested structures such as balanced parentheses, matching begin-end’s, corresponding if-then-else’s, and soon. These nested structures cannot be described by regular expressions.
4.3.2 Eliminating Ambiguity
Sometimes an ambiguous grammar can be rewritten to eliminate the ambiguity. As an example, we shall eliminate the ambiguity from the following “dangling-else” grammar:
|
stmt |
→ if expr then stmt | if expr then stmt else stmt | other
|
(4.14)
|
Here “other” stands for any other statement. According to this grammar, the compound conditional statement
|
if E1 then S1 else if E2 then S2 else S3 |
|
|
|
Figure 4.8: Parse tree for a conditional statement |
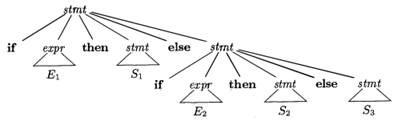
has the parse tree shown in Fig. 4.8. 1 Grammar (4.14) is ambiguous since the string
|
if E1 then if E2 then S1 else S2 |
(4.15) |
has the two parse trees shown in Fig. 4.9.
|
|
|
|
|
Figure 4.9: Two parse trees for an ambiguous sentence |
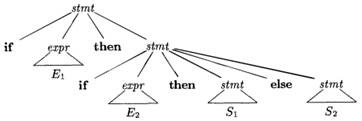
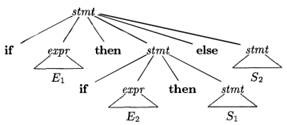
In all programming languages with conditional statements of this form, the first parse tree is preferred. The general rule is, “Match each else with the closest unmatched then.”2 This disambiguating rule can theoretically be incorporated directly into a grammar, but in practice it is rarely built into the productions.
|
1 The subscripts on E and S are just to distinguish different occurrences of the same nonterminal, and do not imply distinct nonterminals. 2 We should note that C and its derivatives are included in this class. Even though the C family of languages do not use the keyword then, its role is played by the closing parenthesis for the condition that follows if. |
Example 4.16: We can rewrite the dangling-else grammar (4.14) as the following unambiguous grammar. The idea is that a statement appearing between a then and an else must be “matched”; that is, the interior statement must not end with an unmatched or open then. A matched statement is either an if-then-else statement containing no open statements or it is any other kind of unconditional statement. Thus, we may use the grammar in Fig. 4.10. This grammar generates the same strings as the dangling-else grammar (4.14), but it allows only one parsing for string (4.15); namely, the one that associates each else with the closest previous unmatched then. □
|
stmt |
→ matched stmt | open stmt |
|
matched_stmt |
→ if expr then matched stmt else matched stmt | other |
|
open_stmt |
→ if expr then stmt | if expr then matched stmt else open stmt |
|
Figure 4.10: Unambiguous grammar for if-then-else statements |
|
4.3.3 Elimination of Left Recursion
A grammar is left recursive if it has a nonterminal A such that there is a derivation A=+>Aα for some string α. Top-down parsing methods cannot handle left-recursive grammars, so a transformation is needed to eliminate left recursion. In Section 2.4.5, we discussed immediate left recursion, where there is a production of the form A → Aα. Here, we study the general case. In Section 2.4.5, we showed how the left-recursive pair of productions A → Aα | β could be replaced by the non-left-recursive productions:
A →βA’
A’ → αA’ | ϵ
without changing the strings derivable from A. This rule by itself suffices for many grammars.
Example 4.17: The non-left-recursive expression grammar (4.2), repeated here,
E → T E’
E’ → + T E’
T → F T’
T’ → * F T’
F → (E) | id
is obtained by eliminating immediate left recursion from the expression grammar (4.1). The left-recursive pair of productions E → E + T | T are replaced by E → T E’ and E’ → + T E’ | ϵ. The new productions for T and T’ are obtained similarly by eliminating immediate left recursion. □
Immediate left recursion can be eliminated by the following technique, which works for any number of A-productions. First, group the productions as
A → A α1 | A α2 | … | A αm |β1 |β2 | … |βn
where no βi begins with an A. Then, replace the A-productions by
A → β1 A’ | β2 A’ | … | βn A’
A’ → α1 A’ |α2 A’ | … | αm A’ | ϵ
The nonterminal A generates the same strings as before but is no longer left recursive. This procedure eliminates all left recursion from the A and A’ productions (provided no αi is ϵ), but it does not eliminate left recursion involving derivations of two or more steps. For example, consider the grammar
|
S → A a | b A → A c | S d | ϵ |
(4.18) |
The nonterminal S is left recursive because S ⇒ Aa ⇒ Sda, but it is not immediately left recursive.
Algorithm 4.19, below, systematically eliminates left recursion from a grammar. It is guaranteed to work if the grammar has no cycles (derivations of the form A =+>A) or ϵ-productions (productions of the form A →ϵ). Cycles can be eliminated systematically from a grammar, as can ϵ-productions (see Exercises 4.4.6 and 4.4.7).
Algorithm 4.19: Eliminating left recursion.
INPUT: Grammar G with no cycles or ϵ-productions.
OUTPUT: An equivalent grammar with no left recursion.
METHOD: Apply the algorithm in Fig. 4.11 to G. Note that the resulting non-left-recursive grammar may have ϵ-productions. □
|
1) |
arrange the nonterminals in some order A1, A2, …,An. |
|
2) |
for ( each i from 1 to n ) { |
|
3) |
for ( each j from 1 to i-1 ) { |
|
4) |
replace each production of the form Ai → Ajγ by the productions Ai → δ1γ |δ2γ | … |δkγ, where Aj → δ1 |δ2 | … |δk are all current Aj-productions |
|
5) |
} |
|
6) |
eliminate the immediate left recursion among the Ai-productions |
|
7) |
} |
|
Figure 4.11: Algorithm to eliminate left recursion from a grammar |
|
The procedure in Fig. 4.11 works as follows. In the first iteration for i = 1, the outer for-loop of lines (2) through (7) eliminates any immediate left recursion among A1-productions. Any remaining A1 productions of the form A1 → Alα must therefore have l > 1. After the i-1st iteration of the outer for-loop, all nonterminals Ak, where k < i, are “cleaned”; that is, any production Ak → Alα, must have l > k. As a result, on the ith iteration, the inner loop of lines (3) through (5) progressively raises the lower limit in any production Ai → Amα, until we have m≥i. Then, eliminating immediate left recursion for the Ai productions at line (6) forces m to be greater than i.
Example 4.20: Let us apply Algorithm 4.19 to the grammar (4.18). Technically, the algorithm is not guaranteed to work, because of the ϵ-production, but in this case, the production A →ϵ turns out to be harmless.
We order the nonterminals S, A. There is no immediate left recursion among the S -productions, so nothing happens during the outer loop for i = 1. For i = 2, we substitute for S in A → S d to obtain the following A-productions.
A → A c | A a d | b d | ϵ
Eliminating the immediate left recursion among these A-productions yields the following grammar.
S → A a | b
A → b d A’ | A’
A’ → c A’ | a d A’ | ϵ
□
4.3.4 Left Factoring
Left factoring is a grammar transformation that is useful for producing a grammar suitable for predictive, or top-down, parsing. When the choice between two alternative A-productions is not clear, we may be able to rewrite the productions to defer the decision until enough of the input has been seen that we can make the right choice.
For example, if we have the two productions
|
stmt |
→ if expr then stmt else stmt | if expr then stmt |
on seeing the input if, we cannot immediately tell which production to choose to expand stmt. In general, if A → αβ1 |αβ2 are two A-productions, and the input begins with a nonempty string derived from α, we do not know whether to expand A to αβ1 or αβ2. However, we may defer the decision by expanding A to A’. Then, after seeing the input derived from α, we expand A’ to β1 or to β2. That is, left-factored, the original productions become
A → A’
A’ → β1 | β2
Algorithm 4.21: Left factoring a grammar.
INPUT: Grammar G.
OUTPUT: An equivalent left-factored grammar.
METHOD: For each nonterminal A, find the longest prefix common to two or more of its alternatives. If α ≠ ϵ i.e., there is a nontrivial common prefix | replace all of the A-productions A →αβ1 |αβ2 | … |αβn | γ, where represents all alternatives that do not begin with α, by
A → αA’ | γ
A’ → β1 |β2 | … |βn
Here A 0 is a new nonterminal. Repeatedly apply this transformation until no two alternatives for a nonterminal have a common prefix. □
Example 4.22: The following grammar abstracts the “dangling-else” problem:
|
S → i E t S | i E t S e S | a E → b |
(4.23) |
Here, i, t, and e stand for if, then, and else; E and S stand for “conditional expression” and “statement.” Left-factored, this grammar becomes:
|
S → i E t S S’ | a S’ → e S | ϵ E → b |
(4.24) |
Thus, we may expand S to iEtSS’ on input i, and wait until iEtS has been seen to decide whether to expand S’ to eS or to ϵ. Of course, these grammars are both ambiguous, and on input e, it will not be clear which alternative for S’ should be chosen. Example 4.33 discusses a way out of this dilemma. □
4.3.5 Non-Context-Free Language Constructs
A few syntactic constructs found in typical programming languages cannot be specified using grammars alone. Here, we consider two of these constructs, using simple abstract languages to illustrate the difficulties.
Example 4.25: The language in this example abstracts the problem of checking that identifiers are declared before they are used in a program. The language consists of strings of the form wcw, where the first w represents the declaration of an identifier w, c represents an intervening program fragment, and the second w represents the use of the identifier.
The abstract language is L1 = {wcw | w is in (a|b)*}. L1 consists of all words composed of a repeated string of a’s and b’s separated by c, such as aabcaab. While it is beyond the scope of this book to prove it, the non-context-freedom of L1 directly implies the non-context-freedom of programming languages like C and Java, which require declaration of identifiers before their use and which allow identifiers of arbitrary length.
For this reason, a grammar for C or Java does not distinguish among identifiers that are different character strings. Instead, all identifiers are represented by a token such as id in the grammar. In a compiler for such a language, the semantic-analysis phase checks that identifiers are declared before they are used. □
Example 4.26: The non-context-free language in this example abstracts the problem of checking that the number of formal parameters in the declaration of a function agrees with the number of actual parameters in a use of the function. The language consists of strings of the form anbmcndm. (Recall an means a written n times.) Here an and bm could represent the formal-parameter lists of two functions declared to have n and m arguments, respectively, while cn and dm represent the actual-parameter lists in calls to these two functions.
The abstract language is L2 = { anbmcndm | n≥1 and m≥1}. That is, L2 consists of strings in the language generated by the regular expression a*b*c*d* such that the number of a’s and c’s are equal and the number of b’s and d’s are equal. This language is not context free.
Again, the typical syntax of function declarations and uses does not concern itself with counting the number of parameters. For example, a function call in C-like language might be specified by
|
stmt |
→ id ( expr_list ) |
|
expr_list |
→ expr_list , expr | expr |
with suitable productions for expr. Checking that the number of parameters in a call is correct is usually done during the semantic-analysis phase. □
4.3 Writing a Grammar的更多相关文章
- SH Script Grammar
http://linux.about.com/library/cmd/blcmdl1_sh.htm http://pubs.opengroup.org/onlinepubs/9699919799/ut ...
- Writing a simple Lexer in PHP/C++/Java
catalog . Comparison of parser generators . Writing a simple lexer in PHP . phc . JLexPHP: A PHP Lex ...
- Writing the first draft of your science paper — some dos and don’ts
Writing the first draft of your science paper — some dos and don’ts 如何起草一篇科学论文?经验丰富的Angel Borja教授告诉你 ...
- 写出完美论文的十个技巧10 Tips for Writing the Perfect Paper
10 Tips for Writing the Perfect Paper Like a gourmet meal or an old master painting, the perfect col ...
- Example of Formalising a Grammar for use with Lex & Yacc
Here is a sample of a data-file that we want to try and recognise. It is a list of students and info ...
- Preparation for MCM/ICM Writing
Preparation for MCM/ICM Writing -- by Chance Zhang $1^{st}ed$ key words: MCM/ICM, format, phrases, t ...
- Spring Enable annotation – writing a custom Enable annotation
原文地址:https://www.javacodegeeks.com/2015/04/spring-enable-annotation-writing-a-custom-enable-annotati ...
- Writing to a MySQL database from SSIS
Writing to a MySQL database from SSIS 出处 : http://blogs.msdn.com/b/mattm/archive/2009/01/07/writin ...
- Writing Clean Code 读后感
最近花了一些时间看了这本书,书名是 <Writing Clean Code ── Microsoft Techniques for Developing Bug-free C Programs& ...
随机推荐
- delphi clipboard
判断clipboard里的格式: if CliPBoard.HasFormat(CF_TEXT) then EdIT1.Text := CliPBoard.AsText ...
- Project Euler
Euler 34 答案:40730 我用程序算了无数次都是145,蛋疼,最后拿别人的程序仔细对比…… 原来 !=…… 真蛋疼,我竟然连基础数学都忘了 Euler-44 根据公式容易得出:Pmin + ...
- 十款开发者常用的Chrome插件,让chrome成为开发利器!
Chrome浏览器无论是作为浏览器市场的NO1还是其强大的跨平台能力以及丰富的扩展插件,一直是许多开发者的首要选择的浏览器.chrome浏览器也因为其丰富的Chrome插件,帮助开发者们在开发流程中极 ...
- allegro学习--区域约束
前言: 在有些情况需要我们在走线时在某些区域的时候,线是细的,例如BGA封装的FPGA在引出线的时候,我们希望在FPGA内部的线细,出了FPGA后,线变粗.如图: 这就用到了区域的规则约束. 实现: ...
- Leetcode 143.重排链表
重排链表 给定一个单链表 L:L0→L1→…→Ln-1→Ln ,将其重新排列后变为: L0→Ln→L1→Ln-1→L2→Ln-2→… 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换. 示 ...
- Codeforces Round #304 (Div. 2)-D. Soldier and Number Game,素因子打表,超时哭晕~~
D. Soldier and Number Game time limit per test 3 seconds memory limit per test 256 megabytes input s ...
- Maxscale安装-读写分离(1)
前言 关于MySQL中间件的产品也很多,之前用过了360的Atlas.玩过MyCat.这边我选择 Maxscale的原因就是功能能满足需求,也看好他的未来发展. 其实有关于如何安装 Maxscale的 ...
- 安装eclipse插件,很慢终于找到了解决的方法
1 .除非你需要,否则不要选择"联接到所有更新站点" 在安装对话框里有一个小复选框,其标示为"在安装过程中联接到所有更新站点从而找到所需的软件."从表面上看,这 ...
- ajax接收json数据到js解析
今天又学到了一点新知识,脑子记不住东西特把它记录下来! 页面ajax请求后台时一般都是返回字符串进行判断,要是返回list或者对象时该怎么办? 第一种:ajax接收到list并返回给前台 js代码: ...
- 家的范围 Home on the Range(洛谷 2733)
题目背景 农民约翰在一片边长是N (2 <= N <= 250)英里的正方形牧场上放牧他的奶牛.(因为一些原因,他的奶牛只在正方形的牧场上吃草.)遗憾的是,他的奶牛已经毁坏一些土地.( 一 ...