scrapy 之自定义命令运行所有爬虫文件
1、在spider文件夹同级目录创建commands python包
2、在包下创建command.py文件
3、从scrapy.commands包下引入ScrapyCommand
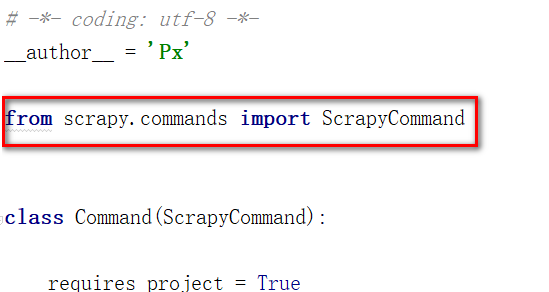
4、创建一个类,继承ScrapyCommand
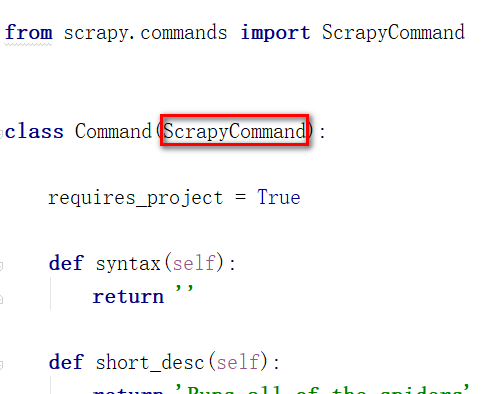
5、重新定义类变量 requires_project = True

6、重写syntax short_desc方法,syntax返回空字符串 short_desc返回描述字符串

7、重写run方法。
8、在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list() #通过self.crawler_process.spider.list()获得所有爬虫
for name in spider_list: #遍历所有爬虫
self.crawler_process.crawl(name, **opts.__dict__) #运行爬虫 self.crawler_process.start() #启动进程
crawler_process 来自父类 完整代码
# -*- coding: utf-8 -*-
__author__ = 'Px' from scrapy.commands import ScrapyCommand class Command(ScrapyCommand): requires_project = True def syntax(self):
return '' def short_desc(self):
return 'Runs all of the spiders' def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
scrapy 之自定义命令运行所有爬虫文件的更多相关文章
- scrapy电影天堂实战(二)创建爬虫项目
公众号原文 创建数据库 我在上一篇笔记中已经创建了数据库,具体查看<scrapy电影天堂实战(一)创建数据库>,这篇笔记创建scrapy实例,先熟悉下要用到到xpath知识 用到的xpat ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- Scrapy的shell命令(转)
scrapy python MrZONT 2015年08月29日发布 ...
- scrapy框架--新建调试的main.py文件
一.原因: 由于pycharm中没有scrapy的一个模板,所有没办法直接在scrapy文件中调试,所有我们需要写一个自己的main.py文件,在文件里面调用命令行,来实现scrapy的一个调试.(在 ...
- scrapy框架的命令行解释
scrapy框架的命令解释 创建爬虫项目 scrapy startproject 项目名例子如下: scrapy startproject test1 这个时候爬虫的目录结构就已经创建完成了,目录结构 ...
- python+pytest,通过自定义命令行参数,实现浏览器兼容性跑用例
场景拓展: UI自动化可能需要指定浏览器进行测试,为了做成自定义配置浏览器,可以通过动态添加pytest的命令行参数,在执行的时候,获取命令行传入的参数,在对应的浏览器执行用例. 1.自动化用例需要支 ...
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- scrapy 基础组件专题(六):自定义命令
写好自己的爬虫项目之后,可以自己定制爬虫运行的命令. 一.单爬虫 在项目的根目录下新建一个py文件,如命名为start.py,写入如下代码: from scrapy.cmdline import ex ...
随机推荐
- Behavior开发时找不到Expression.Interactions的问题解决
比如下面使用Behavior的例子,需要参照:Microsoft.Expression.Interactions.dll. <Window x:Class="VisualStudioB ...
- 虚拟机中的linux系统文件突然全部变成只读的问题
当宿主系统和虚拟机的IO都比较繁忙时,虚拟机的IO请求得不到及时的响应.虚拟机Linux不知道自己运行在虚拟机里面,会认为是磁盘IO错误,为了保护磁盘数据会remount分区为只读. 这时候如果只是对 ...
- jQuery使用CDN加速
使用新浪.百度.谷歌和微软的CDN加速jQuery 随着jQuery的版本更新,体积也越来越大,如果把jQuery放在自己的服务器上,会消耗不少的流量.而谷歌和百度等互联网公司为了方便开发者,提供了C ...
- 继承RelativeLayout 自定义布局
public class HomeToolbarView extends RelativeLayout { TextView tvTitle; public HomeToolbarView(Conte ...
- jupyter依赖tornado版本
使用jupyter莫名奇妙出现500错误,发现是更新tornado出了问题,我的jupyter版本是5.7.4不支持6.x版本的tornado,回退到5.x版本的tornado就好了. pip ins ...
- Altium Designer 放置机械孔
先放置一个圆弧,将圆选中:执行Tools -> Convert -> Create Board Cutout from Selected Primitives
- Ubuntu、CenOS、Debian等不同版本简单概念与不同
最近在云计算中使用虚拟机,在进行Xen搭建时发现Ubuntu好像从10版本没有开始官方维护,又去了解了更多的Linux的版本 后续打算采用CenOS尝试一下 下文选自https://blog.csdn ...
- python类特列方法使用
class Rgc(object): def __new__(cls, *args, **kwargs): print('在类通过__new__方法实例化一个对象') return super(Rgc ...
- 使用requests+BeautifulSoup爬取龙族V小说
这几天想看龙族最新版本,但是搜索半天发现 没有网站提供 下载, 我又只想下载后离线阅读(写代码已经很费眼睛了).无奈只有自己 爬取了. 这里记录一下,以后想看时,直接运行脚本 下载小说. 这里是从 ...
- java 日志脱敏框架 sensitive,优雅的打印脱敏日志
问题 为了保证用户的信息安全,敏感信息需要脱敏. 项目开发过程中,每次处理敏感信息的日志问题感觉很麻烦,大部分都是用工具类单独处理,不利于以后统一管理,很不优雅. 于是,就写了一个基于 java 注解 ...