记录小白实习生的HashMap源码 put元素 的学习和一些疑问
首先看HashMap存储结构
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
/*
……
*/
}
我对存储结构的理解
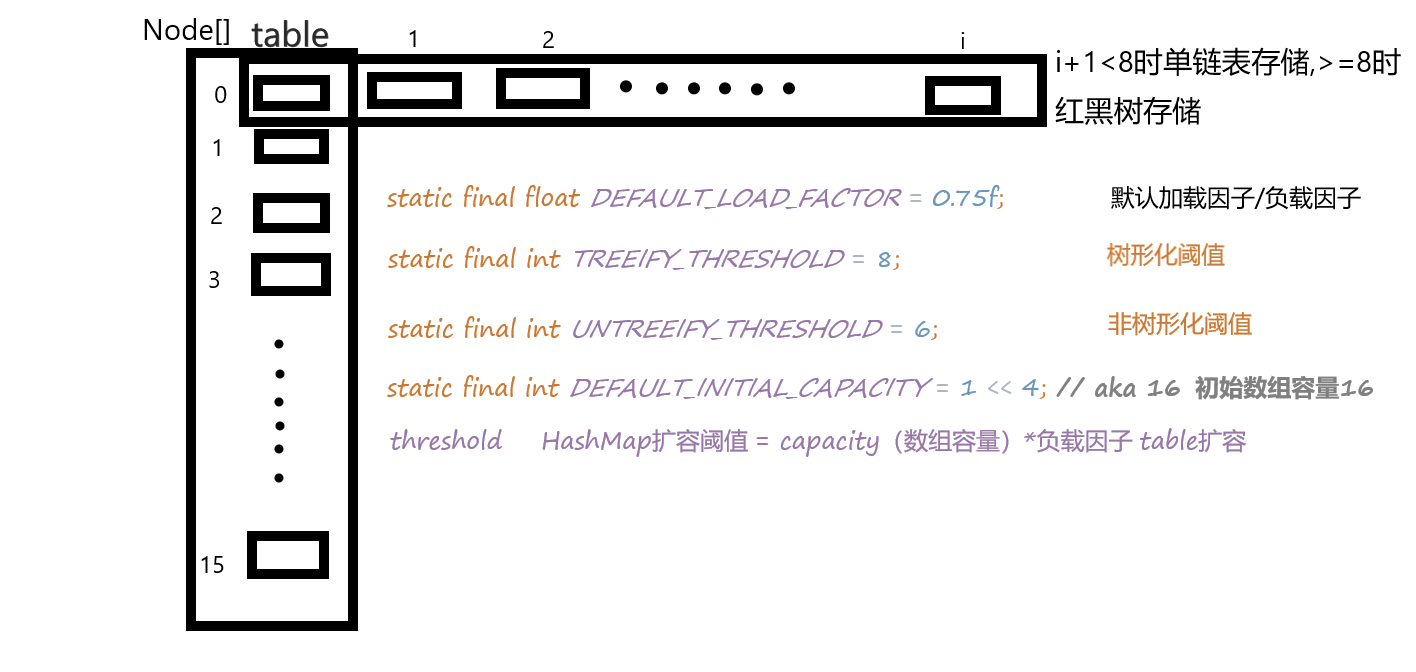
初始化一个长度为16的Node数组,数组中每一个元素是一个Node构成的单链表,好像是大家说的桶?当桶中Node结点长度(链表长度)大于等于TREEIFY_THRESHOLD (8)时 单链表改为 树(红黑树?现在还一点不了解,知道个名字) 存储 ,当桶中Node结点长度(链表长度)小于等于UNTREEIFY_THRESHOLD (6)时,树形结构转换为单链表存储
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
putVal 参数 分别为 key的哈希值,key值,value值,onlyIfAbsent true表示只有在该key对应原来的value为null的时候才插入,也就是说如果value之前存在了,就不会被新put的元素覆盖,false相反,evict //evict if false, the table is in creation mode. 这个是源码中的注释,true的话就不是creation mode?看园里大佬zju_jzb的博说
用于LinkedHashMap中的尾部操作,这里没有实际意义 传送门 https://www.cnblogs.com/jzb-blog/p/6637823.html
new HashMap<>()进行put时
先对table=null 和 table.length = 0 的情况进行处理 执行resize方法默认构造一个长为16的Node数组
再根据hash值 (table.length - 1) & hash 计算出put 的桶的下标
若该元素为空 newNode(hash, key, value, null); 创建一个单链表的“头”结点
若该元素不为空
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
如果第一个元素key与put的key相同时,将第一个元素引用赋值给要put的新结点e
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
如果第一个元素 是 TreeNode类型时,说明已转换为树形结构存储,插入到树中
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
如果第一个元素与要put元素不同,而且此时也仍是单链表结构存储的话,遍历链表。找到后又分三种情况
第一种情况时,插入后链表长度达到8,需要转化为树形结构。
第二种情况时,插入后链表长度小于8,仍然是链表存储。
第三种情况时,链表中遍历到相同key值的结点,获得该结点的引用
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
对已存在key的value进行覆盖 返回put之前key所对应的值
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
modCount是对HashMap结构改变次数的记录(插入删除)
若put一个元素后 需要对Node[] table进行扩容 就扩容
putVal 方法走到这里时已经说明 HashMap中不存在和要put的Key相同的Key 返回null
afterNodeInsertion方法还不了解
看了一天了 感觉对HashMap的大致结构有一定的了解了 但是还有很多疑问
记录小白实习生的HashMap源码 put元素 的学习和一些疑问的更多相关文章
- hashMap源码学习记录
hashMap作为java开发面试最常考的一个题目之一,有必要花时间去阅读源码,了解底层实现原理. 首先,让我们看看hashMap这个类有哪些属性 // hashMap初始数组容量 static fi ...
- Java中的HashMap源码记录以及并发环境的几个问题
HashMap源码简单分析: 1 一切需要从HashMap属性字段说起: /** The default initial capacity - MUST be a power of two. 初始容量 ...
- HashMap源码分析
最近一直特别忙,好不容易闲下来了.准备把HashMap的知识总结一下,很久以前看过HashMap源码.一直想把集合类的知识都总结一下,加深自己的基础.我觉的java的集合类特别重要,能够深刻理解和应用 ...
- HashMap源码解读(转)
http://www.360doc.com/content/10/1214/22/573136_78188909.shtml 最近朋友推荐的一个很好的工作,又是面了2轮没通过,已经是好几次朋友内推没过 ...
- 自学Java HashMap源码
自学Java HashMap源码 参考:http://zhangshixi.iteye.com/blog/672697 HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提 ...
- HashMap源码分析(一)
前言:相信不管在生产过程中还是面试过程中,HashMap出现的几率都非常的大,因此有必要对其源码进行分析,但要注意的是jdk1.8对HashMap进行了大量的优化,因此笔者会根据不同版本对HashMa ...
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- 基于JDK1.8版本的hashmap源码笔记(二)
这一篇是接着上一篇写的, 上一篇的地址是:基于JDK1.8版本的hashmap源码分析(一) /** * 返回boolean类型的值,当集合中包含key的键值,就返回true,否则就返 ...
- HashMap源码解读(JDK1.7)
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
随机推荐
- 对TSNU网站的初步分析
这是一个教育网的网站,其中网站的教务子系统,html页面是用表单嵌套来格式化显示样式的,另外还有<div>.<iframe>等等 .在这个上有个form表单,提交的参数有如下几 ...
- Oracle使用外部表批量创建用户
整体思路:通过使用外部表将用户名导入Oracle的表中,然后通过PL/SQL遍历数据表,批量创建用户. 具体步骤如下: 1.在安装数据库的服务器的C盘根目录创建一个User List.txt文件,内容 ...
- PythonStudy——nonlocal关键字
# 作用:将局部的变量提升为嵌套局部变量# 1.必须有同名嵌套局部变量,就是统一嵌套局部与局部的同名变量# -- 如果局部想改变嵌套局部变量的值(发生地址的变化),可以用nonlocal声明该变量 d ...
- SignalR 行实时通信最大连接数
SignalR 搭建实时刷新应用虽然非常方便,但是有个问题你必须考虑到,就是一般的浏览器,对于SignalR的全双工通信方式,绝大多数浏览器都只支持6个新窗口,如果你打开第7个,那么新的框口页面是不会 ...
- 命令生成所有数据库表模型以及 CRUD
将下列代码写到文件复制到项目 console\controller 目录下: <?php namespace console\controllers; use Yii; use yii\cons ...
- 通过Spark Streaming的foreachRDD把处理后的数据写入外部存储系统中
转载自:http://blog.csdn.net/erfucun/article/details/52312682 本博文主要内容包括: 技术实现foreachRDD与foreachPartition ...
- Android studio 中添加依赖model时依赖所需的准备
例如向app中添加依赖core: core要做如下修改: 1.将core中build.gradle中 修改为 . 2.将core中的 applicationId 注释掉.
- nginx 配置说明
======nginx 配置文件分开==== http://blog.csdn.net/baple/article/details/44197981 1.备份现在有nginx.conf2.复制ngin ...
- C#中Dispose,finalize,GC,析构函数区别
释放类所使用的未托管资源的两种方式: 1.利用运行库强制执行的析构函数,但析构函数的执行是不确定的,而且,由于垃圾收集器的工作方式,它会给运行库增加不可接受的系统开销. 2.IDisposable接 ...
- 理解OpenShift(6):集中式日志处理
理解OpenShift(1):网络之 Router 和 Route 理解OpenShift(2):网络之 DNS(域名服务) 理解OpenShift(3):网络之 SDN 理解OpenShift(4) ...