SparkSQL – 从0到1认识Catalyst(转载)
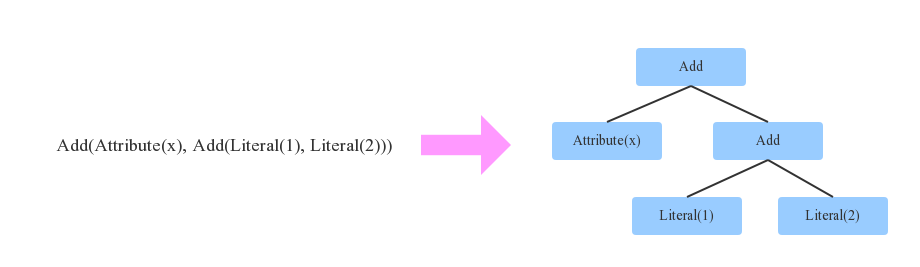
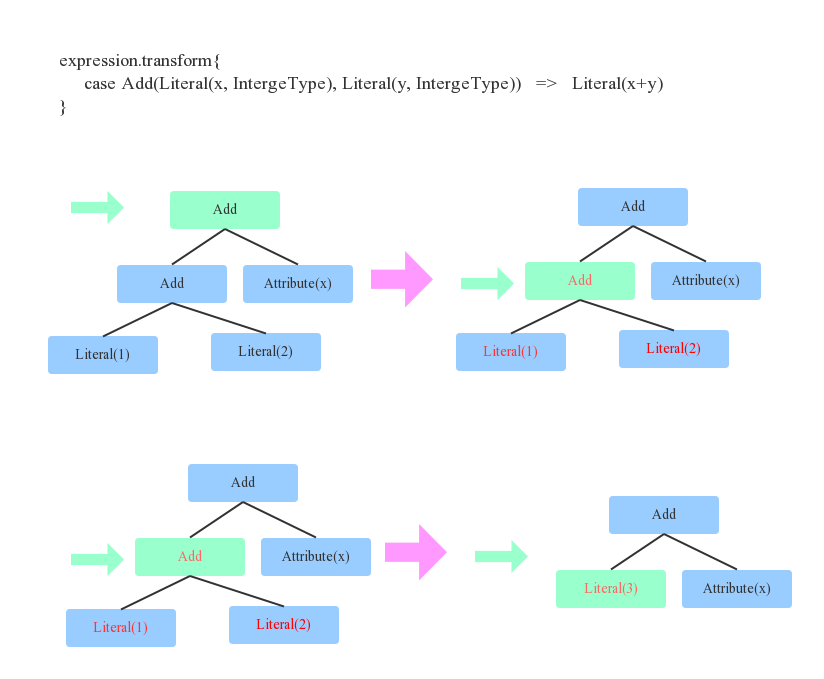
预备知识-Tree&Rule
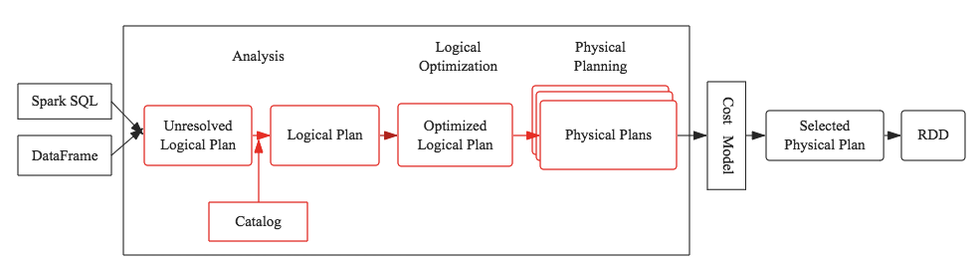
Catalyst工作流程
Parser
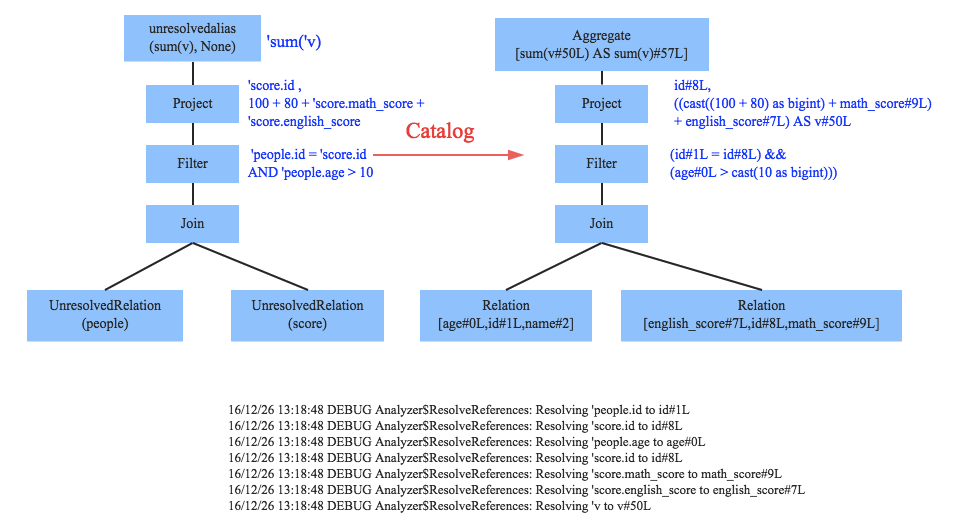
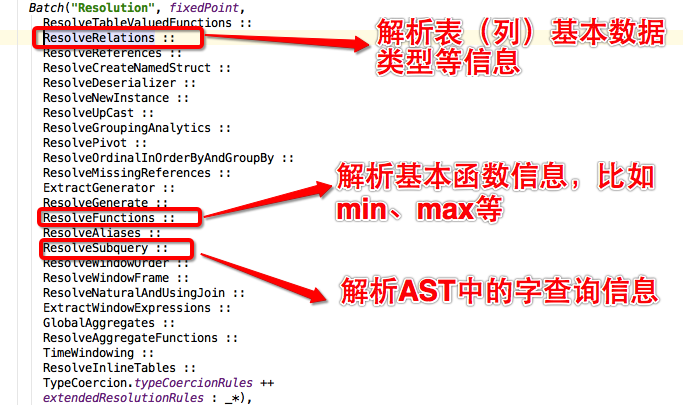
Analyzer
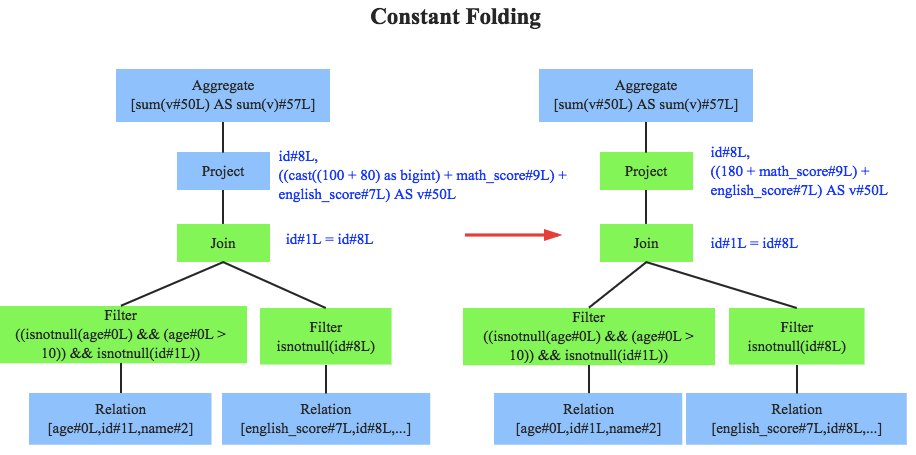
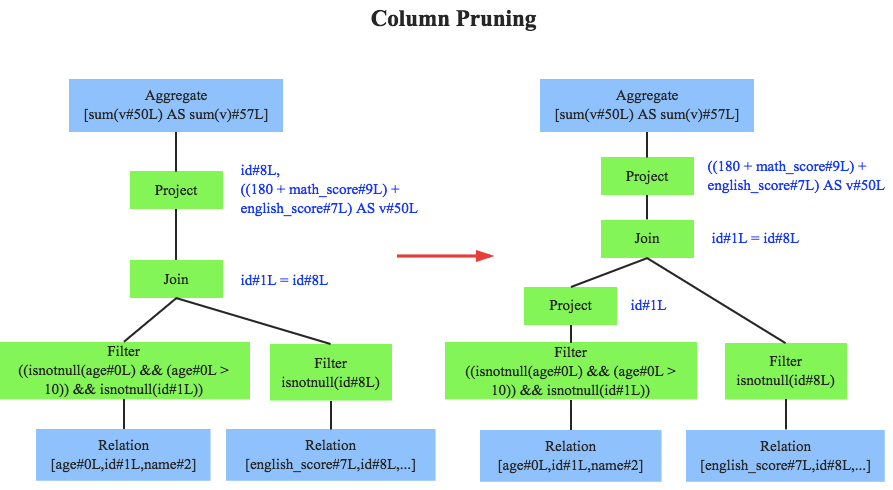
Optimizer


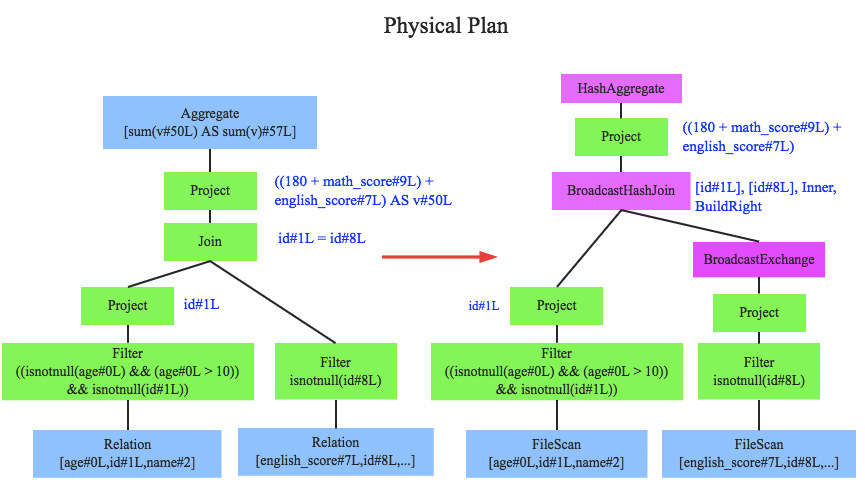
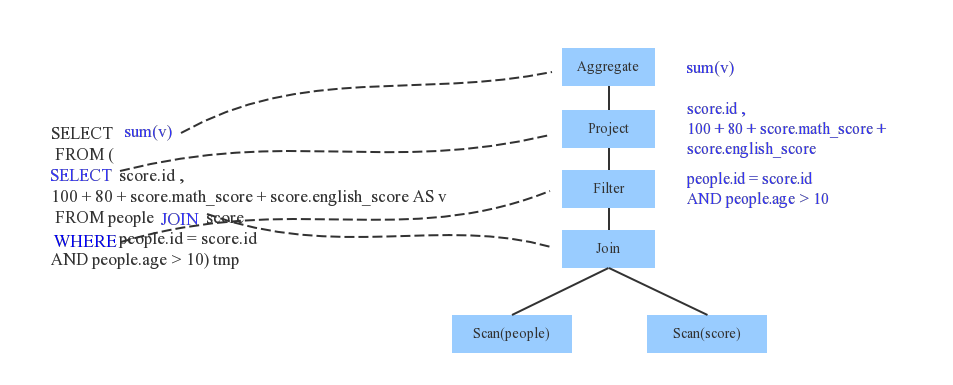
SparkSQL执行计划
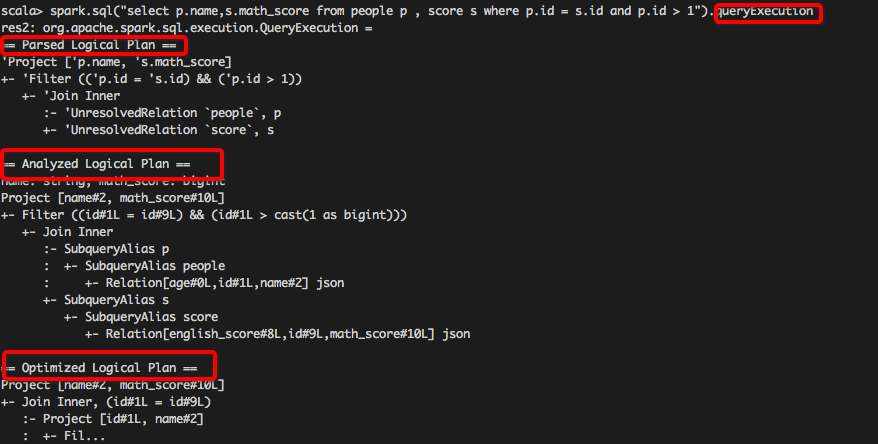
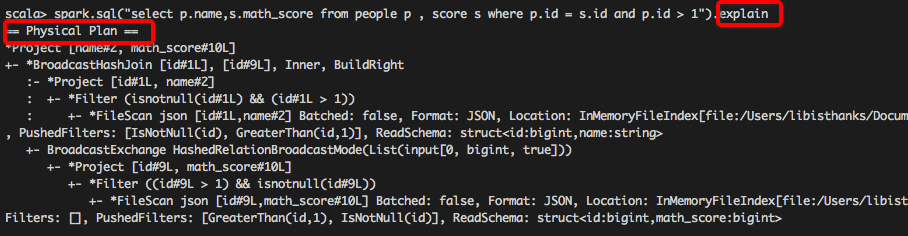
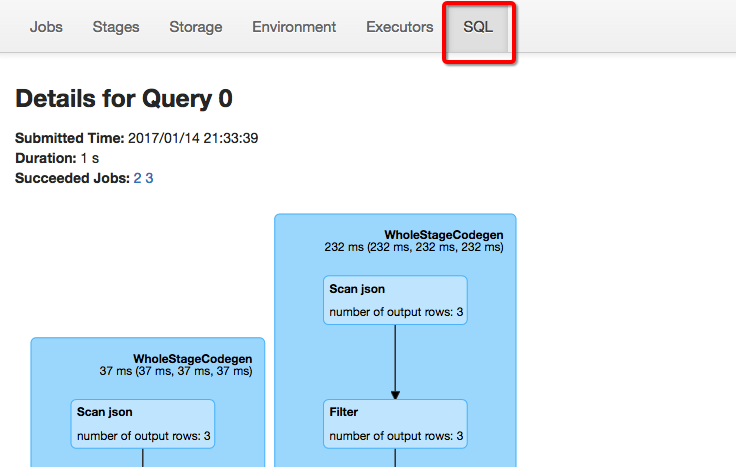
SparkSQL – 从0到1认识Catalyst(转载)的更多相关文章
- Socket的用法——NIO包下SocketChannel的用法 ———————————————— 版权声明:本文为CSDN博主「茶_小哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/ycgslh/article/details/79604074
服务端代码实现如下,其中包括一个静态内部类Handler来作为处理器,处理不同的操作.注意在遍历选择键集合时,没处理完一个操作,要将该请求在集合中移除./*模拟服务端-nio-Socket实现*/pu ...
- Apache Spark 2.2.0新特性介绍(转载)
这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(experimental tag)已经被移除.在流系统中支持对任意状态进行操作:A ...
- mongodb 3.0 WT 引擎性能测试(转载)
网上转载来的测试,仅供参考.原文地址:http://www.mongoing.com/benchmark_3_0 类机器. 测试均在单机器,单实例的情况下进行. 机器A(cache 12G,即内存&g ...
- Cocos2d-x 3.0坐标系详解(转载)
Cocos2d-x 3.0坐标系详解 Cocos2d-x坐标系和OpenGL坐标系相同,都是起源于笛卡尔坐标系. 笛卡尔坐标系 笛卡尔坐标系中定义右手系原点在左下角,x向右,y向上,z向外,OpenG ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载-2)
原文:http://www.cnblogs.com/PurpleDream/p/4510279.html 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群 前言: ...
- do{...}while(0)的意义和用法(转载)
linux内核和其他一些开源的代码中,经常会遇到这样的代码: do{ ... }while(0) 这样的代码一看就不是一个循环,do..while表面上在这里一点意义都没有,那么为什么要这么用呢? 实 ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载)
原文:http://www.open-open.com/lib/view/open1435468300700.html 第一步,确定目标: Tracker 192.168.224.20:22122 ...
- ip地址0.0.0.0与127.0.0.1的区别(转载)
原文链接:http://blog.csdn.net/ttx_laughing/article/details/58586907 最近在项目开发中发现一个奇怪的问题,当服务器与客户端在同一台机器上时,用 ...
- 在Android 5.0中使用JobScheduler(转载)
翻译见:http://blog.csdn.net/bboyfeiyu/article/details/44809395 In this tutorial, you will learn how to ...
随机推荐
- input range样式优化
首先HTML代码: <input id="snrPollInterval" type="range" min="1" max=&quo ...
- (后端)安装mongodb以及设置为windows服务 详细步骤(转)
1.在data文件夹下新建一个log文件夹,用于存放日志文件,在log文件夹下新建文件mongodb.log 2.在 D:\mongodb文件夹下新建文件mongo.config,并用记事本打开mon ...
- 杨学明老师推出全新课程--《敏捷开发&IPD和敏捷开发结合的实践》
课时:13小时(2天) 敏捷开发&IPD和敏捷开发结合的实践 讲 师:杨学明 [课程背景] 集成产品开发(IPD).集成能力成熟度模型(CMMI).敏捷开发(Agile Developmen ...
- 使用fiddler对手机上的程序进行抓包
用fiddler对手机上的程序进行抓包,网上有很多的资料,这里写一下来进行备用. 前提: 1.必须确保安装fiddler的电脑和手机在同一个wifi环境下 备注:如果电脑用的是台式机,可以安装一个 ...
- 计算机图形学(第2版 于万波 于硕 编著)第45页的Bresenham算法有错误
计算机图形学(第2版 于万波 于硕 编著)第45页的Bresenham算法有错误: 书上本来要写的是以x为阶越步长的方法,但是他写的是用一部分y为阶越步长的方法(其实也写的不对),最后以x为阶越步长的 ...
- spring4笔记----Spring几种常用的容器后处理器
PropertyPlaceholderConfigurer 属性占位符配置器 PropertyOverrideConfigureer 重写占位符配置器 CustomAutowireConfig ...
- MySQL并行复制的一个坑
早上巡检数据库,发现一个延迟从库的sql_thread中断了. Last_SQL_Errno: 1755 Last_SQL_Error: Cannot execute the current even ...
- 分布式:Dubbo与Zookeeper、SpringMVC整合和使用(负载均衡、容错)
互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,Dubbo是一个分布式服务框架,在这种情况下诞生的.现在核心业务抽取出来,作为独立的服务,使 ...
- MapFileParser.sh: Permission denied
Unity项目,需要用Xcode运行,结果报了错误. 解决方案: 1.打开终端, 2.输入以下命令: chmod +x /Users/......./MapFileParser.sh (MapFi ...
- Python爬虫之Urllib库的基本使用
# get请求 import urllib.request response = urllib.request.urlopen("http://www.baidu.com") pr ...