Hadoop环境准备
1. 集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
Hadoop部署方式分三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster mode(群集模式),其中前两种都是在单机部署。
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
我们以3节点为例进行搭建,角色分配如下:
node-01 NameNode DataNode ResourceManager
node-02 DataNode NodeManager SecondaryNameNode
node-03 DataNode NodeManager
2. 服务器准备
本案例使用VMware Workstation Pro虚拟机创建虚拟服务器来搭建HADOOP集群,所用软件及版本如下:
VMware Workstation Pro 15.0
Centos 7.5 64bit
3. 网络环境准备
采用NAT方式联网。
如果创建的是桌面版的Centos系统,可以在安装完毕后通过图形页面进行编辑。如果是mini版本的,可通过编辑ifcfg-eth*配置文件进行配置。
注意BOOTPROTO、GATEWAY、NETMASK。
4. 服务器系统设置
同步时间
#手动同步集群各机器时间
date -s "2017-03-03 03:03:03"
yum install ntpdate
#网络同步时间
ntpdate cn.pool.ntp.org
设置主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node-1
配置IP、主机名映射
vi /etc/hosts
192.168.33.151 node-1
192.168.33.152 node-2
192.168.33.153 node-3
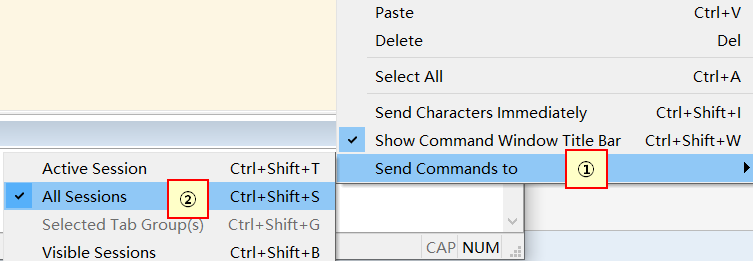
小技巧:使用SecureCRT同时操作3台虚拟机
勾选Command Window

在控制台右键→Send Commands to→All Sessions
配置ssh免密登陆
#生成ssh免登陆密钥(一般配置从主节点到从节点的免密登录)
ssh-keygen -t rsa (四个回车)
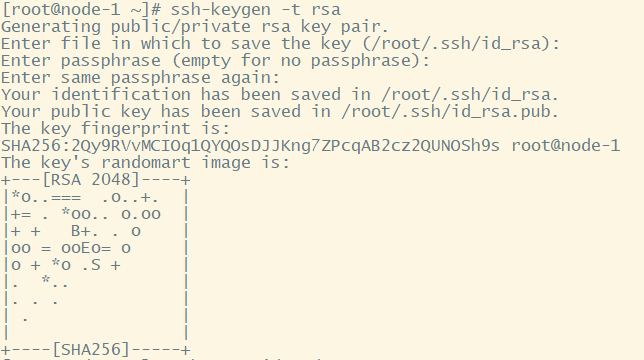
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id node-2 ssh-copy-id node-3
注意:
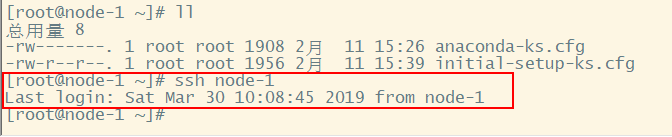
在给其他主机配置免密登录时,一定要给本主机配置免密登录
在未配置免密登录时,如下图所示:(系统会提示你输入密码,即root账户密码)

接下来对node-1配置免密登录,先生成ssh免登陆密钥(参考上文),接下来如下操作:

配置后再次登录,配置成功后如下图所示:
同理,在主机node-1中配置node-2、node-3的免密登录
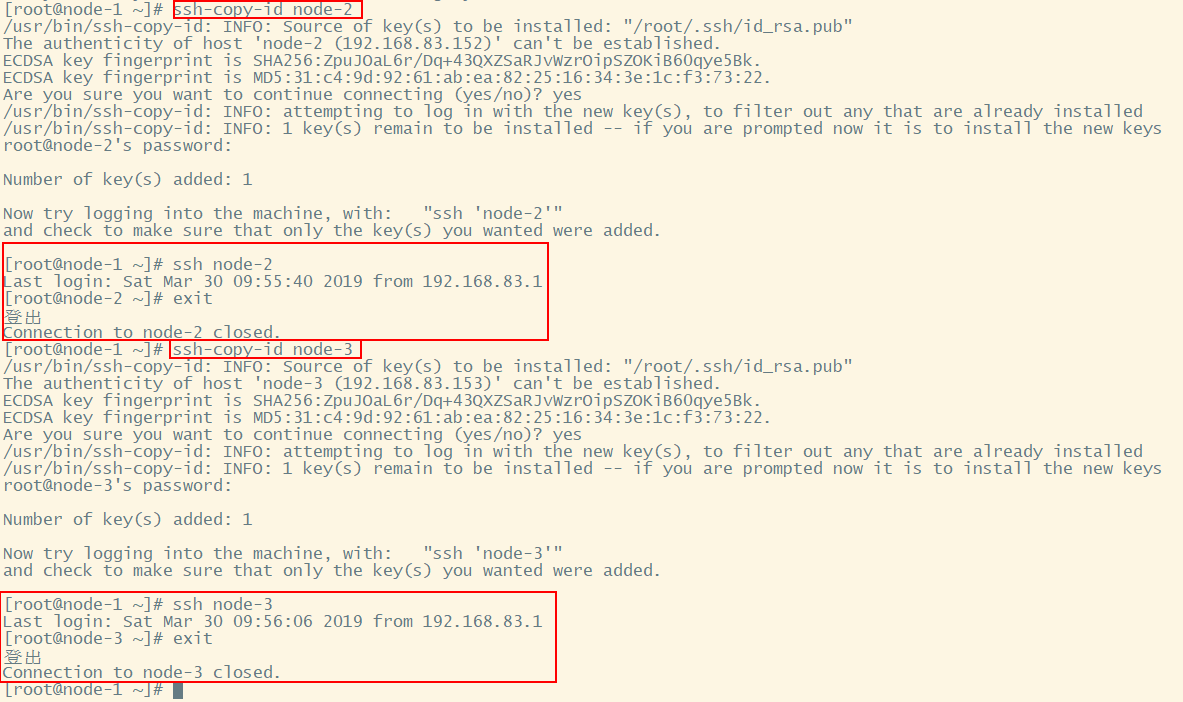
以上操作就完成了node-1到自己(本身)、node-1到node-2、node-1到node-3的免密登录。
那么有的同学可能会问node-2到node-3或者node-3到node-1需要配置吗?
答案是不需要在进行这样的配置。我们后续的操作主要在node-1这台主机上进行,可见node-1这台主机的地位还是比较高的。
配置防火墙
可以选择关闭防火墙
5. JDK环境安装
可以参考我之前的jdk安装教程
至此,前期工作准备完成,接下来就是hadoop的安装了。
Hadoop环境准备的更多相关文章
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- 【Hadoop测试程序】编写MapReduce测试Hadoop环境
我们使用之前搭建好的Hadoop环境,可参见: <[Hadoop环境搭建]Centos6.8搭建hadoop伪分布模式>http://www.cnblogs.com/ssslinppp/p ...
- 【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式
阅读目录 ~/.ssh/authorized_keys 把公钥加到用于认证的公钥文件中,authorized_keys是用于认证的公钥文件 方式2: (未测试,应该可用) 基于空口令创建新的SSH密钥 ...
- hadoop环境安装及简单Map-Reduce示例
说明:这篇博客来自我的csdn博客,http://blog.csdn.net/lxxgreat/article/details/7753511 一.参考书:<hadoop权威指南--第二版(中文 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- 虚拟机搭建hadoop环境
这里简单用三台虚拟机,搭建了一个两个数据节点的hadoop机群,仅供新人学习.零零碎碎,花了大概一天时间,总算完成了. 环境 Linux版本:CentOS 6.5 VMware虚拟机 jdk1.6.0 ...
- 大数据学习系列之一 ----- Hadoop环境搭建(单机)
一.环境选择 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内存:1G 硬盘:40G ip:39.108.77.250 2,配置选择 JD ...
- hadoop环境配置过程中可能遇到问题的解决方案
Failed to set setXIncludeAware(true) for parser 遇到此问题一般是jar包冲突的问题.一种情况是我们向java的lib目录添加我们自己的jar包导致had ...
- 在本机eclipse中创建maven项目,查看linux中hadoop下的文件、在本机搭建hadoop环境
注意 第一次建立maven项目时需要在联网情况下,因为他会自动下载一些东西,不然突然终止 需要手动删除断网前建立的文件 在eclipse里新建maven项目步骤 直接新建maven项目出了错 ...
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
随机推荐
- POJ 3678 Katu Puzzle (2-SAT)
Katu Puzzle Time Limit: 1000MS ...
- rownum查询前N条记录
在Oracle中,要按特定条件查询前N条记录,用个rownum就搞定了.——select * from emp where rownum <= 5 而且书上也告诫,不能对rownum用" ...
- TCP详解——连接建立与断开
一.报文结构介绍 在开始讲TCP连接过程时,还是先看看TCP报文的格式如图1所示.IP数据报此时由IP头部+TCP头部+TCP数据组成.不带选项的TCP头部是20字节长,而带选项的,TCP头部最长可达 ...
- spring集成Hessian的基本使用方法
一.什么是RPC RPC全称Remote Procedure Call,中文名叫远程过程调用.RPC是一种远程调用技术,用于不同系统之间的远程相互调用.其在分布式系统中应用十分广泛. 二.什么是Hes ...
- Docker笔记一:Docker介绍
目录 什么是Docker? Docker的核心概念 Docker镜像命令 Docker容器命令 Docker实战 查看我的镜像 启动Redis Docker中国镜像加速 血与泪的教训 什么是Docke ...
- Kafka技术内幕 读书笔记之(五) 协调者——协调者处理请求
消费者客户端使用“消费者的协调者对象”( ConsumerCoordinator )来代表所有和服务端协调者节点有关的请求处理,比如心跳请求.获取和提交分区的偏移量(自动提交任务).发送“加入组请求” ...
- [NIO-1]缓冲区
常用的是ByteBuffer.CharBuffer
- HDU 1115(求质量均匀分布的多边形重心 物理)
题意是给一个 n 边形,给出沿逆时针方向分布的各顶点的坐标,求出 n 边形的重心. 求多边形重心的情况大致上有三种: 一.多边形的质量都分布在各顶点上,像是用轻杆连接成的多边形框,各顶点的坐标为Xi, ...
- Python复习笔记(十)Http协议--Web服务器-并发服务器
1. HTTP协议(超文本传输协议) 浏览器===>服务器发送的请求格式如下:(浏览器告诉服务器,浏览器的信息) GET / HTTP/1.1 Host: www.baidu.com Conne ...
- Http状态码解释
参考:urllib与urllib2的学习总结(python2.7.X) # Table mapping response codes to messages; entries have the # f ...