python学习日记(文件操作)
文件操作概述
计算机系统分为:操作系统,计算机硬件,应用程序。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久的保存下来。
读文件
#相对路径下创建的log文件,也可以绝对路径,不过要写完整路径名
f = open('log',mode='r',encoding='utf-8')#以什么编码方式创建的,以什么编码方式读出来
l = f.read()
print(l)
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

写文件
f = open('log',mode='w',encoding='utf-8')#写入的话是先清空原有内容,再写入新的数据,若文件不存在,创建新文件
f.write('这是新写入的内容')
f.close()
#对写完新内容的文件进行读取
f = open('log',mode='r',encoding='utf-8')#以什么编码方式创建的,以什么编码方式读出来
l = f.read()
print(l)
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

追加内容
#对文件进行追加内容,指针在文件末尾,若文件不存在,创建新文件
f = open('log',mode='a',encoding='utf-8')
f.write('---这是追加的内容')
f.close()
#对追加完内容的文件进行读取
f = open('log',mode='r',encoding='utf-8')#以什么编码方式创建的,以什么编码方式读出来
l = f.read()
print(l)
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

二进制文件
前面讲的默认都是读取文本文件,并且是以utf-8编码的文本文件。要读取二进制文件,比如,图片、视频等,用'rb' 模式打开即可。非文本文件
rb
一、
f = open('log',mode='w',encoding='utf-8')#写入的话是先清空原有内容,再写入新的数据
f.write('abcd123')
f.close()
f = open('log',mode='rb')#bytes类型,非文本文件等
l = f.read()
print(l)
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

二、汉字
f = open('log',mode='w',encoding='utf-8')#写入的话是先清空原有内容,再写入新的数据
f.write('这是五个字')
f.close()
f = open('log',mode='rb')#bytes类型,非文本文件等
l = f.read()
print(l)
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

wb
一、
f = open('log',mode='wb')#写入的话是先清空原有内容,再写入新的数据,若文件不存在,创建新文件
f.write('abcde'.encode('utf-8'))#涉及到str-->bytes
f.close()
f = open('log',mode='r')
l = f.read()
print(l,type(l))#自动帮你转换成str
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

二、汉字
f = open('log',mode='wb')#写入的话是先清空原有内容,再写入新的数据,若文件不存在,创建新文件
f.write('三个字'.encode())#涉及到str-->bytes,编码方式默认是utf-8
f.close()
f = open('log',mode='r',encoding='utf-8')
l = f.read()
print(l,type(l))#自动帮你转换成str
f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
# 并且操作系统同一时间能打开的文件数量也是有限的

ab
同理,不再赘述。
读写r+
一、先读再写
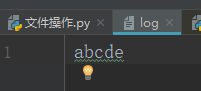
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
print(f.read())#读完,光标移动到最后,写才没有覆盖
f.write('')
f.close()

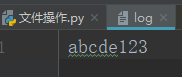
二、先写再读
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
f.write('')#指针在文件开头
print(f.read())
f.close()

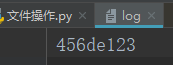
写完之后,指针在‘456’的后面,然后执行读,读的是当前指针之后的字符串。
w+
打开一个文件用于读写,并从头开始编辑,即原有内容会被删除,若文件不存在,创建新文件。
f = open('log',mode='w+',encoding='utf-8')#打开一个文件用于读写
f.write('')#指针在文件开头
print(f.read())#指针已经到了最后,所以读是无输出的
f.close()
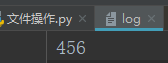
a+
打开一个文件用于读写,文件已存在,指针在文件末尾,不存在,创建新文件。
f = open('log',mode='a+',encoding='utf-8')#打开一个文件用于读写
f.write('追加的')#指针在文件末尾
print(f.read())#追加,所以读无输出
f.close()
二进制文件
同理。
seek (字节)
一、
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
print(f.read())
f.close()
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
f.seek(3)#指针移到3,指定光标位置
print(f.read())
f.close()

二、
f = open('log',mode='w',encoding='utf-8')
f.write('晴川历历汉阳树')
f.close()
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
f.seek(3)#seek单位是字节,一个中文三个字节
print(f.read())
f.close()

对于中文,不是3的整数倍,就会引发异常。
tell(字节)
一、
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
f.seek(3)#指针移到3,指定光标位置
print(f.tell())#找到指针当前位置,seek指定的为3
print(f.read())
f.close()

二、
f = open('log',mode='w',encoding='utf-8')
f.write('晴川Abc')
f.close()
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
f.seek(3)#seek单位是字节,一个中文三个字节
print(f.read(2))#从当前指针位置读取几个字符
print(f.tell())#tell单位是字节,找到指针当前位置
f.close()

read(字符)
f = open('log',mode='w',encoding='utf-8')
f.write('晴川abc历历汉阳树')
f.close()
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写
f.seek(3)#seek单位是字节,一个中文三个字节
print(f.read(3))#从当前指针位置读取几个字符
f.close()

with ... as...
可以省去.close()
with open('log',mode='r+',encoding='utf-8') as f1,\
open('log',mode='a+',encoding='utf-8') as f2:#\可以用来换行
l1 = f1.read()
print(l1)
f2.write('汉阳树')#此时指针在末尾
f2.seek(0)
l2 = f2.read()
print(l2)

readline(),readlines()
with open('log',mode='w+',encoding='utf-8') as f1,\
open('log',mode='r+',encoding='utf-8') as f2:
f1.write('晴川历历汉阳树\n芳草萋萋鹦鹉洲')
f1.seek(0)
print(f2.read())
f2.seek(0)
print('########分界线#######')
print(f2.readline(),end='\n')#只能读取一行
f2.seek(0)
print(f2.readlines())#读取多行,并且是一个列表

注:列表可以用for循环读取。
truncate(size)
从文件的首行字符开始截断,截断文件为size个字节,无size表示从当前位置截断,截断之后后面的所有字符被删除。
f = open('log',mode='w+',encoding='utf-8')
f.write('晴川历历汉阳树,芳草萋萋鹦鹉洲')
f.truncate(3)#按字节,一个中文三个字节,否则引发异常
f.seek(0)
print(f.read())
f.close()
f = open('log',mode='w+',encoding='utf-8')
f.write('晴aaa川历历汉阳树,芳草萋萋鹦鹉洲')
f.truncate(5)#按字节,一个中文三个字节,否则引发异常
f.seek(0)
print(f.read())
f.close()

编码
编码概述
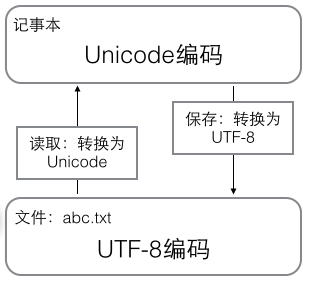
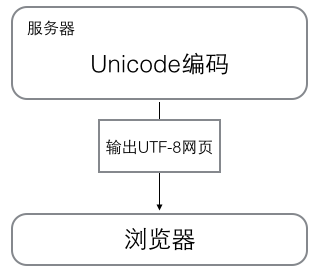
在计算机内存中,统一使用unicode编码,当需要保存到硬盘中或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把unicode转换为utf-8保存到文件:
浏览网页的时候,服务器会把动态生成的unicode内容转换为utf-8再传输到浏览器:
#str --->bytes encode 编码
s = '李白'#字符串是unicode
b = s.encode('utf-8')#编码成其他编码方式用来保存或传输
print(b,type(b))
#bytes --->str decode 解码
s1 = b.decode('utf-8')
print(s1,type(s1))

s = 'aaa'
b = s.encode('utf-8')#编码
print(b,type(b))
#bytes --->str decode 解码
s1 = b.decode('gbk')
print(s1,type(s1))

pass
python学习日记(文件操作)的更多相关文章
- python学习笔记:文件操作和集合(转)
转自:http://www.nnzhp.cn/article/16/ 这篇博客来说一下python对文件的操作. 对文件的操作分三步: 1.打开文件获取文件的句柄,句柄就理解为这个文件 2.通过文件句 ...
- python学习总结---文件操作
# 文件操作 ### 目录管理(os) - 示例 ```python # 执行系统命令 # 清屏 # os.system('cls') # 调出计算器 # os.system('calc') # 查看 ...
- 03 python学习笔记-文件操作(三)
本文内容主要包括以下方面: 1. 文件操作基本认识2. 只读(r, rb)3. 只写(w, wb)4. 追加(a, ab)5. r+读写6. w+写读7. a+写读(追加写读)8. 文件的修改 一.文 ...
- python学习day8 文件操作(深度学习)
文件操作 (day7内容扩展) 1 文件基本操作 obj = open('路径',mode='模式',encoding='编码')obj.write()obj.read()obj.close() 2 ...
- python 学习分享-文件操作篇
文件操作 f_open=open('*.txt','r')#以只读的方式(r)打开*.txt文件(需要与py文件在同一目录下,如果不同目录,需写全路径) f_open.close()#关闭文件 打开文 ...
- Python学习笔记——文件操作
python中,一切皆对象. 一.文件操作流程 (1)打开文件,得到一个文件句柄(对象),赋给一个对象: (2)通过文件句柄对文件进行操作: (3)关闭文件. 文件对象f通过open()函数来创建 ...
- Python学习之==>文件操作
1.打开文件的模式 r,只读模式(默认)[不可写:文件不存在,会报错] w,只写模式[不可读:不存在则创建:存在则删除内容] a,追加模式[不可读:不存在则创建:存在则追加内容] r+,读写模式[可读 ...
- Python学习之文件操作
Python 文件打开方式 文件打开方法:open(name[,mode[buf]]) name:文件路径mode:打开方式buf:缓冲buffering大小 f = open('test.txt', ...
- Python学习 :文件操作
文件基本操作流程: 一. 创建文件对象 二. 调用文件方法进行操作 三. 关闭文件(注意:只有在关闭文件后,才会写入数据) fh = open('李白诗句','w',encoding='utf-8') ...
随机推荐
- Palindromic characteristics CodeForces - 835D (区间DP,预处理回文串问题)
Palindromic characteristics of string s with length |s| is a sequence of |s|integers, where k-th num ...
- mysql面试题目1
有这样一个成绩表,学生A,B,C,三个人,考试科目分别为C(chinese),M(math),E(english) 求三门课成绩都大于80分的那个学生姓名: 即查询的方法可分为俩种:select na ...
- java 8中抽象类与接口的异同
1.java 8中抽象类与接口的异同 相同点: 1)都是抽象类型: 2)都可以有实现方法(以前接口不行): 3)都可以不需要实现类或者继承者去实现所有方法,(以前不行,现在接口中默认方法不需要实现者实 ...
- semantic-ui 图标
semantic-ui提供了很多的图标,基本常用的在官网上面都能找到.要想记住这么多图标是不可能的,但是也是有简便方法记忆. 首先,图标其实和按钮的区别基本没有,要说有的话,也就是基础样式的大小不同吧 ...
- React-Native之截图组件view-shot的介绍与使用
React-Native之截图组件view-shot的介绍与使用 一,需求分析 1,需要将分享页生成图片,并分享到微信好友与朋友圈. 二,react-native-view-shot介绍 1,可以截取 ...
- java lang(ClassLoader)
一.什么是ClassLoader? 大家都知道,当我们写好一个Java程序之后,不是管是CS还是BS应用,都是由若干个.class文件组织而成的一个完整的Java应用程序,当程序在运行时,即会调用该程 ...
- 994.Contiguous Array 邻近数组
描述 Given a binary array, find the maximum length of a contiguous subarray with equal number of 0 and ...
- day 7-8 协程
不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去调 只要你用并发,就会有锁的问题,但是你不能一直去自己加锁吧那么我们 ...
- C# Note28: Dispatcher类
在项目中也是经常用到: 刚见到它时,你会想:为什么不直接使用System.Windows命名空间下的MessageBox类,何必要这么麻烦?(认真分析看它做了什么,具体原因下面解释) 主要介绍的方法: ...
- C#Note13:如何在C#中调用python
前言 IronPython 是一种在 .NET 及 Mono上的 Python 实现,由微软的 Jim Hugunin(同时也是 Jython 创造者) 所发起,是一个开源的项目,基于微软的 DLR ...