AI - Tips
01 - 10
01- Playground
http://playground.tensorflow.org
TensorFlow的网页工具Playground提供了几种简单类型的data,可以调节网络结构、学习率、激活函数、正则项等参数,非常直观地看到每个神经元和相关输出的变化,体会到简化的深度学习模型调参的过程。
注意:Playground每次重置后都将采用新的训练数据和测试数据,因此每次运行Playground的结果也就不同。
02- ConvNetJS
https://cs.stanford.edu/people/karpathy/convnetjs/
ConvNetJS将一些经典数据集(如Mnist和Cifar-10)每层网络的输出可视化出来,帮助理解不同网络做了什么事情。
03- 深度学习框架

Keras是一个模型级(model-level)的库,可以将TensorFlow、Theano、CNTK等进一步封装(作为后端引擎),因为高度封装,所以使用起来相对简单。
如果不想花太多时间在框架上,但又想去实现一个神经网络模型的话,建议去学习Keras。
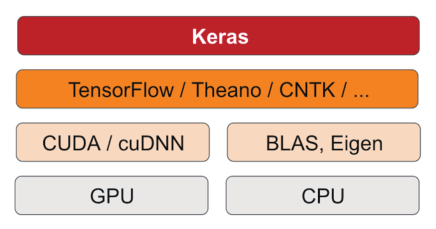
04- 速查表
05- 使用Linux平台进行深度学习
如果要做深度学习,Linux还是首选,因为其对很多学习模型支持比较好(主要是深度学习的Library)。
如果使用的是Windows系统,可以使用虚拟机来安装Ubuntu来进行学习。
小型的深度学习模型足够了,大型的深度学习我们很少在本地/个人计算机上运行。
06- 机器学习在实际应用中避免缺陷的几个关注点
1 - 仔细考虑如何拆分样本:了解数据代表的含义,才能有效的进行数据拆分。
2 - 避免 “标签泄漏” (一些训练标签泄漏到特征中,使模型带有欺骗性)。
3 - 一些有效的机器学习准则
- 确保第一个模型简单易用
- 着重确保数据管道的正确性
- 使用简单且可观察的指标进行训练和评估
- 拥有并监控您的输入特征
- 将您的模型配置视为代码:进行审核并记录在案
- 记下所有实验的结果,尤其是“失败”的结果
10- LaTex数学公式
LaTex 是一种基于 TeX 的排版系统,适用于生成复杂的表格、公式、化学方程式等。
List of LaTeX symbols:http://latex.wikia.com/wiki/List_of_LaTeX_symbols
在线生成和验证数学公式(LaTex)
- LaTex Practice Box:http://www.forkosh.com/mathtextutorial.html
- LaTex Editor:https://codecogs.com/latex/eqneditor.php
- Latex Equation Editor:https://www.numberempire.com/latexequationeditor.php
11 - 20
11- 在cnblogs博客中插入LaTex数学公式
1- 登录博客--》管理--》选项--》勾选“启用数学公式支持”--》保存。
2- 登录博客--》设置 --》页首Html代码,添加内容<script type="text/javascript" src="http://common.cnblogs.com/script/ASCIIMathML.js"></script>--》保存。
3- 可以在博客中直接使用latex语法公式(公式必须以$作为开头和结尾)。
注意:步骤2的添加内容也可以是<script src="http://latex.codecogs.com/latex.js" type="text/javascript"></script>。
12- Kaggle
http://www.kaggle.com/
对于机器学习的初学者,可以将Kaggle当做一个低成本的应用机器学习的机会,目的在于参与与体验,了解大神的经验和看法、如何将技能落在实处。
国内类似的平台有天池大数据竞赛(https://tianchi.aliyun.com/)和DataCastle(http://www.pkbigdata.com/)。
13- 问题处理:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
问题描述:运行ensorFlow(CPU版本)代码时报如下错误。
2019-01-10 17:18:22.458207: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
问题处理:
方法1:在代码中加入如下代码,忽略警告。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
方法2:换成支持cpu用AVX2编译的TensorFlow版本从而彻底解决此问题。
参考信息:
- https://blog.csdn.net/hq86937375/article/details/79696023
- https://blog.csdn.net/z564359805/article/details/81873350
14- 关于算法
算法是机器学习的核心。一般意义上的“学习‘机器学习’”,也是从算法开始。
机器学习领域十分繁杂,根本不可能真正深入理解几十种不同的算法。
应该了解一些基础的算法,比如:朴素贝叶斯、支持向量机、感知器、决策树等。
但请专注于那些有发展潜力的架构,比如:神经网络、强化学习等。
仅从使用角度而言,掌握算法,大致可分为如下由浅入深的几步:
简单使用:了解某个算法基本原理,应用领域,功能和局限。
- 该算法的应用问题域是什么?
- 该算法的应用目标是什么?
- 该算法适合应用在怎样的数据集,它能对数据造成怎样的影响?
- 能够主动获取该算法的函数库,调用该算法生成模型。
算法优化:对所采用算法和对应模型的数学公式有所了解。
- 知道调用函数中各个参数的意义,能够通过调节这些参数达到优化结果的目的。
- 能够通过加约束条件来优化算法。
- 了解在当前问题域,目标和输入数据确定的情况下,还可以用哪些其他模型可替换现有模型,并进行尝试。
- 能够将多个弱模型加权组成强模型。
运行效率优化:对模型本身的数学推导过程和模型最优化方法有所掌握,对于各种最优化方法的特点、资源占用及消耗情况有所了解。
- 了解算法在当前数据集上的运行效率。
- 了解在其他语言、平台、框架的工具包中有否同等或近似功能但在当前应用场景下效率更高的算法。
- 能够针对具体场景,通过转换模型的最优化方法(optimizer)来改进运行效率。
丰富的数据胜过聪明的算法
在计算机科学中,通常情况下,两个主要的资源限制是时间和内存。但在机器学习中,还有第三个约束:训练数据。
根据经验,在“时间受限”的情景下,具有大量数据的傻瓜算法往往胜过一个具有适度数量的聪明算法。
复杂的学习器虽然很吸引人,但通常耗时并且很难使用。
通常,首先尝试最简单的学习器(例如,逻辑回归前的朴素贝叶斯,支持向量机之前的邻近算法)。
15- Scikit-Learn_algorithm_cheat-sheet
https://scikit-learn.org/stable/_static/ml_map.png
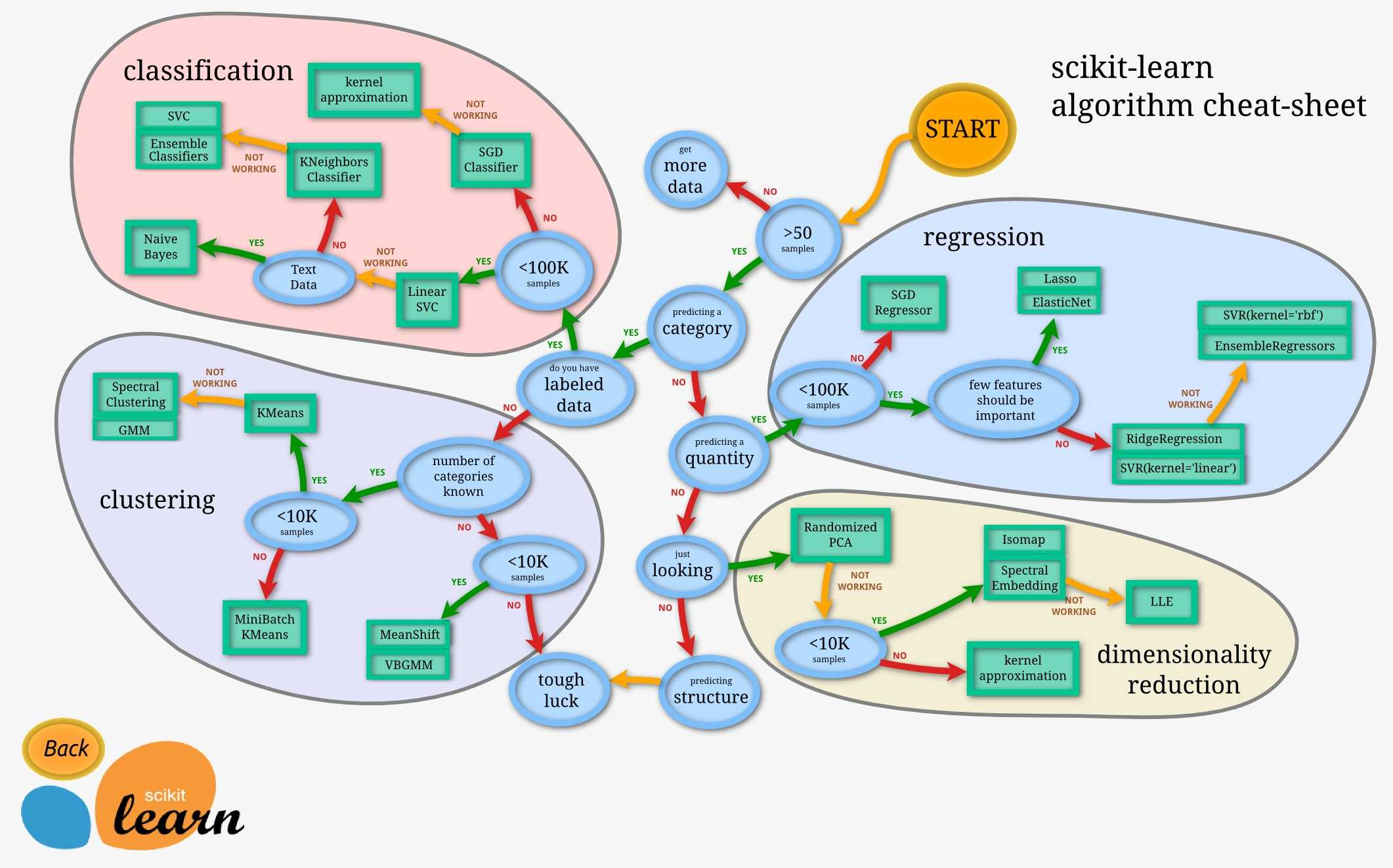
{kind=link}
16- 模型的保存与恢复
- 保存和恢复 - TensorFlow:https://www.tensorflow.org/guide/saved_model?hl=zh-cn
- 保存和恢复模型 - tf.keras:https://www.tensorflow.org/tutorials/keras/save_and_restore_models?hl=zh-cn
- 在Eager中保存 - 基于对象的保存:https://www.tensorflow.org/guide/eager?hl=zh-cn#object_based_saving
17- 迁移TensorFlow1.x到TensorFlow2.0
一行代码迁移 TensorFlow 1.x 到 TensorFlow 2.0:https://www.infoq.cn/article/6KPET-j2caEbfS79wVWg
18 - Kubeflow
- https://www.kubeflow.org/
- 利用开源的Kubeflow可以搭建一个麻雀虽小五脏俱全的机器学习平台。利用这一平台对模型进行训练。
- 轻松扩展你的机器学习能力-Kubeflow:https://my.oschina.net/taogang/blog/2052152
- 基于 Kubeflow 的机器学习调度平台落地实战:https://www.infoq.cn/article/k4uLIMaNccimGfuQk_cd
19 - 机器学习学到多深够用?
原文链接 - 机器学习学到多深够用?
作为程序员、工程人员(算法使用者而非研究者),想用机器学习算法解决实际问题,至少要在三个维度上达到一定深度的掌握:算法、数据和验证。
算法
算法是机器学习的核心。一般意义上的“学习‘机器学习’”,也是从算法开始。
仅从使用角度而言,掌握算法,大致可分为如下由浅入深的几步:
简单使用:了解某个算法基本原理,应用领域,功能和局限。
- 该算法的应用问题域是什么?
- 该算法的应用目标是什么?
- 该算法适合应用在怎样的数据集,它能对数据造成怎样的影响?
- 能够主动获取该算法的函数库,调用该算法生成模型。
算法优化:对所采用算法和对应模型的数学公式有所了解。
- 知道调用函数中各个参数的意义,能够通过调节这些参数达到优化结果的目的。
- 能够通过加约束条件来优化算法。
- 了解在当前问题域,目标和输入数据确定的情况下,还可以用哪些其他模型可替换现有模型,并进行尝试。
- 能够将多个弱模型加权组成强模型。
运行效率优化:对模型本身的数学推导过程和模型最优化方法有所掌握,对于各种最优化方法的特点、资源占用及消耗情况有所了解。
- 了解算法在当前数据集上的运行效率。
- 了解在其他语言、平台、框架的工具包中有否同等或近似功能但在当前应用场景下效率更高的算法。
- 能够针对具体场景,通过转换模型的最优化方法(optimizer)来改进运行效率。
数据
仅仅只有算法,并不能解决问题。算法和数据结合,才能获得有效的模型。
对于数据,需要从“具有业务含义的信息”和“用于运算的数字”这两个角度来对其进行理解和掌握。
特征选取:从业务角度区分输入数据包含的特征,并认识到这些特征对结果的贡献。
- 对数据本身和其对应的业务领域有所了解。
- 能够根据需要标注数据。
- 知道如何从全集中通过划分特征子集、加减特征等方法选取有效特征集。
向量空间模型(VSM)构建:了解如何将自然语言、图片等人类日常使用的信息转化成算法可以运算的数据。
- 能够把文字、语音、图像等输入转化成算法所需输入格式(一般为实数空间的矩阵或向量)。
- 能够根据信息熵等指标选取有效特征。
数据处理:运用统计学方法处理输入数据。
- 能够对数据进行归一化(normalization), 正则化(regularization)等标准化操作。
- 能够采用bootstrap等采样方法处理有限的训练/测试数据,以达到更好的运算效果。
验证
算法+数据就能够得到模型。但是这个模型的质量如何?这个模型和那个模型比较,哪个更适合解决当前问题?在做了如此这般的优化之后得出了一个新的模型,怎么能够确认它比旧的模型好?
为了解答这些问题,就需要掌握度量模型质量的方法。
- 了解bias,overfitting等基本概念,及针对这些情况的基本改进方法。
- 了解各种模型度量指标的计算方法和含义,及其对模型质量的影响。
- 能够构建训练集、测试集,并进行交叉验证。
- 能够运用多种不同的验证方法来适应不同的数据集。
注意
上面所说的全部都是针对基于统计的机器学习算法而言的(典型算法包括:线性回归,逻辑回归,朴素贝叶斯法、决策树、支持向量机、隐马尔可夫模型、条件随机场等等)。
当前比机器学习更热的深度学习(Deep Learning),玩法很不相同。
CNN, DNN, RNN, LSTM等一众神经网络,淡化甚至省略了特征筛选的部分,对标注数据量和运算能力的要求却极大。
在数据量不足的情况下,深度学习效果甚至还不如一般的统计学习方法。而如果运算能力不足,则可能导致不可容忍的训练时间。
而且相对于统计学习方法而言,深度学习的理论性相对不够成熟,试验的成分很高,许多方法还在探索之中。
因此,现阶段,人工智能领域的普通工程开发者(程序员),更有可能应用到的是没那么酷的基于统计的机器学习算法,而非深度学习。
20 - 机器学习项目流程举例
从业务流程来看,机器学习项目基本就是了解业务需求 ->调研业界方案 -> 查看是否适用 -> 上线效果。
小型NLP项目流程举例:

AI - Tips的更多相关文章
- 来自AI的Tips——情景智能
来自AI的Tips--情景智能 上一次我们介绍了华为快服务智慧平台是什么,今天我们来侃一侃平台最有代表性的一个流量入口--情景智能(AI Tips). 首先情景智能在哪呢?大家可以拿出自己的华 ...
- Mac上MySQL忘记root密码且没有权限的处理办法&workbench的一些tips (转)
忘记Root密码肿么办 Mac上安装MySQL就不多说了,去mysql的官网上下载最新的mysql包以及workbench,先安装哪个影响都不大.如果你是第一次安装,在mysql安装完成之后,会弹出来 ...
- [深度学习]实现一个博弈型的AI,从五子棋开始(2)
嗯,今天接着来搞五子棋,从五子棋开始给小伙伴们聊AI. 昨天晚上我们已经实现了一个五子棋的逻辑部分,其实讲道理,有个规则在,可以开始搞AI了,但是考虑到不够直观,我们还是顺带先把五子棋的UI也先搞出来 ...
- 【深度学习系列】一起来参加百度 PaddlePaddle AI 大赛吧!
写这个系列写了两个月了,对paddlepaddle的使用和越来越熟悉,不过一直没找到合适的应用场景.最近百度搞了个AI大赛,据说有四个赛题,现在是第一个----综艺节目精彩片段预测 ,大家可以去检测一 ...
- (转) Using the latest advancements in AI to predict stock market movements
Using the latest advancements in AI to predict stock market movements 2019-01-13 21:31:18 This blog ...
- 聊聊找AI算法岗工作
https://blog.csdn.net/weixin_42137700/article/details/81628028 首先,本文不是为了增加大家的焦虑感,而是站在一名学生的角度聊聊找AI算法岗 ...
- AI 基础
what AI ? 人工智能(Artificial Intelligence),英文缩写为AI. 人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的 ...
- Newtonsoft.Json C# Json序列化和反序列化工具的使用、类型方法大全 C# 算法题系列(二) 各位相加、整数反转、回文数、罗马数字转整数 C# 算法题系列(一) 两数之和、无重复字符的最长子串 DateTime Tips c#发送邮件,可发送多个附件 MVC图片上传详解
Newtonsoft.Json C# Json序列化和反序列化工具的使用.类型方法大全 Newtonsoft.Json Newtonsoft.Json 是.Net平台操作Json的工具,他的介绍就 ...
- AlphaZero并行五子棋AI
AlphaZero-Gomoku-MPI Link Github : AlphaZero-Gomoku-MPI Overview This repo is based on junxiaosong/A ...
随机推荐
- [Hadoop]Hadoop章3 NameNode的ZKFC机制
基本概念 首先我们要明确ZKFC 是什么,有什么作用: zkfc是什么? ZooKeeperFailoverController 它是什么?是Hadoop中通过ZK实现FC功能的一个实用工具. 主要作 ...
- HDU4460
#include <iostream> #include <queue> #include <vector> #include <cstring> #i ...
- 《Miracle-House团队》项目需求分析改进
(一)团队项目需求分析改进 一.<西小餐项目需求规格说明书>的不足 通过老师和其他同学的指正和建议,我们发现上次的需求规格说明书存在以下不足: 1.需求规格文档不够完整和规范: 2.系统设 ...
- django model设计与实际数据库表的对比
# 文章class Article(models.Model): title = models.CharField('标题', max_length=70) excerpt = models.Text ...
- Maven学习 八 采用Maven搭建SSM环境
第一步:创建一个Maven项目 项目的打包方式选择,war 第二步:在webapp下面创建java web项目的目录结构,并配置web.xml文件 <?xml version="1.0 ...
- KVM 虚拟机的热迁移
热迁移:顾名思义在虚拟机不关机的情况下将KVM虚拟机进行迁移 准备工作:两台KVM虚拟机,一台nfs虚拟机,centos7.4系统 主机 IP地址 主机名 KVM01 10.00.11 kvm01 K ...
- 语音端点检测(Voice Activity Detection,VAD)
本文内容均翻译自这篇博文:(该博主的相关文章都比较好,感兴趣的可以自行学习) Voice Activity Detection(VAD) Tutorial 语音端点检测一般用于鉴别音频信号当中的语音出 ...
- python文件操作打开模式 r,w,a,r+,w+,a+ 区别辨析
主要分成三大类: r 和 r+ "读"功能 r 只读 r+ 读写(先读后写) 辨析:对于r,只有读取功能,利用光标的移动,可以选择要读取的内容. 对于r+,同时具有读和写 ...
- 《Linux就该这么学》第十三天课程
使用Apache服务部署静态网站 原创地址:https://www.linuxprobe.com/chapter-10.html 今天学了Apache,这只是RHCE课程的开始,估计后面越来越难 今天 ...
- 28. 实现strStr()
实现 strStr() 函数. 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始).如果不存在,则返 ...