Hive(一)
1. HIVE概念:
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序
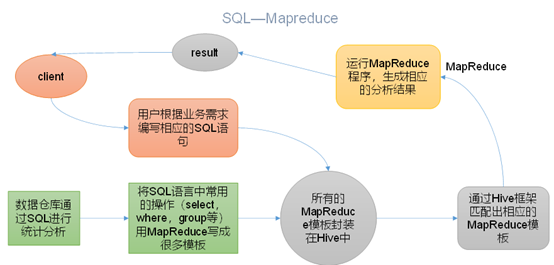
1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
2. HIVE优缺点
优点:
1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2)避免了去写MapReduce,减少开发人员的学习成本。
3)ive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
4)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
Hive的HQL表达能力有限
迭代式算法无法表达
数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
3. Hive架构原理
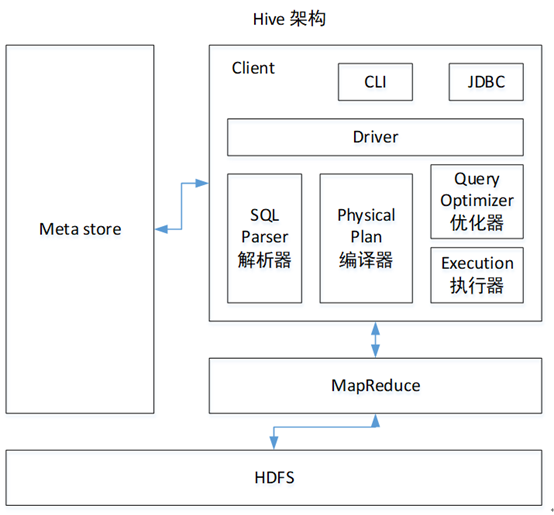
1.用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
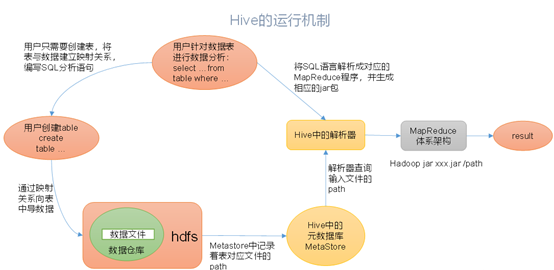
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
4. Hive安装地址
1.Hive官网地址
http://hive.apache.org/
2.文档查看地址
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3.下载地址
http://archive.apache.org/dist/hive/
4.github地址
https://github.com/apache/hive
5. Hive安装部署
1)解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
2)修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
3)配置hive-env.sh文件

4)Hadoop集群配置
必须启动hdfs和yarn
6. 配置Metastore到MySql
(1)拷贝/mysql-libs/mysql-connector-java-5.1.27目录下的mysql-connector-java-5.1.27-bin.jar到/hive/lib/下
(2)在/hive/conf目录下创建一个hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl"
href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a
JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a
JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against
metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>密码</value>
<description>password to use against
metastore database</description>
</property>
</configuration>
(3)配置完毕后,如果启动hive异常,可以重新启动虚拟机
7. Hive数据仓库位置配置
1)Default数据仓库的最原始位置是在hdfs上的:/user/hive/warehouse路径下。
2)在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
3)修改default数据仓库原始位置(将hive-default.xml.template如下配置信息拷贝到hive-site.xml文件中)。
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the
warehouse</description>
</property>
8. 查询后信息显示配置
1)在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2)重新启动hive
9. Hive运行日志信息配置
1.Hive的log默认存放在/tmp/用户名/hive.log目录下(当前用户名下)
2.修改hive的log存放日志到/opt/module/hive/logs
(1)修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为
(2)在hive-log4j.properties文件中修改log存放位置
hive.log.dir= /opt/module/hive/logs
10.
参数配置方式
1.查看当前所有的配置信息
hive>set;
2.参数的配置三种方式
(1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
(2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:
bin/hive
-hiveconf mapred.reduce.tasks=10;
注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
(3)参数声明方式
可以在HQL中使用SET关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次hive启动有效。
查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
11.
HIVE基本数据类型
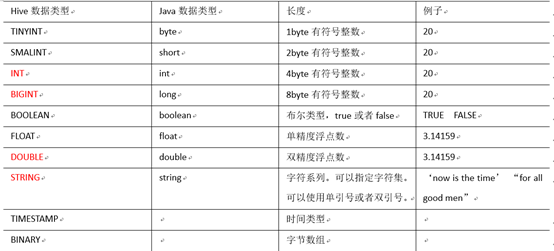
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
集合数据类型
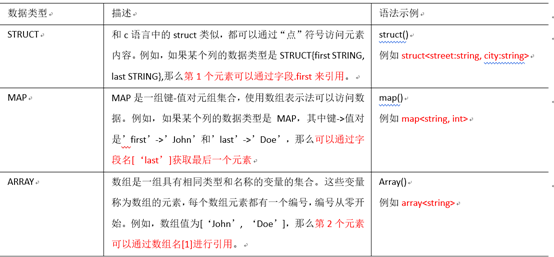
Hive有三种复杂数据类型ARRAY、MAP
和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
字段解释:
row format delimited fields
terminated by ',' -- 列分隔符
collection items terminated
by '_' --MAP
STRUCT 和 ARRAY 的分隔符(数据分割符号)多个集合分割符号要保持一致
map keys terminated by ':' -- MAP中的key与value的分隔符
lines terminated by '\n'; -- 行分隔符
12.
HIVE基本操作
(1)本地文件导入Hive
hive> load data local inpath ‘路径’ into table 表名
(2)常用交互命令

<1>“-e”不进入hive的交互窗口执行sql语句
bin/hive -e "select id from student;"
<2>“-f”执行脚本中sql语句
bin/hive -f /opt/module/datas/hivef.sql
(3) 退出hive窗口
hive(default)>exit;
hive(default)>quit;
在新版的hive中没区别了,在以前的版本是有的:
exit:先隐性提交数据,再退出;
quit:不提交数据,退出;
(4) 在hive cli命令窗口中如何查看hdfs文件系统
hive(default)>dfs -ls /;
(5) 在hive cli命令窗口中如何查看本地文件系统
hive(default)>! ls /opt/module/datas;
(6) 查看在hive中输入的所有历史命令
进入到当前用户的根目录/root或/home/用户名
查看. hivehistory文件
cat .hivehistory
13.
HiveJDBC访问
(1) 启动hiveserver2服务
bin/hiveserver2
(2) 启动beeline
bin/beeline
(3) 连接hiveserver2
beeline> !connect
jdbc:hive2://hiveserver2所在的主机:10000(jdbc协议回车)
Connecting to
jdbc:hive2:// hiveserver2所在的主机:10000(10000:端口号)
Enter username for
jdbc:hive2:// hiveserver2所在的主机:10000: 连接的主机用户名(回车)
Enter password for
jdbc:hive2:// hiveserver2所在的主机:10000: (无需密码直接回车)
Hive(一)的更多相关文章
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- HIVE教程
完整PDF下载:<HIVE简明教程> 前言 Hive是对于数据仓库进行管理和分析的工具.但是不要被“数据仓库”这个词所吓倒,数据仓库是很复杂的东西,但是如果你会SQL,就会发现Hive是那 ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
- hive
Hive Documentation https://cwiki.apache.org/confluence/display/Hive/Home 2016-12-22 14:52:41 ANTLR ...
- 深入浅出数据仓库中SQL性能优化之Hive篇
转自:http://www.csdn.net/article/2015-01-13/2823530 一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,R ...
- Hive读取外表数据时跳过文件行首和行尾
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 有时候用hive读取外表数据时,比如csv这种类型的,需要跳过行首或者行尾一些和数据无关的或者自 ...
- Hive索引功能测试
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 从Hive的官方wiki来看,Hive0.7以后增加了一个对表建立index的功能,想试下性能是 ...
- 轻量级OLAP(二):Hive + Elasticsearch
1. 引言 在做OLAP数据分析时,常常会遇到过滤分析需求,比如:除去只有性别.常驻地标签的用户,计算广告媒体上的覆盖UV.OLAP解决方案Kylin不支持复杂数据类型(array.struct.ma ...
随机推荐
- redis缓存雪崩、穿透、击穿概念及解决办法
缓存雪崩 对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机.缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据 ...
- sql语句order by排序问题
根据某个字段的值排序,等于这个值的放最前面,不等的放后面 select * from [DTS_Interface] order by case when from_tag_name='木质饰条' t ...
- 2018年 js 简易控制滚动条滚动的简单方法
首先是es2015 的新api Element.scrollIntoView() // 滚动到最上方 等同于 dom.scrollIntoView(true) Element.scrollIntoVi ...
- boost Asio网络编程简介
:first-child { margin-top: 0px; } .markdown-preview:not([data-use-github-style]) h1, .markdown-previ ...
- 自适应Web主页
HTML <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- python基础中的四大天王-增-删-改-查
列表-list-[] 输入内存储存容器 发生改变通常直接变化,让我们看看下面列子 增---默认在最后添加 #append()--括号中可以是数字,可以是字符串,可以是元祖,可以是集合,可以是字典 #l ...
- Autel MaxiTPMS TS601 Wireless TPMS Sensor Reset Relearn Activate Programming Tool
Why Choose Autel TPMS TS601? MaxiTPMS TS601 is a TPMS tool with highest performance in the world. It ...
- 201621123002《JAVA程序设计》第十四周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结与数据库相关内容. 2. 使用数据库技术改造你的系统 2.1 简述如何使用数据库技术改造你的系统.要建立什么表?截图你的表设计. 用 ...
- SQL Injection-Http请求的参数中对特殊字符的处理
1.背景:最近学习webgoat到了SQL Injection的这一课,要完成这一课需要拦截Http请求,修改参数,不过在修改的参数中加入特殊字符才能完成.下面让我们一起来学习吧. 2.题目: 大致翻 ...
- 五、Pyqt5事件、信号和槽
PyQt中提供了两种针对事件处理的机制:一种是事件,另一种则是信号和槽. 一.事件 事件处理在PyQt中是比较底层的,常用的事件有键盘事件.鼠标事件.拖放事件.滚轮事件.定时事件.焦点事件.进入和离开 ...