降维方法PCA与SVD的联系与区别
在遇到维度灾难的时候,作为数据处理者们最先想到的降维方法一定是SVD(奇异值分解)和PCA(主成分分析)。
两者的原理在各种算法和机器学习的书籍中都有介绍,两者之间也有着某种千丝万缕的联系。本文在简单介绍PCA和SVD原理的基础上比较了两者的区别与联系,以及两者适用的场景和得到的效果。
一、SVD
1.1 特征值分解
在说奇异值分解之前,先说说特征值分解,特征值分解 \(A = PDP^{-1}\) ,只对A为正交矩阵来说,且得到的D是对角的。由于特征值分解和奇异值分解的本质都是矩阵分解,其本身的几何意义没有那么明显,我们能够看到的是矩阵分解后的三个矩阵对于几何变换的意义。
假设对称矩阵A有m个不同的特征值,设特征值为 \(\lambda_{i}\) ,对应的单位特征向量为 \(x_{i}\) ,则有:
\(Ax_{1}=\lambda_{1}x_{1}\)
\(Ax_{2}=\lambda_{2}x_{2}\)
...
\(Ax_{m}=\lambda_{m}x_{m}\)
进而...
\(AU=U\Lambda\)
U为单位正交矩阵,其每个列向量为A对应的单位特征向量,所以U的逆等于U的转置,可得:
\(A=U\Lambda U^{T}\)
这里,我们已经进行完了特征值分解,将A分解成了三个矩阵,现在让我们用A来对一个向量 \(x\) 进行变换,即:
\(Ax=U\Lambda U^{T}x\)
我们先把三个分解后的矩阵打开来看:
\(Ax=[x_{1},x_{2}...x_{m}]\begin{bmatrix}\lambda_{1} && \\ & ... & \\ && \lambda_{m}\end{bmatrix} \begin{bmatrix}x_{1}^{T}\\x_{2}^{T}\\...\\x_{m}^{T}\end{bmatrix}x\)
对等式右边做递归相乘操作:
- \(U^{T}\) 的每一行对应一个单位正交向量,也可以说它的所有行构成了一组新的单位正交基。 \(U^{T}x\) 的结果相当于 \(U^{T}\) 的每一行与\(x\)向量做内积,内积的几何意义在于一个向量\(x\)在另一向量 \(x_{1}^{T}\) 上的投影再乘以 \(x_{1}^{T}\) 的模,对于单位矩阵 \(x_{1}^{T}\) 来说,这个模为1。所以, \(U^{T}x\) 的几何意义就是一个正交变换,将\(x\)向量映射到新的正交基上,其结果为新基上的坐标。这个过程可以看作是旋转。
- 再看 \(\Lambda U^{T}x\) , \(\Lambda\) 是一个对角矩阵,对角矩阵的元素即为A的特征值。这个过程相当于对 \(U^{T}x\) 的结果的每一维做了一个拉伸或收缩,且如果某一维度的特征值为0,则这一维度直接去除。
- 最后看 \(U\Lambda U^{T}x\) ,与1同理,同样是进行一个单位正交变换,由于U和U'是互为逆矩阵,所以U变换是U’变换的逆变换。
现在可以看到特征值分解的意义了:
假设对称阵特征值全为1那么显然它就是单位阵,如果对称阵的特征值有个别是0其他全是1,那么它就是一个正交投影矩阵,它将m维向量投影到它的列空间中。
1.2 奇异值分解(SVD)
先看几何意义:SVD分解的结果为: \(A =U \Sigma V^{T}\) ,与前面的特征值分解1~4相似,几何意义可以理解为:
A 是一个线性变换,把 A 分解成 USV',S 给出了变换后椭圆长短轴的长度, U 和 V'一起确定了变换后的方向,所以 U、S、V' 包含了这个线性变换的全部信息。S 矩阵的对角线元素称为 A 的奇异值,与特征值一样,大的奇异值对应长轴,小的奇异值对应短轴,大的奇异值包含更多信息。
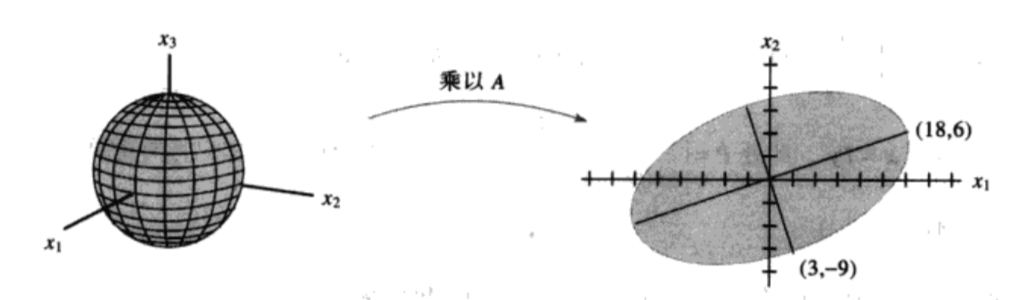
特征值分解的本质是将一组正交基映射到另一组正交基上,A为映射矩阵。那么对于非对称矩阵呢?对任意m✖️n矩阵 \(A_{m*n}\) ,能否在n维空间中找到一组正交基使得经过它变换后在m维中还是正交的呢?
为了找到这一组正交基V,我们先假设已经找到了这一组n维空间正交基 \(\{v_{1},v_{2}...,v_{n}\}\) ,
那么 \(Av_{1},Av{2}...\) 即为n维空间中的正交基经过矩阵A的变换后在m维空间的向量。请看上面的图,图表示3维空间到2维空间的一个变换,假设变换矩阵A为
\(\begin{bmatrix}4&11&14\\8&7&-2\end{bmatrix}\) (一个2✖️3的矩阵),v1为 \(\begin{bmatrix}1/3\\2/3\\2/3\end{bmatrix}\) (在3维空间中的一个单位向量)。
那么线性变换x -> Ax:
\(Av_{1}=\begin{bmatrix}4&11&14\\8&7&-2\end{bmatrix}\begin{bmatrix}1/3\\2/3\\2/3\end{bmatrix}=\begin{bmatrix}18\\6\end{bmatrix}\)
其结果正好对应2维空间椭圆的长轴,我们可以联想到A与某个特定的单位向量v2相乘应该是对应椭圆的短轴了。可是,为什么呢?
对于上例中A这个3维空间到2维空间的线性变换,我们想找出使得长度 \(||Av||\) 最大的单位向量v。使得 \(||Av||\) 最大化的v同样可以使得 \(||Av||^{2}\) 最大化,且后者更容易计算:
\(||Av||^{2}=(Av)^{T}(Av)=v^{T}A^{T}Av=v^{T}(A^{T}A)v ---(*1)\)
这是一个二次型。\(A^{T}A\)是个对称矩阵,我们可以求出其特征值\(\lambda\)和对应的特征向量\(v\):
\(A^{T}Av=\lambda v\)
带入(*1),则:
\(||Av||^{2}==v^{T}(A^{T}A)v==v^{T}\lambda v=\lambda\) ---------v是单位向量
对于每一个 \(\lambda_{i}\) ,开根号即为对应的奇异值 \(\sigma_{i}\)
可以得到, \(||Av||=\sqrt{\lambda}=\sigma\) ,所以向量v经过矩阵A变换后在m维空间中的向量长度就是对应的奇异值\(\sigma\)呀,amazing!
这就是奇异值分解中V矩阵的意义, \(AV=[Av_{1},Av_{2}...Av_{n}]\) ,等式右边矩阵中每一个Av代表n维空间中一个单位向量v经过A的映射到m维空间坐标的值,且所有向量v之间是正交的(因为对称矩阵不同特征的特征向量之间正交)。
所以\(AV\)的几何意义就是找到n维空间中的一组单位正交基\(V=[v_{1},...,v_{n}]\),使得V在通过线性变换A后,在m维空间中得到的向量仍是正交的。
那么,U矩阵是什么呢?
前面,我们已经知道 \(Av_{i}\) 代表m维空间中的向量,那么将每个 \(Av_{i}\) 单位化得到一组标准正交基 \(\{u_{1}, ...,u_{r}\}\) , 将其扩充到m维则得到U。
此处 \(u_{i}=\frac{1}{||Av_{i}||}Av_{i}=\frac{1}{\sigma_{i}}Av_{i}---(*2)\)
还记得\(\sigma\)嘛,奇异值。上面已经讨论过,每一个奇异值也是每一个向量v经过矩阵A变换后在m维空间中的向量长度。那么再看(*2)式,是不是觉得很自然了呢!
所以 \(U\Sigma=[u_{1},...u_{m}]\begin{bmatrix}\sigma_{1} && \\ & ... & \\ && \sigma_{r}..\\&&&0\end{bmatrix}=[\sigma_{1}u_{1},...,\sigma_{r}u_{r},0,...0]---(*3)\)
看(*3)的等式最右边,\(u\)为n维空间中向量v在矩阵变换A后在m维空间中的单位向量,\(\sigma\)为该单位向量的长度,所以 \(U\Sigma\) 就是n维空间中向量集V在矩阵变换A后在m维空间中的向量集,这跟\(AV\)的几何意义完全一样。
所以, \(AV=U\Sigma\)
进而, \(A=U\Sigma V^{T}\)
到这为止,奇异值分解的几何意义已经讲完了,它是将变换矩阵进行分解的一个过程,那么奇异值分解为什么可以降维呢?
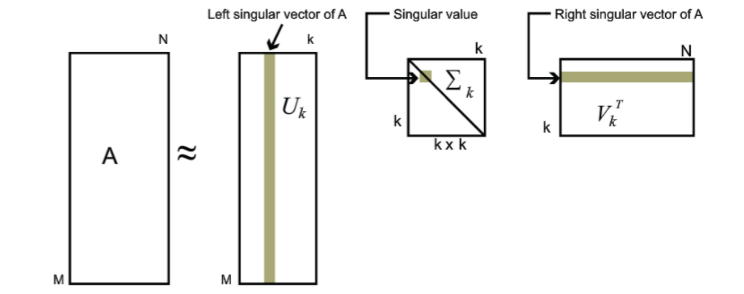
假设我们要对 \(A_{m\times n}\) 进行降维,那么通过奇异值分解 \(A_{m\times n}=U_{m\times m}\Sigma_{m\times n}V_{n\times n}\) ,等式两边等价。由于 \(\Sigma_{m\times n}\) 的对角线元素,也就是奇异值的分布是:几乎前10%甚至1%的奇异值的和占了全部奇异值只和的99%以上,也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量U和V来近似描述矩阵,即:
\(A_{m\times n}=U_{m\times m}\Sigma_{m\times n}V_{n\times n}\approx U_{m\times k}\Sigma_{k\times k}V_{k\times n}\)
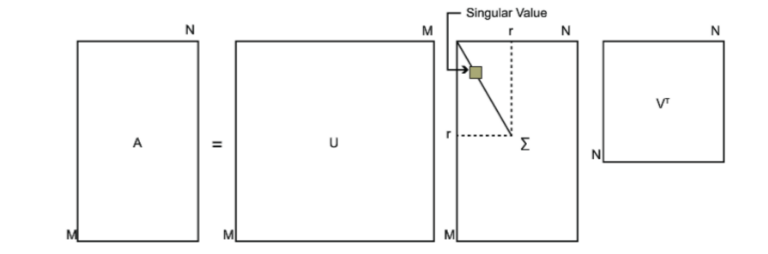
这里借用Pinard大神的两张图:
这是正常的奇异值分解:
这是可近似的分解结果:
SVD计算过程:
- 将矩阵\(A^{T}A\)正交对角化
- 算出 \(V,\Sigma\)
- 构造U
PS: 有关SVD在推荐系统上的应用可以看我的这篇博客从SVD到推荐系统
二、PCA
主成分分析是一个优化问题。
借用LittleHann大神的图:

这是一个二维坐标,上面的点是二维上的点,我们现在要用一维来表示这些点,有希望尽可能保留原来的信息,应该怎么办?这就是主成分分析需要解决的问题。
其实,上述问题我们需要解决的无非是找到一组基,使得原来的样本点映射到这组基上的距离足够近(最近重构性),且样本点在这组基上的投影尽可能分开(最大可分性)。
2.1 最大化方差
最大可分性需要是的样本点在新基上的投影尽可能分开,这种分散程度在数学上我们可以用样本点的方差来表示。方差越大,表示分散程度越大。此处,一个维度基上各样本点投影的方差可以看做是每个元素与字段均值的差的平方和的均值,即
\(Var(a)=\frac{1}{m}\sum_{i=1}^{m}(a_{i}-\mu)^{2}\)
所以,在进行PCA之前,我们需要把样本矩阵进行均值化,这样上式可以变为
\(Var(a)=\frac{1}{m}\sum_{i=1}^{m}a_{i}^{2}\)
2.2 最小化协方差
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。但是对于高维问题来说,比如从三维到二维,如果我们单纯只选择方差最大的方向,很明显,第二个选择的维度与第一个维度应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。从直观上说,让不同尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个维度不是完全独立,必然存在重复表示的信息。
数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为0,则:
\(Cov(a,b)=\frac{1}{m}\sum_{i=1}^{m}a_{i}b_{i}\)
所以,在维度均值为0的情况下,两个维度的协方差表示为其内积除以元素数m。
当协方差为0时,表示两个维度的字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。至此,我们得到了降维问题的优化目标:
将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0(各自独立),而字段的方差则尽可能大(投影后的点尽可能离散)。在正交的约束下,取最大的K个方差
2.3 协方差矩阵
对于2.1和2.2的两个优化目标(最大化方差,最小化协方差),都可以用一个矩阵来实现,这就是协方差矩阵。
假设一个二维空间,共有m个样本,按列组成矩阵X

然后用X乘X的转置,得到协方差矩阵

对角线是基上每个维度样本投影的方差,非对角线上是不同两个维度之间的字段的协方差。当前协方差矩阵是样本在原来的正交基上的情况。很明显,由于协方差不为0,所以这个分布是有冗余的。我们的目标就是找到另一组基,使得同样的这些样本在那组基上可以达到方差最大,协方差最小。
这就需要对当前协方差矩阵进行对角化了。由于协方差矩阵是对称矩阵,必然可以找到矩阵P,令\(Y=PX\),使得:
\(D=\frac{1}{m}YY^{T}=\frac{1}{m}(PX)(PX)^{T}=P(\frac{1}{m}XX^{T})P^{T}=PCP^{T}\)
其中C为原来的协方差矩阵,经过对角化之后得到D矩阵,且D矩阵的非对角线元素全为0,所以我们的优化目标优变为:
优化目标变成了寻找一个矩阵P,满足\(PCP^{T}\)是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件
所以主成分分析的步骤为:
- 设有m条n维数据,组成\(X_{n \times m}\)矩阵
- 对所有样本进行中心化
- 计算样本的协方差矩阵
- 对协方差矩阵进行特征值分解
- 取最大的k个特征值所对应的特征向量构成矩阵P
- Y=PX 即为降维到k维后的数据
最后,送上这张经典的图:
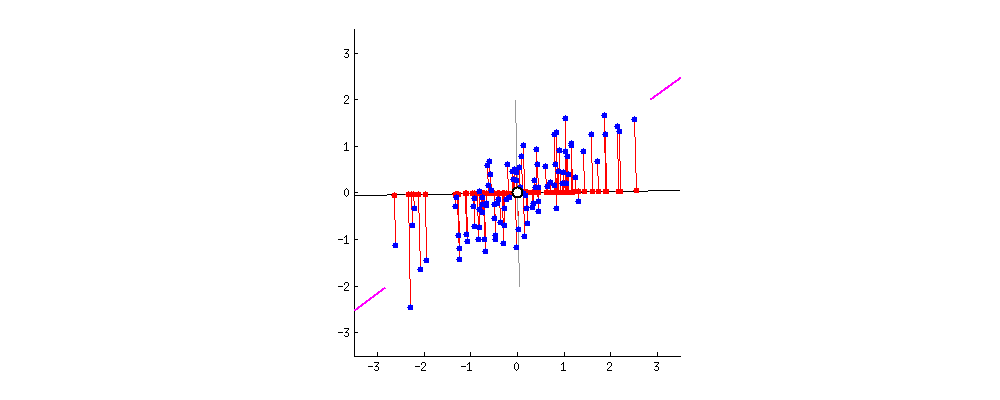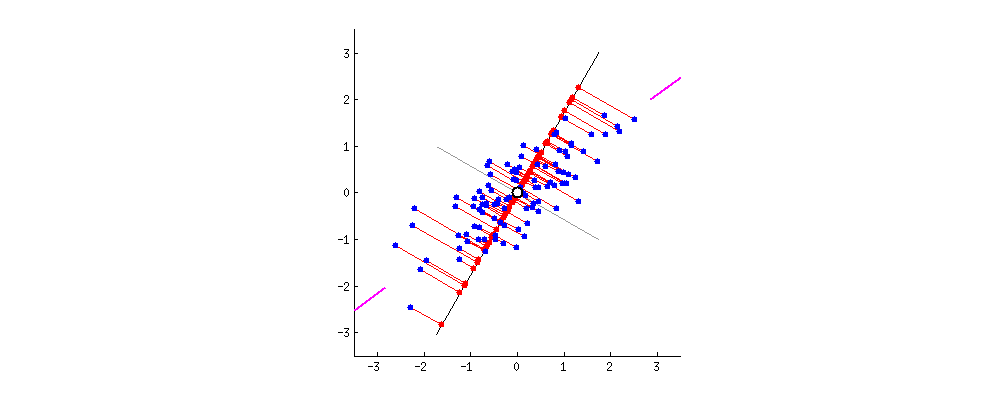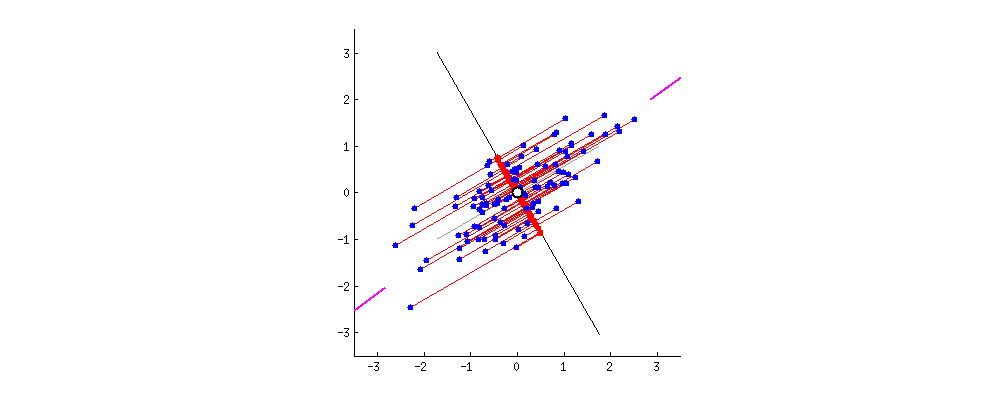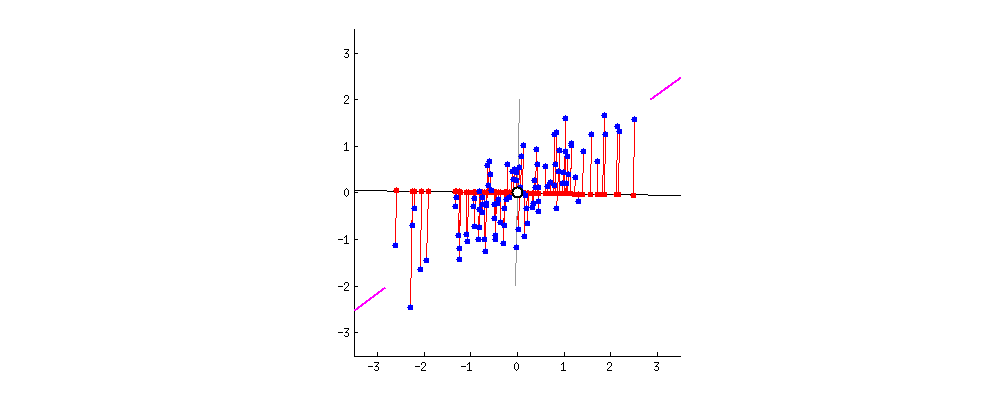
三、SVD与PCA区别与联系
3.1 从目的上来说:
SVD是一种矩阵分解方法,相当于因式分解,他的目的纯粹就是将一个矩阵拆分成多个矩阵相乘的形式。
PCA从名字上就很直观,找到矩阵的主成分,也就意味这从一出生这就是个降维的方法。
3.2 从方法上来说:
PCA在过程中要计算协方差矩阵,当样本数和特征数很多的时候,这个计算量是相当大的。
注意到SVD也可以得到协方差矩阵 \(X^{T}X\) 最大的k个特征向量张成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵\(X^{T}X\),也能求出我们的右奇异矩阵V。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。
另一方面,A的奇异值分解迭代计算比协方差矩阵的特征值分解更快更准确。
注意到PCA仅仅使用了SVD的右奇异矩阵V,没有使用左奇异矩阵U,那么左奇异矩阵有什么用呢?
假设我们的样本是m✖️n的矩阵X,如果我们通过SVD找到了矩阵 \(X^{T}X\) 的最大的k个特征向量组成的m✖️d维矩阵U,则我们进行如下处理:
\(X'_{d \times n}=U^{T}_{d \times m}X_{m\times n}\)
可以得到一个d✖️n的矩阵X',且这个矩阵和我们原来的m✖️n维的样本矩阵X相比,行数从m剪到了k,可见对行数进行了压缩。
也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
换句话说,SVD可以获取另一个方向上的主成分,而PCA只能获得单个方向上的主成分。这一点在NLP的文本处理上得到了很大体现。
3.3 从操作上来说:
下面来看sklearn手册
这是 sklearn.decomposition.PCA 的 fit_transform() 操作:
这是 sklearn.decomposition.TruncatedSVD 的 fit_transform() 操作:

看到两者的区别了嘛?两者在输出上都是一样的,唯一的区别在输入,SVD可以输入稀疏矩阵(sparse matrix)。在原理上,也可以说SVD更适于输入稀疏矩阵。
因为PCA需要进行去均值化处理,所以不可避免的破坏了矩阵的稀疏性。所以,对于稀疏矩阵来说,SVD更适用,这样对于大数据来说节省了很大空间。
四、附录:
4.1 基变换

如上图,在黑色直角坐标系(x,y)上,红色箭头表示的向量x的坐标为(3,2),现在我要改变坐标系,将该红色向量在以蓝色坐标系上(也就是另一个基)进行表示。
继续看上图,(1,1)和(-1,1)也可以成为蓝色坐标的一组基。但是一般来说,我们希望基的模是1,因为从内积的意义( \(A\cdot B=|A||B|cos\theta\) ,若A或B有一个模是1,那么内积表示的就是另一向量在模是1的向量上的投影)可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!
所以,蓝色坐标的基我们表示为 \((\frac{1}{\sqrt2},\frac{1}{\sqrt2}),(-\frac{1}{\sqrt2},\frac{1}{\sqrt2})\)
那么基变换就可以表示为:

等式左边第一个矩阵的每一行为新基向量,第二个矩阵的每一列为一个需要变换的样本。等式右边为每个样本在新基下的坐标表示。
从矩阵相乘的角度来讲:
两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换
Reference:
- 《线性代数及其应用》. David C Lay
- https://blog.csdn.net/zhongkejingwang/article/details/43053513
- http://www.cnblogs.com/LittleHann/p/6558575.html#undefined (强烈推荐)
- https://my.oschina.net/findbill/blog/535044
- https://www.cnblogs.com/pinard/p/6251584.html
- https://blog.csdn.net/wangjian1204/article/details/50642732
- 《机器学习》. 周志华
降维方法PCA与SVD的联系与区别的更多相关文章
- 机器学习实战基础(二十三):sklearn中的降维算法PCA和SVD(四) PCA与SVD 之 PCA中的SVD
PCA中的SVD 1 PCA中的SVD哪里来? 细心的小伙伴可能注意到了,svd_solver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,P ...
- 机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现
简述 在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响.同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或 ...
- 机器学习实战基础(二十二):sklearn中的降维算法PCA和SVD(三) PCA与SVD 之 重要参数n_components
重要参数n_components n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数. ...
- [机器学习理论] 降维算法PCA、SVD(部分内容,有待更新)
几个概念 正交矩阵 在矩阵论中,正交矩阵(orthogonal matrix)是一个方块矩阵,其元素为实数,而且行向量与列向量皆为正交的单位向量,使得该矩阵的转置矩阵为其逆矩阵: 其中,为单位矩阵. ...
- 机器学习实战基础(二十七):sklearn中的降维算法PCA和SVD(八)PCA对手写数字数据集的降维
PCA对手写数字数据集的降维 1. 导入需要的模块和库 from sklearn.decomposition import PCA from sklearn.ensemble import Rando ...
- 机器学习实战基础(二十四):sklearn中的降维算法PCA和SVD(五) PCA与SVD 之 重要接口inverse_transform
重要接口inverse_transform 在上周的特征工程课中,我们学到了神奇的接口inverse_transform,可以将我们归一化,标准化,甚至做过哑变量的特征矩阵还原回原始数据中的特征矩阵 ...
- 机器学习实战基础(二十五):sklearn中的降维算法PCA和SVD(六) 重要接口,参数和属性总结
到现在,我们已经完成了对PCA的讲解.我们讲解了重要参数参数n_components,svd_solver,random_state,讲解了三个重要属性:components_, explained_ ...
- 机器学习实战基础(二十):sklearn中的降维算法PCA和SVD(一) 之 概述
概述 1 从什么叫“维度”说开来 我们不断提到一些语言,比如说:随机森林是通过随机抽取特征来建树,以避免高维计算:再比如说,sklearn中导入特征矩阵,必须是至少二维:上周我们讲解特征工程,还特地提 ...
- 机器学习实战基础(二十六):sklearn中的降维算法PCA和SVD(七) 附录
随机推荐
- 搭建Hexo博客(一)-创建Hexo环境
Hexo配合github,可以创建自己的博客.基本原理是使用Hexo生成静态页面,发布到github上.在本地需要搭建Hexo环境. 1.安装nodejs 下载并安装NodeJS,官网地址:https ...
- CentOS 部署.net core 2.0 项目
上传项目到服务器 安装Nginx(反向代理服务器),配置文件 https://www.cnblogs.com/xiaonangua/p/9176137.html 安装supervisor https: ...
- java Builder模式创建不可变类
package com.geostar.gfstack.operationcenter.logger.manager.common; /** * Created by Nihaorz on 2017/ ...
- POJ 1966 Cable TV Network (算竞进阶习题)
拆点+网络流 拆点建图应该是很常见的套路了..一张无向图不联通,那么肯定有两个点不联通,但是我们不知道这两个点是什么. 所以我们枚举所有点,并把每个点拆成入点和出点,每次把枚举的两个点的入点作为s和t ...
- BZOJ 1912 巡逻(算竞进阶习题)
树的直径 这题如果k=1很简单,就是在树的最长链上加个环,这样就最大化的减少重复的路程 但是k=2的时候需要考虑两个环的重叠部分,如果没有重叠部分,则和k=1的情况是一样的,但是假如有重叠部分,我们可 ...
- 【刷题】BZOJ 1413 [ZJOI2009]取石子游戏
Description 在研究过Nim游戏及各种变种之后,Orez又发现了一种全新的取石子游戏,这个游戏是这样的: 有n堆石子,将这n堆石子摆成一排.游戏由两个人进行,两人轮流操作,每次操作者都可以从 ...
- [luogu1452]Beauty Contest【凸包+旋转卡壳】
题目大意 求出平面最远点对距离的平方. 分析 此题我wa了好久,第一是凸包写错了,后面又是旋转卡壳写错了..自闭3s. 题解应该是旋转卡壳,但是有人用随机化乱搞过掉了Orz. 讲讲正解. 我们先求出所 ...
- opencontrail-vrouter命令
vif命令 vrouter需要vrouter接口(vif)来转发流量.使用vif命令查看vrouter已知的接口. 注意: 仅在OS(Linux)中使用接口不足以进行转发.相关接口必须添加到vrout ...
- MongoDB常用操作命令
查看所有数据库: > show dbs; 选定数据库: > use ECommerce; 查看当前数据库状态: > db.stats(); 查看当前数据库中所有集合: > sh ...
- 【CF375D】Tree and Queries
题目大意:给定一棵 N 个节点的有根树,1 号节点为根节点,每个节点有一个颜色.有 M 个询问,每次询问以 i 为根的子树中颜色大于等于 K 的有多少种. 题解:子树询问直接 dfs 序转化成序列问题 ...