机器学习算法总结(四)——GBDT与XGBOOST
Boosting方法实际上是采用加法模型与前向分布算法。在上一篇提到的Adaboost算法也可以用加法模型和前向分布算法来表示。以决策树为基学习器的提升方法称为提升树(Boosting Tree)。对分类问题决策树是CART分类树,对回归问题决策树是CART回归树。
1、前向分布算法
引入加法模型

在给定了训练数据和损失函数$L(y, f(x))$ 的条件下,可以通过损失函数最小化来学习加法模型

然而对于这个问题是个很复杂的优化问题,而且要训练的参数非常的多,前向分布算法的提出就是为了解决模型的优化问题,其核心思想是因为加法模型是由多各模型相加在一起的,而且在Boosting中模型之间又是有先后顺序的,因此可以在执行每一步加法的时候对模型进行优化,那么每一步只需要学习一个模型和一个参数,通过这种方式来逐步逼近全局最优,每一步优化的损失函数:
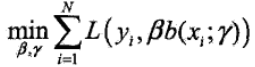
具体算法流程如下:
1)初始化$f_0(x) = 0$;
2)第m次迭代时,极小化损失函数
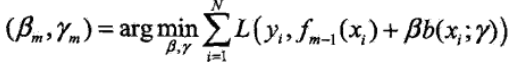
3)更新模型,则$f_m (x)$:

4)得到最终的加法模型
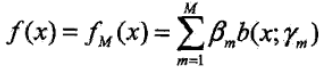
Adaboost算法也可以用前向分布算法来描述,在这里输入的数据集是带有权重分布的数据集,损失函数是指数损失函数。
2、GBDT算法
GBDT是梯度提升决策树(Gradient Boosting Decision Tree)的简称,GBDT可以说是最好的机器学习算法之一。GBDT分类和回归时的基学习器都是CART回归树,因为是拟合残差的。GBDT和Adaboost一样可以用前向分布算法来描述,不同之处在于Adaboost算法每次拟合基学习器时,输入的样本数据是不一样的(每一轮迭代时的样本权重不一致),因为Adaboost旨在重点关注上一轮分类错误的样本,GBDT算法在每一步迭代时是输出的值不一样,本轮要拟合的输出值是之前的加法模型的预测值和真实值的差值(模型的残差,也称为损失)。用于一个简单的例子来说明GBDT,假如某人的年龄为30岁,第一次用20岁去拟合,发现损失还有10岁,第二次用6岁去拟合10岁,发现损失还有4岁,第三次用3岁去拟合4岁,依次下去直到损失在我们可接受范围内。
以平方误差损失函数的回归问题为例,来看看以损失来拟合是个什么样子,采用前向分布算法:
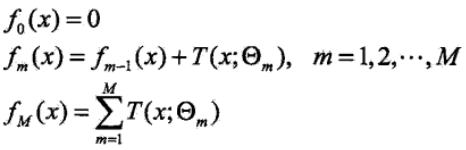
在第$m$次迭代时,我们要优化的损失函数:
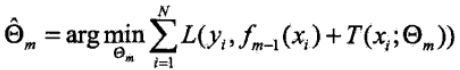
此时我们采用平方误差损失函数为例:
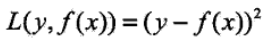
则上面损失函数变为:
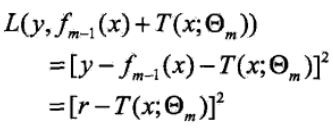
问题就成了对残差r的拟合了
然而对于大多数损失函数,却没那么容易直接获得模型的残差,针对该问题,大神Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值,拟合一个回归树
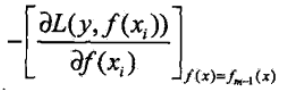
关于GBDT一般损失函数的具体算法流程如下:
1)初始化$f_0(x)$:
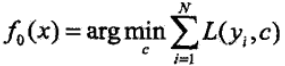
2)第$m$次迭代时,计算当前要拟合的残差$r_{mi}$:

以$r_{mi}$为输出值,对$r_{mi}$拟合一个回归树(此时只是确定了树的结构,但是还未确定叶子节点中的输出值),然后通过最小化当前的损失函数,并求得每个叶子节点中的输出值$c_{mj}$,$j$表示第$j$个叶子节点

更新当前的模型$f_m(x)$为:
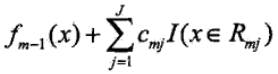
3)依次迭代到我们设定的基学习器的个数$M$,得到最终的模型,其中$M$表示基学习器的个数,$J$表示叶子节点的个数
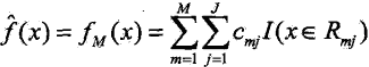
GBDT算法提供了众多的可选择的损失函数,通过选择不同的损失函数可以用来处理分类、回归问题,比如用对数似然损失函数就可以处理分类问题。大概的总结下常用的损失函数:
1)对于分类问题可以选用指数损失函数、对数损失函数。
2)对于回归问题可以选用均方差损失函数、绝对损失函数。
3)另外还有huber损失函数和分位数损失函数,也是用于回归问题,可以增加回归问题的健壮性,可以减少异常点对损失函数的影响。
3、GBDT的正则化
在Adaboost中我们会对每个模型乘上一个弱化系数(正则化系数),减小每个模型对提升的贡献(注意:这个系数和模型的权重不一样,是在权重上又乘以一个0,1之间的小数),在GBDT中我们采用同样的策略,对于每个模型乘以一个系数λ (0 < λ ≤ 1),降低每个模型对拟合损失的贡献,这种方法也意味着我们需要更多的基学习器。
第二种是每次通过按比例(推荐[0.5, 0.8] 之间)随机抽取部分样本来训练模型,这种方法有点类似Bagging,可以减小方差,但同样会增加模型的偏差,可采用交叉验证选取,这种方式称为子采样。采用子采样的GBDT有时也称为随机梯度提升树(SGBT)。
第三种就是控制基学习器CART树的复杂度,可以采用剪枝正则化。
4、GBDT的优缺点
GBDT的主要优点:
1)可以灵活的处理各种类型的数据
2)预测的准确率高
3)使用了一些健壮的损失函数,如huber,可以很好的处理异常值
GBDT的缺点:
1)由于基学习器之间的依赖关系,难以并行化处理,不过可以通过子采样的SGBT来实现部分并行。
5、XGBoost算法
事实上对于树模型为基学习器的集成方法在建模过程中可以分为两个步骤:一是确定树模型的结构,二是确定树模型的叶子节点中的输出值。
5.1 定义树的复杂度
首先把树拆分成结构部分$q$和叶子节点输出值$w$,在这里$w$是一个向量,表示各叶子节点中的输出值。在这里就囊括了上面提到的两点,确定树结构$q$和叶子结点的输出值$w$。从下图中可以看出,$q(x)$实际上是确定输入值最终会落到哪个叶子节点上,而$w$将会给出相应的输出值。
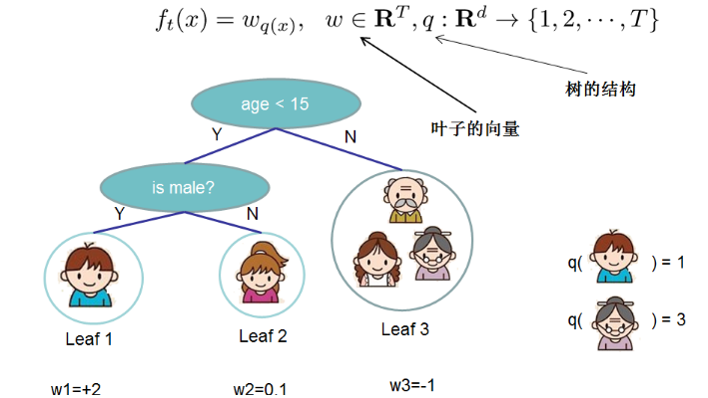
具体表现示例如下,引入正则化项 $\Omega (f_t)$来控制树的复杂度,从而实现有效的控制模型的过拟合,这是xgboost中的第一个重要点。式子中的$T$为叶子节点数

5.2 XGBoost中的Boosting Tree模型

和GBDT方法一样,XGBoost的提升模型也是采用残差,不同的是分裂结点选取的时候不一定是最小平方损失,其损失函数如下,较GBDT其根据树模型的复杂度加入了一项正则化项:
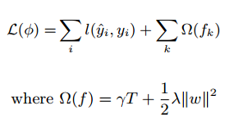
5.3 对目标函数进行改写

上面的式子是通过泰勒展开式将损失函数展开为具有二阶导的平方函数。
在GBDT中我们通过求损失函数的负梯度(一阶导数),利用负梯度替代残差来拟合树模型。在XGBoost中直接用泰勒展开式将损失函数展开成二项式函数(前提是损失函数一阶、二阶都连续可导,而且在这里计算一阶导和二阶导时可以并行计算),假设此时我们定义好了树的结构(在后面介绍,和GBDT中直接用残差拟合不同),假设我们的叶节点区域为:
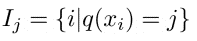
上面式子中$i$代表样本$i$,$j$代表叶子节点$j$。
则我们的目标优化函数可以转换成(因为$l(y_i, y_i^{t-1})$是个已经确定的常数,可以舍去):
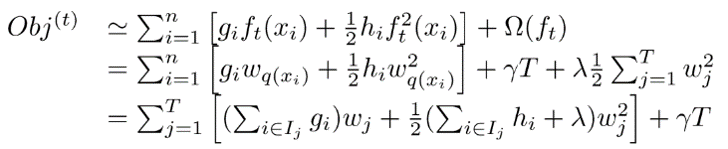
上面式子把样本都合并到叶子节点中了。
此时我们对$w_j$求导并令导数为0,可得:
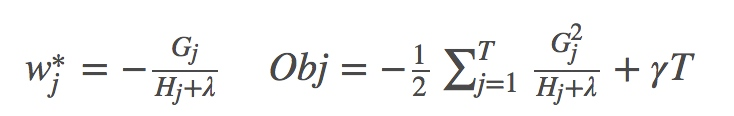
其中 $ G_j = \sum_{i \in I_j} g_i, H_j = \sum_{i \in T_j} h_j $。
5.4 树结构的打分函数
上面的Obj值代表当指定一个树结构时,在目标上面最多减少多少,我们可以把它称为结构分数。可以认为这是一个类似与基尼指数一样更一般的对树结构进行打分的函数。如下面的例子所示
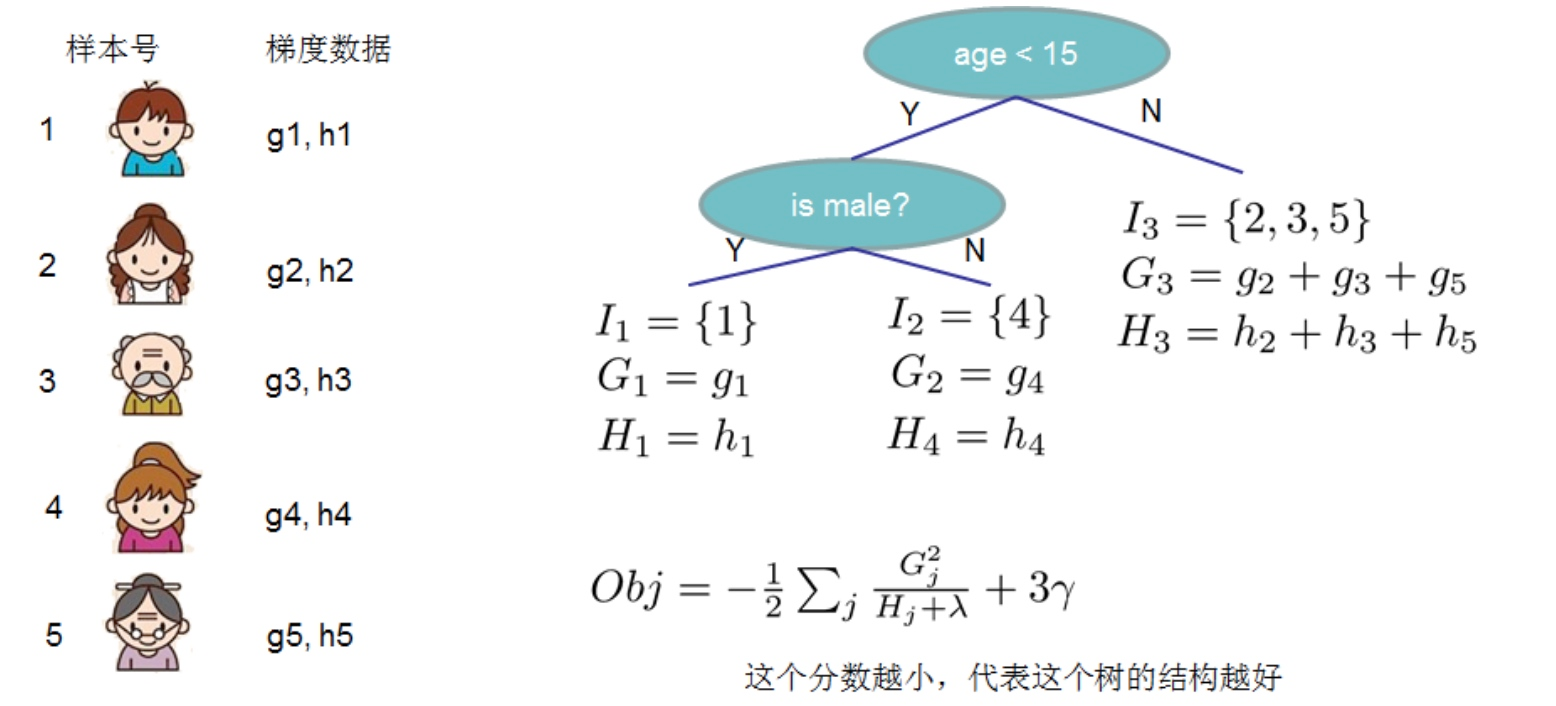
对于求得Obj分数最小的树结构,我们可以枚举所有的可能性,然后对比结构分数来获得最优的树结构,然而这种方法计算消耗太大,更常用的是贪心法(事实上绝大多数树模型都是这样的,只考虑当前节点的划分最优),每次尝试对已经存在的叶节点(最开始的叶节点是根节点)进行分割,然后获得分割后的增益为:
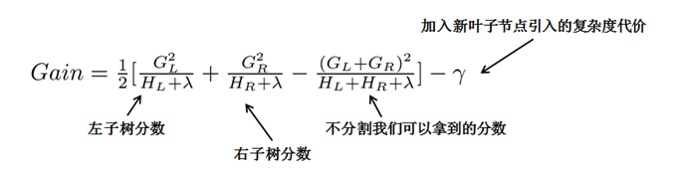
在这里以$Gain$作为判断是否分割的条件,这里的$Gain$可以看作是未分割前的Obj减去分割后的左右Obj,因此如果$Gain < 0$,则此叶节点不做分割,然而这样对于每次分割还是需要列出所有的分割方案(对于特征的值的个数为n时,总共有2^n - 2 种划分)。而实际中是采用近似贪心方法,我们先将所有样本按照$g_i$从小到大排序,然后进行遍历,查看每个节点是否需要分割(对于特征的值的个数为$n$时,总共有$n-1$种划分),具体示例如下:

最简单的树结构就是一个节点的树。我们可以算出这棵单节点的树的好坏程度obj*。假设我们现在想按照年龄将这棵单节点树进行分叉,我们需要知道:
1)按照年龄分是否有效,也就是是否减少了obj的值
2)如果可分,那么以哪个年龄值来分。
此时我们就是先将年龄特征从小到大排好序,然后再从左到右遍历分割
这样的分割方式,我们就只要对样本扫描一遍,就可以分割出$G_L$,$G_R$,然后根据$Gain$的分数进行分割,极大地节省了时间。所以从这里看,XGBoost中从新定义了一个划分属性,也就是这里的$Gain$,而这个划分属性的计算是由其目标损失决定obj的。
5.5 XGBoost中其他的正则化方法
1)像Adaboost和GBDT中一样,对每一个模型乘以一个系数$\lambda(0 < \lambda ≤ 1)$,用来降低每个模型对结果的贡献。
2)采用特征子采样方法,和RandomForest中的特征子采样一样,可以降低模型的方差
6、XGBoost和GBDT的区别
1)将树模型的复杂度加入到正则项中,来避免过拟合,因此泛化性能会由于GBDT。
2)损失函数是用泰勒展开式展开的,同时用到了一阶导和二阶导,可以加快优化速度。
3)和GBDT只支持CART作为基分类器之外,还支持线性分类器,在使用线性分类器的时候可以使用L1,L2正则化。
4)引进了特征子采样,像RandomForest那样,这种方法既能降低过拟合,还能减少计算。
5)在寻找最佳分割点时,考虑到传统的贪心算法效率较低,实现了一种近似贪心算法,用来加速和减小内存消耗,除此之外还考虑了稀疏数据集和缺失值的处理,对于特征的值有缺失的样本,XGBoost依然能自动找到其要分裂的方向。
6)XGBoost支持并行处理,XGBoost的并行不是在模型上的并行,而是在特征上的并行,将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。这个block也使得并行化成为了可能,其次在进行节点分裂时,计算每个特征的增益,最终选择增益最大的那个特征去做分割,那么各个特征的增益计算就可以开多线程进行。
机器学习算法总结(四)——GBDT与XGBOOST的更多相关文章
- 机器学习(八)—GBDT 与 XGBOOST
RF.GBDT和XGBoost都属于集成学习(Ensemble Learning),集成学习的目的是通过结合多个基学习器的预测结果来改善单个学习器的泛化能力和鲁棒性. 根据个体学习器的生成方式,目前 ...
- 个性化排序算法实践(四)——GBDT+LR
本质上GBDT+LR是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题.这个方法出自于Facebook 2014年的论文 Practical Lessons from Predi ...
- Andrew Ng机器学习算法入门(四):阶梯下降算法
梯度降级算法简介 之前如果需要求出最佳的线性回归模型,就需要求出代价函数的最小值.在上一篇文章中,求解的问题比较简单,只有一个简单的参数.梯度降级算法就可以用来求出代价函数最小值. 梯度降级算法的在维 ...
- GB、GBDT、XGboost理解
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- 机器学习(四)--- 从gbdt到xgboost
gbdt(又称Gradient Boosted Decision Tree/Grdient Boosted Regression Tree),是一种迭代的决策树算法,该算法由多个决策树组成.它最早见于 ...
- 机器学习总结(一) Adaboost,GBDT和XGboost算法
一: 提升方法概述 提升方法是一种常用的统计学习方法,其实就是将多个弱学习器提升(boost)为一个强学习器的算法.其工作机制是通过一个弱学习算法,从初始训练集中训练出一个弱学习器,再根据弱学习器的表 ...
- 机器学习算法--GBDT
转自 http://blog.csdn.net/u014568921/article/details/49383379 另外一个很容易理解的文章 :http://www.jianshu.com/p/0 ...
- 机器学习算法GBDT的面试要点总结-上篇
1.简介 gbdt全称梯度下降树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩.原因大概有几个,一是效果确实挺不错.二是 ...
- 机器学习算法GBDT
http://www-personal.umich.edu/~jizhu/jizhu/wuke/Friedman-AoS01.pdf https://www.cnblogs.com/bentuwuyi ...
随机推荐
- MyBatis:自定义Mapper
在开发中有时可能需要我们自己自定义一些mapper还有些一些自定义的xml,SQL语句.其实在我们的框架中很方便.只需要在mapper中添加自定义接口,在resources中自定义一个mapper的x ...
- 汇编语言--微机CPU的指令系统(五)(转移指令)
(9)转移指令 转移指令是汇编语言程序员经常使用的一组指令.在高级语言中,时常有“尽量不要使用转移语句”的劝告,但如果在汇编语言的程序中也尽量不用转移语句,那么该程序要么无法编写,要么没有多少功能,所 ...
- java 反射模式
反射模式优化工厂类大量switch分支问题 继续上一篇工厂模式的案例,上一篇只有两个算法类(加法和减法),现在再加一个乘法 第一步: //运算类 public class Operation { pr ...
- blfs(systemd版本)学习笔记-编译安装gnome桌面组件及应用
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! blfs中的gnome项目地址:http://www.linuxfromscratch.org/blfs/view/stable ...
- 折半插入排序算法的C++实现
折半插入排序思想和直接插入排序类似. 1)找到插入位置: 2)依次后移正确位置及后面的元素. 区别是查找插入位置的方法不同. 折半插入排序使用的折半查找法在一个已经有序的序列中找到查找位置. 注意,折 ...
- Android项目实战(四十一):游戏和视频类型应用 状态栏沉浸式效果
需求: 手机app ,当打游戏或者全屏看视频的时候会发现这时候手机顶部的状态栏是不显示的,当我们从手机顶端向下进行滑动或手机底端向上滑动的时候,状态栏会显示出来,如果短暂的几秒时间没有操作的话,状态 ...
- C程序
/* 不适用C库函数,只是用 C 语言实现函数 void* memcpy( void *dst, const void *src, size_t len ) memmove 函数的功能是拷贝 src ...
- [Python][小知识][NO.4] wxPython 字体选择对话框(O.O 不知道放到那里就放到这个分类的)
1.前言 O.O 前两天回家浪了两天,断更了 哎~~~ o.o 有时候,有木有想改标签或编辑框中内容的字体呀?(o.o 反正我是没有). wxpython也可以说是所在的操作系统,有字体选择器,给我们 ...
- mac上Docker安装&初体验
Docker是什么? Docker是一个虚拟环境容器,可以将你的开发环境.代码.配置文件等一并打包到这个容器中,并发布和应用到任意平台中. 官方文档:https://docs.docker.com H ...
- 批量修改所有服务器的dbmail配置
最近遇到这样一个案例,需要修改所有SQL Server的Database Mail的SMTP,原来的SMTP为10.xxx.xxx.xxx, 现在需要修改为192.168.xxx.xxx, 另外需要规 ...