Storm安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上
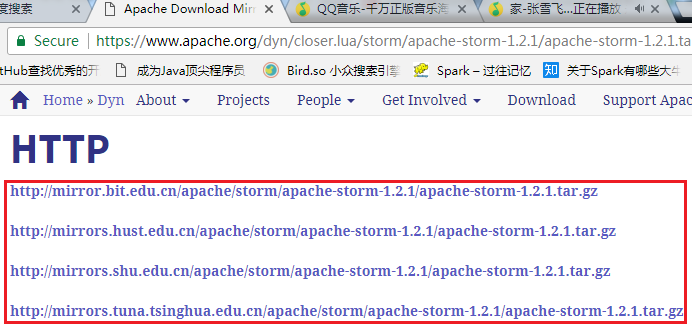
下载apache-storm-1.2.1.tar.gz 版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads/目录:
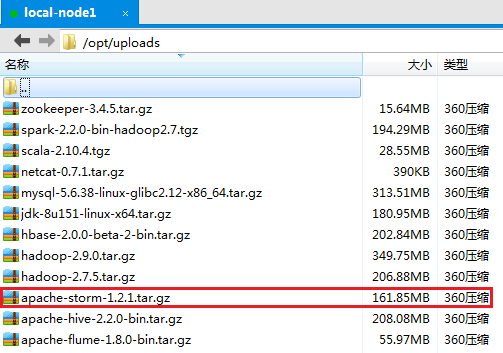
2、解压apache-storm-1.2.1.tar.gz,并把解压的安装包移动到/opt/app/目录上
tar zxvf apache-storm-1.2.1.tar.gz


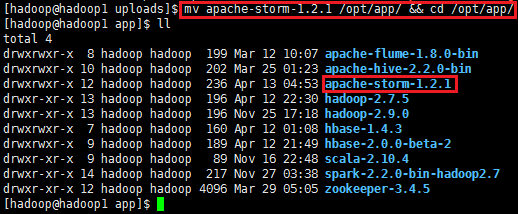
mv apache-storm-1.2.1 /opt/app/ && cd /opt/app/
3、修改环境变量(每台机器都要执行),编辑/etc/profile,并生效环境变量,输入如下命令:
sudo vi /etc/profile
添加如下内容:
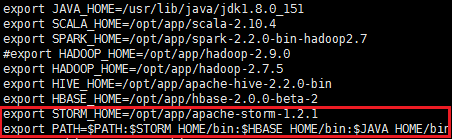
export STORM_HOME=/opt/app/apache-storm-1.2.1
export PATH=:$PATH:$STORM_HOME/bin
使环境变量生效:source /etc/profile
4、zookeeper集群搭建
①下载解压zookeeper:http://zookeeper.apache.org/releases.html
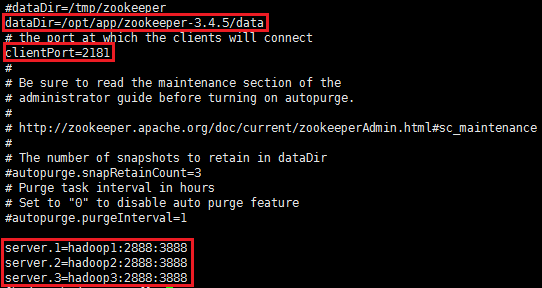
②修改zookeeper的conf/zoo.cfg文件,增加如下内容:
dataDir=/opt/app/zookeeper-3.4.5/data
clientPort=2181
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
③启动zookeeper集群
在每台机器上通过zookeeper的bin/zkServer.sh start启动zk,zookeeper会自动组件集群。
6、修改配置文件storm.yaml
进入storm配置文件的目录,cd /opt/app/apache-storm-1.2.1/conf/
修改storm.yaml文件 vi storm.yaml,将以下内容写入到storm.yaml文件中
# zookeeper集群的hosts
storm.zookeeper.servers:
- "hadoop1"
- "hadoop2"
- "hadoop3"
# 指定zookeeper的端口
storm.zookeeper.port: 2181
# storm存储的数据目录
storm.local.dir: "/opt/app/apache-storm-1.2.1/storm-local"
# 指定storm集群中的nimbus节点所在的服务器
nimbus.seeds: ["hadoop1"]
# 指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
# 指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx768m"
# 指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上
ui.childopts: "-Xmx768m"
# 指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
storm.health.check.dir: "healthchecks"
storm.health.check.timeout.ms: 5000
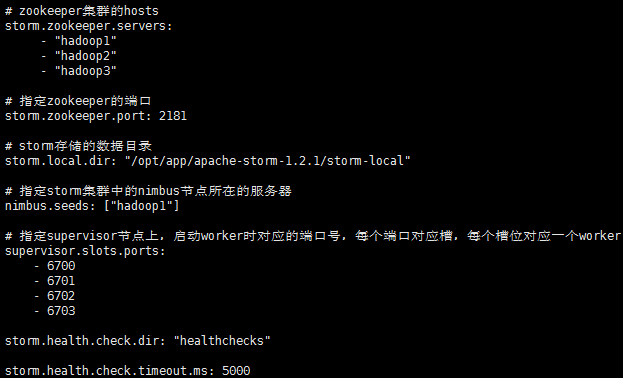
其中storm.local.dir指定的目录需要提前创建,supervisor.slots.ports配置的端口数量决定了每台supervisor机器的worker集群,每个worker会有自己的监听端口用于监听任务。
7、把storm的安装包发送到其他节点机器
scp -r /opt/app/apache-storm-1.2.1/ hadoop@hadoop2:/opt/app/
scp -r /opt/app/apache-storm-1.2.1/ hadoop@hadoop3:/opt/app/
8、启动storm
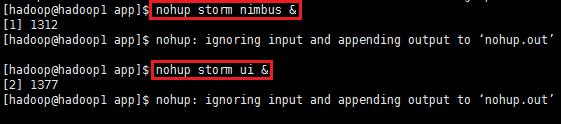
在hadoop1节点机器上启动nimbus和监控ui
nohup storm nimbus &
nohup storm ui &
在hadoop2和hadoop3节点机器上启动supervisor作为worker
nohup storm supervisor &

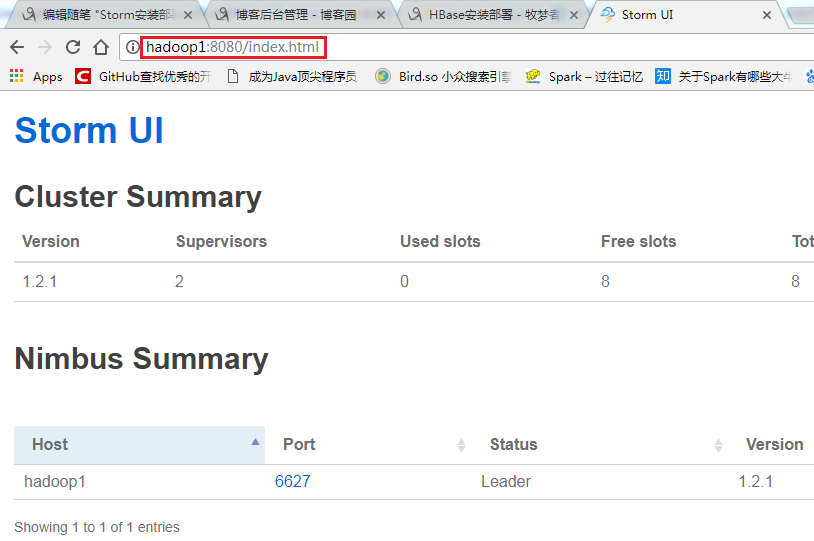
9、环境确认
通过浏览器访问ui监控界面,“storm ui”命令运行的机器ip + 默认8080端口,如图:
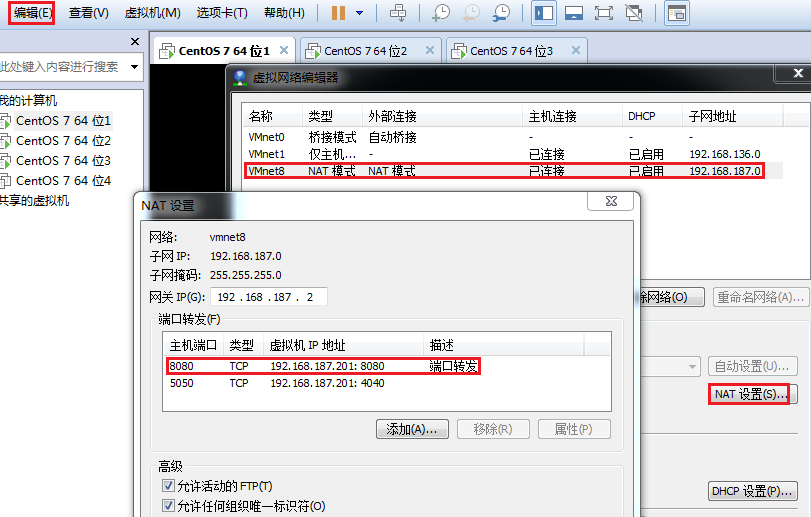
前提条件:三台机器集群是部署在VMware 12上面的,通过NAT网络通信,如果需要访问虚拟机的8080端口,需要在VMware12上面设置端口转发,如图:
至此,storm集群搭建完成,主要工作为:①zookeeper的安装配置;②storm中配置zookeeper的地址;③分别启动storm的nimbus和supervisor及监控ui。
参考资料:
https://blog.csdn.net/qingkangxu/article/details/79513697
http://storm.apache.org/releases/1.2.1/Setting-up-a-Storm-cluster.html
Storm安装部署的更多相关文章
- 【Storm一】Storm安装部署
storm安装部署 解压storm安装包 $ tar -zxvf apache-storm-1.1.0.tar.gz -C /usr/local/src 修改解压后的apache-storm-1.1. ...
- Storm 安装部署
环境要求JDK 1.6+java -versionPython 2.6.6+python -V ZooKeeper3.4.5+storm 0.9.4+ 单机模式上传解压 $ .tar.gz $ cd ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- Storm集群安装部署步骤
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以"注意事项"的形式给出. 1. Sto ...
- storm集群安装部署
安装步骤: 搭建Zookeeper集群: 安装Storm依赖库: 下载并解压Storm发布版本: 修改storm.yaml配置文件: 启动Storm各个后台进程. 1. 搭建Zookeeper集群 这 ...
- Storm-0.9.0.1安装部署 指导
可以带着下面问题来阅读本文章: 1.Storm只支持什么传输 2.通过什么配置,可以更改Zookeeper默认端口 3.Storm UI必须和Storm Nimbus部署在同一台机器上,UI无法正常工 ...
- Storm介绍及安装部署
本节内容: Apache Storm是什么 Apache Storm核心概念 Storm原理架构 Storm集群安装部署 启动storm ui.Nimbus和Supervisor 一.Apache S ...
- twitter storm学习 - 安装部署问题汇总
已经碰到的或者将来碰到的关于安装部署方面的问题以及解决方法,先挖个坑 1.提交的topology在admin界面上看emitted始终都是0,查看日志发现有如下错误: worker [ERROR] E ...
随机推荐
- Gogs 部署安装(windows)
Gogs简介 Gogs 是一款类似GitHub的开源文件/代码管理系统(基于Git),Gogs 的目标是打造一个最简单.最快速和最轻松的方式搭建自助 Git 服务.使用 Go 语言开发使得 Gogs ...
- BZOJ 2521: [Shoi2010]最小生成树(最小割)
题意 对于某一条无向图中的指定边 \((a, b)\) , 求出至少需要多少次操作.可以保证 \((a, b)\) 边在这个无向图的最小生成树中. 一次操作指: 先选择一条图中的边 \((u, v)\ ...
- 反射中Class.forName()和classLoader的区别
搞清楚两者之间区别前,我们来了解下类加载过程. 一.类加载过程 1.加载 通过一个类的全限定名来获取定义此类的二进制字节流. 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构. 在内存中生 ...
- Luogu P5316 【恋恋的数学题】
是个神仙题 就三种情况,分类讨论. \(k=2\): 因为保证有解,所以直接输出即可. \(k=3\): 由于对应情况可以枚举全排列寻找,所以在此只考虑顺序对应时的情况,不妨设六个数分别为\(g_{a ...
- Luogu P5290 / LOJ3052 【[十二省联考2019]春节十二响】
联考Day2T2...多亏有这题...让我水了85精准翻盘进了A队... 题目大意: 挺简单的就不说了吧...(这怎么简述啊) 题目思路: 看到题的时候想了半天,不知道怎么搞.把样例画到演草纸上之后又 ...
- 51nod 1443 路径和树(最短路树)
题目链接:路径和树 题意:给定无向带权连通图,求从u开始边权和最小的最短路树,输出最小边权和. 题解:构造出最短路树,把存留下来的边权全部加起来.(跑dijkstra的时候松弛加上$ < $变成 ...
- POJ--1797 Heavy Transportation (最短路)
题目电波: POJ--1797 Heavy Transportation n点m条边, 求1到n最短边最大的路径的最短边长度 改进dijikstra,dist[i]数组保存源点到i点的最短边最大的路径 ...
- echarts x轴文字显示不全解决办法
标题:echarts x轴文字显示不全(xAxis文字倾斜比较全面的3种做法值得推荐):http://blog.csdn.net/kebi007/article/details/68488694
- HDU 1560 DNA sequence (迭代加深搜索)
The twenty-first century is a biology-technology developing century. We know that a gene is made of ...
- Elastic 基础篇(2)
1.基本概念 1)Elastic和RDMS对比 RDMS Elastic 数据库database 索引index 表table 类型type 行row 文档document 列column 字段fie ...