Python 爬虫五 进阶案例-web微信登陆与消息发送
首先回顾下网页微信登陆的一般流程
1、打开浏览器输入网址
2、使用手机微信扫码登陆
3、进入用户界面
1、打开浏览器输入网址
首先打开浏览器输入web微信网址,并进行监控:
https://wx.qq.com/
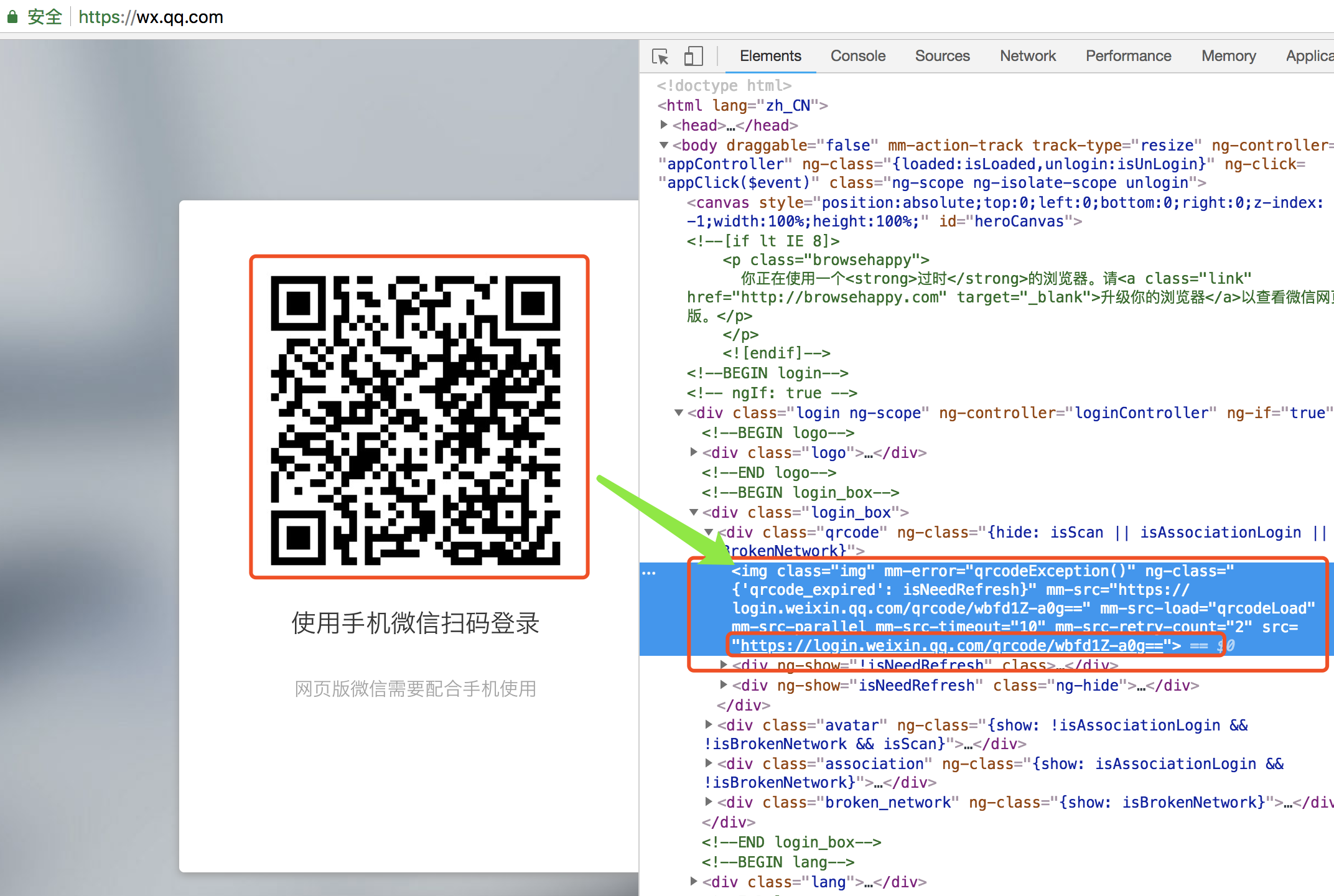
可以发现网页中包含了一个新的url,而这个url就是二维码的来源。
https://login.weixin.qq.com/qrcode/wbfd1Z-a0g==
可以猜测一下获取url的一般网址就是https://login.weixin.qq.com/qrcode,而wbfd1Z-a0g==肯定就是通过请求前面的url后传入的参数,最终生成二维码图片。
此时再监控此次请求的network,去寻找,究竟是什么时候返回给客户端wbfd1Z-a0g==字符串的。

最终在网址:https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_=1532592134738的response里面找到了二维码参数。
这个网址里面_=1532592134738里面传入的看着像一个时间戳。此时我们先新建一个Django项目,在login页面向上面的网址发送请求。取得二维码参数,再传给前台的img标签,就可以做出二维码登陆页面。
新建一个Django项目、并新建一个app wechat:
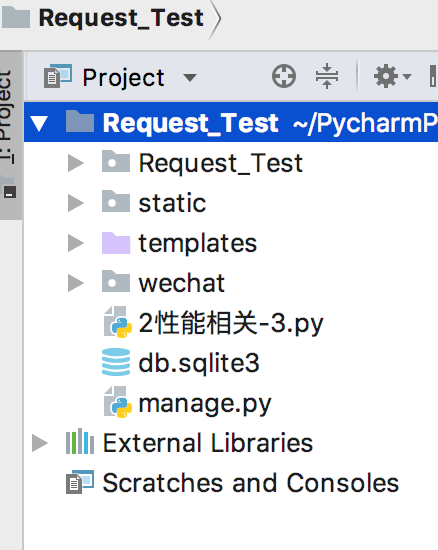
将主url路由指向wechat app里面的url, 并写好一个login url,让用户从我们这边开始登陆微信。
wechat urls:
views内的login函数:
from django.shortcuts import render, HttpResponse, redirect
import requests, time
import re, json
from bs4 import BeautifulSoup
# Create your views here. def login(req):
ctime = time.time() * 1000 # 模拟一个相同的时间戳
base_url = 'https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_={0}'
url = base_url.format(ctime) # 字符串拼接,生成新的url
response = requests.get(url) # 向新的url发送get请求
xcode_list = re.findall('window.QRLogin.uuid = "(.*)";', response.text) # 通过正则表达式,提取到对于的参数列表['YZzTdz9m_A==', 'YZzTdz9m_A==']
req.session['xcode'] = xcode_list[0] # 获取到参数,存入session内
return render(req, 'wechat/login.html', {'xcode': xcode_list[0]}) # 返回给login页面此参数
在templates目录里面创建一个wechat目录,在wechat目录创建一个login.html页面,传入参数。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img id="xcode" style="width: 200px; height: 200px; margin:100px 40%" src="https://login.weixin.qq.com/qrcode/{{ xcode }}">
</body>
</html>
因为加入了session功能需要先run一下
python3 manage.py makemigrations
python3 mange.py migrate
运行并访问login:

此时,就完成第一个二维码页面了。
第二步,有了二维码,手机扫描是如何进行交互的?是不是这个网页有个后台一直在请求某个网页,一旦扫码验证就进行下一步操作?继续监控请求
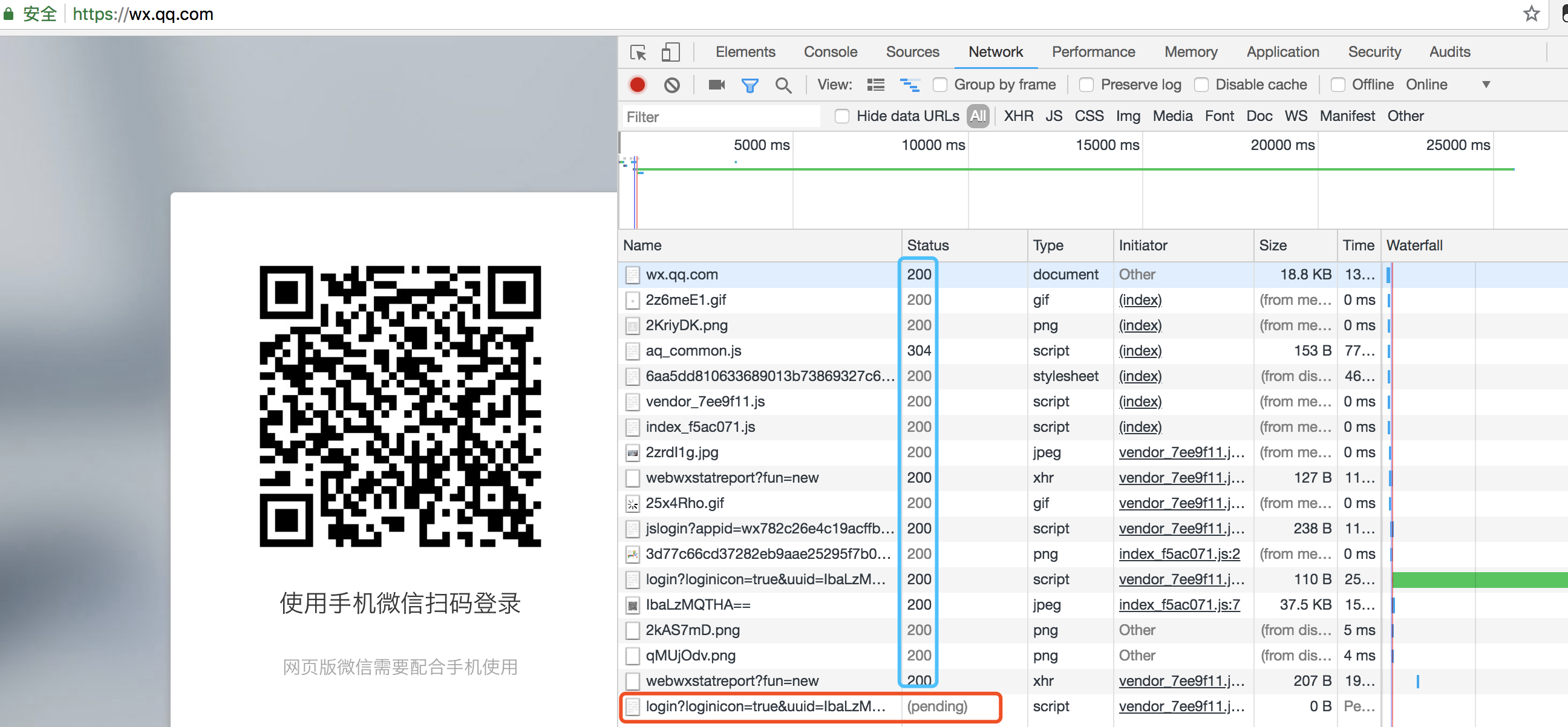
思路渐渐清晰了,在请求登陆的时候大概是如下的流程:


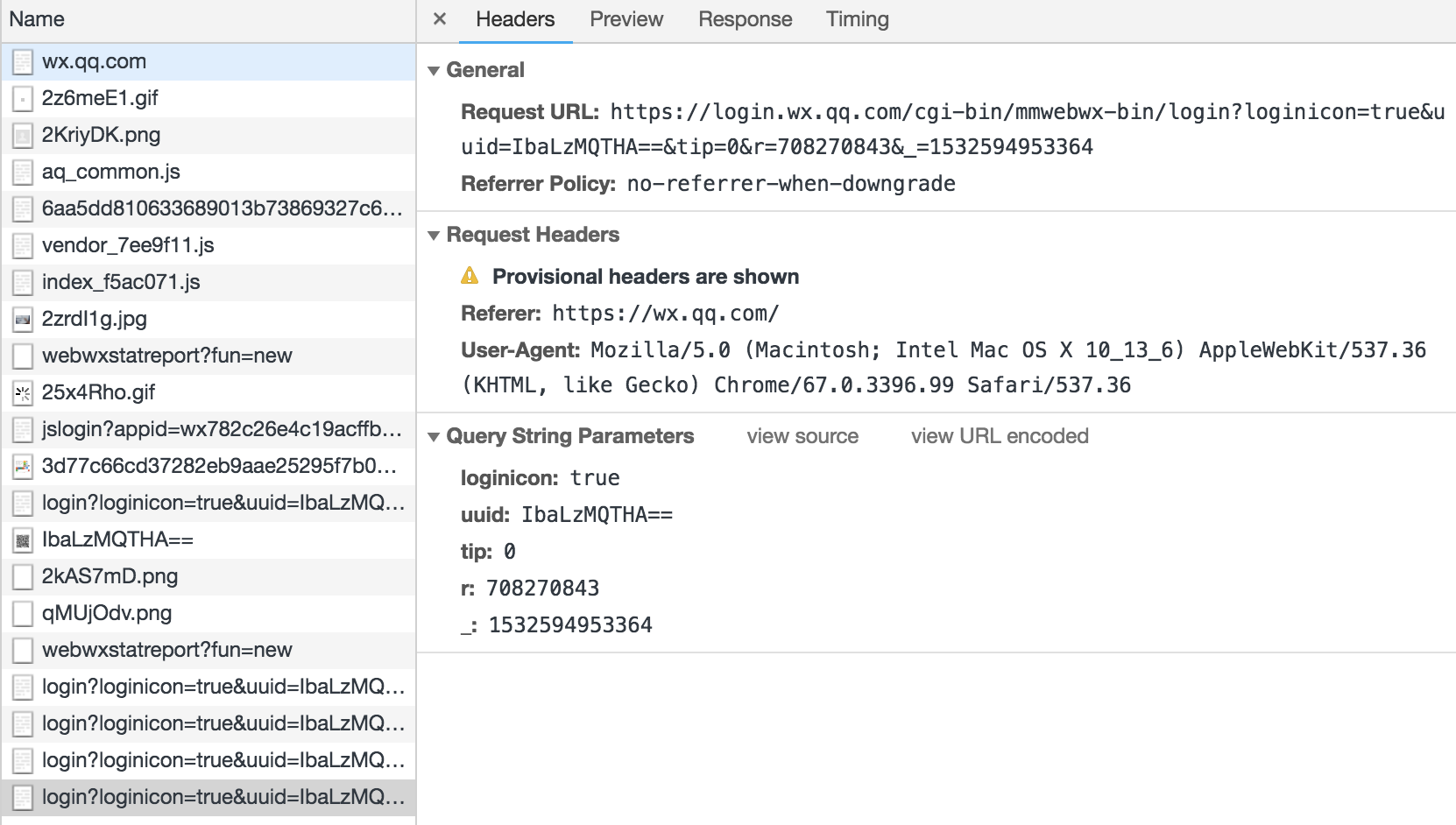
打开一个失效的url:
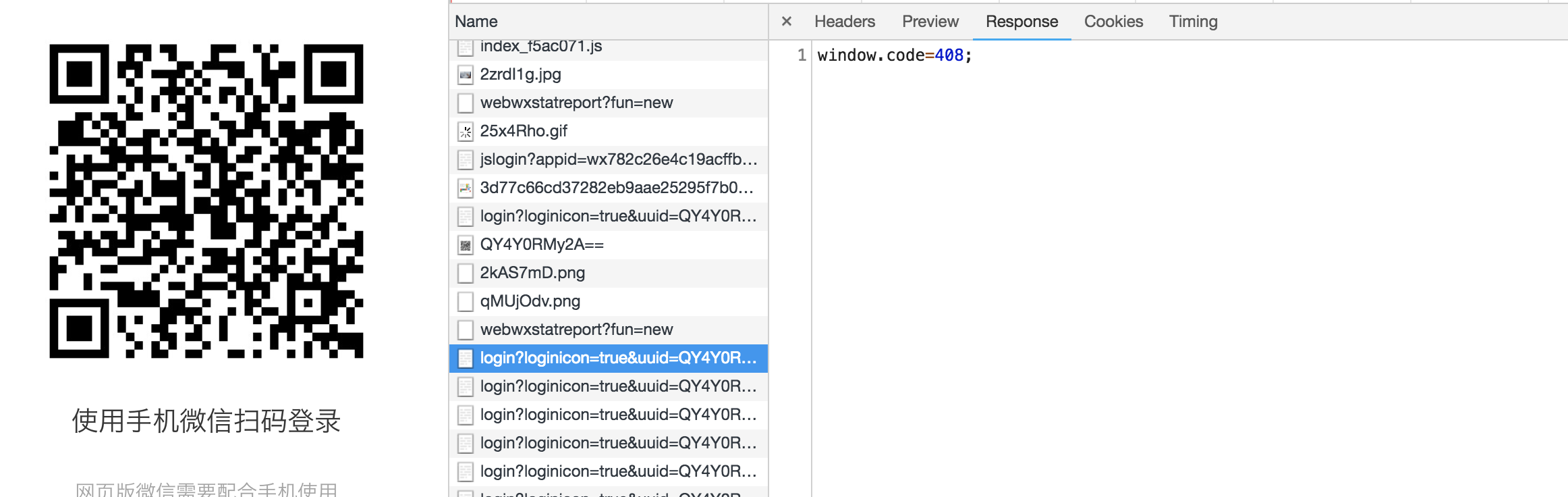
再查看扫描完的URL的返回:
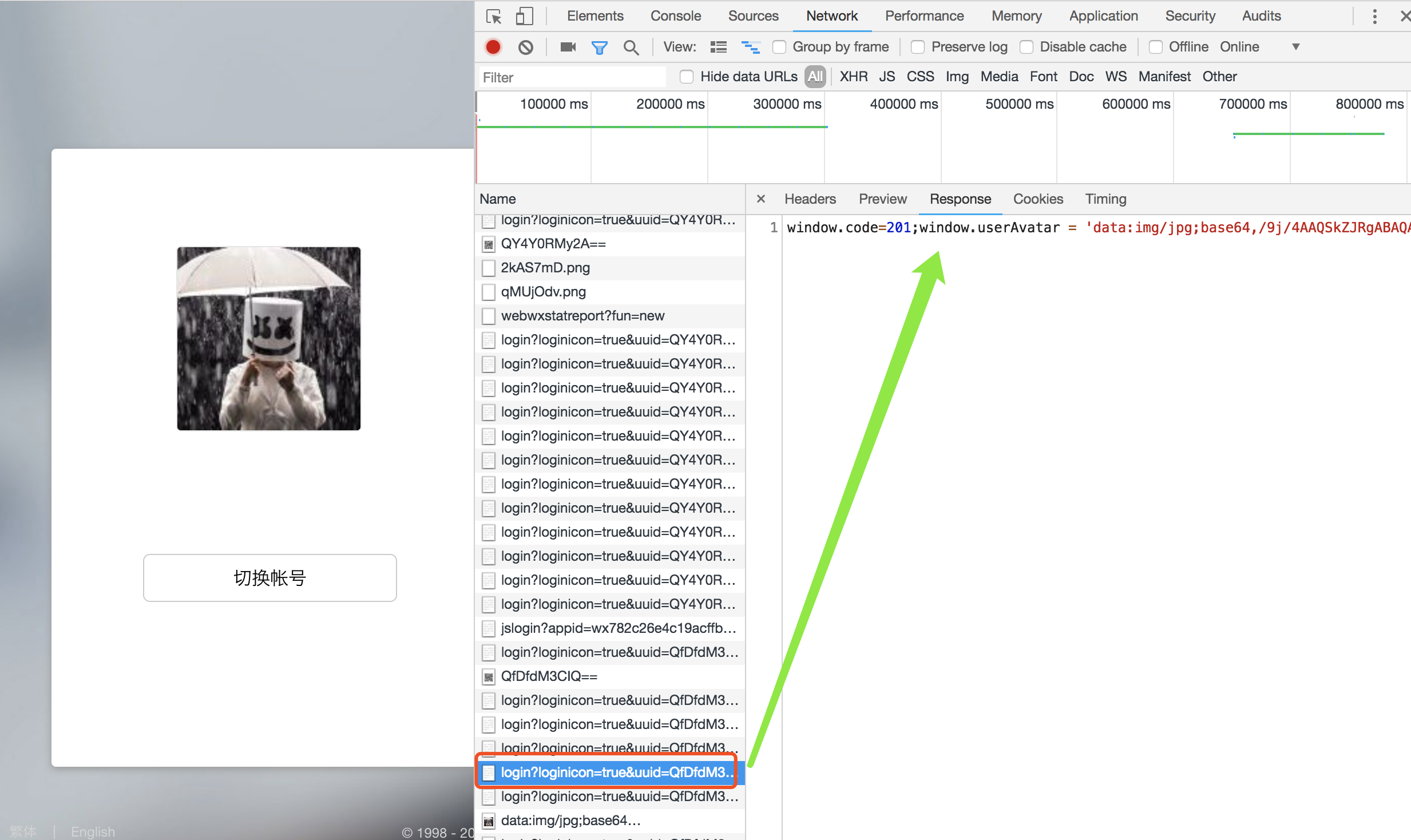
最后确认登陆:

再次观察,会发现这个url其实是一个长轮询,一直在请求认证结果。pending的是在等待的当前请求。而在我们的项目内部,因为浏览器存在一个同源策略,所以无法完成在前端直接获取结果。此时改变一下思路:可以通过login内部写个url 偷偷的访问后端的视图,视图层再通过requests模块去发送请求获取结果返回给前端。
另外关于url的三种返回:
1、408代表没有人扫码(需要重新发送)
2、201代表已经有用户扫码,后面的参数返回的是用户头像
3、200代表用户已经登陆
定义一下检查的url:
path('check_login/', views.check_login),
login.html页面加入javascript
<script src="/static/jquery.min.js"></script>
<script>
tip = 1
function checkLogin() {
$.ajax({
url:'/wechat/check_login/',
data: {'tip': tip},
type: 'GET',
dataType: 'JSON',
success:function (arg) {
if (arg.code == 201){
// 有人扫码了
$('#xcode').attr('src', arg.data);
checkLogin();
tip = 0;
}else if (arg.code == 408){
checkLogin();
}else if (arg.code == 200){
window.location.href='/wechat/index/'
}
}
})
}
checkLogin();
</script>
这边需要提醒的是当用户扫码之后的url发送的参数中有一个tip参数有变动,从1变成0.
def check_login(req):
tip = req.GET.get('tip') # 标记是否扫码
# 自定义返回的json数据格式
ret = {
'code': 408, # 初始值408代表没有任何操作
'data': None
}
ctime = time.time() * 1000 # 根据得到的url,伪造匹配的时间戳
base_url = 'https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid={0}&tip={1}&r=903313058&_={2}'
url1 = base_url.format(req.session['xcode'], tip, ctime) # 字符串修饰
r1 = requests.get(url1) # 获取响应
if 'window.code=201' in r1.text:
# 有人扫码
v = re.findall("window.userAvatar = '(.*)';", r1.text)
avatar = v[0]
ret['code'] = 201 # 状态码,代表有人扫码了
ret['data'] = avatar # 用户头像
elif 'window.code=200;' in r1.text:
# 扫码之后,点击确定登录
req.session['login_cookie'] = r1.cookies.get_dict() # 获取确认登陆的cookie
uri = re.findall('window.redirect_uri="(.*)";', r1.text) # 之前的图片,已经发现这里是一个重定向路由,所以获取重定向的路由
# https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxnewloginpage?ticket=AfpJ_ZmEJGcJ8iU62SiPyuTo@qrticket_0&uuid=gZHgYImvDQ==&lang=zh_CN&scan=1532410951
redirect_url = '{0}&fun=new&version=v2'.format(uri[0]) # 字符串拼接,形成新的url
# 获取凭证
r2 = requests.get(redirect_url) # 网页重定向的时候,会返回凭证用来进行之后的验证
ticket_dict = {}
soup = BeautifulSoup(r2.text, 'html.parser') # 标签文本实例化bs对象
for item in soup.find(name='error').children: # 找到需要的凭证
ticket_dict[item.name] = item.text # 凭证存入字典
req.session['ticket_dict'] = ticket_dict # 凭证存入session
req.session['ticket_cookie'] = r2.cookies.get_dict() # session中存入获取重定向的cookie
ret['code'] = 200 # 200表示确定登陆了
req.session['is_login'] = True # 给后面的url判断是否登陆
return HttpResponse(json.dumps(ret)) # Json序列化返回
最后创建一个新的路由:
path('index/', views.index),
创建一个新的html和视图函数index:
def index(req):
return render(req, 'wechat/index.html')
此时,便可以完成web微信登陆功能。
留一份确认登陆的凭证:
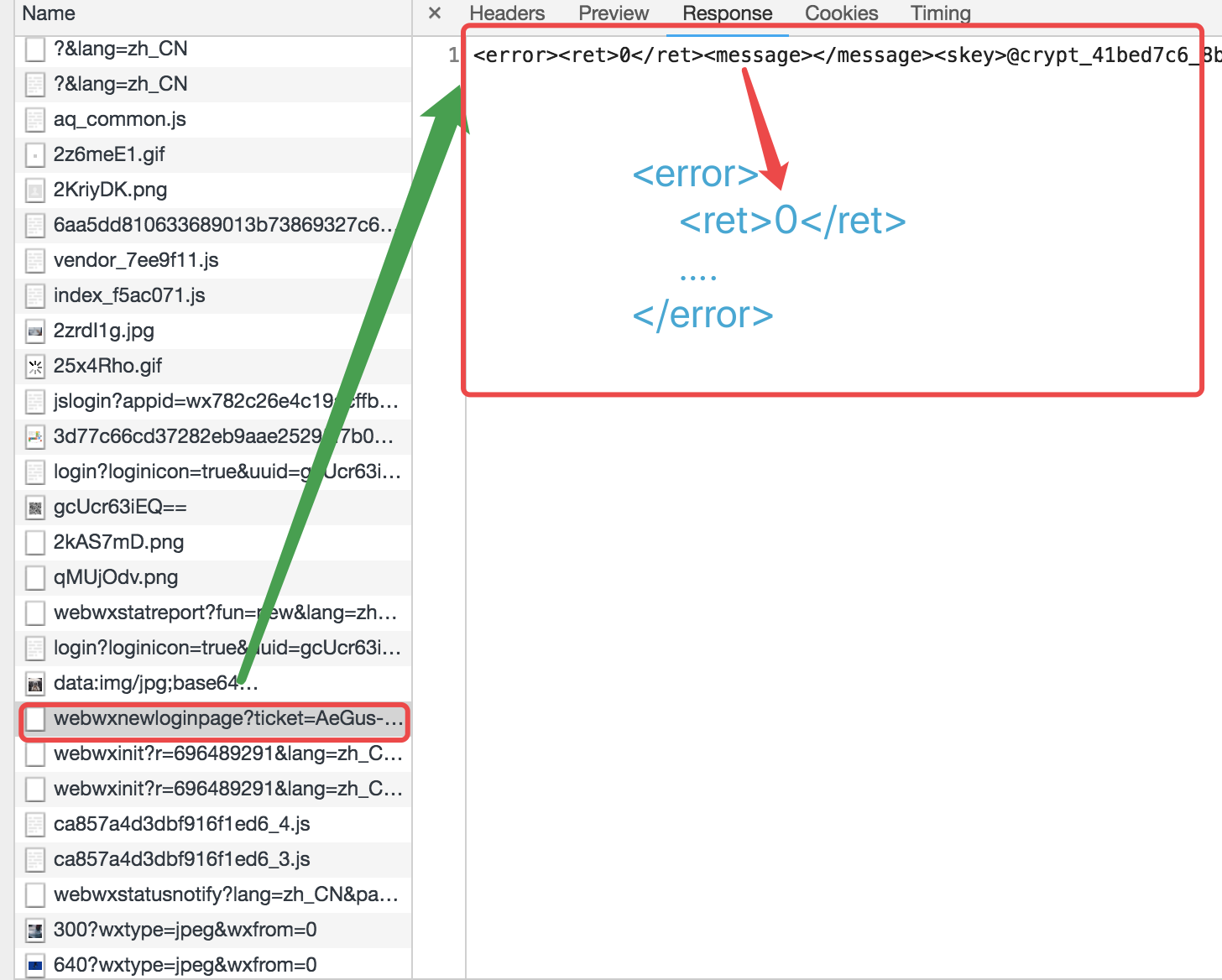
<error>
<ret>0</ret>
<message></message>
<skey>@crypt_41bad7c6_8bff0cc40ih18fba431b5a7e87l63bc7</skey>
<wxsid>LkgBf9UVGIkHdg80</wxsid>
<wxuin>15749213440</wxuin>
<pass_ticket>QvkUzyBHDWQ8HJDowkqw6rmqQ48weyrwDiNPTbn%2FnZl7tk%3D</pass_ticket>
<isgrayscale>1</isgrayscale>
</error>
获取登陆信息
根据平时登陆web wechat的常识,登陆确认之后肯定是跳往目的路由,初始化一些用户信息,获取用户的各种资料等等。这只是猜测怎么办?打开web 微信继续检测network。这一次从确认登陆完成进行截图分析。

url: https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=696489291&lang=zh_CN&pass_ticket=QvkUzyBiMqnrFcw6rmqQ4I7E2DiNxTUDPTbn%252FnZl7tk%253D
url里面有pass_ticket参数.
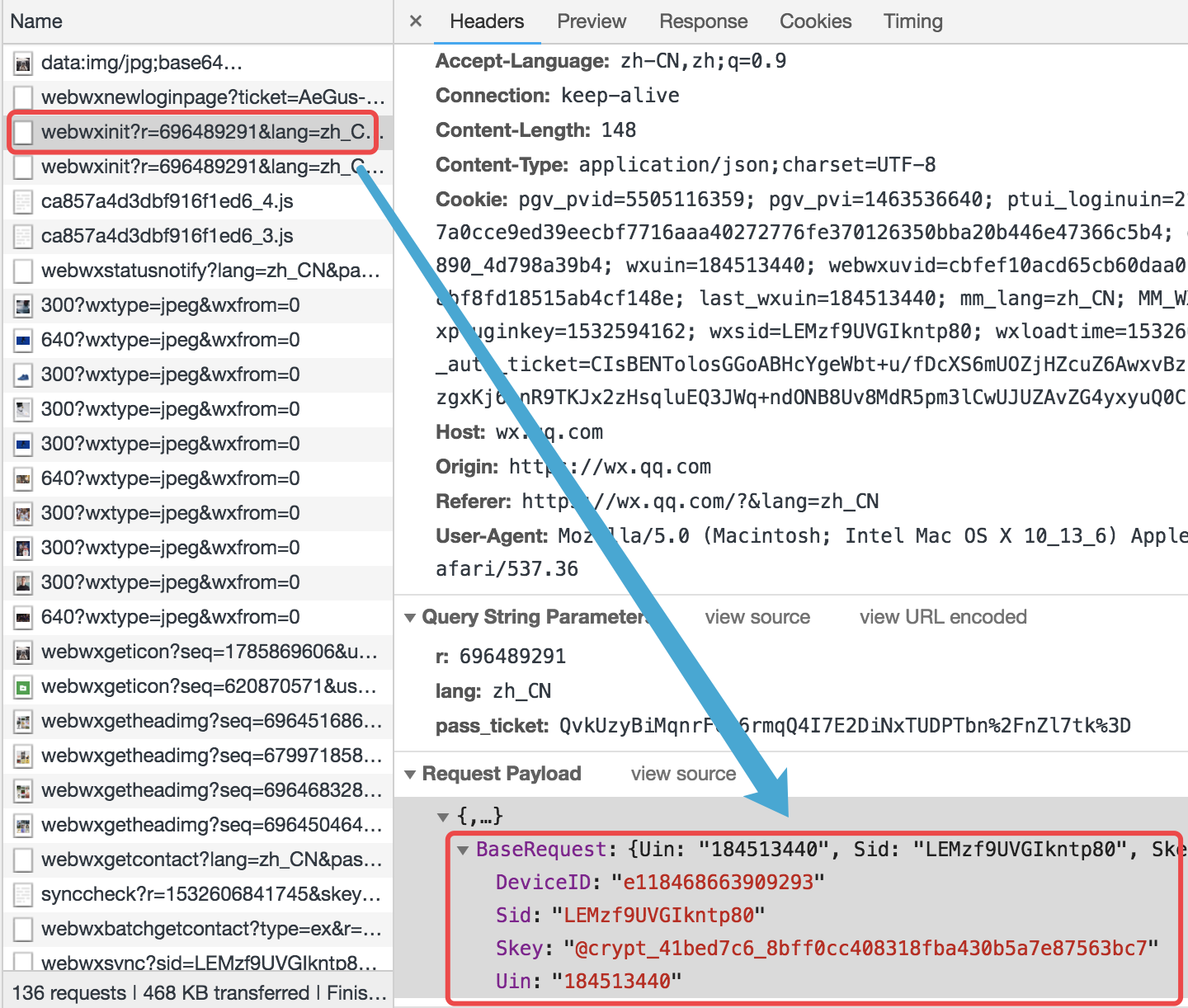
看到凭证组成的form_data,另外此次是POST请求。由于response数据太多了,在index里面我们先写一个for循环看看都有哪些key值,看看能不能根据key值的命名规范,找到规律。
视图函数index:
def index(req):
# 判断是否已经登陆
if not req.session.get('is_login'):
return redirect('/wechat/login/') # 发送post请求,根据ticket_dict进行构造数据
# https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=892259194&pass_ticket=TS7TEfumVaVzKhn%252FrnLKS2zZyhixJDEYxlXqGgQVplQ%253D
base_url = 'https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=892259194&pass_ticket={0}'
url = base_url.format(req.session['ticket_dict']['pass_ticket'])
# BaseRequest
# :
# {Uin: "184513440", Sid: "U4WojQwDRwKqdeMs", Skey: "", DeviceID: "e409571391728320"} # 伪造的数据格式样板 form_data = { # 伪造数据
'BaseRequest': {
'DeviceID': "e409571391728320",
'Sid': req.session['ticket_dict']['wxsid'],
'Skey': req.session['ticket_dict']['skey'],
'Uin': req.session['ticket_dict']['wxuin']
}
}
r1 = requests.post(
url=url,
json=form_data
)
r1.encoding = r1.apparent_encoding # 使用默认编码原则
user_info = json.loads(r1.content)
for key in user_info:
print(key)
return render(req, 'wechat/index.html', {"user_info": user_info})
结果:
BaseResponse
Count
ContactList
SyncKey
User
ChatSet
SKey
ClientVersion
SystemTime
GrayScale
InviteStartCount
MPSubscribeMsgCount
MPSubscribeMsgList
ClickReportInterval
可以猜测ContactList应该是最近联系人;User应该是用户本身,MPSubscribeMsgList应该是订阅号信息。
再打印一下User里面的key看一下,视图函数改一句就好了:
for key in user_info['User']:
print(key)
结果key:
Uin
UserName
NickName
HeadImgUrl
RemarkName
PYInitial
PYQuanPin
RemarkPYInitial
RemarkPYQuanPin
HideInputBarFlag
StarFriend
Sex
Signature
AppAccountFlag
VerifyFlag
ContactFlag
WebWxPluginSwitch
HeadImgFlag
SnsFlag
果然,现在这么看应该是登陆用户的信息了。
同理测试一下订阅号:
{
'UserName': '@8fbbad518f4d3cf22ebd0a1b0b6d2cb5',
'MPArticleCount': 4,
'MPArticleList': [
{
'Title': '80%的爱情还没开始就会终结。关于错过的遗憾,20 年前几米就教给你了',
'Digest': '你活得不开心,因为你太把自己当大人。',
'Cover': 'http://mmbiz.qpic.cn/mmbiz_jpg/ib0l8DHhOSLuh527WuVHWnnIXwxR5s37pgacZriaKQPUkKEqArKEa9v6tH8buhrNHZB3IMMgf33RCKxtziazCTPrQ/640?wxtype=jpeg&wxfrom=0',
'Url': 'http://mp.weixin.qq.com/s?__biz=MzIzMzk1MzE0NQ==&mid=2247485983&idx=1&sn=6e268e95cdaf04c21114b53f1285bba4&chksm=e8fc8809df8b011fba6a8092400b312102e247780168d56f69c6863e31e7c4f3945253b1f259&scene=0#rd'
},
{...}
],
'Time': 1532608404,
'NickName': '新世相读书会'
}
此时我们对index进行处理:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>个人信息:{{ user_info.User.NickName }}</h1>
<ul>
{% for user in user_info.ContactList %}
<li>{{ user.NickName }}</li>
{% endfor %}
</ul>
<a href="/wechat/contact_all/">查看更多联系人</a>
<h3>公众号信息</h3>
{% for msg in user_info.MPSubscribeMsgList %}
<div>
<h3>{{ msg.NickName }}</h3>
<ul>
{% for article in msg.MPArticleList %}
<li><a href="{{ article.Url }}">{{ article.Title }}</a></li>
{% endfor %}
</ul>
</div>
{% endfor %}
</body>
</html>
中间建立了一个新的url,用来显示所有联系人。先建立一个路由跟视图函数,其他暂时不管。
稍微修改了一下视图函数,加了个User字典到session里面,后面要用到:
def index(req):
# 判断是否已经登陆
if not req.session.get('is_login'):
return redirect('/wechat/login/') # 获取最新联系人、并展示
# 发送post请求,根据ticket_dict进行构造数据
# https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=892259194&pass_ticket=TS7TEfumVaVzKhn%252FrnLKS2zZyhixJDEYxlXqGgQVplQ%253D
base_url = 'https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=892259194&pass_ticket={0}'
url = base_url.format(req.session['ticket_dict']['pass_ticket'])
# BaseRequest
# :
# {Uin: "184513440", Sid: "U4WojQwDRwKqdeMs", Skey: "", DeviceID: "e409571391728320"} form_data = {
'BaseRequest': {
'DeviceID': "e409571391728320",
'Sid': req.session['ticket_dict']['wxsid'],
'Skey': req.session['ticket_dict']['skey'],
'Uin': req.session['ticket_dict']['wxuin']
}
}
r1 = requests.post(
url=url,
json=form_data
)
r1.encoding = r1.apparent_encoding
user_info = json.loads(r1.content)
req.session['current_user_info'] = user_info['User']
# for k, v in user_info.items():
# print(k, v)
# for user in user_info['ContactList']:
# print(user['NickName'])
# for msg in user_info['MPSubscribeMsgList']:
# print(msg['NickName'])
return render(req, 'wechat/index.html', {"user_info": user_info})
结果示意图:

此时解决查看联系人的问题,还是老方法,继续监控network。这里就不再卖关子了。getcontact这个就是获取所有联系人的url。
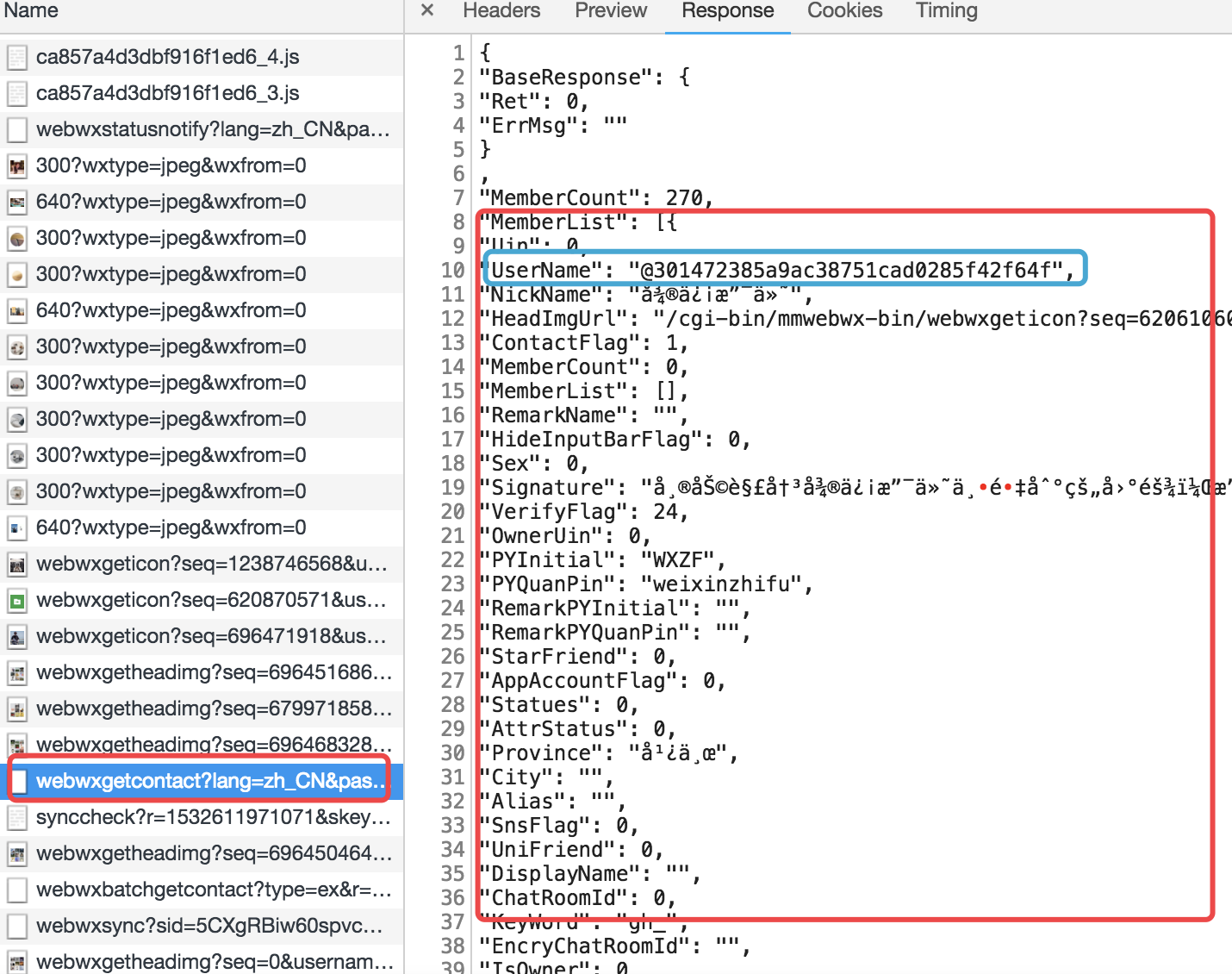
不必多说,继续伪造:
path('contact_all/', views.contact_all),
视图函数:
def contact_all(req):
# https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact?pass_ticket=z%252BTVxEioLl3A5arKy%252BUMHbeTME%252BmAkJEulNYIYgGcpw%253D&r=1532421128264&seq=0&skey=@crypt_41bed7c6_e213390395ab3a4ef54bfef5d004f719
base_url = 'https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact?pass_ticket={0}&r={1}&seq=0&skey={2}'
url = base_url.format(
req.session['ticket_dict']['pass_ticket'],
time.time() * 1000,
req.session['ticket_dict']['skey'],
) # url拼接
all_cookies = {}
all_cookies.update(req.session['login_cookie'])
all_cookies.update(req.session['ticket_cookie']) # 带入所有的cookies r1 = requests.get(url, cookies=all_cookies)
r1.encoding = r1.apparent_encoding
contact_dict = json.loads(r1.content)
for item in contact_dict:
print(item)
# for item in contact_dict['MemberList']:
# # if item['RemarkName'] == '宇宙第一帅':
# # print(item)
return render(req, 'wechat/contact_all.html', {'contact_dict': contact_dict})
index.html
打印了所有的最外层的key:
BaseResponse
MemberCount
MemberList
Seq
上面被注释的那段代码,可以用来查找你备注的某个人的信息。监控里面看到的username其实是用户在微信里面的唯一ID。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<div>
<h1>联系人列表</h1>
<ul>
{% for item in contact_dict.MemberList %}
<li>{{ item.UserName|safe }} --- {{ item.NickName|safe }}</li>
{% endfor %}
</ul>
</div>
</body>
</html>
截图:

好了,现在到最紧张的最后一步了,如何发送消息?
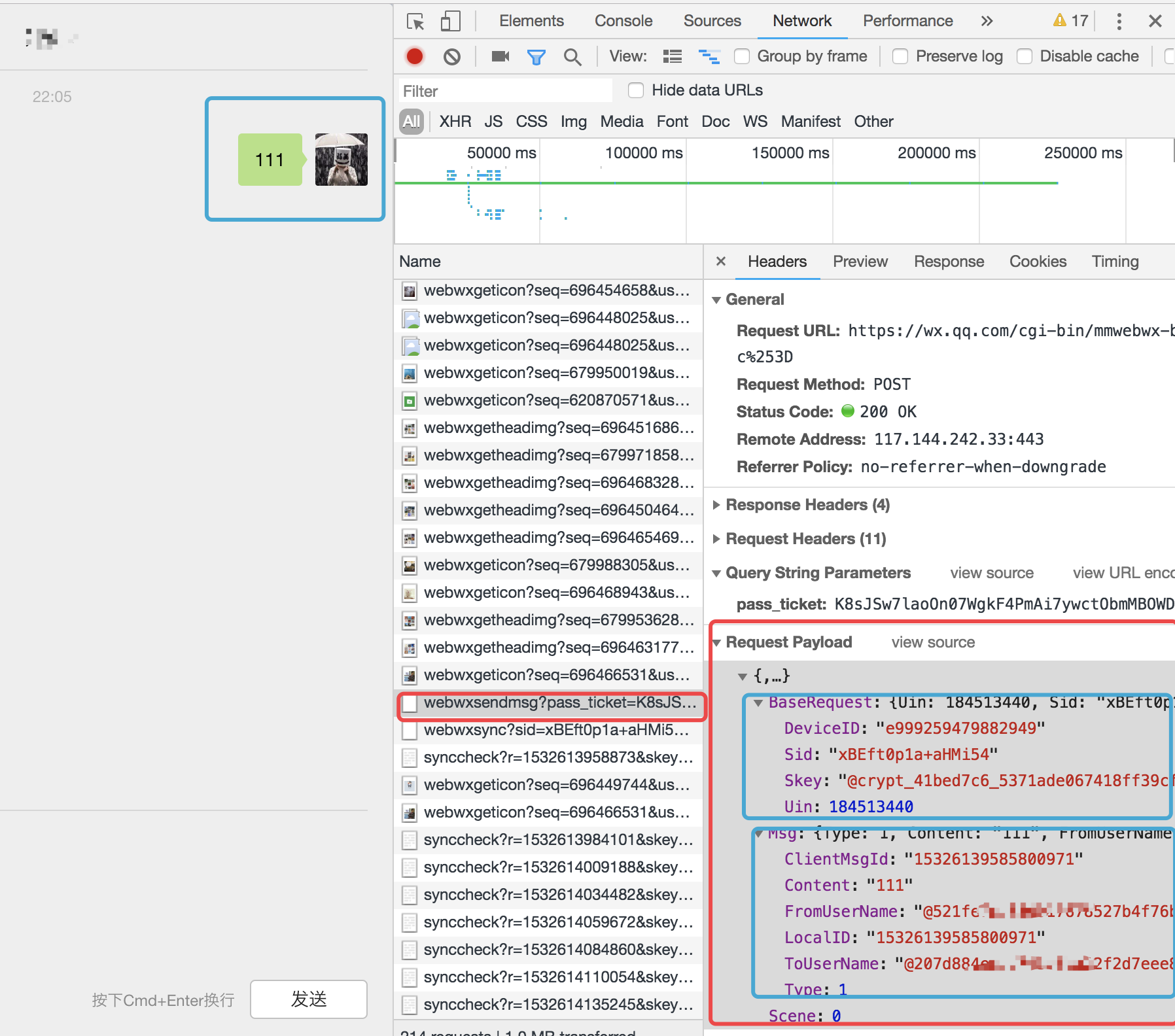
现在只需要伪造信息就好了,这里我们可以看见就是根据username的唯一id来发送信息的。
在contact网页里面添加如下代码:
<div>
<h1>发送消息</h1>
<p>接受者:<input type="text" id="recv" /></p>
<p>内容:<input type="text" id="content" /></p>
<input type="button" id="btn" value="Send" />
</div> <script src="/static/jquery.min.js"></script>
<script>
$(function() {
$('#btn').click(function() {
var recv = $('#recv').val();
var content = $('#content').val();
$.ajax({
url: '/wechat/send_msg/',
type: 'GET',
data: {'recv': recv, 'content': content},
success: function(arg) {
console.log(arg)
}
})
})
})
</script>
路由:
path('send_msg/', views.send_msg),
视图函数:
def send_msg(req):
recv = req.GET.get('recv')
content = req.GET.get('content')
# https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxsendmsg?pass_ticket=wtwzy%252F7fxQgJaTA511weqPXIkIGSJmZdCRATgZdIfYY%253D
base_url = 'https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxsendmsg?pass_ticket={0}'
url = base_url.format(req.session['ticket_dict']['pass_ticket'])
ctime = time.time() * 1000
form_data = { # 伪造数据格式
'BaseRequest': {
'DeviceID': "e939509344931677",
'Sid': req.session['ticket_dict']['wxsid'],
'Skey': req.session['ticket_dict']['skey'],
'Uin': req.session['ticket_dict']['wxuin']
},
'Msg': {
'ClientMsgId': ctime,
'Content': content,
'FromUserName': req.session['current_user_info']['UserName'],
'LocalID': ctime,
'ToUserName': recv,
'Type': 1, # 文本
},
'Scene': 0
}
all_cookies = {}
all_cookies.update(req.session['login_cookie'])
all_cookies.update(req.session['ticket_cookie']) # 带入cookie,试验过证明是需要的
r1 = requests.post(
url=url,
data=bytes(json.dumps(form_data, ensure_ascii=False), encoding='utf-8'),
cookies=all_cookies,
headers={
'Content-Type': 'application/json' # 这句话用来表示,需要序列化成json数据;也可以去掉data跟headers直接用json=form_data来实现
}
)
print(r1.text)
return HttpResponse('.....')
测试一下:

em。。。。。。
对,然后被拉黑了。至于接收消息,发送图片什么的其实都可以自己通过网络监控做到的。这里就不再多提了。
收工!
Python 爬虫五 进阶案例-web微信登陆与消息发送的更多相关文章
- C#开发微信门户及应用(19)-微信企业号的消息发送(文本、图片、文件、语音、视频、图文消息等)
我们知道,企业号主要是面向企业需求而生的,因此内部消息的交流显得非常重要,而且发送.回复消息数量应该很可观,对于大企业尤其如此,因此可以结合企业号实现内部消息的交流.企业号具有关注安全.消息无限制等特 ...
- python爬虫加定时任务,制作微信提醒备忘录
一.任务的记录与提取 1.1 制作每日任务 为了便于爬取,推荐使用网页版的在线记事本,现在这种工具很多,我选择"石墨文档"进行操作演示.记录内容的 格式可以根据自己的需求和爬虫自行 ...
- 基于Flask 实现Web微信登陆
网页版微信登陆网址 https://login.wx.qq.com/ 获取微信登陆的二维码 在浏览器中访问登陆接口 https://login.wx.qq.com/ 我们查找二维码的图片可以看到 其中 ...
- Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式 爬取Github数据 GET&POST请求一般格式 很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”.任何的网络通信归根 ...
- python爬虫(五)_urllib2:Get请求和Post请求
本篇将介绍urllib2的Get和Post方法,更多内容请参考:python学习指南 urllib2默认只支持HTTP/HTTPS的GET和POST方法 urllib.urlencode() urll ...
- Python爬虫(十一)_案例:使用正则表达式的爬虫
本章将结合先前所学的爬虫和正则表达式知识,做一个简单的爬虫案例,更多内容请参考:Python学习指南 现在拥有了正则表达式这把神兵利器,我们就可以进行对爬取到的全部网页源代码进行筛选了. 下面我们一起 ...
- Python爬虫(十三)_案例:使用XPath的爬虫
本篇是使用XPath的案例,更多内容请参考:Python学习指南 案例:使用XPath的爬虫 现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子且将该帖子里每个楼层发布的图片下载 ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- Python 爬虫 (五)
# 头条街拍图片爬取 1 import re import requests from urllib import request import json import os i = 0 header ...
随机推荐
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- http uri唯一标识
URI:唯一标识并且信息资源(简单理解为:发邮件的地址,身份证号).uri包括url 比如通过查找一个uri,找到一张图片“https://timgsa.baidu.com/timg?image&am ...
- Tennis Game CodeForces - 496D(唯一分解定理,费马大定理)
Tennis Game CodeForces - 496D 通过排列组合解决问题. 首先两组不同素数的乘积,是互不相同的.这应该算是唯一分解定理的逆运用了. 然后是,输入中的素数,任意组合,就是n的因 ...
- sqlserver2008查看表记录或者修改存储过程出现目录名无效错误解决方法
登陆数据库后,右键打开表提示:目录名无效,执行SQL语句也提示有错误,现在把解决方法分享给大家 1.新建查询 2.点工具栏中[显示估计的查询计划],结果提示Documents and Settings ...
- loopback(回环)
Loopback接口是一个虚拟网络接口,在不同的领域,其含义也大不一样. 1. TCP/IP协议栈中的loopback接口 在TCP/IP中回环设备是一个通过软件实现的虚拟网络接口,它不与任何硬件相 ...
- icmpsh解决运行报错
运行./run.sh报错 sysctl -w net.ipv4.icmp_echo_ignore_all=1 >/dev/null python icmpsh_m.py 攻击机ip 目标机ip ...
- PHP手动搭建环境
php手动搭建环境有好多种组合,版本号不一致,会导致搭建失败. 我搭建的组合是: php5.6+MySQL5.6+Apache2.4的组合. 一.PHP语言包下载 首先从官网上下载php5.6 htt ...
- 2019年 十款Mac上必备的实用软件列表
2019年 十款Mac上必备的实用软件列表 文章来源:风云社区 (www.scoee.com 两千多款Mac软件下载) 1.Parallels Desktop 如果你还是想在Mac上使用Windows ...
- 三台机器之间root用户ssh互信配置
三台机器之间root用户ssh互信配置 (1)在所有的主机上执行:ssh-keygen -t rsa # 在每台都需要操作,一路回车 (2)将所有机子上公钥(id_rsa.pub)导到一个主机的/ro ...
- 【C#】C#创建自定义Object对象
艹,老是忘!!! }; 记录一下,var obj = new { Name="lily",Age=12};