oracle_基本SQL语言
一:DDL数据定义语言
1:create(创建)
创建表
CREATE TABLE <table_name>(
column1 DATATYPE [NOT NULL] [PRIMARY KEY],
column2 DATATYPE [NOT NULL],
...
[constraint <约束名> 约束类型 (要约束的字段)
... ] )
/*说明:
DATATYPE --是Oracle的数据类型,可以查看附录。
NUT NULL --可不可以允许资料有空的(尚未有资料填入)。
PRIMARY KEY --是本表的主键。
constraint --是对表里的字段添加约束.(约束类型有
Check,Unique,Primary key,not null,Foreign key)。
*/
---示例:
create table stu(
s_id number(8) PRIMARY KEY,
s_name varchar2(20) not null,
s_sex varchar2(8),
clsid number(8),
constraint u_1 unique(s_name),
constraint c_1 check (s_sex in ('MALE','FEMALE'))
);
复制表
CREATE TABLE <table_name> as <SELECT 语句> ---(需注意的是复制表不能复制表的约束); --示例:
create table test as select * from emp; ---如果只复制表的结构不复制表的数据则:
create table test as select * from emp where 1=2;
创建索引
--创建索引 --------------------------------------------------------------------------------
CREATE [UNIQUE] INDEX <index_name> ON <table_name>(字段 [ASC|DESC]);
/*
UNIQUE --确保所有的索引列中的值都是可以区分的。
[ASC|DESC] --在列上按指定排序创建索引。 (创建索引的准则:
1.如果表里有几百行记录则可以对其创建索引(表里的记录行数越多索引的效果就越明显)。
2.不要试图对表创建两个或三个以上的索引。
3.为频繁使用的行创建索引。
)
*/ --示例
create index i_1 on emp(empno asc);
创建同义词
--创建同义词 -------------------------------------------------------------------------------- CREATE SYNONYM <synonym_name> for <tablename/viewname> --同义词即是给表或视图取一个别名。 --示例:
create synonym mm for emp;
2:alter(修改)
--修改表 -------------------------------------------------------------------------------- --1.向表中添加新字段
ALTER TABLE <table_name> ADD (字段1 类型 [NOT NULL],字段2 类型 [NOT NULL].... ); --2.修改表中字段
ALTER TABLE <table_name> modify(字段1 类型,字段2 类型.... ); --3 .删除表中字段
ALTER TABLE <table_name> drop(字段1,字段2 .... ); --4 .修改表的名称
RENAME <table_name> to <new table_name>; --5 .对已经存在的表添加约束
ALTER TABLE <table_name> ADD CONSTRAINT <constraint_name> 约束类型 (针对的字段名);
---示例:
Alter table emp add constraint S_F Foreign key (deptno) references dept(deptno); --6 .对表里的约束禁用;
ALTER TABLE <table_name> DISABLE CONSTRAINT <constraint_name>; ---7 .对表里的约束重新启用;
ALTER TABLE <table_name> ENABLE CONSTRAINT <constraint_name>; ---8 .删除表中约束
ALTER TABLE <table_name> DROP CONSTRAINT <constraint_name>;
---示例:
ALTER TABLE emp drop CONSTRAINT <Primary key>;
2:drop(删除)
删除表
--删除表 --------------------------------------------------------------------------------
DROP TABLE <table_name>; ---示例
drop table emp;
删除索引
--删除索引 --------------------------------------------------------------------------------
DROP INDEX <index_name>; --示例
drop index i_1;
删除同义词
--删除同义词 --------------------------------------------------------------------------------
DROP SYNONYM <synonym_name>; --示例
drop synonym mm;
二:DML数据操纵语言
插入记录 insert into
--插入记录 --------------------------------------------------------------------------------
INSERT INTO table_name (column1,column2,...)
values ( value1,value2, ...); --示例
insert into emp (empno,ename) values(9500,'AA'); --把 一个表中的数据插入另一个表中 INSERT INTO <table_name> <SELECT 语句>
--示例
create table a as select * from emp where 1=2;
insert into a select * from emp where sal>2000;
查询记录 select
--查询记录 -------------------------------------------------------------------------------- --一般查询
SELECT [DISTINCT] <column1 [as new name] ,columns2,...>
FROM <table1>
[WHERE <条件>]
[GROUP BY <column_list>]
[HAVING <条件>]
[ORDER BY <column_list> [ASC|DESC]] /*
DISTINCT --表示隐藏重复的行
WHERE --按照一定的条件查找记录
GROUP BY --分组查找(需要汇总时使用)
HAVING --分组的条件
ORDER BY --对查询结果排序 要显示全部的列可以用*表示 */
--示例:
select * from emp; WHERE 语句的运算符
where <条件1>AND<条件2> --两个条件都满足
--示例:
select * from emp where deptno=10 and sal>1000; where <条件1>OR<条件2> --两个条件中有一个满足即可
--示例:
select * from emp where deptno=10 OR sal>2000; where NOT <条件> --不满足条件的
--示例:
select * from emp where not deptno=10; where IN(条件列表) --所有满足在条件列表中的记录
--示例:
select * from emp where empno in(7788,7369,7499); where BETWEEN .. AND .. --按范围查找
--示例:
select * from emp where sal between 1000 and 3000; where 字段 LIKE --主要用与字符类型的字段
--示例1:
select * from emp where ename like '_C%'; --查询姓名中第二个字母是'C'的人
--'-' 表示任意字符;
--'%' 表示多字符的序列; where 字段 IS [NOT] NULL --查找该字段是[不是]空的记录 --汇总数据是用的函数
--SUM --求和
--示例:
select deptno,sum(sal) as sumsal from emp GROUP BY deptno; /*
AVG --求平均值
MAX --求最大值
MIN --求最小值
COUNT --求个数
*/ --子查询
SELECT <字段列表> from <table_name> where 字段 运算符(<SELECT 语句>); --示例:
select * from emp where sal=(select max(sal) from emp); --运算符
Any
--示例:
select * from emp where sal>ANY(select sal from emp where deptno=30) and deptno<>30;
--找出比deptno=30的员工最低工资高的其他部门的员工 --ALL
select * from emp where sal>ALL(select sal from emp where deptno=30) and deptno<>30;
--找出比deptno=30的员工最高工资高的其他部门的员工 --连接查询
SELECT <字段列表> from <table1,table2> WHERE table1.字段[(+)]=table2.字段[(+)] --示例
select empno,ename,dname from emp,dept where emp.deptno=dept.deptno; --查询指定行数的数据
SELECT <字段列表> from <table_name> WHERE ROWNUM<行数;
--示例:
select * from emp where rownum<=10;--查询前10行记录
--注意ROWNUM只能为1 因此不能写 select * from emp where rownum between 20 and 30; --要查第几行的数据可以使用以下方法:
select * from emp where rownum<=3 and empno not in (select empno from emp where rownum<=3);
--结果可以返回整个数据的3-6行;
--不过这种方法的性能不高;如果有别的好方法请告诉我。
更新数据 update
--更新数据 --------------------------------------------------------------------------------
UPDATE table_name set column1=new value,column2=new value,...
WHERE <条件> --示例
update emp set sal=1000,empno=8888 where ename='SCOTT'
删除数据 delete
--更新数据 --------------------------------------------------------------------------------
DELETE FROM <table_name>
WHERE <条件> --示例
delete from emp where empno=''
三:DCL数据控制语言
数据控制语言
--数据控制语言 --------------------------------------------------------------------------------
--1.授权
GRANT <权限列表> to <user_name>; --2.收回权限
REVOKE <权限列表> from <user_name> /*
Oracle 的权限列表
connect 连接
resource 资源
unlimited tablespace 无限表空间
dba 管理员
session 会话
*/
四:TCL事务控制语言
--数据控制语言 --------------------------------------------------------------------------------
--1.提交;
COMMIT; --2.回滚;
ROLLBACK [TO savepoint] --3.保存位置。
SAVEPOINT <savepoint>
五:Oracle 其他对象
视图:
--创建视图
--------------------------------------------------------------------------------
CREATE [OR REPLACE] VIEW <view_name>
AS
<SELECT 语句>; OR REPLACE --表示替换以有的视图 --删除视图
-------------------------------------------------------------------------------- DROP VIEW <view_name>
序列:
--创建序列
-------------------------------------------------------------------------------- CREATE SEQUENCE <sequencen_name>
INCREMENT BY n
START WITH n
[MAXVALUE n][MINVALUE n]
[CYCLE|NOCYCLE]
[CACHE n|NOCACHE]; /*
INCREMENT BY n --表示序列每次增长的幅度;默认值为1.
START WITH n --表示序列开始时的序列号。默认值为1.
MAXVALUE n --表示序列可以生成的最大值(升序).
MINVALUE n --表示序列可以生成的最小值(降序).
CYCLE --表示序列到达最大值后,在重新开始生成序列.默认值为 NOCYCLE。
CACHE --允许更快的生成序列.
*/ --示例:
create sequence se_1
increment by 1
start with 100
maxvalue 999999
cycle; --修改序列 -------------------------------------------------------------------------------- ALTER SEQUENCE <sequencen_name>
INCREMENT BY n
START WITH n
[MAXVALUE n][MINVALUE n]
[CYCLE|NOCYCLE]
[CACHE n|NOCACHE]; --删除序列 -------------------------------------------------------------------------------- DROP SEQUENCE <sequence_name> --使用序列 -------------------------------------------------------------------------------- 1.CURRVAL
返回序列的当前值.
注意在刚建立序列后,序列的CURRVAL值为NULL,所以不能直接使用。
可以先初始化序列:
方法:select <sequence_name>.nextval from dual;
示例:select se_1.nextval from dual;
之后就可以使用CURRVAL属性了 2.NEXTVAL
返回序列下一个值;
示例:
begin
for i in 1..5
loop
insert into emp(empno) values(se_1.nextval);
end loop;
end; --查看序列的当前值
select <sequence_name>.currval from dual; --示例:select se_1.currval from dual;
用户
--创建用户
-------------------------------------------------------------------------------- CREATE USER <user_name> [profile "DEFAULT"]
identified by "<password>" [default tablespace "USERS"] --删除用户 -------------------------------------------------------------------------------- DROP USER <user_name> CASCADE
角色
--创建角色
-------------------------------------------------------------------------------- CREATE ROLE <role_name>
identified by "<password>" --删除角色
-------------------------------------------------------------------------------- DROP ROLE <role_name>
六:PL/SQL
PL/SQL 结构
---PL/SQL 结构 --------------------------------------------------------------------------------
DECLARE --声明部分
声明语句
BEGIN --执行部分
执行语句 EXCEPTION --异常处理部分
执行语句 END; 变量声明
<变量名> 类型[:=初始值];
特殊类型 字段%type
示例: name emp.ename%type --表示name的类型和emp.ename的类型相同
表 %rowtype
示例: test emp%rowtype --表示test的类型为emp表的行类型;也有 .empno; .ename; .sal ;等属性 常量声明
<变量名> CONSTANT 类型:=初始值;
示例: pi constant number(5,3):=3.14; 全局变量声明
VARIABLE <变量名> 类型;
示例: VARIABLE num number; 使用全局变量
:<变量名>
示例:
:num:=100;
i=:num; 查看全局变量的值
print <变量名>
示例: print num; 赋值运算符: :=
示例: num := 100; 使用SELECT <列名> INTO <变量名> FROM <表名> WHERE <条件>
注意select into 语句的返回结果只能为一行;
示例:test emp%rowtype;
select * into test from emp where empno=7788; 用户交互输入
<变量>:='&变量'
示例:
num:=# 注意oracle的用户交互输入是先接受用户输入的所有值后在执行语句;
所以不能使用循环进行用户交互输入; 条件控制语句
IF <条件1> THEN
语句
[ELSIF <条件2> THEN
语句
.
.
.
ELSIF <条件n> THEN
语句]
[ELSE
语句]
END IF; 循环控制语句
1.LOOP
LOOP
语句;
EXIT WHEN <条件>
END LOOP; 2.WHILE LOOP
WHILE <条件>
LOOP
语句;
END LOOP; 3.FOR
FOR <循环变量> IN 下限..上限
LOOP
语句;
END LOOP; NULL 语句
null;
表示没有操作; 注释使用
单行注释: --
多行注释:/* .......
...............*/ 异常处理 EXCEPTION
WHEN <异常类型> THEN
语句;
WHEN OTHERS THEN
语句;
END;
关于异常类型请查看附录.
游标
显示游标
-------------------------------------------------------------------------------- 定义:CURSOR <游标名> IS <SELECT 语句> [FOR UPDATE | FOR UPDATE OF 字段]; [FOR UPDATE | FOR UPDATE OF 字段] --给游标加锁,既是在程序中有"UPDATE","INSERT","DELETE"语句对数据库操作时。
游标自动给指定的表或者字段加锁,防止同时有别的程序对指定的表或字段进行"UPDATE","INSERT","DELETE"操作.
在使用"DELETE","UPDATE"后还可以在程序中使用CURRENT OF <游标名> 子句引用当前行. 操作:OPEN <游标名> --打开游标
FETCH <游标名> INTO 变量1,变量2,变量3,....变量n,;
或者
FETCH <游标名> INTO 行对象; --取出游标当前位置的值
CLOSE <游标名> --关闭游标
属性: %NOTFOUND --如果FETCH语句失败,则该属性为"TRUE",否则为"FALSE";
%FOUND --如果FETCH语句成果,则该属性为"TRUE",否则为"FALSE";
%ROWCOUNT --返回游标当前行的行数;
%ISOPEN --如果游标是开的则返回"TRUE",否则为"FALSE"; 使用:
LOOP循环
示例:
DECLARE
cursor c_1 is select * from emp; --定义游标
r c_1%rowtype; --定义一个行对象,用于获得游标的值
BEGIN
if c_1%isopen then
CLOSE c_1;
end if;
OPEN c_1; --判断游标是否打开.如果开了将其关闭,然后在打开
dbms_output.put_line('行号 姓名 薪水');
LOOP
FETCH c_1 INTO r; --取值
EXIT WHEN c_1%NOTFOUND; --如果游标没有取到值,退出循环.
dbms_output.put_line(c_1%rowcount||''||r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示.
END LOOP;
END; FOR循环
示例:
DECLARE
cursor c_1 is select ename,sal from emp; --定义游标
BEGIN
dbms_output.put_line('行号 姓名 薪水');
FOR i IN c_1 --for循环中的循环变量i为c_1%rowtype类型;
LOOP
dbms_output.put_line(c_1%rowcount||''||i.ename||''||i.sal); --输出结果,需要 set serverout on 才能显示.
END LOOP;
END; for循环使用游标是在循环开始前自动打开游标,并且自动取值到循环结束后,自动关闭游标. 游标加锁示例:
DECLARE
cursor c_1 is select ename,sal from emp for update of sal; --定义游标对emp表的sal字段加锁.
BEGIN
dbms_output.put_line('行号 姓名 薪水');
FOR i IN c_1 --for循环中的循环变量i为c_1%rowtype类型;
LOOP
UPDATE EMP set sal=sal+100 WHERE CURRENT OF c_1; --表示对当前行的sal进行跟新.
END LOOP;
FOR i IN c_1
LOOP
dbms_output.put_line(c_1%rowcount||''||i.ename||''||i.sal); --输出结果,需要 set serverout on 才能显示.
END LOOP;
END; 代参数的游标
定义:CURSOR <游标名>(参数列表) IS <SELECT 语句> [FOR UPDATE | FOR UPDATE OF 字段];
示例:
DECLARE
cursor c_1(name emp.ename%type) is select ename,sal from emp where ename=name; --定义游标
BEGIN
dbms_output.put_line('行号 姓名 薪水');
FOR i IN c_1('&name') --for循环中的循环变量i为c_1%rowtype类型;
LOOP
dbms_output.put_line(c_1%rowcount||''||i.ename||''||i.sal); --输出结果,需要 set serverout on 才能显示.
END LOOP;
END; 隐试游标
--------------------------------------------------------------------------------
隐试游标游标是系统自动生成的。每执行一个DML语句就会产生一个隐试游标,起名字为SQL; 隐试游标不能进行"OPEN" ,"CLOSE","FETCH"这些操作; 属性:
%NOTFOUND --如果DML语句没有影响到任何一行时,则该属性为"TRUE",否则为"FALSE";
%FOUND --如果DML语句影响到一行或一行以上时,则该属性为"TRUE",否则为"FALSE";
%ROWCOUNT --返回游标当最后一行的行数; 个人认为隐试游标的作用是判断一个DML语句;
示例:
BEGIN
DELETE FROM EMP WHERE empno=&a;
IF SQL%NOTFOUND THEN
dbms_output.put_line('empno不存在');
END IF;
IF SQL%ROWCOUNT>0 THEN
dbms_output.put_line('删除成功');
END IF;
END;
PL/SQL表
PL/SQL表
--------------------------------------------------------------------------------
pl/sql表只有两列,其中第一列为序号列为INTEGER类型,第二列为用户自定义列. 定义:TYPE <类型名> IS TABLE OF <列的类型> [NOT NULL] INDEX BY BINARY_INTEGER;
<列的类型>可以为Oracle的数据类行以及用户自定义类型; 属性方法:
.count --返回pl/sql表的总行数
.delect --删除pl/sql表的所有内容
.delect(行数) --删除pl/sql表的指定的行
.delct(开始行,结束行) --删除pl/sql表的多行
.first --返回表的第一个INDEX;
.next(行数) --这个行数的下一条的INDEX;
.last --返回表的最后一个INDEX; 使用
示例:
DECLARE
TYPE mytable IS TABLE OF VARCHAR2(20) index by binary_integer; --定义一个名为mytable的PL/sql表类型;
cursor c_1 is select ename from emp;
n number:=1;
tab_1 mytable; --为mytable类型实例化一个tab_1对象;
BEGIN
for i in c_1
loop
tab_1(n):=i.ename; --将得到的值输入pl/sql表
n:=n+1;
end loop;
n:=1;
tab_1.delete(&要删除的行数); --删除pl/sql表的指定行
for i in tab_1.first..tab_1.count
loop
dbms_output.put_line(n||''||tab_1(n)); --打印pl/sql表的内容
n:=tab_1.next(n);
end loop;
EXCEPTION
WHEN NO_DATA_FOUND THEN --由于删除了一行,会发生异常,下面语句可以接着删除的行后显示
for i in n..tab_1.count+1
loop
dbms_output.put_line(n||''||tab_1(n));
n:=tab_1.next(n);
end loop;
END;
PL/SQL记录
PL/SQL记录
--------------------------------------------------------------------------------
pl/sql表只有一行,但是有多列。 定义:TYPE <类型名> IS RECORD <列名1 类型1,列名2 类型2,...列名n 类型n,> [NOT NULL]
<列的类型>可以为Oracle的数据类行以及用户自定义类型;可以是记录类型的嵌套 使用
示例:
DECLARE
TYPE myrecord IS RECORD(id emp.empno%type,
name emp.ename%type,sal emp.sal%type); --定义一个名为myrecoed的PL/sql记录类型;
rec_1 myrecord; --为myrecord类型实例化一个rec_1对象;
BEGIN
select empno,ename,sal into rec_1.id,rec_1.name,rec_1.sal
from emp where empno=7788; --将得到的值输入pl/sql记录
dbms_output.put_line(rec_1.id||''||rec_1.name||''||rec_1.sal); --打印pl/sql记录的内容
END; 结合使用PL/SQL表和PL/SQL记录
示例:
DECLARE
CURSOR c_1 is select empno,ename,job,sal from emp;
TYPE myrecord IS RECORD(empno emp.empno%type,ename emp.ename%type,
job emp.job%type,sal emp.sal%type); --定义一个名为myrecoed的PL/sql记录类型;
TYPE mytable IS TABLE OF myrecord index by binary_integer;
--定义一个名为mytable的PL/sql表类型;字段类型为PL/sql记录类型; n number:=1;
tab_1 mytable; --为mytable类型实例化一个tab_1对象;
BEGIN
--赋值
for i in c_1
loop
tab_1(n).empno:=i.empno;
tab_1(n).ename:=i.ename;
tab_1(n).job:=i.job;
tab_1(n).sal:=i.sal;
n:=n+1;
end loop;
n:=1;
--输出
for i in n..tab_1.count
loop
dbms_output.put_line(i||''||tab_1(i).empno
||''||tab_1(i).ename||''||tab_1(i).job||''||tab_1(i).sal);
end loop;
END;
REF游标
强型REF游标
-------------------------------------------------------------------------------- 定义:TYPE <游标名> IS REF CURSOR RETURN<返回类型>; 操作:OPEN <游标名> For <select 语句> --打开游标
FETCH <游标名> INTO 变量1,变量2,变量3,....变量n,;
或者
FETCH <游标名> INTO 行对象; --取出游标当前位置的值
CLOSE <游标名> --关闭游标
属性: %NOTFOUND --如果FETCH语句失败,则该属性为"TRUE",否则为"FALSE";
%FOUND --如果FETCH语句成果,则该属性为"TRUE",否则为"FALSE";
%ROWCOUNT --返回游标当前行的行数;
%ISOPEN --如果游标是开的则返回"TRUE",否则为"FALSE"; 使用:
示例:
DECLARE
type c_type is ref cursor return emp%rowtype; --定义游标
c_1 c_type; --实例化这个游标类型
r emp%rowtype;
BEGIN
dbms_output.put_line('行号 姓名 薪水');
open c_1 for select * from emp;
loop
fetch c_1 into r;
exit when c_1%notfound;
dbms_output.put_line(c_1%rowcount||''||r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示.
END LOOP;
close c_1;
END; 弱型REF游标
--------------------------------------------------------------------------------
定义:TYPE <游标名> IS REF CURSOR; 操作:OPEN <游标名> For <select 语句> --打开游标
FETCH <游标名> INTO 变量1,变量2,变量3,....变量n,;
或者
FETCH <游标名> INTO 行对象; --取出游标当前位置的值
CLOSE <游标名> --关闭游标
属性: %NOTFOUND --如果FETCH语句失败,则该属性为"TRUE",否则为"FALSE";
%FOUND --如果FETCH语句成果,则该属性为"TRUE",否则为"FALSE";
%ROWCOUNT --返回游标当前行的行数;
%ISOPEN --如果游标是开的则返回"TRUE",否则为"FALSE";
示例:
set autoprint on;
var c_1 refcursor;
DECLARE
n number;
BEGIN
n:=&请输入;
if n=1 then
open :c_1 for select * from emp;
else
open :c_1 for select * from dept;
end if;
END;
过程
-------------------------------------------------------------------------------- 定义:CREATE [OR REPLACE] PROCEDURE <过程名>[(参数列表)] IS
[局部变量声明]
BEGIN
可执行语句
EXCEPTION
异常处理语句
END [<过程名>]; 变量的类型:in 为默认类型,表示输入; out 表示只输出;in out 表示即输入又输出; 操作以有的过程:在PL/SQL块中直接使用过程名;在程序外使用execute <过程名>[(参数列表)] 使用:
示例:
创建过程:
create or replace procedure p_1(n in out number) is
r emp%rowtype;
BEGIN
dbms_output.put_line('姓名 薪水');
select * into r from emp where empno=n;
dbms_output.put_line(r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示.
n:=r.sal;
END;
使用过程:
declare
n number;
begin
n:=&请输入员工号;
p_1(n);
dbms_output.put_line('n的值为 '||n);
end; 删除过程:
DROP PROCEDURE <过程名>;
函数
函数
-------------------------------------------------------------------------------- 定义:CREATE [OR REPLACE] FUNCTION <过程名>[(参数列表)] RETURN 数据类型 IS
[局部变量声明]
BEGIN
可执行语句
EXCEPTION
异常处理语句
END [<过程名>]; 变量的类型:in 为默认类型,表示输入; out 表示只输出;in out 表示即输入又输出; 使用:
示例:
创建函数:
create or replace function f_1(n number) return number is
r emp%rowtype;
BEGIN
dbms_output.put_line('姓名 薪水');
select * into r from emp where empno=n;
dbms_output.put_line(r.ename||''||r.sal); --输出结果,需要 set serverout on 才能显示.
return r.sal;
END;
使用函数:
declare
n number;
m number;
begin
n:=&请输入员工号;
m:=f_1(n);
dbms_output.put_line('m的值为 '||m);
end; 删除函数:
DROP FUNCTION <函数名>;
数据包
数据包
-------------------------------------------------------------------------------- 定义:
定义包的规范
CREATE [OR REPLACE] PACKAGE <数据包名> AS
--公共类型和对象声明
--子程序说明
END;
定义包的主体
CREATE [OR REPLACE] PACKAGE BODY <数据包名> AS
--公共类型和对象声明
--子程序主体
BEGIN
-初始化语句
END; 使用:
示例:
创建数据包规范:
create or replace package pack_1 as
n number;
procedure p_1;
FUNCTION f_1 RETURN number;
end; 创建数据包主体:
create or replace package body pack_1 as
procedure p_1 is
r emp%rowtype;
begin
select * into r from emp where empno=7788;
dbms_output.put_line(r.empno||''||r.ename||''||r.sal);
end; FUNCTION f_1 RETURN number is
r emp%rowtype;
begin
select * into r from emp where empno=7788;
return r.sal;
end;
end; 使用包:
declare
n number;
begin
n:=&请输入员工号;
pack_1.n:=n;
pack_1.p_1;
n:=pack_1.f_1;
dbms_output.put_line('薪水为 '||n);
end; 在包中使用REF游标
示例:
创建数据包规范:
create or replace package pack_2 as
TYPE c_type is REF CURSOR; --建立一个ref游标类型
PROCEDURE p_1(c1 in out c_type); --过程的参数为ref游标类型;
end; 创建数据包主体:
create or replace package body pack_2 as
PROCEDURE p_1(c1 in out c_type) is
begin
open c1 for select * from emp;
end;
end; 使用包:
var c_1 refcursor;
set autoprint on;
execute pack_2.p_1(:c_1); 删除包:
DROP PACKAGE <包名>;
触发器
触发器 --------------------------------------------------------------------------------
创建触发器:
CREATE [OR REPLACE] TRIGGER <触发器名>
BEFORE|AFTER
INSERT|DELETE|UPDATE [OF <列名>] ON <表名>
[FOR EACH ROW]
WHEN (<条件>)
<pl/sql块> 关键字"BEFORE"在操作完成前触发;"AFTER"则是在操作完成后触发;
关键字"FOR EACH ROW"指定触发器每行触发一次.
关键字"OF <列名>" 不写表示对整个表的所有列.
WHEN (<条件>)表达式的值必须为"TRUE". 特殊变量:
:new --为一个引用最新的列值;
:old --为一个引用以前的列值;
这些变量只有在使用了关键字 "FOR EACH ROW"时才存在.且update语句两个都有,而insert只有:new ,delect 只有:old; 使用RAISE_APPLICATION_ERROR
语法:RAISE_APPLICATION_ERROR(错误号(-20000到-20999),消息[,{true|false}]);
抛出用户自定义错误.
如果参数为'TRUE',则错误放在先前的堆栈上. INSTEAD OF 触发器
INSTEAD OF 触发器主要针对视图(VIEW)将触发的dml语句替换成为触发器中的执行语句,而不执行dml语句. 禁用某个触发器
ALTER TRIGGER <触发器名> DISABLE
重新启用触发器
ALTER TRIGGER <触发器名> ENABLE
禁用所有触发器
ALTER TRIGGER <触发器名> DISABLE ALL TRIGGERS
启用所有触发器
ALTER TRIGGER <触发器名> ENABLE ALL TRIGGERS
删除触发器
DROP TRIGGER <触发器名>
自定义对象
自定义对象 --------------------------------------------------------------------------------
创建对象:
CREATE [OR REPLACE] TYPE <对象名> AS OBJECT(
属性1 类型
属性2 类型
.
.
方法1的规范(MEMBER PROCEDURE <过程名>
方法2的规范 (MEMBER FUNCTION <函数名> RETURN 类型)
.
.
PRAGMA RESTRIC_REFERENCES(<方法名>,WNDS/RNDS/WNPS/RNPS);
关键字"PRAGMA RESTRIC_REFERENCES"通知ORACLE函数按以下模式之一操作;
WNDS-不能写入数据库状态;
RNDS-不能读出数据库状态;
WNPS-不能写入包状态;
RNDS-不能读出包状态; 创建对象主体:
CREATE [OR REPLACE] TYPE body <对象名> AS
方法1的规范(MEMBER PROCEDURE <过程名> is <PL/SQL块>
方法2的规范 (MEMBER FUNCTION <函数名> RETURN 类型 is <PL/SQL块>
END; 使用MAP方法和ORDER方法
用于对自定义类型排序。每个类型只有一个MAP或ORDER方法。
格式:MAP MEMBER FUNCTION <函数名> RETURN 类型
ORDER MEMBER FUNCTION <函数名> RETURN NUMBER 创建对象表
CREATE TABLE <表名> OF <对象类型> 示例:
1. 创建name 类型
create or replace type name_type as object(
f_name varchar2(20),
l_name varchar2(20),
map member function name_map return varchar2); create or replace type body name_type as
map member function name_map return varchar2 is --对f_name和l_name排序
begin
return f_name||l_name;
end;
end;
2 创建address 类型
create or replace type address_type as object
( city varchar2(20),
street varchar2(20),
zip number,
order member function address_order(other address_type) return number); create or replace type body address_type as
order member function address_order(other address_type) return number is --对zip排序
begin
return self.zip-other.zip;
end;
end; 3 创建stu对象
create or replace type stu_type as object (
stu_id number(5),
stu_name name_type,
stu_addr address_type,
age number(3),
birth date,
map member function stu_map return number,
member procedure update_age); create or replace type body stu_type as
map member function stu_map return number is --对stu_id排序
begin
return stu_id;
end;
member procedure update_age is --求年龄用现在时间-birth
begin
update student set age=to_char(sysdate,'yyyy')-to_char(birth,'yyyy') where stu_id=self.stu_id;
end;
end;
4. 创建对象表
create table student of stu_type(primary key(stu_id));
5.向对象表插值
insert into student values(1,name_type('关','羽'),address_type('武汉','成都路',43000), null,sysdate-365*20);
6.使用对象的方法
delcare
aa stu_type;
begin
select value(s) into aa from student s where stu_id=1; --value()将对象表的每一行转成行对象括号中必须为表的别名
aa.update_age();
end;
7.select stu_id,s.stu_name.f_name,s.stu_name.l_name from student s; --查看类型的值
8.select ref(s) from student s ; --ref()求出行对象的OID,括号中必须为表的别名;deref()将oid变成行队像;
其他
其他 --------------------------------------------------------------------------------
1.在PL/SQL中使用DDL
将sql语句赋给一个varchar2变量,在用execute immediate 这个varchar2变量即可;
示例:
declare
str varchar2(200);
begin
str:='create table test(id number,name varchar2(20))'; --创建表
execute immediate str;
str:='insert into test values(3,''c'')'; --向表里插数据
execute immediate str;
end;
但是要队这个表插入数据也必须使用execute immediate 字符变量 2.判断表是否存在;
示例:
declare
n tab.tname%type;
begin
select tname into n from tab where tname='&请输入表名';
dbms_output.put_line('此表以存在');
exception
when no_data_found then
dbms_output.put_line('还没有此表');
end; 2.查看以有的过程;
示例:
select object_name,object_type,status from user_objects where object_type='PROCEDURE';
七: 附录
Oracle 数据库类型
|
||||||||||||||||||||||||||||
函数
字符函数
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
名称
|
描述 |
|
ABS(数字)
|
一个数的绝对值 |
|
CEIL(数字)
|
向上取整;不论小数后的书为多少都要向前进位; CEIL(123.01)=124; CEIL(-123.99)=-123; |
|
FLOOR(数字)
|
向下取整;不论小数后的书为多少都删除;| floor(123.99)=123; floor(-123.01)=-124; |
|
MOD(被除数,除数)
|
取余数; MOD(20,3)=2 |
|
ROUND(数字,从第几为开始取)
|
四舍五入; ROUND(123.5,0)=124; ROUND(-123.5,0)=-124; ROUND(123.5,-2)=100; ROUND(-123.5,-2)=-100; |
|
SIGN(数字)
|
判断是正数还是负数;正数返回1,负数返回-1,0返回0; |
|
SQRT(数字)
|
对数字开方; |
|
POWER(m,n)
|
求m的n次方; |
|
TRUNC(数字,从第几位开始)
|
切数字; TRUNC(123.99,1)=123.9 TRUNC(-123.99,1)=-123.9 TRUNC(123.99,-1)=120 TRUNC(-123.99,-1)=-120 TRUNC(123.99)=123 |
|
GREATEST(数字列表)
|
找出数字列表中最大的数; 示例: select greatest(100,200,-100) from dual; --结果为200 |
|
LEAST(数字列表)
|
找出数字列表中最小的数; |
|
SIN(n)
|
求n的正旋 |
|
COS(n)
|
求n的余旋 |
|
TAN(n)
|
求n的正切 |
|
ACos(n)
|
求n的反正切 |
|
ATAN(n)
|
求n的反正切 |
|
exp(n)
|
求n的指数 |
|
LN(n)
|
求n的自然对数,n必须大于0 |
|
LOG(m,n)
|
求n以m为底的对数,m和n为正数,且m不能为0 |
日期函数
|
名称
|
描述 |
sysdate |
sysdate |
|
ADD_MONTHS(日期,数字)
|
在以有的日期上加一定的月份; add_months(d1,n1) |
|
LAST_DAY(日期)
|
last_day(d1) |
|
MONTHS_BETWEEN(日期1,日期2)
|
months_between(d1,d2) 示例: |
|
NEW_TIME(时间,时区,'gmt')
|
NEW_TIME(dt1,c1,c2) |
round(d1[,c1]) |
round(d1[,c1]) |
trunc(d1[,c1]) |
trunc(d1[,c1]) |
|
NEXT_DAY(d,char)
|
next_day(d1[,c1]) |
extract(c1 from d1) |
extract(c1 from d1) |
localtimestamp |
localtimestamp |
current_timestamp |
current_timestamp |
current_date |
current_date |
dbtimezone |
dbtimezone |
SESSIONTIMEZONE |
SESSIONTIMEZONE |
INTERVAL c1 set1 |
INTERVAL c1 set1 |
转换函数
|
名称
|
描述 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

chartorowid(c1) 。。 |
chartorowid(c1) 。。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

ROWIDTOCHAR(rowid) 。。 |
ROWIDTOCHAR(rowid) 。。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
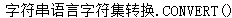
CONVERT(c1,set1,set2) |
CONVERT(c1,set1,set2) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

HEXTORAW(c1) |
HEXTORAW(c1) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
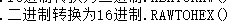
RAWTOHEX(c1) |
RAWTOHEX(c1) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
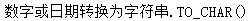
TO_CHAR(x[[,c2],C3]) |
TO_CHAR(x[[,c2],C3]) 【返回】varchar2字符型 【说明1】x为数据型时 c1格式表参考:
【示例】 【说明2】x为日期型,c2可用参数
【示例】 SQL> select to_char(sysdate,' PM yyyy-mm-dd hh24:mi:sssss AD year mon 【示例】带C3示例 select
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

TO_DATE(X[,c2[,c3]]) |
TO_DATE(X[,c2[,c3]]) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

TO_NUMBER(X[[,c2],c3]) |
TO_NUMBER(X[[,c2],c3]) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
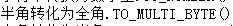
TO_MULTI_BYTE(c1) |
TO_MULTI_BYTE(c1) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
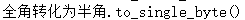
to_single_byte(c1) |
to_single_byte(c1) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

nls_charset_id(c1) |
nls_charset_id(c1) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

nls_charset_name(n1) |
nls_charset_name(n1) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
聚合函数 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

AVG([distinct|all]x) |
AVG([distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

SUM([distinct|all]x) |
SUM([distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

STDDEV([distinct|all]x) |
STDDEV([distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
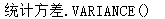
VARIANCE([distinct|all]x) |
VARIANCE([distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
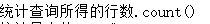
count(*|[distinct|all]x) |
count(*|[distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

MAX([distinct|all]x) |
MAX([distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

MIN([distinct|all]x) |
MIN([distinct|all]x) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Oracle 分析函数 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
其他函数
|
名称
|
描述 |
|
VSIZE(类型)
|
求出数据类型的大小; |
|
NVL(字符串,替换字符)
|
如果字符串为空则替换,否则不替换 |
|
命令
|
描述 |
|
DESC 表名
|
查看表的信息. |
|
SET SERVEROUT [ON|OFF]
|
设置系统输出的状态. |
|
SET PAGESIZE <大小>
|
设置浏览中没页的大小 |
|
SET LINESIZE <大小>
|
设置浏览中每行的长度 |
|
SET AUTOPRINT [ON|OFF]
|
设置是否自动打印全局变量的值 |
|
SELECT SYSDATE FROM DUAL
|
查看当前系统时间 |
|
ALTER SESSION SET nls_date_format='格式'
|
设置当前会话的日期格式 示例:ALTER SESSION SET nls_date_format='dd-mon-yy hh24:mi:ss' |
|
SELECT * FROM TAB
|
查看当前用户下的所有表 |
|
SHOW USER
|
显示当前用户 |
|
HELP TOPIC
|
显示有那些命令 |
|
SAVE <file_name>
|
将buf中的内容保存成一个文件 |
|
RUN <file_name>
|
执行已经保存的文件;也可以写成@<file_name> |
|
GET <file_name>
|
显示文件中的内容 |
|
LIST
|
显示buf中的内容 |
|
ED
|
用记事本打开buf,可以进行修改 |
|
DEL 行数
|
删除buf中的单行 |
|
DEL 开始行 结束行
|
删除buf中的多行 |
|
INPUT 字符串
|
向buf中插入一行 |
|
APPEND 字符串
|
将字符串追加到当前行 |
|
C/以前的字符串/替换的字符串
|
修改buf中当前行的内容 |
|
CONNECT
|
连接 |
|
DISCONNECT
|
断开连接 |
|
QUIT
|
退出sql*plus |
|
EXP
|
导出数据库(可以在DOS键入exp help=y 可以看到详细说明) 示例: exp scott/tiger full=y file=e:\a.dmp; --导出scott下的所有东西 exp scott/tiger tables=(emp,dept) file=e:\emp.dmp --导出scott下的 emp,dept表 |
|
IMP
|
导入数据库(可以在DOS键入imp help=y 可以看到详细说明) imp scott/tiger tables=(emp,dept) file=e:\emp.dmp |
可以通过help <命令>获得命令的帮助
常用命令
|
异常
|
描述
|
|
CURSOR_ALREADY_OPEN
|
试图"OPEN"一个已经打开的游标
|
|
DUP_VAL_ON_INDEX
|
试图向有"UNIQUE"中插入重复的值
|
|
INVALID_CURSOR
|
试图对以关闭的游标进行操作
|
|
INVALID_NUMBER
|
在SQL语句中将字符转换成数字失败
|
|
LOGIN_DENIED
|
使用无效用户登陆
|
|
NO_DATA_FOUND
|
没有找到数据时
|
|
NOT_LOGIN_ON
|
没有登陆Oracle就发出命令时
|
|
PROGRAM_ERROR
|
PL/SQL存在诸如某个函数没有"RETURN"语句等内部问题
|
|
STORAGE_ERROR
|
PL/SQL耗尽内存或内存严重不足
|
|
TIMEOUT_ON_RESOURCE
|
Oracle等待资源期间发生超时
|
|
TOO_MANY_ROWS
|
"SELECT INTO"返回多行时
|
|
VALUE_ERROR
|
当出现赋值错误
|
|
ZERO_DIVIDE
|
除数为零
|
oracle_基本SQL语言的更多相关文章
- 2016 - 3 - 12 SQLite的学习之SQL语言入门
1.SQL语句的特点: 1.1 不区分大小写 1.2 每条语句以;结尾 2.SQL语句中常用关键字: select,insert,update,from,create,where,desc,order ...
- SQL 语言 - 数据库系统原理
SQL 发展历程 从 1970 年美国 IBM 研究中心的 E.F.Codd 发表论文到 1974 年 Boyce 和 Chamberlin 把 SQUARE 语言改为 SEQUEL 语言,到现在的 ...
- SQL语言
SQL语言的分类:DDL DML DQL DCL SQL中的操作无非就是(增删改查) DDL:Data Query Language,数据查询语言! 主要是用来定义和维护数据库的各种操作对象,比如库. ...
- SQL语言分类
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML, 数据定义语言DDL,数据控制语言DCL. 1 数据查询语言DQL数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHER ...
- SQL语言概述
功能概述 DDL,数据库定义语言,创建,修改,删除数据库,表,视图,索引,约束条件等 DML,数据库操纵语言,对数据库中的数据进行增,删,改,查 DCL,数据库定义语言,对数据库总数据的访问设置权限 ...
- MySQL中的SQL语言
从功能上划分,SQL 语言可以分为DDL,DML和DCL三大类.1. DDL(Data Definition Language)数据定义语言,用于定义和管理 SQL 数据库中的所有对象的语言 :CRE ...
- atitit.java解析sql语言解析器解释器的实现
atitit.java解析sql语言解析器解释器的实现 1. 解析sql的本质:实现一个4gl dsl编程语言的编译器 1 2. 解析sql的主要的流程,词法分析,而后进行语法分析,语义分析,构建sq ...
- SQLLite 可以通过SQL语言来访问的文件型SQL数据库
Web Storage分为两类: - sessionStorage:数据保存在session 对象中(临时) - localStorage:数据保存在本地硬件设备中(永久) sessionStorag ...
- 数据库与SQL语言
数据库(DB) :长期储存在计算机中.有组织.可共享的数据的集合. 特点:(1)数据按一定的数据模型组织.描述和储存:(2)较小的冗余度:(3)数据独立性较高:(4)易扩展:(5)可共享(不同用户可按 ...
随机推荐
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
- CentOS7查询最近修改的文件
当需要排查问题的时候,经常需要找到最近修改和产生的文件 下面的命令是查询当前目录下以log结尾的日志,并且在30分钟内修改过,这个可以根据情况修改时间为1分钟,查找最新产生的日志 突然想到这个问题,是 ...
- vue运行说明
1.cd 到demo里面 如:cd vuedemo(项目名) 2.安装依赖: npm install 3.运行项目 npm run dev
- python判断小数示例&写入文件内容示例
#需求分析: #1.判断小数点个数是否为1 #2.按照小数点分隔,取到小数点左边和右边的值 #3.判断正小数,小数点左边为整数,小数点右边为整数 #4.判断负小数,小数点左边以负号开头,并且只有一个负 ...
- python 的基础 学习 第五天 基础数据类型的操作方法
1,列表的基本操作方法 1,列表是python中的基础数据类型之一,其他语言中也有类似于列表的数据类型,比如js中叫数组,他是以[ ]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如: ...
- GDI+学习---2.GDI+编程模式及组成类
在使用GDI+的时候,您不必像在GDI中那样关心设备场景句柄,只需简单地创建一个Graphics对象,然后以您熟悉的面向对象的方式(如myGraphicsObject.DrawLine(paramet ...
- C++11 线程并发
并发 头文件<future> <thread> 高级接口 async().future<> future<int> result1; //int为fun ...
- mysql 查询优化 ~ 优化基础补充
一 简介:此文章是对于 sql通用基础的补充说明 二 虚拟列: mysql虚拟列是mysql5.7的新特性,对于函数计算形成的结果可作为虚拟列,并可以对虚拟列添加索引,这样就能加速sql的运行,不过有 ...
- Redis protected-mode属性解读
redis3.2版本后新增protected-mode配置,默认是yes,即开启.设置外部网络连接redis服务,设置方式如下: 1.关闭protected-mode模式,此时外部网络可以直接访问 2 ...
- 不指定虚拟路径的前提下通过http访问pdf、图片等文件
通常我们通过http访问图片或者pdf的时候都是将文件上传到指定文件夹下面,然后通过配置虚拟路径来访问指定的资源. 在不配置虚拟路径的情况下,我们通过获取到response的outpurstream, ...