Elasticsearch 关键字:索引,类型,字段,索引状态,mapping,文档
1. 索引(_index)
索引:说的就是数据库的名字。
我这个说法是对应到咱经常使用的数据库。
结合es的插件 head 来看。
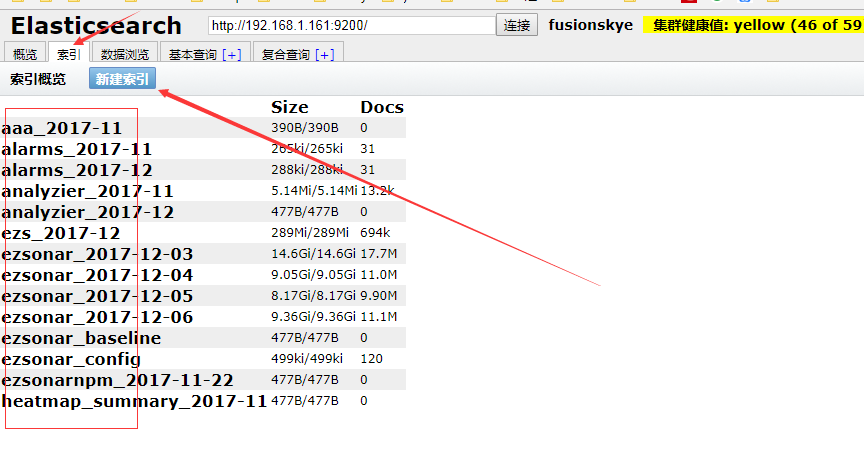
可以看到,我这个地方,就有这么几个索引,索引就是数据库,后面是这个数据库占用多大空间,以及里面有多少条docs,也就是里面有多少条数据。
(下面这些话算是我从其他地方复制官话吧。可以参考,但是,看完的效果不敢保证。)
索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。你可以把索引看成关系型数据库的表(湿胸我反对,你家的数据库一张表里面可以存不同的数据吗?存个学生,存个学校?存个dog?咱关系数据库,难道不是分三个表,一个表叫学生,一个叫学校,一个叫狗。吗?)。然而,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
2. 类型(_type)
还是结合head插件,来说这个关键字。
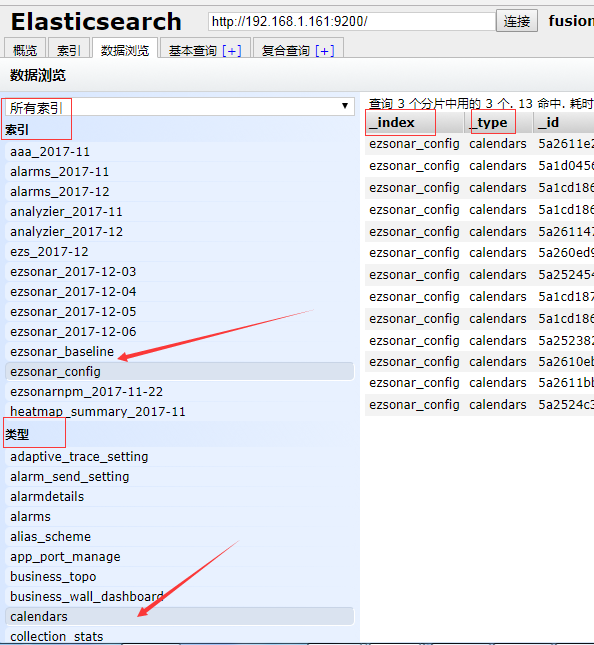
从图上,可以看到:我选择了一个索引,head插件,也是这么对索引翻译的,选择了索引之后,我在下面的类型里面又选择啦类型。
这个效果就是,右边展示的数据,现在展示的是我选择的那个索引里面的叫做calendars类型的数据,
相当于选择了某个数据库(ezsonar_config:可以算是数据库名称)里面的某个表(calendars:姑且可以叫表名称)
所以,这个类型就可以理解为我们常用的数据库的一张表
再多说一句,这个地方,可以看到很多的类型,这些类型是上面的所有的索引里面的所有字段的总和,不是说,你选了某个索引(数据库)之后,下面的类型(表)就会对应展示成某个数据库里面的表,他说全量展示的。所以,下面在展示字段的时候,也是展示的是所有的索引(数据库)的所有的类型(表)的所有的属性。
(下面这些话算是我从其他地方复制官话吧。可以参考,但是,看完的效果不敢保证。)
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。文档类型让我们轻易地区分单个索引中的不同对象。每个文档可以有不同的结构,但在实际部署中,将文件按类型区分对数据操作有很大帮助。当然,需要记住一个限制,不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫title的字段必须具有相同的类型。
上面变红的这句话,我翻译一下,就是说你在一个Student.class类里面有个属性 age 是 int,表示年龄用,,,你在另外一个Country.class 里面有个属性,也叫 age,string 类型,表示世纪。。。,那么,es就炸啦。我下面也将要说到,这个field,字段是一起展示的,也就是说es他是一起处理这些字段的,所以,你同一个字段,这里说的就是叫age的属性,一个是int类型,一个是字符串类型,他就会炸。。。。
我在使用,spring-data-elasticsearch的时候,还真的有这个情况,就是某个bean model里面他已经取了个属性名称是某个类型啦,我不知道,又在我自己新建的bean model里面也取了一样的名称的属性,但是类型不一样,,,,所以,我在保存数据到es的时候,崩 的炸啦。。。换个名称就没事啦。。。
我觉得,这是es的设计bug。。。
我自己设计model bean的时候,我怎么知道我这个属性的名称是否在其他地方被使用啦呢。。。。。。。
3. 字段(field)
还是结合head插件
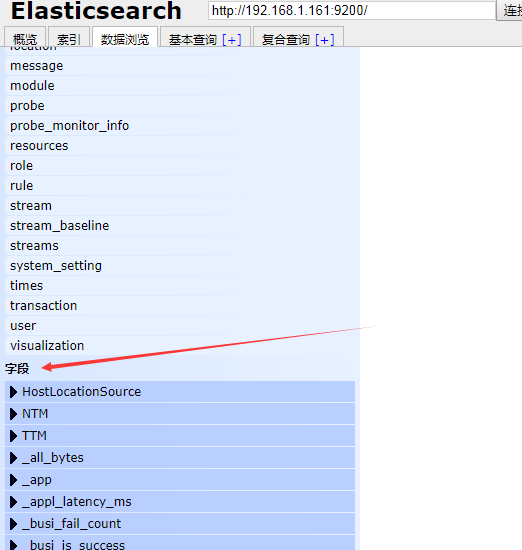
在索引完了之后,是类型,类型之后,是字段
这个字段,此处所展示的是包含了所有索引的所有类型的所有字段。
这个字段就是说,你保存的某个表里面的属性的的名称,比如,你存个学生类型,会有个Student类型,这个学生对象是不是可以有name,age,class等属性。这些属性在es里面就叫做。字段。
(我这好像没有复制官方的话。)
4. 文档(document)
文档:也就是指es里面的单条数据。看图。
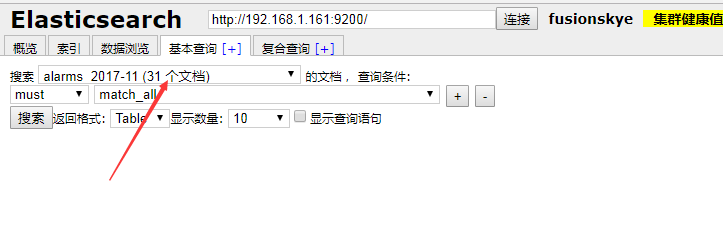
看到图里面,选择了一个索引(数据库),后面显示31个文档,就是简单的说明这个数据库里面一共有31条数据。是不是一个类型(表)里面的,就不得而知。
(下面这些话算是我从其他地方复制官话吧。可以参考,但是,看完的效果不敢保证。)
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。每个字段有类型,如文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。字段类型在Elasticsearch中很重要,因为它给出了各种操作(如分析或排序)如何被执行的信息。幸好,这可以自动确定,然而,我们仍然建议使用映射。与关系型数据库不同,文档不需要有固定的结构,每个文档可以有不同的字段,此外,在程序开发期间,不必确定有哪些字段。当然,可以用模式强行规定文档结构。从客户端的角度看,文档是一个JSON对象。每个文档存储在一个索引中并有一个Elasticsearch自动生成的唯一标识符和文档类型。文档需要有对应文档类型的唯一标识符,这意味着在一个索引中,两个不同类型的文档可以有相同的唯一标识符。
5. 映射(mapping)
这个是重点,就像你在使用数据库的时候,一样样滴。
还是看head插件的截图。
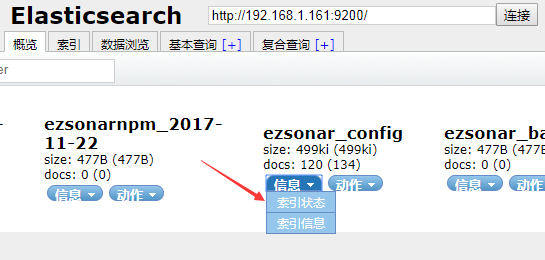
在head插件,可以如上图,查看当前索引(数据库)的状态和信息。
索引状态和索引信息,这2个词,是head插件翻译的。咱就这么用吧。
索引状态:就是简单的描述了下这个索引(数据库)的信息。可以大概看看,如下图。
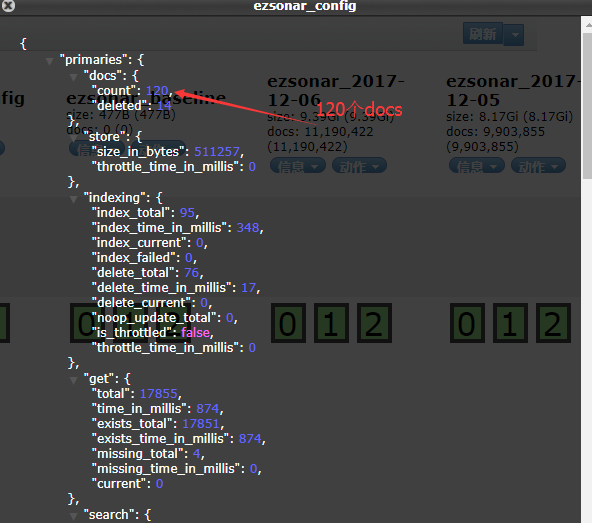
索引信息:这个是关键,这个说的是这个索引(数据库)里面的类型(表)的结构的设计。就像你在设计表结构一样,某个类型(表)的哪个字段(属性)是String,还是int还是boolean啥的,都在这地放看的。
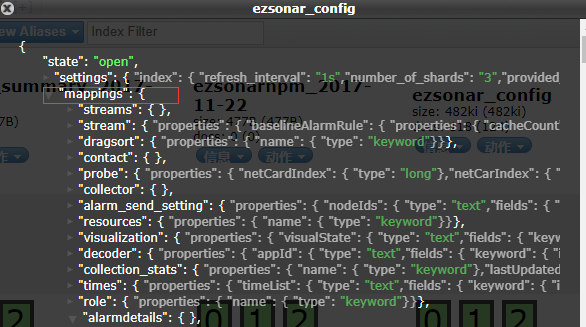
为了,实际对比,我这放一个Java里面的model bean 以及生成的mapping。因为字段也就是属性太多,我就删除了部分。
- @Document(indexName = "ezsonar_config", type = "calendars", shards = 3, replicas = 0)
- public class Calendar extends Type {
- @Id
- private String id;
- /**
- * 名称
- * 添加 @Field(type = FieldType.keyword)
- * 注解作用:不分词,查ES的时候,就是精确查找。
- */
- @Field(type = FieldType.keyword)
- private String name;
- private String content;
- private int streamType;
- private String jsonContent;
- }
上面是bean,下面是在索引信息里面的对应数据
- {
- "calendars": {
- "properties": {
- "hid": {
- "type": "text",
- "fields": {
- "keyword": {
- "ignore_above": 256,
- "type": "keyword"
- }
- }
- },
- "content": {
- "type": "text",
- "fields": {
- "keyword": {
- "ignore_above": 256,
- "type": "keyword"
- }
- }
- },
- "streamType": {
- "type": "text",
- "fields": {
- "keyword": {
- "ignore_above": 256,
- "type": "keyword"
- }
- }
- },
- "name": {
- "type": "keyword"
- },
- "id": {
- "type": "text",
- "fields": {
- "keyword": {
- "ignore_above": 256,
- "type": "keyword"
- }
- }
- },
- "jsonContent": {
- "type": "text",
- "fields": {
- "keyword": {
- "ignore_above": 256,
- "type": "keyword"
- }
- }
- }
- }
- }
- }
一个json对象吧
(下面这些话算是我从其他地方复制官话吧。可以参考,但是,看完的效果不敢保证。)
在有关全文搜索基础知识部分,我们提到了分析的过程:为建索引和搜索准备输入文本。文档中的每个字段都必须根据不同类型做相应的分析。举例来说,对数值字段和从网页抓取的文本字段有不同的分析,比如前者的数字不应该按字母顺序排序,后者的第一步是忽略HTML标签,因为它们是无用的信息噪音。Elasticsearch在映射中存储有关字段的信息。每一个文档类型都有自己的映射,即使我们没有明确定义。
Elasticsearch 主要概念
现在,我们已经知道Elasticsearch把数据存储在一个或多个索引上,每个索引包含各种类型的文档。我们也知道了每个文档有很多字段,映射定义了Elasticsearch如何对待这些字段。但还有更多,从一开始,Elasticsearch就被设计为能处理数以亿计的文档和每秒数以百计的搜索请求的分布式解决方案。这归功于几个重要的概念,我们现在将更详细地描述。
1. 节点和集群
Elasticsearch可以作为一个独立的单个搜索服务器。不过,为了能够处理大型数据集,实现容错和高可用性,Elasticsearch可以运行在许多互相合作的服务器上。这些服务器称为集群(cluster),形成集群的每个服务器称为节点(node)。
2. 分片
当有大量的文档时,由于内存的限制、硬盘能力、处理能力不足、无法足够快地响应客户端请求等,一个节点可能不够。在这种情况下,数据可以分为较小的称为分片(shard)的部分(其中每个分片都是一个独立的Apache Lucene索引)。每个分片可以放在不同的服务器上,因此,数据可以在集群的节点中传播。当你查询的索引分布在多个分片上时,Elasticsearch会把查询发送给每个相关的分片,并将结果合并在一起,而应用程序并不知道分片的存在。此外,多个分片可以加快索引。
3. 副本
为了提高查询吞吐量或实现高可用性,可以使用分片副本。副本(replica)只是一个分片的精确复制,每个分片可以有零个或多个副本。换句话说,Elasticsearch可以有许多相同的分片,其中之一被自动选择去更改索引操作。这种特殊的分片称为主分片(primary shard),其余称为副本分片(replica shard)。在主分片丢失时,例如该分片数据所在服务器不可用,集群将副本提升为新的主分片。
4. 时光之门
Elasticsearch处理许多节点。集群的状态由时光之门控制。默认情况下,每个节点都在本地存储这些信息,并且在节点中同步。
面向文档
应用中的对象很少只是简单的键值列表,更多时候它拥有复杂的数据结构,比如包含日期、地理位置、另一个对象或者数组。
总有一天你会想到把这些对象存储到数据库中。将这些数据保存到由行和列组成的关系数据库中,就好像是把一个丰富,信息表现力强的对象拆散了放入一个非常大的表格中:你不得不拆散对象以适应表模式(通常一列表示一个字段),然后又不得不在查询的时候重建它们。
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
Elasticsearch 关键字:索引,类型,字段,索引状态,mapping,文档的更多相关文章
- elasticsearch最全详细使用教程:入门、索引管理、映射详解、索引别名、分词器、文档管理、路由、搜索详解
一.快速入门1. 查看集群的健康状况http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 状 ...
- mysql索引类型和索引方法
索引类型 mysql索引类型normal,unique,full text的区别是什么? normal:表示普通索引 unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号 ...
- ES入门三部曲:索引操作,映射操作,文档操作
ES入门三部曲:索引操作,映射操作,文档操作 一.索引操作 1.创建索引库 #语法 PUT /索引名称 { "settings": { "属性名": " ...
- Es图形化软件使用之ElasticSearch-head、Kibana,Elasticsearch之-倒排索引操作、映射管理、文档增删改查
今日内容概要 ElasticSearch之-ElasticSearch-head ElasticSearch之-安装Kibana Elasticsearch之-倒排索引 Elasticsearch之- ...
- swagger 指定字段不显示到文档里
Swagger UI 隐藏指定接口类或方法 - 宁静致远 - CSDN博客https://blog.csdn.net/lqh4188/article/details/53538201 swagger ...
- mysql建立索引类型及索引建立的原则
索引类型:Unique(唯一索引,一般为主键),Normal(一般索引,普通字段,可做组合索引),索引方法:BTREE 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录 ...
- MySQL索引类型 btree索引和hash索引的区别
来源一 Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 ...
- 观后感-MySQL索引类型 btree索引和hash索引的区别
http://www.cnblogs.com/osfipin/p/4943229.html.http://www.2cto.com/database/201411/351106.html-文章地址 首 ...
- lucene全文搜索之四:创建索引搜索器、6种文档搜索器实现以及搜索结果分析(结合IKAnalyzer分词器的搜索器)基于lucene5.5.3
前言: 前面几章已经很详细的讲解了如何创建索引器对索引进行增删查(没有更新操作).如何管理索引目录以及如何使用分词器,上一章讲解了如何生成索引字段和创建索引文档,并把创建的索引文档保存到索引目录,到这 ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
随机推荐
- Javascript 高级程序设计--总结【四】
******************************* Chapter 11 DOM扩展 ******************************* 主要的扩展是 选择符API 和 H ...
- 简单易懂的程序语言入门小册子(5):基于文本替换的解释器,递归,不动点,fix表达式,letrec表达式
这个系列有个显著的特点,那就是标题越来越长.忽然发现今天是读书节,读书节多读书. ==下面是没有意义的一段话============================================== ...
- 【audio】耳机插拔 线控按键识别流程【转】
耳机插拔/线控按键识别流程 耳机插拔/线控按键识别流程 1.文档概述 本文以msm8909平台,android N为例,介绍了通用情况下,耳机插拔的流程步骤,以及对耳机类型的识别逻辑.以方便在项目工作 ...
- Node 各个版本支持ES2015特性的网站
如果想了解Node 各个版本支持ES2015到那个程度,可以看下面网站. https://node.green/
- 如何指定一个计划和目标——6W
作为一名IT人员,需要自己指定一个计划和目标,来保证完成进度和高效的完成任务. 参考管理学如何制作计划和目标的,套用过来,也是同样适用的.来先看看管理学的相关知识吧. 计划的概念:计划是为实现组织目标 ...
- Hadoop下添加节点和删除节点
添加节点 1.修改host 和普通的datanode一样.添加namenode的ip 2.修改namenode的配置文件conf/slaves 添加新增节点的ip或host 3.在新节点的机器 ...
- swiper.js + jquery.magnific-popup.js 实现奇葩的轮播需要
奇葩的轮播图 说轮播图很简单的,一定是没有遇到厉害的产品. 先说需求: 首先,一个mask会有三张图片,点击左右按钮会左右滑动一张图片的宽度. 点击展示的三张图片的任意一张,弹出遮罩,显示该图片的放大 ...
- Codeforces Round #542 C. Connect 搜索
C. Connect time limit per test 1 second memory limit per test 256 megabytes input standard input out ...
- 启动PHP study时提示80端口或者3306端口被占用的解决办法
一.查看PID WIN+R打开命令行------>netstat -ano+回车,就会显示下面的信息: 二.打开任务管理器 Ctrl+Alt+Delete------>任务管理器,找到对应 ...
- pm2命令,端口查询,mongodb服务启动,nginx服务启动,n模块的使用,搭建nodejs服务器环境,搭建oracledb服务器环境 linux的环境搭建
pm2命令 pm2 ls //查询pm2 启动的列表 pm2 start app.js //启动文件 pm2 restart app //重启项目 pm2 logs app //监控项目执行日志打印 ...