Python 的开发环境
建议在Windows 下开发,成本低廉,简单,效率高。
综合下:开发的程序,Python Django (Mysql,PostgreSQL) Nginx Redis ,这一组组合可以适应不同的平台,Linux 或者 Windows Server 下。。
Python版本:
推荐2.X系列,2.7是用的较多的。3.0N多不兼容。。。。想尝鲜的,呵呵呵呵
Windows-->Visual Studio2013 +PTVS2.2
Mac -->Xcode
Linux -->vi pycharm ......呵呵呵呵
也有用Pycharm 或者Eclipse的,亲身试试就知道那款合适了。不做比较。
小贴士:SharpDevelop_3.1。。。。。用这个来进行C# 项目代码的转化,你懂得。。。。
Web 框架:Django,Web.py 其他不考虑呵呵呵,你懂
数据库:Mysql Pgsql (Sqlite 额太mini,袖珍。Oracle 略贵 SqlServer 额,仅Windows.................MonoDB Nosql 等等等,争议太多,不要图新鲜,做试验品)
缓存:Memcached 或者Redis
Server:Nginx -->OpenResty
OpenResty - a fast web app server by extending nginx
、Tornado、Apache
前端:Jquery、 bootstrap、 kando
源码管理:vs 的 直接TFS,也可换成git
ORM工具:Django自带的或者 SQLAlchemy
序列化争议:
pickle和cPickle:Python对象的序列化(上)
pickle和cPickle:Python对象的序列化(下)
- 推荐 1 推荐
- 收藏 4 收藏,2k 浏览
目的:Python对象序列化
可用性:pickle至少1.4版本,cPickle 1.5版本以上
pickle模块实现了一种算法,将任意一个Python对象转化成一系列字节(byets)。此过程也调用了serializing对象。代表对象的字节流之后可以被传输或存储,再重构后创建一个拥有相同特征(the same characteristics)的新的对象。
cPickle使用C而不是Python,实现了相同的算法。这比Python实现要快好几倍,但是它不允许用户从Pickle派生子类。如果子类对你的使用来说无关紧要,那么cPickle是个更好的选择。
警告:本文档直接说明,pickle不提供安全保证。如果你在多线程通信(inter-process communication)或者数据存储或存储数据中使用pickle,一定要小心。请勿信任你不能确定为安全的数据。
导入
如平常一样,尝试导入cPickle,给它赋予一个别名“pickle”。如果因为某些原因导入失败,退而求其次到Python的原生(native)实现pickle模块。如果cPickle可用,能给你提供一个更快速的执行,否则只能是轻便的执行(the portable implementation)。
try:
import cPickle as pickle
except:
import pickle
编码和解码
第一个例子将一种数据结构编码成一个字符串,然后把该字符串打印至控制台。使用一种包含所有原生类型(native types)的数据结构。任何类型的实例都可被腌渍(pickled,译者注:模块名称pickle的中文含义为腌菜),在稍后的例子中会演示。使用pickle.dumps()来创建一个表示该对象值的字符串。
try:
import cPickle as pickle
except:
import pickle
import pprint
data = [ { 'a':'A', 'b':2, 'c':3.0 } ]
print 'DATA:',
pprint.pprint(data)
data_string = pickle.dumps(data)
print 'PICKLE:', data_string
pickle默认仅由ASCII字符组成。也可以使用更高效的二进制格式(binary format),只是因为在打印的时候更易于理解,本页的所有例子都使用ASCII输出。
$ python pickle_string.py
DATA:[{'a': 'A', 'b': 2, 'c': 3.0}]
PICKLE: (lp1
(dp2
S'a'
S'A'
sS'c'
F3
sS'b'
I2
sa.
数据被序列化以后,你可以将它们写入文件、套接字、管道等等中。之后你也可以从文件中读取出来、将它反腌渍(unpickled)而构造一个具有相同值得新对象。
try:
import cPickle as pickle
except:
import pickle
import pprint
data1 = [ { 'a':'A', 'b':2, 'c':3.0 } ]
print 'BEFORE:',
pprint.pprint(data1)
data1_string = pickle.dumps(data1)
data2 = pickle.loads(data1_string)
print 'AFTER:',
pprint.pprint(data2)
print 'SAME?:', (data1 is data2)
print 'EQUAL?:', (data1 == data2)
如你所见,这个新构造的对象与原对象相同,但并非同一对象。这不足为奇。
$ python pickle_unpickle.py
BEFORE:[{'a': 'A', 'b': 2, 'c': 3.0}]
AFTER:[{'a': 'A', 'b': 2, 'c': 3.0}]
SAME?: False
EQUAL?: True
与流一起工作
除dumps()和loads()外,pickle还提供一对用在类文件流(file-like streams)的转化函数。可以往一个流中写对个对象,然后从流中把它们读取出来,此过程不需要预先写入的对象有几个、它们多大。
try:
import cPickle as pickle
except:
import pickle
import pprint
from StringIO import StringIO
class SimpleObject(object):
def __init__(self, name):
self.name = name
l = list(name)
l.reverse()
self.name_backwards = ''.join(l)
return
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('cPickle'))
data.append(SimpleObject('last'))
# 使用StringIO模拟一个文件
out_s = StringIO()
# 写入该流
for o in data:
print 'WRITING: %s (%s)' % (o.name, o.name_backwards)
pickle.dump(o, out_s)
out_s.flush()
# 建立一个可读流
in_s = StringIO(out_s.getvalue())
# 读数据
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print 'READ: %s (%s)' % (o.name, o.name_backwards)
这个例子使用SringIO缓存器(buffer)模拟流,所以在建立可读流的时候我们玩了一把。一个简单数据库的格式化也可以使用pickles来存储对象,只是shelve与之工作更加简便。
$ python pickle_stream.py
WRITING: pickle (elkcip)
WRITING: cPickle (elkciPc)
WRITING: last (tsal)
READ: pickle (elkcip)
READ: cPickle (elkciPc)
READ: last (tsal)
除了存储数据,pickles在进程间通信(inter-process communication)中也非常称手。例如,使用os.fork()和os.pipe()可以创立工作者进程(worker processes),从一个管道(pipe)读取作业指令(job instruction)然后将结果写入另一个管道。管理工作者池(worker pool)和将作业送入、接受响应(response)的核心代码可被重用,因为作业和响应并不属于某个特定类中。如果你使用管道或者套接字(sockets),在通过连至另一端(end)的连接倾倒(dumps)所有对象、推送数据之后,别忘了冲洗(flush)。如果你想写自己的工作者池管理器,请看multiprocessing。
原文:pickle and cPickle – Python object serialization - Python Module of the Week 的前半部分
pickle和cPickle:Python对象的序列化(下)
- 推荐 0 推荐
- 收藏 2 收藏,474 浏览
重构对象的问题
当与你自己的类一起工作时,你必须保证类被腌渍出现在读取pickle的进程的命名空间中。只有该实例的数据而不是类定义被腌渍。类名被用于在反腌渍时,找到构造器(constructor)以创建新对象。以此——往一个文件写入一个类的实例为例:
try:
import cPickle as pickle
except:
import pickle
import sys
class SimpleObject(object):
def __init__(self, name):
self.name = name
l = list(name)
l.reverse()
self.name_backwards = ''.join(l)
return
if __name__ == '__main__':
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('cPickle'))
data.append(SimpleObject('last'))
try:
filename = sys.argv[1]
except IndexError:
raise RuntimeError('Please specify a filename as an argument to %s' % sys.argv[0])
out_s = open(filename, 'wb')
try:
# 写入流中
for o in data:
print 'WRITING: %s (%s)' % (o.name, o.name_backwards)
pickle.dump(o, out_s)
finally:
out_s.close()
在运行时,该脚本创建一个以在命令行指定的参数为名的文件:
$ python pickle_dump_to_file_1.py test.dat
WRITING: pickle (elkcip)
WRITING: cPickle (elkciPc)
WRITING: last (tsal)
一个在读取结果腌渍对象失败的简化尝试:
try:
import cPickle as pickle
except:
import pickle
import pprint
from StringIO import StringIO
import sys
try:
filename = sys.argv[1]
except IndexError:
raise RuntimeError('Please specify a filename as an argument to %s' % sys.argv[0])
in_s = open(filename, 'rb')
try:
# 读取数据
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print 'READ: %s (%s)' % (o.name, o.name_backwards)
finally:
in_s.close()
该版本失败的原因在于没有 SimpleObject 类可用:
$ python pickle_load_from_file_1.py test.dat
Traceback (most recent call last):
File "pickle_load_from_file_1.py", line 52, in <module>
o = pickle.load(in_s)
AttributeError: 'module' object has no attribute 'SimpleObject'
正确的版本从原脚本中导入 SimpleObject ,可成功运行。
添加:
from pickle_dump_to_file_1 import SimpleObject
至导入列表的尾部,接着重新运行该脚本:
$ python pickle_load_from_file_2.py test.dat
READ: pickle (elkcip)
READ: cPickle (elkciPc)
READ: last (tsal)
当腌渍有值的数据类型不能被腌渍时(套接字、文件句柄(file handles)、数据库连接等之类的),有一些特别的考虑。因为使用值而不能被腌渍的类,可以定义 __getstate__() 和 __setstate__() 来返回状态(state)的一个子集,才能被腌渍。新式类(New-style classes)也可以定义__getnewargs__(),该函数应当返回被传递至类内存分配器(the class memory allocator)(C.__new__())的参数。使用这些新特性的更多细节,包含在标准库文档中。
环形引用(Circular References)
pickle协议(pickle protocol)自动处理对象间的环形引用,因此,即使是很复杂的对象,你也不用特别为此做什么。考虑下面这个图:
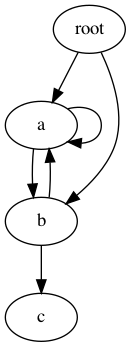
上图虽然包括几个环形引用,但也能以正确的结构腌渍和重新读取(reloaded)。
import pickle
class Node(object):
"""
一个所有结点都可知它所连通的其它结点的简单有向图。
"""
def __init__(self, name):
self.name = name
self.connections = []
return
def add_edge(self, node):
"创建两个结点之间的一条边。"
self.connections.append(node)
return
def __iter__(self):
return iter(self.connections)
def preorder_traversal(root, seen=None, parent=None):
"""产生器(Generator )函数通过一个先根遍历(preorder traversal)生成(yield)边。"""
if seen is None:
seen = set()
yield (parent, root)
if root in seen:
return
seen.add(root)
for node in root:
for (parent, subnode) in preorder_traversal(node, seen, root):
yield (parent, subnode)
return
def show_edges(root):
"打印图中的所有边。"
for parent, child in preorder_traversal(root):
if not parent:
continue
print '%5s -> %2s (%s)' % (parent.name, child.name, id(child))
# 创建结点。
root = Node('root')
a = Node('a')
b = Node('b')
c = Node('c')
# 添加边。
root.add_edge(a)
root.add_edge(b)
a.add_edge(b)
b.add_edge(a)
b.add_edge(c)
a.add_edge(a)
print 'ORIGINAL GRAPH:'
show_edges(root)
# 腌渍和反腌渍该图来创建
# 一个结点集合。
dumped = pickle.dumps(root)
reloaded = pickle.loads(dumped)
print
print 'RELOADED GRAPH:'
show_edges(reloaded)
重新读取的诸多节点(译者注:对应图中的圆圈)不再是同一个对象,但是节点间的关系保持住了,而且读取的仅仅是带有多个引用的对象的一个拷贝。上面所说的可以通过测试各节点在pickle处理前和之后的id()值来验证。
$ python pickle_cycle.py
ORIGINAL GRAPH:
root -> a (4299721744)
a -> b (4299721808)
b -> a (4299721744)
b -> c (4299721872)
a -> a (4299721744)
root -> b (4299721808)
RELOADED GRAPH:
root -> a (4299722000)
a -> b (4299722064)
b -> a (4299722000)
b -> c (4299722128)
a -> a (4299722000)
root -> b (4299722064)
原文 pickle and cPickle – Python object serialization - Python Module of the Week 的后半部分。
Python 的开发环境的更多相关文章
- windows和linux中搭建python集成开发环境IDE——如何设置多个python环境
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 【转】windows和linux中搭建python集成开发环境IDE
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 【转】linux和windows下安装python集成开发环境及其python包
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- Python虚拟开发环境
最近,一直在不同版本的Python之间来回折腾,发现了几个Python虚拟开发环境工具,具体如下: 1. Virtualenv,可以指定开发环境的Python版本.继承已有开发环境配置,virtual ...
- [转]virtualenv建立多个Python独立开发环境
不同的人喜欢用不同的方式建立各自的开发环境,但在几乎所有的编程社区,总有一个(或一个以上)开发环境让人更容易接受. 使用不同的开发环境虽然没有什么错误,但有些环境设置更容易进行便利的测试,并做一些重复 ...
- 西秦的ACE-Python教程 一、Python本地开发环境部署
西秦的ACE-Python教程 一.Python本地开发环境部署 西秦 级别: 论坛版主 发帖 1357 云币 2782 加关注 写私信 只看楼主 更多操作楼主 发表于: 10-10 ...
- 在windows下用eclipse + pydev插件来配置python的开发环境
在windows下用eclipse + pydev插件来配置python的开发环境 一.安装 python 可以到网上下个Windows版的python,官网为:https://www.python. ...
- centos6.5下Python IDE开发环境搭建
自由不是想做什么就做什么,而是想不做什么就不做什么. ---摘抄于2016/11/30晚 之前学习了一段时间的Python,但所有部署都在windows上.正赶上最近在学习liux,以后 ...
- Python GUI开发环境的搭建
原文:Python GUI开发环境的搭建 最近对Python的开发又来了兴趣,对于Python的开发一直停留在一个表面层的认识,玩的部分比较大. Python的入手简单,语法让人爱不释手,在网络通信方 ...
- Python集成开发环境(Eclipse+Pydev)
刚開始学习python,就用Editplus, Notepad++来写小程序, 后来接触了Sublime Text2.认为很不错,没事写写代码.就用编辑器Sublime Text2,最好再配搭一个ap ...
随机推荐
- 为MVC 添加下载权限
今天碰到一个错误,极其郁闷,本地开发和本地部署测试没有问题,但是放到阿里云上,出现了权限问题. 报错:ASP.NET 无权访问所请求的资源.请考虑对 ASP.NET 请求标识授予. 参考网上很多资料, ...
- PowerShell中调用外部程序和进程操作命令例子
学习PowerShell,我们不指望通过C#编程去搞定所有事情,我们应该记住cmd.exe或者说批处理给我们留下的宝贵财富——通过调用外部程序去解决问题.调用了外部程序,势必就要对进程进行管理,这就是 ...
- smarty 从配置文件读取变量
smarty变量分3种: Variables [变量] Variables assigned from PHP [从PHP分配的变量] Variables loaded from config fil ...
- Html.DropDownList的用法
直接上代码 页面代码 <td> <%= Html.DropDownList("selCity") %> </td> controller里面的代 ...
- ZZY的宠物
Description ZZY领养了一对刚刚出生的不知名小宠物..巨萌巨可爱!!...小宠物的生命为5个单位时间并且不会在中间出意外翘辫子(如: 从0出生能活到5但活不到6)..小宠物经过2个单位时间 ...
- HTML5 拼图游戏
点击之后被选中的切片会变为透明 源代码 点击打开链接
- hdu 5424 Rikka with Graph II(dfs+哈密顿路径)
Problem Description As we know, Rikka is poor at math. Yuta is worrying about this situation, so h ...
- hdu 4869 Turn the pokers(组合数+费马小定理)
Problem Description During summer vacation,Alice stay at home for a long time, with nothing to do. S ...
- (转)iOS7界面设计规范(8) - UI基础 - 术语和措辞
讨厌周一,讨厌一周.今天中午交互组聚餐,却很开心:大家都是很厉害的人,你可以感到他们身上的能量,可以感到有些什么东西正在推着自己尽力向前走.这是一种很健康的状态,同时也很难得,自然越发需要珍惜.从无到 ...
- ffmpeg + sdl -03 简单音频播放器实现
没办法,工作中遇到了问题. 目前NEC EMMA的架构如下: 从USB读入文件 -> 文件分析并提取Packet中的Payload Data -> NEC HANDLE AVTrans ...