Amazon Redshift and Massively Parellel Processing
Today, Yelp held a tech talk in Columbia University about the data warehouse adopted by Yelp.
Yelp used Amazon Redshift as data warehouse.
There are several features for Redshift:
1. Massively Parellel Processing
2. SQL access
3. Column-based Datastore
Benefits are:
1. Data is structured, accessible and well documented.
2. Architecture allows for easy extensibility and sharing across teams.
3. Allows use of entire SQL-compatible tool ecosystem.
Details:
Massively Parellel Processing (MMP)
Traditional BigData always uses Hadoop + MapReduce. MapReduce's native control mechanism is Java code (to implement the Map and Reduce logic), whereas MPP products are queried with SQL(Structural Query Language). You can refer detail here.
Below is the structure for implementing MMP.
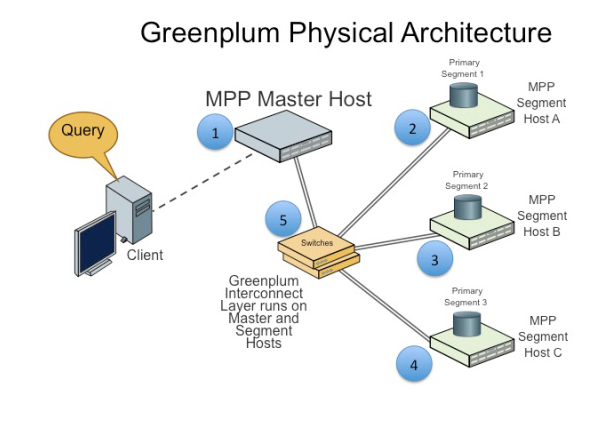
Similarly, Data is distributed across each segment database to achieve data and processing parallelism. This is achieved by creating a database table with DISTRIBUTED BY clause. By using this clause data is automatically distributed across segment databases. (referrence: Introduction to MMP)
Typical query sentence in MMP

Column-based Datastore
Enables sparse table definitions
Enables compact storage
Improve scanning/filtering
(Benefits: wiki)
Column-based Datastore
- Column-oriented organizations are more efficient when an aggregate needs to be computed over many rows but only for a notably smaller subset of all columns of data, because reading that smaller subset of data can be faster than reading all data.
- Column-oriented organizations are more efficient when new values of a column are supplied for all rows at once, because that column data can be written efficiently and replace old column data without touching any other columns for the rows.
- Row-oriented organizations are more efficient when many columns of a single row are required at the same time, and when row-size is relatively small, as the entire row can be retrieved with a single disk seek.
- Row-oriented organizations are more efficient when writing a new row if all of the row data is supplied at the same time, as the entire row can be written with a single disk seek.
In practice, row-oriented storage layouts are well-suited for OLTP-like workloads which are more heavily loaded with interactive transactions. Column-oriented storage layouts are well-suited for OLAP-like workloads (e.g., data warehouses) which typically involve a smaller number of highly complex queries over all data (possibly terabytes).
Amazon Redshift and Massively Parellel Processing的更多相关文章
- Amazon Redshift数据库
Amazon Redshift介绍 Amazon Redshift是一种可轻松扩展的完全托管型PB级数据仓库,它通过使用列存储技术和并行化多个节点的查询来提供快速的查询性能,使您能够更高效的分析现有数 ...
- Power BI连接至Amazon Redshift
一直在使用Power BI连接至MongoDB中,但效果一直不是太理想,今天使用另一种方法,将MongoDB中的数据通过Azure Data Factory转入Amazon Redshift中,而在P ...
- amazon redshift 分析型数据库特点——本质还是列存储
Amazon Redshift 是一种快速且完全托管的 PB 级数据仓库,使您可以使用现有的商业智能工具经济高效地轻松分析您的所有数据.从最低 0.25 USD 每小时 (不承担任何义务) 直到每年每 ...
- Amazon Redshift数据迁移到MaxCompute
Amazon Redshift数据迁移到MaxCompute Amazon Redshift 中的数据迁移到MaxCompute中经常需要先卸载到S3中,再到阿里云对象存储OSS中,大数据计算服务Ma ...
- POWER BI 基于 ODBC 数据源的配置刷新-以Amazon Redshift为例
POWER BI 基于 ODBC 数据源的配置刷新-以Amazon Redshift为例 Powerbi 有多种数据源连接,可以使用它们连接到不同数据源. 如果在 Power BI Desktop 的 ...
- Amazon Redshift and the Case for Simpler Data Warehouses
Redshift是Amazon一个商业产品上的进化 但并不是技术的进化,他使用的无非都是传统数仓领域的技术 如果说创新,就是大量使用Amazon本身的云服务的云原生架构,大大提升的产品的迭代速度,可维 ...
- Python 如何连接并操作 Aws 上 PB 级云数据仓库 Redshift
Python 如何连接并操作 Aws 上 PB 级云数据仓库 Redshift 一.简介 Amazon Redshift 是一个快速.可扩展的数据仓库,可以简单.经济高效地分析数据仓库和数据湖中的所有 ...
- Qwiklab'实验-DynamoDB, Redshift, Elasticsearch'
title: AWS之Qwiklab subtitle: 4. Qwiklab'实验-Amazon DynamoDB, Amazon Redshift, Elasticsearch Service' ...
- Massively parallel supercomputer
A novel massively parallel supercomputer of hundreds of teraOPS-scale includes node architectures ba ...
随机推荐
- Quartus DSE 初步应用
介绍 Design Space Explorer (DSE) is a program that automates the process of finding the optimal collec ...
- Find Peak Element 解答
Question A peak element is an element that is greater than its neighbors. Given an input array where ...
- 《Two Days DIV + CSS》读书笔记——CSS控制页面方式
1.1 你必须知道的知识 (其中包括1.1.1 DIV + CSS的叫法解释:1.1.2 DIV + CSS 名字的误区:以及1.1.3 W3C简介.由于只是背景知识,跳过该章.) 1.2 你必须掌握 ...
- python高级编程之描述符与属性03
# -*- coding: utf-8 -*- # python:2.x __author__ = 'Administrator' #属性Property #提供了一个内建描述符类型,它知道如何将一个 ...
- J2EE之普通类载入web资源文件的方法
在WEB中普通类并不能像Servlet那样通过this.getServletContext().getResourceAsStream()获取web资源,须要通过类载入器载入,这里有两种方式,这两种方 ...
- Git 提供篇
1. Git自动补全 假使你使用命令行工具运行Git命令,那么每次手动输入各种命令是一件很令人厌烦的事情.为了解决这个问题,你可以启用Git的自动补全功能,完成这项工作仅需要几分钟. 为了得到这个脚本 ...
- iOS:UI系列之UINavigationController
又到了总结的时间了,突然间感觉时间过得好快啊, 总觉的时间不够用,但是这也没办法啊, 只有自己挤时间了,虽然是零基础,但是这并不能代表什么啦,只要努力,收获总还是有的, 同时我也相信广大的博友肯定也有 ...
- JAVA反射机制示例,读取excel数据映射到JAVA对象中
import java.beans.PropertyDescriptor; import java.io.File; import java.io.FileInputStream; import ja ...
- [HeadFirst-JSPServlet学习笔记][第三章:实战MVC]
第三章 实战MVC J2EE如何集成一切 Java2企业版(Java 2 Enterprise Editon,J2EE)是一种超级规范.规定了servlets2.4,JSP2.0,EJB2.1(Ent ...
- break,continue,return 区别
using System;using System.Collections.Generic;using System.Text; namespace breakcontinue_test{ cl ...