Netty内存池及命中缓存的分配
内存池的内存规格:
在前面的源码分析过程中,关于内存规格大小我们应该还有些印象。其实在Netty 内存池中主要设置了四种规格大小的内存:tiny 是指0-512Byte 之间的规格大小,small 是指512Byte-8KB 之间的规格大小,normal 是指8KB-16MB 之间的规格大小,huge 是指16MB 以上。为什么Netty 会选择这些值作为一个分界点呢?其实在Netty 底层还有一个内存单位的封装,为了更高效地管理内存,避免内存浪费,把每一个区间的内存规格由做了细分。默认情况下,Netty将内存规格划分为4 个部分。Netty 中所有的内存申请是以Chunk 为单位向内存申请的,大小为16M,后续的所有内存分配都是在这个Chunk 里面的操作。8K 对应的是一个Page,一个Chunk 会以Page 为单位进行切分,8K 对应Chunk被划分为2048 个Page。小于8K 的对应的是SubPage。例如:我们申请的一段内存空间只有1K,却给我们分配了一个Page,显然另外7K 就会被浪费,所以就继续把Page 进行划分,来节省空间。如下图所示:

至此,小伙伴们应该已经基本清楚Netty 的内存池缓存管理机制了。
命中缓存的分配:
前面我们简单分析了directArena 内存分配大概流程, 知道其先命中缓存, 如果命中不到, 则区分配一款连续内存。现在开始带大家剖析命中缓存的相关逻辑。前面我们也讲到PoolThreadCache 中维护了三个缓存数组(实际上是六个, 这里仅仅以Direct 为例, Heap 类型的逻辑是一样的): tinySubPageDirectCaches, smallSubPageDirectCaches, 和normalDirectCaches 分别代表tiny 类型, small 类型和normal 类型的缓存数组)。这三个数组保存在PoolThreadCache的成员变量中,其实是在构造方法中进行了初始化:
final class PoolThreadCache {
final PoolArena<byte[]> heapArena;
final PoolArena<ByteBuffer> directArena;
static final int numTinySubpagePools = 512 >>> 4;// 32
private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches;
private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
private final MemoryRegionCache<byte[]>[] normalHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
......//参数来自PooledByteBufAllocator的属性
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena,
int tinyCacheSize, int smallCacheSize, int normalCacheSize,
int maxCachedBufferCapacity, int freeSweepAllocationThreshold) {
.......if (directArena != null) {
tinySubPageDirectCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
smallSubPageDirectCaches = createSubPageCaches(
smallCacheSize, directArena.numSmallSubpagePools, SizeClass.Small);
numShiftsNormalDirect = log2(directArena.pageSize);
normalDirectCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, directArena);
directArena.numThreadCaches.getAndIncrement();
} else {
// No directArea is configured so just null out all caches
tinySubPageDirectCaches = null;
smallSubPageDirectCaches = null;
normalDirectCaches = null;
numShiftsNormalDirect = -1;
}
if (heapArena != null) {
// Create the caches for the heap allocations
tinySubPageHeapCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
smallSubPageHeapCaches = createSubPageCaches(
smallCacheSize, heapArena.numSmallSubpagePools, SizeClass.Small);
numShiftsNormalHeap = log2(heapArena.pageSize);
normalHeapCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, heapArena);
heapArena.numThreadCaches.getAndIncrement();
} else {
// No heapArea is configured so just null out all caches
tinySubPageHeapCaches = null;
smallSubPageHeapCaches = null;
normalHeapCaches = null;
numShiftsNormalHeap = -1;
}
// The thread-local cache will keep a list of pooled buffers which must be returned to
// the pool when the thread is not alive anymore.
ThreadDeathWatcher.watch(thread, freeTask);
}
}
我这以tiny 类型为例跟到createSubPageCaches 方法中:
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches, SizeClass sizeClass) {
if (cacheSize > 0) {
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
// TODO: maybe use cacheSize / cache.length
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass);
}
return cache;
} else {
return null;
}
}
从代码中看出,其实就是创建了一个缓存数组, 这个缓存数组的长度,也就是numCaches, 在不同的类型, 这个长度不一样, tiny 类型长度是32, small 类型长度为4, normal 类型长度为3。我们知道, 缓存数组中每个节点代表一个缓存对象, 里面维护了一个队列, 队列大小由PooledByteBufAllocator 类中的tinyCacheSize, smallCacheSize,normalCacheSize 属性决定的。其中每个缓存对象, 队列中缓存的ByteBuf 大小是固定的, netty 将每种缓冲区类型分成了不同长度规格, 而每个缓存中的队列缓存的ByteBuf 的长度, 都是同一个规格的长度, 而缓冲区数组的长度, 就是规格的数量。
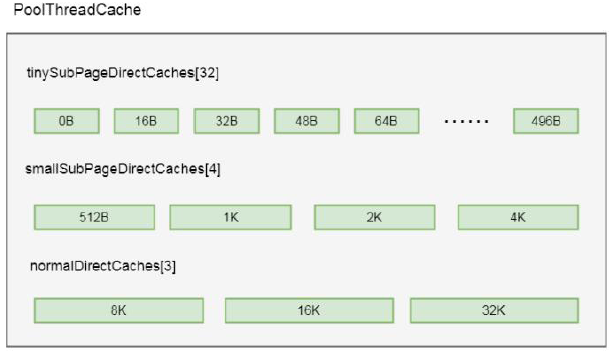
比如:在tiny 类型中,Netty 将其长度分成32 个规格, 每个规格都是16 的整数倍, 也就是包含0Byte, 16Byte,32Byte, 48Byte, 64Byte, 80Byte, 96Byte......496Byte 总共32 种规格, 而在其缓存数组tinySubPageDirectCaches 中, 这每一种规格代表数组中的一个缓存对象缓存的ByteBuf 的大小, 我们以tinySubPageDirectCaches[1]为例(这里下标选择1 是因为下标为0 代表的规格是0Byte, 其实就代表一个空的缓存, 这里不进行举例), 在tinySubPageDirectCaches[1]的缓存对象中所缓存的ByteBuf 的缓冲区长度是16Byte, 在tinySubPageDirectCaches[2]中缓存的ByteBuf 长度都为32Byte, 以此类推, tinySubPageDirectCaches[31]中缓存的ByteBuf 长度为496Byte。其具体类型规则的配置如下(可以通过Dbug验证):
- tiny:总共32 个规格, 均是16 的整数倍, 0Byte, 16Byte, 32Byte, 48Byte, 64Byte, 80Byte, 96Byte......496Byte;
- small:4 种规格, 512Byte, 1KB, 2KB, 4KB;
- nomal:3 种规格, 8KB, 16KB,32KB。
如此,我们得出结论PoolThreadCache 中缓存数组的数据结构如下图所示:
在基本了解缓存数组的数据结构之后, 我们再继续剖析在缓冲中分配内存的逻辑,回到PoolArena 的allocate()方法中:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
//规格化 reqCapacity=256
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
//判断是不是tiny
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512//缓存分配
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}//通过tinyIdx 拿到tableIdx
tableIdx = tinyIdx(normCapacity);
//subpage 的数组
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
//拿到对应的节点
final PoolSubpage<T> head = table[tableIdx];
synchronized (head) {
final PoolSubpage<T> s = head.next;
//默认情况下, head 的next 也是自身
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
if (normCapacity <= chunkSize) {
//首先在缓存上进行内存分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}//分配不成功, 做实际的内存分配
allocateNormal(buf, reqCapacity, normCapacity);
} else {//大于这个值, 就不在缓存上分配
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
首先通过normalizeCapacity 方法进行内存规格化,我们跟到normalizeCapacity()方法中:
int normalizeCapacity(int reqCapacity) {
// reqCapacity = 256
if (reqCapacity < 0) {
throw new IllegalArgumentException("capacity: " + reqCapacity + " (expected: 0+)");
}
if (reqCapacity >= chunkSize) {
return reqCapacity;
}
// 如果 >tiny
if (!isTiny(reqCapacity)) { // >= 512
// Doubled 256
// 找一个2 的幂次方的数值, 确保数值大于等于reqCapacity
int normalizedCapacity = reqCapacity;
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
return normalizedCapacity;
}
// Quantum-spaced 如果是16 的倍数
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
// 不是16 的倍数, 变成最大小于当前值的值+16
return (reqCapacity & ~15) + 16;
}
上面代码中if (!isTiny(reqCapacity)) 代表如果大于tiny 类型的大小, 也就是512, 则会找一个2 的幂次方的数值, 确保这个数值大于等于reqCapacity。如果是tiny, 则继续往下if ((reqCapacity & 15) == 0) 这里判断如果是16 的倍数, 则直接返回。如果不是16 的倍数, 则返回(reqCapacity & ~15) + 16 , 也就是变成最小大于当前值的16 的倍数值。从上面规格化逻辑看出, 这里将缓存大小规格化成固定大小, 确保每个缓存对象缓存的ByteBuf 容量统一。回到allocate()方法: if(isTinyOrSmall(normCapacity)) 这里是根据规格化后的大小判断是否tiny 或者small 类型, 我们跟进去:
// capacity < pageSize
boolean isTinyOrSmall(int normCapacity) {
return (normCapacity & subpageOverflowMask) == 0;
}
这个方法是判断如果normCapacity 小于一个page 的大小, 也就是8k 代表其实tiny 或者small。继续看allocate()方法,如果当前大小是tiny 或者small, 则isTiny(normCapacity)判断是否是tiny 类型, 跟进去:
// normCapacity < 512
static boolean isTiny(int normCapacity) {
return (normCapacity & 0xFFFFFE00) == 0;
}
这个方法是判断如果小于512, 则认为是tiny。再继续看allocate()方法:如果是tiny, 则通过cache.allocateTiny(this, buf, reqCapacity, normCapacity)在缓存上进行分配。我们就以tiny 类型为例, 分析在缓存上分配ByteBuf 的流:allocateTiny 是缓存分配的入口。我们跟进去, 进入到了PoolThreadCache 的allocateTiny()方法中:
/**
* Try to allocate a tiny buffer out of the cache. Returns {@code true} if successful {@code false} otherwise
*/
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
这里有个方法cacheForTiny(area, normCapacity), 这个方法的作用是根据normCapacity 找到tiny 类型缓存数组中的一个缓存对象。我们跟进到cacheForTiny()方法:
private MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {
int idx = PoolArena.tinyIdx(normCapacity);
if (area.isDirect()) {
return cache(tinySubPageDirectCaches, idx);
}
return cache(tinySubPageHeapCaches, idx);
}
PoolArena.tinyIdx(normCapacity)是找到tiny 类型缓存数组的下标。继续跟tinyIdx()方法:
static int tinyIdx(int normCapacity) {
return normCapacity >>> 4;
}
这里相当于直接将normCapacity 除以16, 通过前面的内容我们知道, tiny 类型缓存数组中每个元素规格化的数据都是16 的倍数, 所以通过这种方式可以找到其下标, 参考图5-2, 如果是16Byte 会拿到下标为1 的元素, 如果是32Byte 则会拿到下标为2 的元素。
回到cacheForTiny()方法中: if (area.isDirect()) 这里判断是否是分配堆外内存, 因为我们是按照堆外内存进行举例, 所以这里为true。再继续跟到cache(tinySubPageDirectCaches, idx)方法:
private static <T> MemoryRegionCache<T> cache(MemoryRegionCache<T>[] cache, int idx) {
if (cache == null || idx > cache.length - 1) {
return null;
}
return cache[idx];
}
这里我们看到直接通过下标的方式拿到了缓存数组中的对象,回到PoolThreadCache 的allocateTiny()方法中:
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {
if (cache == null) {
// no cache found so just return false here
return false;
}
boolean allocated = cache.allocate(buf, reqCapacity);
if (++ allocations >= freeSweepAllocationThreshold) {
allocations = 0;
trim();
}
return allocated;
}
看到cache.allocate(buf, reqCapacity) 进行继续进行分配。再继续往里跟, 来到内部类MemoryRegionCache 的allocate(PooledByteBuf<T> buf, int reqCapacity)方法:
public final boolean allocate(PooledByteBuf<T> buf, int reqCapacity) {
Entry<T> entry = queue.poll();
if (entry == null) {
return false;
}
initBuf(entry.chunk, entry.handle, buf, reqCapacity);
entry.recycle();
// allocations is not thread-safe which is fine as this is only called from the same thread all time.
++ allocations;
return true;
}
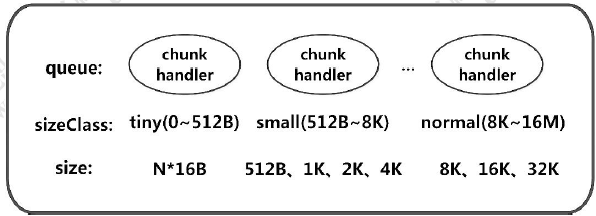
在这个方法中,首先通过queue.poll()这种方式弹出一个entry, 我们之前的小节分析过, MemoryRegionCache 维护着一个队列, 而队列中的每一个值是一个entry。我们简单看下Entry 这个类:
static final class Entry<T> {
final Handle<Entry<?>> recyclerHandle;
PoolChunk<T> chunk;
long handle = -1;
Entry(Handle<Entry<?>> recyclerHandle) {
this.recyclerHandle = recyclerHandle;
}
void recycle() {
chunk = null;
handle = -1;
recyclerHandle.recycle(this);
}
}
我们重点关注chunk 和handle 的这两个属性, chunk 代表一块连续的内存, 我们之前简单介绍过, netty 是通过chunk为单位进行内存分配的, 我们后面会对chunk 进行详细剖析。handle 相当于一个指针, 可以唯一定位到chunk 里面的一块连续的内存, 之后也会详细分析。这样, 通过chunk 和handle 就可以定位ByteBuf 中指定一块连续内存, 有关ByteBuf 相关的读写, 都会在这块内存中进行。
弹出entry 之后, 通过initBuf(entry.chunk, entry.handle, buf, reqCapacity)这种方式给ByteBuf 初始化, 这里参数传入当前Entry 的chunk 和hanle 。因为我们知道之前在初始化tiny数组的时候缓存对象类型是SubPageMemoryRegionCache 类型, 所以我们继续跟到SubPageMemoryRegionCache 类的initBuf(entry.chunk,entry.handle, buf, reqCapacity)方法中:
@Override
protected void initBuf(
PoolChunk<T> chunk, long handle, PooledByteBuf<T> buf, int reqCapacity) {
chunk.initBufWithSubpage(buf, handle, reqCapacity);
}
//PoolChunk 类中的方法
void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int reqCapacity) {
initBufWithSubpage(buf, handle, bitmapIdx(handle), reqCapacity);
}
上面代码中,调用了bitmapIdx()方法,有关bitmapIdx(handle)相关的逻辑, 会在后续的章节进行剖析, 这里继续往里跟,看initBufWithSubpage()的逻辑:
private void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int bitmapIdx, int reqCapacity) {
assert bitmapIdx != 0;
int memoryMapIdx = memoryMapIdx(handle);
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage.doNotDestroy;
assert reqCapacity <= subpage.elemSize;
buf.init(
this, handle,
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize, reqCapacity, subpage.elemSize,
arena.parent.threadCache());
}
我们先关注init 方法, 因为我们是以PooledUnsafeDirectByteBuf 为例, 所以这里走的是PooledUnsafeDirectByteBuf的init()方法。进入init()方法:
void init(PoolChunk<ByteBuffer> chunk, long handle, int offset, int length, int maxLength,
PoolThreadCache cache) {
super.init(chunk, handle, offset, length, maxLength, cache);
initMemoryAddress();
}
首先调用了父类的init 方法, 继续跟进去:
void init(PoolChunk<T> chunk, long handle, int offset, int length, int maxLength, PoolThreadCache cache) {
//初始化
assert handle >= 0;
assert chunk != null;
//在哪一块内存上进行分配的
this.chunk = chunk;
//这一块内存上的哪一块连续内存
this.handle = handle;
memory = chunk.memory;
this.offset = offset;
this.length = length;
this.maxLength = maxLength;
tmpNioBuf = null;
this.cache = cache;
}
上面的代码就是将PooledUnsafeDirectByteBuf 的各个属性进行了初始化。this.chunk = chunk 这里初始化了chunk, 代表当前的ByteBuf 是在哪一块内存中分配的。this.handle = handle 这里初始化了handle, 代表当前的ByteBuf 是这块内存的哪个连续内存。有关offset 和length, 我们会在之后再分析, 在这里我们只需要知道, 通过缓存分配ByteBuf, 我们只需要通过一个chunk 和handle, 就可以确定一块内存,以上就是通过缓存分配ByteBuf 对象的全过程。现在,我们回到MemoryRegionCache 的allocate(PooledByteBuf<T> buf, int reqCapacity)方法:
public final boolean allocate(PooledByteBuf<T> buf, int reqCapacity) {
Entry<T> entry = queue.poll();
if (entry == null) {
return false;
}
initBuf(entry.chunk, entry.handle, buf, reqCapacity);
entry.recycle();
// allocations is not thread-safe which is fine as this is only called from the same thread all time.
++ allocations;
return true;
}
再继续往下看:entry.recycle()这步是将entry 对象进行回收, 因为entry 对象弹出之后没有再被引用, 可能gc 会将entry 对象回收, netty 为了将对象进行循环利用, 就将其放在对象回收站进行回收。我们跟进recycle()方法:
void recycle() {
chunk = null;
handle = -1;
recyclerHandle.recycle(this);
}
chunk = null 和handle = -1 表示当前Entry 不指向任何一块内存。recyclerHandle.recycle(this) 将当前entry 回收。以上就是命中缓存的流程, 因为这里我们是假设缓中有值的情况下进行分配的, 如果第一次分配, 缓存中是没有值的,最后,我们简单总结一下MemoryRegionCache 对象的基本结构,如下图所示:
Netty内存池及命中缓存的分配的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第6节: 命中缓存的分配
Netty源码分析第6章: ByteBuf 第六节: 命中缓存的分配 上一小节简单分析了directArena内存分配大概流程, 知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一小节带 ...
- Netty内存池ByteBuf 内存回收
内存池ByteBuf 内存回收: 在前面的章节中我们有提到, 堆外内存是不受JVM 垃圾回收机制控制的, 所以我们分配一块堆外内存进行ByteBuf 操作时, 使用完毕要对对象进行回收, 本节就以Po ...
- Netty内存池的整体架构
一.为什么要实现内存管理? Netty 作为底层网络通信框架,网络IO读写必定是非常频繁的操作,考虑到更高效的网络传输性能,堆外内存DirectByteBuffer必然是最合适的选择.堆外内存在 JV ...
- Netty内存池
参考资料:http://blog.csdn.net/youaremoon/article/details/47910971 主要思想:buddy allocation,jemalloc
- 感悟优化——Netty对JDK缓冲区的内存池零拷贝改造
NIO中缓冲区是数据传输的基础,JDK通过ByteBuffer实现,Netty框架中并未采用JDK原生的ByteBuffer,而是构造了ByteBuf. ByteBuf对ByteBuffer做了大量的 ...
- PooledByteBuf内存池-------这个我现在不太懂
转载自:http://blog.csdn.net/youaremoon/article/details/47910971 http://blog.csdn.net/youar ...
- 重写boost内存池
最近在写游戏服务器网络模块的时候,需要用到内存池.大量玩家通过tcp连接到服务器,通过大量的消息包与服务器进行交互.因此要给每个tcp分配收发两块缓冲区.那么这缓冲区多大呢?通常游戏操作的消息包都很小 ...
- nginx——内存池篇
nginx--内存池篇 一.内存池概述 内存池是在真正使用内存之前,预先申请分配一定数量的.大小相等(一般情况下)的内存块留作备用.当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续 ...
- 定长内存池之BOOST::pool
内存池可有效降低动态申请内存的次数,减少与内核态的交互,提升系统性能,减少内存碎片,增加内存空间使用率,避免内存泄漏的可能性,这么多的优点,没有理由不在系统中使用该技术. 内存池分类: 1. ...
随机推荐
- 搭建Eclipse+pydev+python2.7.5+django1.5.1+mysql5.0.45平台
mysqldb 下载地址 http://sourceforge.net/projects/mysql-python/ or https://pypi.python.org/pypi/MySQL-pyt ...
- 从后台看python--为什么说python是慢的
python越来越作为一种科学技术研究的语言越来越流行,可是我们经常听到一个问题,python是慢的.那么我们从后台分析一下,为什么python是慢的. python是一种动态类型,解释型语言,它的值 ...
- linux 配置 Sersync
[root@SERSYNC sersync]# cp conf/confxml.xml conf/confxml.xml.bak.$(date +%F) [root@SERSYNC sersync]# ...
- nodejs 文件读写
文件读取: //例如: fs.readFile 就是用来读取文件的 //1. 使用require方法来加载 fs 核心模块 var fs = require('fs'); /* *2. 读取文件 * ...
- 一、touch.js
一.touch.js 1.引用链接: <script src="https://cdn.bootcss.com/touchjs/0.2.14/touch.min.js"> ...
- java中的Excel导出功能
public void exportExcel(Long activityId, HttpServletResponse response) throws IOException { // 获取统计报 ...
- Integer类的缓存机制
一.Integer类的缓存机制 我们查看Integer的源码,就会发现里面有个静态内部类. public static Integer valueOf(int i) { assert IntegerC ...
- Python---基础---数据类型的内置函数
2019-05-23 ---------------------------- 一. #数据类型的内置函数Python有哪些数据类型?Number 数值型string 字符型list ...
- 利用已控的标边界一台机器的 beacon对目标内网进行各种存活探测
本节的知识摘要: 基于常规 tcp / udp 端口扫描的内网存活探测 基于 icmp 的内网存活探测 基于 arp 的内网存活探测 加载外部脚本进行的各种存活探测 基础环境说明:: WebServe ...
- django数据库迁移相关【sqlite3迁移到MySQL】(django2.0.3测试通过)
前言 项目部署到服务器之后,用的数据库还是sqlite3. 发现一些问题,sqlite3是小巧,但是服务器上查看数据库比较费劲,不能直观看到数据.可是我们经常需要即时.直观查看数据,这就用到MySQL ...