python多线程之threading、ThreadPoolExecutor.map
背景:
(多线程执行同一个函数任务)某个应用场景需要从数据库中取出几十万的数据时,需要对每个数据进行相应的操作。逐个数据处理过慢,于是考虑对数据进行分段线程处理:
方法一:使用threading模块
代码:
# -*- coding: utf-8 -*-
import math
import random
import time
from threading import Thread _result_list = [] def split_df():
# 线程列表
thread_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
thread = Thread(target=work, args=(item, _list,))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
count += split_count # 线程同步,等待子线程结束任务,主线程再结束
for _item in thread_list:
_item.join() def work(df, _list):
"""
每个线程执行的任务,让程序随机sleep几秒
:param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
_result_list.append(df) if __name__ == '__main__':
split_df()
print(len(_result_list), _result_list)
测试结果:

方法二:使用ThreadPoolExecutor.map
代码:
# -*- coding: utf-8 -*-
import math
import random
import time
from concurrent.futures import ThreadPoolExecutor def split_list():
# 线程列表
new_list = []
count_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
new_list.append(_list)
count_list.append(count)
count += split_count
return new_list, count_list def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒
:param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
return sleep_time, df, _list def use():
new_list, count_list = split_list()
with ThreadPoolExecutor(max_workers=len(count_list)) as t:
results = t.map(work, new_list, count_list) # 或执行如下两行代码
# pool = ThreadPoolExecutor(max_workers=5)
# 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中
# results = pool.map(work, new_list, count_list) # map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则 多个参数的 数据长度相同;
# 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1)
# map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果
print(type(results))
# 如下2行 会等待线程任务执行结束后 再执行其他代码
for ret in results:
print(ret)
print('thread execute end!') if __name__ == '__main__':
use()
测试结果:
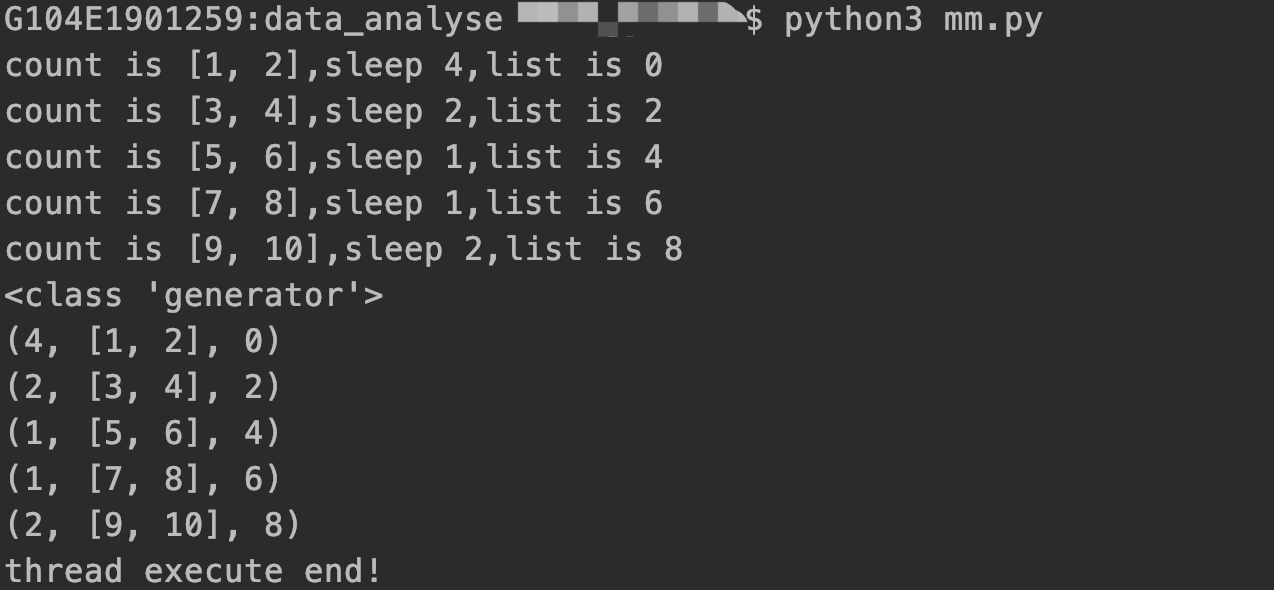
参考链接:https://www.cnblogs.com/rgcLOVEyaya/p/RGC_LOVE_YAYA_1103_3days.html
python多线程之threading、ThreadPoolExecutor.map的更多相关文章
- python多线程之Threading
什么是线程? 线程是操作系统内核调度的基本单位,一个进程中包含一个或多个线程,同一个进程内的多个线程资源共享,线程相比进程是“轻”量级的任务,内核进行调度时效率更高. 多线程有什么优势? 多线程可以实 ...
- “死锁” 与 python多线程之threading模块下的锁机制
一:死锁 在死锁之前需要先了解的概念是“可抢占资源”与“不可抢占资源”[此处的资源可以是硬件设备也可以是一组信息],因为死锁是与不可抢占资源有关的. 可抢占资源:可以从拥有他的进程中抢占而不会发生副作 ...
- python多线程之threading模块
threading模块中的对象 其中除了Thread对象以外,还有许多跟同步相关的对象 threading模块支持守护线程的机制 Thread对象 直接调用法 import threading imp ...
- python 线程之 threading(四)
python 线程之 threading(三) http://www.cnblogs.com/someoneHan/p/6213100.html中对Event做了简单的介绍. 但是如果线程打算一遍一遍 ...
- python 线程之 threading(三)
python 线程之 threading(一)http://www.cnblogs.com/someoneHan/p/6204640.html python 线程之 threading(二)http: ...
- python并发编程之threading线程(一)
进程是系统进行资源分配最小单元,线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.进程在执行过程中拥有独立的内存单元,而多个线程共享内存等资源. 系列文章 py ...
- python利用(threading,ThreadPoolExecutor.map,ThreadPoolExecutor.submit) 三种多线程方式处理 list数据
需求:在从银行数据库中取出 几十万数据时,需要对 每行数据进行相关操作,通过pandas的dataframe发现数据处理过慢,于是 对数据进行 分段后 通过 线程进行处理: 如下给出 测试版代码,通过 ...
- python多线程之Condition(条件变量)
#!/usr/bin/env python # -*- coding: utf-8 -*- from threading import Thread, Condition import time it ...
- python多线程之semaphore(信号量)
#!/usr/bin/env python # -*- coding: utf-8 -*- import threading import time import random semaphore = ...
随机推荐
- 【转】unity3d优化总结篇
https://blog.csdn.net/weixin_33733810/article/details/94610167 某些技术或建议有些过时,但也值得参考 另外,关于如何设置不同layer的裁 ...
- [Java]算术表达式求值之一(中序表达式转后序表达式方案)
第二版请见:https://www.cnblogs.com/xiandedanteng/p/11451359.html 入口类,这个类的主要用途是粗筛用户输入的算术表达式: package com.h ...
- Windows 10下怎么远程连接 Ubuntu 16.0.4(小白级教程)
前言: 公司因为用Ruby做开发,所有适用了Ubuntu系统,但是自己笔记本是W10,又不想装双系统,搭建开发环境,便想到倒不如自己远程操控公司电脑,这样在家的时候也可以处理一些问题.故此便有了下面的 ...
- Kettle使用教程之数据同步
数据模型原型如下: 1.表输入,针对最新的数据输入的表 2.目标表,需要更新的表 3.两个表都需要进行排序操作 4.合并,根据id进行合并 5.数据同步(包括更新.插入.删除) 6.点击运行,就可以实 ...
- 安装 Genymotion及其破解版
https://blog.csdn.net/sxk874890728/article/details/82721746 安装 Genymotion及其破解版 2018年09月16日 11:18:09 ...
- Activity 的 36 大难点,你会几个
前言 学 Android 有一段时间了,一直都只顾着学新的东西,最近发现很多平常用的少的东西竟让都忘了,趁着这两天,打算把有关 Activity 的内容以问题的形式梳理出来,也供大家查缺补漏. 本文中 ...
- ENVI-IDL的MATH_DOIT和CF_DOIT函数(对FID和POS参数的讨论)
MATH_DOIT相当于ENVI的band math,可以完成各种波段运算.参数比较简单,EXP为运算公式的字符串,其他参数均为常见参数. CF_DOIT可以将已有的文件保存为ENVI格式文件,相当于 ...
- 意想不到的JavaScript(每日一题2)
问题一: 答案: 解析:
- POJ3585 Accumulation Degree【换根dp】
题目传送门 题意 给出一棵树,树上的边都有容量,在树上任意选一个点作为根,使得往外流(到叶节点,叶节点可以接受无限多的流量)的流量最大. 分析 首先,还是从1号点工具人开始$dfs$,可以求出$dp[ ...
- mysql——多表——外连接查询——左连接、右连接、复合条件查询
), d_id ), name ), age ), sex ), homeadd ) ); ,,,'nan','beijing'); ,,,'nv','hunan'); ,,,'nan','jiang ...