python 并发编程 多路复用IO模型
多路复用IO(IO multiplexing)
这种IO方式为事件驱动IO(event driven IO)。
我们都知道,select/epoll的好处就在于单个进程process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
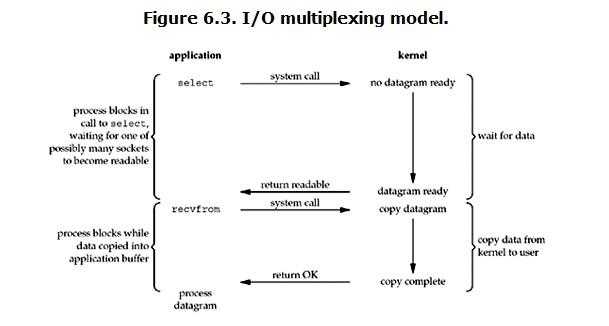
select是多路复用的一种
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,
当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用\(select和recvfrom\),
而blocking IO只调用了一个系统调用\(recvfrom\)。但是,用select的优势在于它可以同时处理多个connection。
多路复用IO比较阻塞IO模型:
1.阻塞IO经历两个阶段 wait data,copy data
2.多路复用3个阶段 wait data,ready copy data, copy data
单连接套接字通信 阻塞IO效率高
多路复用IO select可以代理多个套接字连接,多个套接字通信,多路复用IO效率高
强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,性能高,同时可以检测多个套接字IO行为,不适用于单个连接
select网络IO模型示例
select 检测多个套接字IO行为 accept,recv
IO行为两种:
1.别人给我传数据
2.给别人发送数据
timeout是超时时间
每隔0.5秒去问操作系统准备好数据没有
def select(rlist, wlist, xlist, timeout=None):
pass # [] 传的空列表是出异常的列表
# 返回值3个列表 收列表,发列表,异常列表
rl,wl,xl = select.select(rlist, wlist, [], 0.5)
客户端:
from socket import * client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8000)) while True:
msg = input(">>>:").strip()
if not msg:continue
client.send(msg.encode("utf-8"))
data = client.recv(1024)
print(data.decode("utf-8")) client.close()
服务端代码:
from socket import *
import select server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8000))
server.listen(5)
# 设置socket接口为 非阻塞IO接口
# 默认是True 为阻塞
server.setblocking(False) # 专门存着收消息套接字
rlist = [server,]
# 存放发送消息套接字
wlist = []
# 存放发送的数据
wdata = {}
while True: # 返回值3个列表 收列表,发列表,异常列表
rl,wl,xl = select.select(rlist, wlist, [], 0.5)
print("rl",rl)
print("wl",wl) for sock in rl:
if sock == server:
conn,addr = sock.accept()
rlist.append(conn)
else:
try:
data = sock.recv(1024)
if not data:
sock.close()
rlist.remove(sock)
continue # 收的套接字加到列表
wlist.append(sock)
# 把数据加到字典 做一个 套接字对应数据
wdata[sock] = data.upper() except Exception:
sock.close()
rlist.remove(sock) # 发送数据
for sock in wl:
sock.send(wdata[sock])
wlist.remove(sock)
wdata.pop(sock) server.close()
基于select模块 检测套接字IO行为,实现并发效果
select监听fd变化的过程分析:
用户进程创建socket对象,拷贝监听的fd到内核空间,每一个fd会对应一张系统文件表,内核空间的fd响应到数据后,
就会发送信号给用户进程数据已到;
用户进程再发送系统调用,比如(accept)将内核空间的数据copy到用户空间,同时作为接受数据端内核空间的数据清除,
这样重新监听时fd再有新的数据又可以响应到了(发送端因为基于TCP协议所以需要收到应答后才会清除)。
该模型的优点:
可以同时检测多个套接字,效率比阻塞IO,非阻塞IO高了
相比其他模型,使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多 CPU,同时能够为多客户端提供服务。
如果试图建立一个简单的事件驱动的服务器程序,这个模型有一定的参考价值。
该模型的缺点:
代理的套接字 列表里的多个套接字,需要循环列表 一个个检测,
在代理套接字比较少的情况下,循环比较快。但select代理的套接字非常多的情况下,select随着列表增大,效率就越来越慢
首先select()接口并不是实现“事件驱动”的最好选择。因为当需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄。
很多操作系统提供了更为高效的接口,如linux提供了epoll,BSD提供了kqueue,Solaris提供了/dev/poll,…。
如果需要实现更高效的服务器程序,类似epoll这样的接口更被推荐。遗憾的是不同的操作系统特供的epoll接口有很大差异,
所以使用类似于epoll的接口实现具有较好跨平台能力的服务器会比较困难。
其次,该模型将事件探测和事件响应夹杂在一起,一旦事件响应的执行体庞大,则对整个模型是灾难性的。
epoll是异步方式实现,提交套接字时候,每个套接字身上都绑定一个回调函数,哪个套接字准备好了,就触发回调函数,把自己索引放在单独列表里,对于select来说,只需要去准备好的列表里 根据索引拿到套接字,这样不需要在列表里每个遍历。
epoll不支持windows系统
多路复用IO
python 并发编程 多路复用IO模型的更多相关文章
- python 并发编程 阻塞IO模型
阻塞IO(blocking IO) 在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样: 当用户进程调用了recvfrom这个系统调用,kernel内核就 ...
- python 并发编程 异步IO模型
异步IO(Asynchronous I/O) Linux下的asynchronous IO其实用得不多,从内核2.6版本才开始引入.先看一下它的流程: 用户进程发起read操作之后,立刻就可以开始去做 ...
- Python之网络编程之并发编程的IO模型,
了解新知识之前需要知道的一些知识 同步(synchronous):一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行 #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调 ...
- python网络编程——网络IO模型
1 网络IO模型介绍 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-bl ...
- Python并发编程之IO模型
目录 IO模型介绍 阻塞IO(blocking IO) 非阻塞IO(non-blocking IO) IO多路复用 异步IO IO模型比较分析 selectors模块 一.IO模型介绍 Stevens ...
- python并发编程之IO模型,
了解新知识之前需要知道的一些知识 同步(synchronous):一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行 #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调 ...
- 【并发编程】IO模型
一.要点回顾 为了更好地了解IO模型,我们需要先回顾下几个概念:同步.异步.阻塞.非阻塞 同步: 一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行.就是在发出一个功能调用时,在没 ...
- python并发编程之IO模型(Day38)
一.IO模型介绍 为了更好的学习IO模型,可以先看同步,异步,阻塞,非阻塞 http://www.cnblogs.com/linhaifeng/articles/7430066.html#_label ...
- 33 python 并发编程之IO模型
一 IO模型介绍 为了更好地了解IO模型,我们需要事先回顾下:同步.异步.阻塞.非阻塞 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非 ...
随机推荐
- css-动画,a标签下,文字加下划线,而且动画是由中间向两边扩展开
效果: html: <div class="warp"> <a class="welcome">期待您的参与</a> < ...
- MVC2新闻
链接:https://pan.baidu.com/s/1ABJfNYq49DnVlf8tJZ6dtg 提取码:akon 复制这段内容后打开百度网盘手机App,操作更方便哦 1.目录结构 2.首先验证登 ...
- wx小程序知识点(七)
七.小程序提速与性能优化 参考大佬vicyao的文章 https://blog.csdn.net/wetest_tencent/article/details/61196522 (1)提高页面加载速度 ...
- 批量查询 xml的方式 还一种是表变量
var adds1 = getoneCityList.Select(l => { return new { YDCode = l.YDCode, SJQH = l.SJQH }; });var ...
- [Linux系统] (1)常用操作(CentOS 7.x)
一.Linux系统配置 1.修改主机名 [/etc/hostname] vi /etc/hostname 在其中将旧名字修改为新主机名,保存,重启生效. 2.本地DNS映射 [/etc/hosts] ...
- JS框架_(Qrcode.js)将你的内容转换成二维码格式
百度云盘 传送门 密码:304e 输入网址点击按钮生成二维码,默认为我的博客首页 二维码格式演示 <!DOCTYPE html> <html lang="en"& ...
- hive 分组排序函数 row_number() over(partition by " " order by " "desc
语法:row_number() over (partition by 字段a order by 计算项b desc ) rank --这里rank是别名 partition by:类似hive的建表, ...
- [CSP-S模拟测试]:午餐(贪心+最短路)
题目传送门(内部题115) 输入格式 第一行两个正整数$n,m$. 接下来$m$行,每行$4$个正整数$u_j,v_j,L_j,R_j$. 接下来一行$n$个数,若第$i$个数为$1$,则$i$号同学 ...
- js对象深拷贝、浅拷贝
浅拷贝1 //浅拷贝1 let obj01 = { name: 'Lily', age: '20', time: ['13', '15'], person: { name: 'Henry', age: ...
- Kotlin学习入门笔记
参考资料 官网:https://kotlinlang.org/ 官方文档:https://kotlinlang.org/docs/reference/ Kotlin 源码:https://github ...