大数据笔记(十四)——HBase的过滤器与Mapreduce
一. HBase过滤器
1、列值过滤器
2、列名前缀过滤器
3、多个列名前缀过滤器
4、行键过滤器
5、组合过滤器
package demo; import javax.swing.RowFilter; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.ColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Test; import net.spy.memcached.ops.OperationErrorType; public class TestHBaseFilter { /**
* 列值过滤器:SingleColumnValueFilter
*/
@Test
public void testSingleColumnValueFilter() throws Exception{
//查询工资等于3000的员工
//select * from emp where sal=3000
//配置ZK的地址信息
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端
HTable client = new HTable(conf, "emp");
//定义一个列值过滤器
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("empinfo"),//列族
Bytes.toBytes("sal"), //工资
CompareOp.EQUAL, // =
Bytes.toBytes("3000"));//ֵ //定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter); //通过过滤器查询数据
ResultScanner rs = client.getScanner(scan);
for (Result result : rs) {
String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
System.out.println(name);
} client.close();
} /**
* 列名前缀过滤器:ColumnPrefixFilter
*/
@Test
public void testColumnPrefixFilter() throws Exception{
//列名前缀过滤器
//select ename from emp
//配置ZK的地址信息
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端
HTable client = new HTable(conf, "emp"); //定义一个列名前缀过滤器
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("ename")); //定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter); //通过过滤器查询数据
ResultScanner rs = client.getScanner(scan);
for (Result result : rs) {
String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
System.out.println(name);
} client.close();
} /**
* 多个列名前缀过滤器:MultipleColumnPrefixFilter
*/
@Test
public void testMultipleColumnPrefixFilter() throws Exception{ Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); HTable client = new HTable(conf, "emp");
//员工姓名 薪资
byte[][] names = {Bytes.toBytes("ename"),Bytes.toBytes("sal")}; MultipleColumnPrefixFilter filter = new MultipleColumnPrefixFilter(names); Scan scan = new Scan();
scan.setFilter(filter); ResultScanner rs = client.getScanner(scan);
for (Result result : rs) {
String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
String sal = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
} client.close();
} /**
* 行键过滤器:RowFilter
*/
@Test
public void testRowFilter() throws Exception{ Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); HTable client = new HTable(conf, "emp"); //定义一个行键过滤器
org.apache.hadoop.hbase.filter.RowFilter filter = new org.apache.hadoop.hbase.filter.RowFilter(
CompareOp.EQUAL, //=
new RegexStringComparator("7839")); //定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter); //通过过滤器查询数据
ResultScanner rs = client.getScanner(scan);
for (Result result : rs) {
String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
String sal = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
} client.close();
} /**
* 组合过滤器
*/
@Test
public void testFilter() throws Exception{ Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); HTable client = new HTable(conf, "emp"); //工资=3000
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(Bytes.toBytes("empinfo"),
Bytes.toBytes("sal"), CompareOp.EQUAL, Bytes.toBytes("3000"));
//名字
ColumnPrefixFilter filter2 = new ColumnPrefixFilter(Bytes.toBytes("ename")); FilterList filterList = new FilterList(Operator.MUST_PASS_ALL);
filterList.addFilter(filter1);
filterList.addFilter(filter2); Scan scan = new Scan();
scan.setFilter(filterList); ResultScanner rs = client.getScanner(scan);
for (Result result : rs) {
String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
String sal = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
} client.close();
}
}
二. HDFS上的mapreduce
建立表
create 'word','content'
put 'word','1','content:info','I love Beijing'
put 'word','2','content:info','I love China'
put 'word','3','content:info','Beijing is the capital of China'
create 'stat','content'
注意:export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH

WordCountMapper.java
package wc; import java.io.IOException; import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text; //K2 V2
//没有k1和v1,因为输入的就是表中一条记录
public class WordCountMapper extends TableMapper<Text, IntWritable>{ @Override
protected void map(ImmutableBytesWritable key, Result value,
Context context)throws IOException, InterruptedException {
//key和value代表从表中输入的一条记录
//key:行键 value:数据
String data = Bytes.toString(value.getValue(Bytes.toBytes("content"), Bytes.toBytes("info")));
//分词
String[] words = data.split(" ");
for (String w : words) {
context.write(new Text(w), new IntWritable(1));
}
}
}
WordCountReducer.java
package wc; import java.io.IOException; import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//k3 v3 代表输出一条记录
public class WordCountReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable>{ @Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context)
throws IOException, InterruptedException {
// 求和
int total = 0;
for (IntWritable v : v3) {
total = total + v.get();
} //构造一个put对象
Put put = new Put(Bytes.toBytes(k3.toString()));
put.add(Bytes.toBytes("content"),//列族
Bytes.toBytes("result"),//列
Bytes.toBytes(String.valueOf(total))); //输出
context.write(new ImmutableBytesWritable(Bytes.toBytes(k3.toString())), //把这个单词作为key,就是输出的行键
put);//表中的一条记录
} }
WordCountMain.java
package wc; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job; public class WordCountMain { public static void main(String[] args) throws Exception {
//获取ZK的地址
//指定的配置信息:Zookeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //创建一个任务
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMain.class); //定义一个扫描器读取:content:info
Scan scan = new Scan();
//可以使用filter
scan.addColumn(Bytes.toBytes("content"), Bytes.toBytes("info")); //使用工具类设置Mapper
TableMapReduceUtil.initTableMapperJob(
Bytes.toBytes("word"), //输入的表
scan, //扫描器,只读取需要处理的数据
WordCountMapper.class,
Text.class, //key
IntWritable.class,//value
job); //使用工具类Reducer
TableMapReduceUtil.initTableReducerJob("stat", WordCountReducer.class, job); job.waitForCompletion(true);
} }
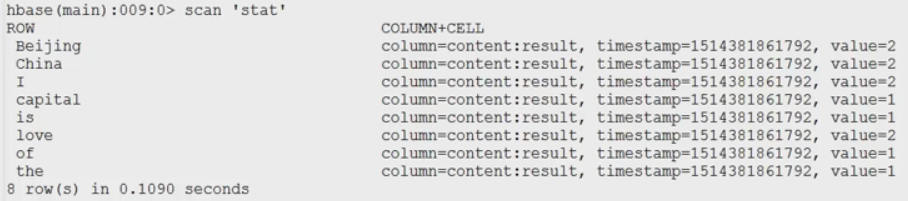
结果:
大数据笔记(十四)——HBase的过滤器与Mapreduce的更多相关文章
- 大数据笔记(四)——操作HDFS
一.Web Console:端口50070 二.HDFS的命令行操作 (一)普通操作命令 HDFS 操作命令帮助信息: hdfs dfs + Enter键 常见命令 1. -mkdir 在HDFS上 ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
- 《C++游戏开发》笔记十四 平滑过渡的战争迷雾(二) 实现:真正的迷雾来了
本系列文章由七十一雾央编写,转载请注明出处. http://blog.csdn.net/u011371356/article/details/9712321 作者:七十一雾央 新浪微博:http:/ ...
- 跟上节奏 大数据时代十大必备IT技能
跟上节奏 大数据时代十大必备IT技能 新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据笔记(十三)——常见的NoSQL数据库之HBase数据库(A)
一.HBase的表结构和体系结构 1.HBase的表结构 把所有的数据存到一张表中.通过牺牲表空间,换取良好的性能. HBase的列以列族的形式存在.每一个列族包括若干列 2.HBase的体系结构 主 ...
- 跟上节奏 大数据时代十大必备IT技能(转)
新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT发展趋势,使得IT人必须了解甚至掌握最 ...
- 大数据时代数据库-云HBase架构&生态&实践
业务的挑战 存储量量/并发计算增大 现如今大量的中小型公司并没有大规模的数据,如果一家公司的数据量超过100T,且能通过数据产生新的价值,基本可以说是大数据公司了 .起初,一个创业公司的基本思路就是首 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
随机推荐
- JSP页面读取数据中的数据内容,出现乱码现象的解决方法
1.首先要确保JSP页面的编码已修改为“utf-8”的字符编码: 2.然后再在jsp页面上添加代码进行设置: 先用getBytes()方法读出数据,然后再new String()方法设置格式为“utf ...
- MySQL-快速入门(7)索引
1.什么是索引 索引是对数据库表中一列或者多列的值进行排序的一种结构.索引是在存储引擎中实现的,每种存储引擎中的索引不一定完全相同. MySQL中索引的存储类型有两种:btree和hash.MyISA ...
- java基础笔记(11)
css 样式的设置主要有选择器+声明{}:声明里又分为属性和值: 注释代码:/*注释语句*/ 内联式:写在元素开始的标签里:例:<p style = "color:red;font-s ...
- 概率与期望dp相关
概率与期望dp 概率 某个事件A发生的可能性的大小,称之为事件A的概率,记作P(A). 假设某事的所有可能结果有n种,每种结果都是等概率,事件A涵盖其中的m种,那么P(A)=m/n. 例如投掷一枚骰子 ...
- java int转Short
使用short(xx) problemMultipleChoiceDO.setExamCount((short)0);//在数据库中是smallint类型
- 最大连续和 Medium
Given a two-dimensional array of positive and negative integers, a sub-rectangle is any contiguous s ...
- 深入理解 JavaScript中的变量、值、传参
1. demo 如果你对下面的代码没有任何疑问就能自信的回答出输出的内容,那么本篇文章就不值得你浪费时间了. var var1 = 1 var var2 = true var var3 = [1,2, ...
- spring boot配置分页插件
在springboot中使用PageHelper插件有两种较为相似的方式,接下来我就将这两种方式进行总结. 方式一:使用原生的PageHelper 1.在pom.xml中引入依赖 <depend ...
- [51Nod1850] 抽卡大赛
link $solution:$ 朴素 $dp$,暴力枚举选择 $i$ 号人的第 $j$ 张卡片,朴素 $dp$ 即可,时间复杂度 $O(n^4)$ . 考虑对于朴素 $dp$ 的优化,发现其实是一个 ...
- PCIeのType0与Type1型配置请求与BAR(基地址寄存器)
PCIe中存在两种配置空间Type0&type1,TYPE0对应非桥设备(Endpoint),Type1对应桥设备(Root和Switch端口中的P2P桥)因为Root每个端口总都含有一个P2 ...