Kafka长文总结
Kafka是目前使用较多的消息队列,以高吞吐量得到广泛使用
特点:
1、同时为发布和订阅提供搞吞吐量。Kafka的设计目标是以时间复杂度为O(1)的方式提供消息持久化能力的,即使对TB级别以上数据也能保证常数时间的访问性能,即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输(一般消息处理是百万级,使用Partition实现机器间的并行处理)
2、消息持久化。将消息持久化到磁盘,因此可用于批量消费,例如ETL以及实时应用程序。通过将数据持久化到磁盘以及复制可以防止数据丢失
3、分布式。支持服务器间的消息分区及分布式消费,同时保证每个Partition内的消息顺序传输。同时保证每个Partition内的消息顺序传输。其内部的Producer、Broker和Consumer都是分布式架构,这更易于向外扩展。
4、 消费消息采用Pull模式。消息被处理的状态是在Consumer端维护的,而不是由服务端维护,Broker无状态,Consumer自己保存offset。
5、支持Online和Offline场景,同时支持离线数据处理和实时数据处理。
基本概念:
一个典型的Kafka体系架构包括若干Producer、若干Broker、若干Consumer,以及一个ZooKeeper集群。其中ZooKeeper是Kafka用来负责集群元数据的管理、控制器的选举等操作的。Producer将
消息发送到Broker,Broker负责将收到的消息存储到磁盘中,而Consumer采用拉(pull模式)负责从Broker订阅并消费消息。
Broker:Kafka集群中的一台或多台服务器
Topic:主题,发布到Kafka的每条消息都有一个类别,这个类别就被称为Topic(物理上,不同Topic的消息分开存储;逻辑上,虽然一个Topic的消息被保存在一个或多个Broker上,但用户只
需要指定消息的Topic即可生产或消费数据,而不必关心数据存于何处)
Partition:物理上的Topic分区,一个Topic可以分为多个Partition,同一Topic下的不同分区包含的消息是不同的,每个partition都是一个有序的队列,在存储层面上可以看作一个可追加的日
志(Log)文件。Partition中的每条消息都会被分配一个有序的ID(offset),它唯一地标识分区中的每个记录,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,
也就是说,Kafka保证的Partition有序而不是Topic有序。且每个Partition只能被一个消费组中的一个消费者消费。
Kafka中的分区可以分布在不同的服务器Broker上,也就是说,一个主题可以横跨多个broker,以此来提供比单个broker更强大的性能。如果一个主题只对应一个文件,那么这个文件所在的机器IO将会成为这个主题的性能瓶颈,而分区解决了这个问题。
Producer:消息和数据的生产者,可以理解为向Kafka发送消息的客户端
Consumer:消息和数据的消费者,可以理解为从Kafka取消息的客户端,通过与Kafka集群建立长连接的方式,不断的从集群中拉取消息
Consumer Group(消费组):每个消费者都属于一个特定的消费组(可为每个消费者指定组名,若不指定组名,则属于默认的组)。这是Kafka用来实现一个Topic的广播(发送给所有的消费者)和单播(发送给任意一个消费者)的手段。一个Topic可以由多个消费组。但对每个消费组,只会把消息发送给该组中的一个消费者。如果要实现广播,只要每个消费者都有一个独立的消费组就可以了;如果要实现单播,只要所有的消费者都在同一个消费者组中就行。
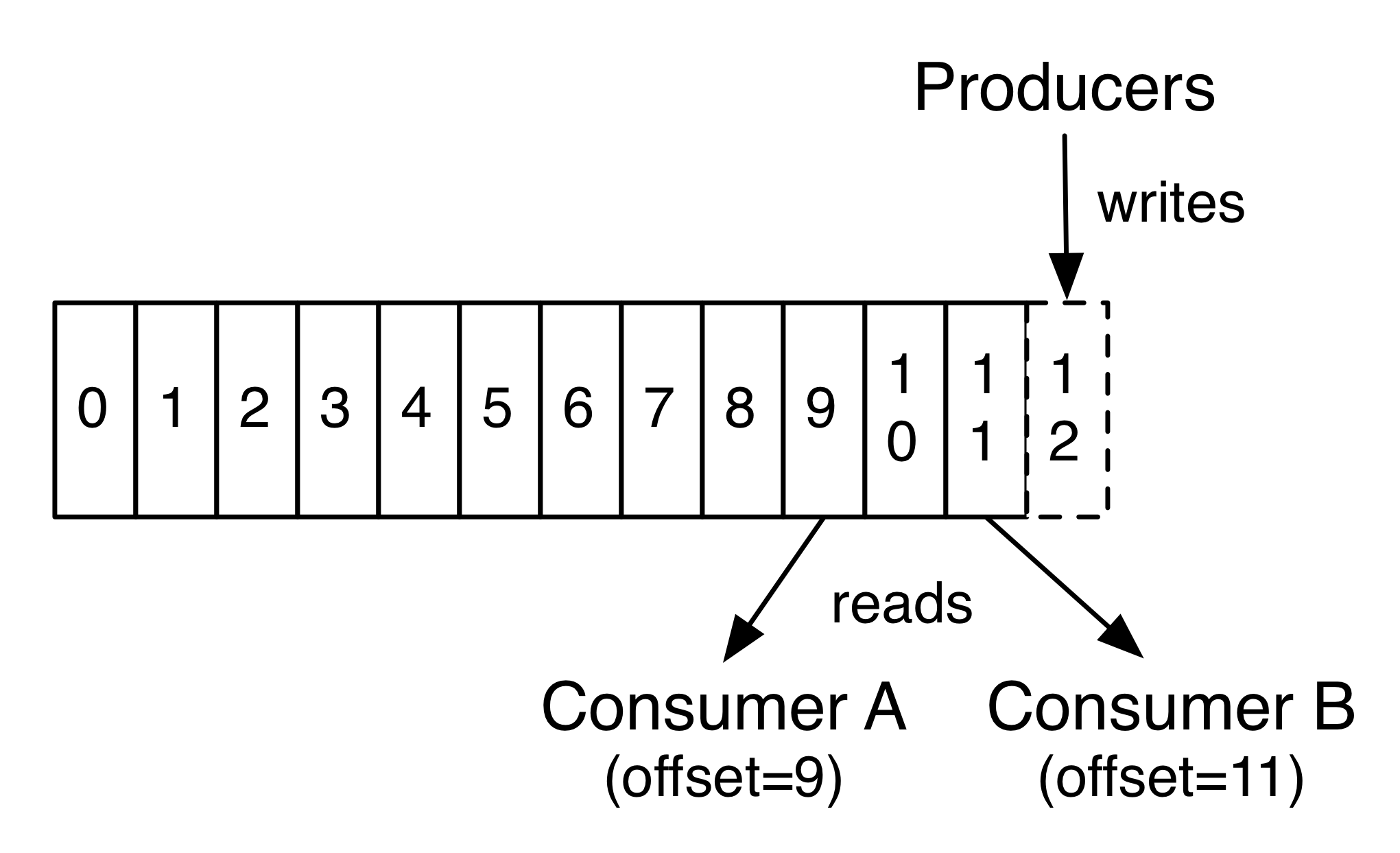
一个典型的Kafka集群中包含若干生产者、若干Broker(Kafka支持水平扩展,一般Broker数量越多集群吞吐量越大)、若干消费者组以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置、选举leader,以及当消费者组发生变化时进行Rebalance(再均衡)。生产者使用推模式将消息发布到Broker,消费者使用拉模式从Broker订阅并消费消息。
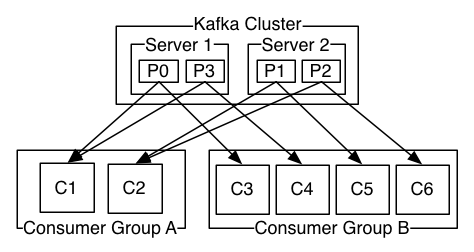
创建一个Topic时,可以指定分区数目,分区数越多,其吞吐量越大,但是需要的资源也越多,也会带来更高的不可用性。
在每条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区,如果分区规则设置的合理,所有的消息都可以均匀地分配到不同的分区中。
生产者在向kafka集群发送消息的分区策略:
1、可以指定分区,则消息投递到指定的分区
2、如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
3、如果既没有指定分区,且消息的key也为空,则用轮询的方式选择一个分区
也就是一条消息只会发送到一个分区中。
对于一个group而言,消费者的数量不应该多于分区的数量,因为在一个group中,每个分区最多只能绑定到一个消费者上,只能被一个消费组中的一个消费者消费。而一个消费者可以消费多个分区。因此,若一个消费组中的消费者数量大于分区数量的话,多余的消费者将不会收到消息(没有分区可以消费)。
再均衡:
再均衡是指分区的所属权从一个消费者转移到另一个消费者的行为,它为消费组具备高可用性和伸缩性提供保障,使我们可以方便安全的删除消费组内的消费者或往消费组内添加消费者。
不过在再均衡期间,消费组内的消费者是无法读取消息的。也就是说,在再均衡发生期间的这一小段时间内,消费组会变得不可用。另外,当一个分区被重新分配给另一个消费者时,消费者当前的状态也会丢失,比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作,之后这个分区又被分配给了消费组内的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就是发生了重复消费。一般情况下,应尽量避免不必要的再均衡发生。
代码实例:
<!--kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.1</version>
</dependency>
消息生产者:

package com.yang.spbo.kafka; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.util.HashMap;
import java.util.Map; /**
* Kafka消息生产者
* 〈功能详细描述〉
*
* @author 17090889
* @see [相关类/方法](可选)
* @since [产品/模块版本] (可选)
*/
public class ProducerSample {
public static void main(String[] args) {
Map<String, Object> props = new HashMap<>();
// Kafka集群,多台服务器地址之间用逗号隔开
props.put("bootstrap.servers", "localhost:9092");
// 消息的序列化类型
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 消息的反序列化类型
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// zookeeper集群地址,提供了基于Zookeeper的集群服务器自动感知功能,可以动态从Zookeeper中读取Kafka集群配置信息
props.put("zk.connect", "127.0.0.1:2181");
String topic = "test-topic";
Producer<String, String> producer = new KafkaProducer<String, String>(props);
// 发送消息
producer.send(new ProducerRecord<String, String>(topic, "idea-key2", "javaMesage1"));
producer.close();
}
}
ProducerRecord构造:
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, K key, V value) {
this(topic, (Integer)null, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, V value) {
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
}
topic和value是必填的,如果指定了partition,那么消息会被发送至指定的partition;如果没有指定partition但指定了key,那么消息会按照hash(key)发送至指定的partition;如果既没有指定partition,也没有指定key,那么消息会按照round-robin模式发送至每一个partition。
消息消费者:
package com.yang.spbo.kafka; import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; /**
* Kafka消息消费者
* 〈功能详细描述〉
*
* @author 17090889
* @see [相关类/方法](可选)
* @since [产品/模块版本] (可选)
*/
public class ConsumerSample {
public static void main(String[] args) {
String topic = "test-topic";
Properties props = new Properties();
// Kafka集群,多台服务器地址之间用逗号隔开
props.put("bootstrap.servers", "localhost:9092");
// 消费组ID
props.put("group.id", "test_group1");
// Consumer的offset是否自动提交
props.put("enable.auto.commit", "true");
// 自动提交offset到zk的时间间隔,时间单位是毫秒
props.put("auto.commit.interval.ms", "1000");
// 消息的反序列化类型
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<String, String>(props);
// 订阅的话题
consumer.subscribe(Arrays.asList(topic));
// Consumer调用poll方法来轮询Kafka集群的消息,一直等到Kafka集群中没有消息或者达到超时时间100ms为止
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println(record.partition() + record.offset());
System.out.println(record.key());
System.out.println(record.value());
}
}
}
}
分析poll及其和自动提交的关系是:
1、每次poll的消息处理完成之后再进行下一次poll,是同步操作
2、每次poll时,consumer都将尝试使用上次消费的offset作为起始offset,然后依次拉取消息
3、poll(long timeout),timeout指等待轮询缓冲区的数据所花费的时间,单位是毫秒
4、每次poll之前检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移
消费者参数详解:
1、consumer.poll(100)
新版本的Consumer的poll方法使用了类似于Select IO机制,因此所有相关的事件(包括reblance,消息获取等都发生在一个事件循环之中)。
100 毫秒是一个超时时间,一旦拿到足够多的数据(fetch.min.bytes 参数设置),,consumer.poll(100)会立即返回 ConsumerRecords<String, String> records。
如果没有拿到足够多的数据,会阻塞100ms,但不会超过100ms就会返回
2、session. timeout. ms <= coordinator检测失败的时间
默认值是10s,该参数是 Consumer Group 主动检测 (组内成员comsummer)崩溃的时间间隔。若超过这个时间内没有收到心跳报文,则认为此消费者已经下线。将触发再均衡操作。
3、max. poll. interval. ms <= 处理逻辑最大时间,默认30000,即5分钟
这个参数是0.10.1.0版本后新增的,当通过消费组管理消费者时,该配置指定拉取消息线程最长空闲时间,若超过这个时间间隔没有发起poll操作,则消费组认为该消费者已离开了消费组,将进行再均衡操作。
注意:如果业务平均处理逻辑为1分钟,那么max. poll. interval. ms需要设置稍微大于1分钟即可,但是session. timeout. ms可以设置小一点(如10s),用于快速检测Consumer崩溃。
超过这个时间将报如下错误信息:
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:861)
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:811)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:894)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:874)
at org.apache.kafka.clients.consumer.internals.RequestFuture$1.onSuccess(RequestFuture.java:204)
at org.apache.kafka.clients.consumer.internals.RequestFuture.fireSuccess(RequestFuture.java:167)
at org.apache.kafka.clients.consumer.internals.RequestFuture.complete(RequestFuture.java:127)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient$RequestFutureCompletionHandler.fireCompletion(ConsumerNetworkClient.java:586)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.firePendingCompletedRequests(ConsumerNetworkClient.java:400)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:303)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.pollNoWakeup(ConsumerNetworkClient.java:310)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator$HeartbeatThread.run(AbstractCoordinator.java:1020)
翻译:
无法完成提交,因为组已经重新平衡并将分区分配给另一个成员。这意味着对poll()的后续调用之间的时间比配置的max.poll.interval.ms长,这通常意味着poll循环花费了太多的时间来处理消息。可以通过增加max.poll.interval.ms来解决这个问题,也可以通过减少在poll()中使用max.poll.records返回的批的最大大小来解决这个问题
4、auto.offset.reset
该属性指定了消费者在读取一个没有偏移量后者偏移量无效(消费者长时间失效当前的偏移量已经过时并且被删除了)的分区的情况下,应该作何处理,默认值是latest,也就是从最新记录读取数据(消费者启动之后生成的记录),另一个值是earliest,意思是在偏移量无效的情况下,消费者从起始位置开始读取数据。
5、enable.auto.commit
开启自动提交offset,对于精确到一次的语义,最好手动提交位移
6、fetch.min.bytes
配置Consumer一次拉取请求中能从Kafka中拉取的最小数据量,默认为1B,如果小于这个参数配置的值,就需要进行等待,直到数据量满足这个参数的配置大小。调大可以提交吞吐量,但也会造成延迟。
7、fetch.max.bytes
一次拉取数据的最大数据量,默认为52428800B,也就是50M,但是如果设置的值过小,甚至小于每条消息的值,实际上也是能消费成功的。
7、max.poll.records <= 吞吐量
单次poll调用返回的最大消息数,如果处理逻辑很轻量,可以适当提高该值。
一次从kafka中poll出来的数据条数,max.poll.records条数据需要在在session.timeout.ms这个时间内处理完
默认值为500
9、fetch.wait.max.ms
若是不满足fetch.min.bytes时,等待消费端请求的最长等待时间,默认是500ms
Kafka Consumer默认配置
AbstractConfig#logAll:279|ConsumerConfig values:
auto.commit.interval.ms = 5000
auto.offset.reset = latest
bootstrap.servers = [10.234.199.148:9092]
check.crcs = true
client.id =
connections.max.idle.ms = 540000
default.api.timeout.ms = 60000
enable.auto.commit = true
exclude.internal.topics = true
fetch.max.bytes = 52428800
fetch.max.wait.ms = 500
fetch.min.bytes = 1
group.id = bssthirdparty.group
heartbeat.interval.ms = 3000 // poll()方法向群组协调器发送心跳的频率,默认3秒
interceptor.classes = []
internal.leave.group.on.close = true
isolation.level = read_uncommitted
key.deserializer = class org.apache.kafka.common.serialization.IntegerDeserializer
max.partition.fetch.bytes = 1048576
max.poll.interval.ms = 300000
max.poll.records = 500
metadata.max.age.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partition.assignment.strategy = [class org.apache.kafka.clients.consumer.RangeAssignor]
receive.buffer.bytes = 65536
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 30000
retry.backoff.ms = 100
sasl.client.callback.handler.class = null
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.login.callback.handler.class = null
sasl.login.class = null
sasl.login.refresh.buffer.seconds = 300
sasl.login.refresh.min.period.seconds = 60
sasl.login.refresh.window.factor = 0.8
sasl.login.refresh.window.jitter = 0.05
sasl.mechanism = GSSAPI
security.protocol = PLAINTEXT
send.buffer.bytes = 131072
session.timeout.ms = 10000 // 会话超时时间,在这个时间内没有发送心跳,broker即认为消费者死亡,触发再均衡
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
ssl.endpoint.identification.algorithm = https
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLS
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
value.deserializer = class org.apache.kafka.common.serialization.StringDeserializer
Kafka应用:
1、用户行为数据采集
2、基于Kafka的日志收集:
集群方式部署的应用,日志文件有多个存放地址,需要快速定位日志问题就比较繁琐,那么就需要一个统一的日志平台来管理项目中产生的日志文件。
各个应用系统在输出日志时利用拥有高吞吐量的Kafka作为数据缓冲平台,将日志统一输出到Kafka,再通过Kafka以统一接口服务的方式开放给消费者。
现在很多公司做的统一日志平台就是收集重要的系统日志几种到Kafka中,然后再导入Elasticsearch、HDFS、Storm等具体日志数据的消费者中,用于进行实时搜索分析、离线统计、数据备份、大数据分析等。引入log4j和Kafka的集成包kafka-log4j-appender,在日志配置文件中配置kafka信息即可
3、基于Kafka的流量削峰
比如秒杀带来的流量高峰的场景,为了保证系统高可用,加入消息队列作为信息流的缓冲,从而缓解短时间内产生的高流量带来的压垮整个应用的问题,这就叫流量削峰。
比如:秒杀场景,将商品的基本信息和库存使用缓存预热保存在Redis中,然后从Redis中读取,系统后台收到秒杀下单请求先从Redis中预减库存,如果库存
不足,返回秒杀失败;如果库存充足,则将请求的业务数据放入消息队列Kafka中排队,之后请求立即返回页面。消息队列的消费者在收到消息后取得业务数据,
执行后续的生成订单、扣减数据库和写消息操作。
Kafka分区:
在使用Kafka作为消息队列时,不管是发布还是订阅都需要指定主题topic,在这里的主题是一个逻辑上的概念,实际上Kafka的基本存储单元是分区Partition,在一个Topic中会有一个或多个Partition,不同的Partition可位于不同的服务器节点上,物理上一个Partition对应一个文件夹。(分区是Topic私有的,所有的Topic之间不共享分区)
站在生产者和Broker的角度,对不同Partition的写操作时完全并行的,但对消费者而言,其并发数则取决于Partition的数量。
所以在实际的项目中需要配置合适的Partition数量,而这个数值需要根据所设计的系统吞吐量来推算。假设p是生产者写入单个Partition的最大吞吐量,c表示消费者从单个Partitin消费的最大吞吐量,系统需要的目标吞吐量为t,那么Partition的数量应取t/p和t/c之间的大者。而且Partition的值要大于或等于消费组中消费者的数量。
Kafka集群复制(1.0保证消息不丢失的策略)
Kafka使用了zookeeper实现了去中心化的集群功能,简单地讲,其运行机制是利用zookeeper维护集群成员的信息,每个Broker实例都会被设置一个唯一的标识符,Broker在启动时会通过创建临时节点的方式把自己的唯一标识符注册到zookeeper中,Kafka中的其他组件会监视Zookeeper里的/broker/ids路径,所以当集群中有Broker加入或退出时其他组件就会收到通知。
虽然Kafka有集群功能,但是在0.8版本之前一直存在一个严重的问题,就是一旦某个Broker宕机,该Broker上的所有Partition数据就不能被消费了,生产者也不能把数据存放在这些Partition中了,显然不满足高可用设计。
为了让Kafka集群中某些节点不能继续提供服务的情况下,集群对外整体依然可用,即生产者可继续发送消息,消费者可继续消费消息,所以需要提供一种集群间数据的复制机制。在Kafka中是通过使用Zookeeper提供的leader选举方式来实现数据复制方案的,其基本原理是:首先在Kafka集群中的所有节点中选举出一个leader,其他副本作为follower,所有的写操作都先发给leader,然后再由leader把消息发给follower。
复制方案使Kafka集群可以在部分节点不可用的情况下还能保证Kafka的整体可用性。Kafka中的复制操作也是针对分区的。一个分区有多个副本,副本被保存在Broker上,每个Broker都可以保存上千个属于不同主题和分区的副本。副本有两种类型:leader副本(每个分区都会有)和follower副本(除了leader副本之外的其他副本)。为了保证一致性,所有的生产者和消费者的请求都会经过leader。而follower不处理客户端的请求,它的职责是从leader处复制消息数据,使自己和leader的状态保持一致,如果leader节点宕机,那么某个follower就会被选为leader继续对外提供服务。
ZooKeeper在kafka中的作用
1、broker
(1)状态:维护所有的运行的broker,记录所有broker的存活状态,broker会向zk发送心跳来上报自己的状态
(2)broker选举:负责选举leader,担任协调器
(3)记录ISR:ISR(in-sync replica),与leader保持一定程度同步的集合,一条消息只有被ISR中的成员都接收到,才被视为已同步状态,只有ISR集合中的副本才有资格被选举为leader
(4)node和topic注册:zk上保存了所有node和topic的注册信息,以临时节点的形式存在,可以方便的找到每个broker持有哪些topic
(5)topic配置:zk上保存了topic相关配置,如topic列表,topic的partition数量,副本的位置等
2、consumer
(1)offset:老版本中offset是存储在zk中的,新版中,保存在kafka自身的offset manager中
(2)注册:consumer的注册是在zk上创建一个临时节点,consumer下线则自动销毁
(3)分区注册:kafka中的每个partition只能被消费组中的一个consumer消费
Kafka保证消息不丢失的方案
一、消息发送
1、消息发送确认:消息数据是存储在分区中的,而分区又可能有多个副本,所以一条消息被发送到Broker之后何时算投递成功呢?Kafka提供了三种模式:
1):不等Broker确认,消息被发送出去就认为是成功的。这种方式延迟最小,但是不能保证消息已经被成功投递到Broker
2):由leader确认,当leader确认接收到消息就认为投递是成功的,然后由其他副本通过异步方式拉取
3):由所有的leader和follower都确认接收到消息才认为是成功的。采用这种方式投递的可靠性最高,但相对会损伤性能
// 生产者消息发送确认模式,0表示第一种,1表示第二种,all表示第三种
props.put("acks", "1");
2、消息重发:Kafka为了高可用性,生产者提供了自动重试机制。当从Broker接收到的是临时可恢复的异常时,生产者会向Broker重发消息,但不能无限
次重发,如果重发次数达到阀值,生产者将不再重试并返回错误。
// 消息发送重试次数
props.put("retries", "10");
// 重试间隔时间,默认100ms,设置时需要知道节点恢复所用的时间,要设置的比节点恢复所用时间长
props.put("retry.backoff.ms", "1000");
二、消息消费
从设计上来说,由于Kafka服务端并不保存消息的状态,所以在消费消息时就需要消费者自己去做很多事情,消费者每次调用poll方法时,该方法总是返回
由生产者写入Kafka中但还没有被消费者消费的消息。Kafka在设计上有一个不同于其他JMS队列的地方是生产者的消息并不需要消费者确认,而消息在分区中
又是顺序排列的,那么必然就可以通过一个偏移量offset来确定每一条消息的位置,偏移量在消息消费的过程中起着很重要的作用。
更新分区当前位置的操作叫做提交偏移量,Kafka中有个叫做_consumer_offset的特殊主题用来保存消息在每个分区的偏移量,消费者每次消费时都会往
这个主题中发送消息,消息包含每个分区的偏移量。如果消费者崩溃或者有新的消费者加入消费组从而触发再均衡操作,再均衡之后该分区的消费者若不是之前
那个,那么新的消费者如何得知该分区的消息已经被之前的消费者消费到哪个位置了呢?这种情况下,就提现了偏移量的用处。为了能继续之前的工作,新的消
费者需要读取每个分区最后一次提交的偏移量,然后再从偏移量开始继续往下消费消息。
偏移量提交方式:
1、自动提交
Kafka默认会定期自动提交偏移量,提交的默认时间间隔是5000ms,但可能存在提交不及时导致再均衡之后重复消费的情况
自动提交不是每消费一条消息就提交一次,而是定期提交,定期提交的间隔由 auto.commit.interval.ms 配置,默认是5秒。即
每隔5秒会将拉取到的每个分区中最大的消息offset进行提交。自动提交的动作是在poll方法的逻辑中完成的,在每次真正向服务端拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。
// Consumer的offset是否自动提交
props.put("enable.auto.commit", "true");
// 自动提交offset到zk的时间间隔,时间单位是毫秒
props.put("auto.commit.interval.ms", "1000");
2、手动提交
先关闭消费者的自动提交配置,然后使用commitSync方法提交偏移量。
// 关闭自动提交
props.put("enable.auto.commit", "false");
// Consumer调用poll方法来轮询Kafka集群的消息,一直等到Kafka集群中没有消息或者达到超时时间100ms为止
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println(record.partition() + record.offset());
System.out.println(record.key());
System.out.println(record.value());
}
// 手动提交最新的偏移量
consumer.commitSync();
}
commitSync方法会提交由poll返回的最新偏移量,所以在处理完记录后要确保调用了commitSync方法,否则还是会发生重复处理的问题。
3、异步提交
使用commitSync方法提交偏移量有一个不足之处,就是该方法在Broker对提交请求做出回应前是阻塞的,要等待回应。因此,采用这种方式每提交一次偏移量就
等待一次限制了消费端的吞吐量,因此Kafka提供了异步提交的方式【consumer.commitAsync();】,消费者只管发送提交请求,而不需要等待Broker的立即回应。
但commitSync方法在成功提交之前如碰到无法恢复的错误之前会一直重试,而commitAsync并不会,因为为了避免异步提交的偏移量被覆盖。
Kafka高吞吐量的原因?
1)、顺序读写
Kafka的消息是不断追加到文件中的,这个特性使Kafka可以充分利用磁盘的顺序读写性能。顺序读写不需要磁盘磁头的寻道时间,避免了随机磁盘寻址的浪费,只需很少的扇区
旋转时间,所以速度远快于随机读写
2)、零拷贝
在Linux Kernel2.2之后出现了一种叫做“零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,
数据不再复制到“用户缓冲区”
3)、分区
kafka中的topic中的内容可以分在多个分区(partition)存储,每个partition又分为多个段segment,所以每次操作都是针对一小部分做操作,很轻便,
并且增加并行操作的能力
4)、批量发送
Kafka允许进行批量发送消息,Productor发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka,可减少IO延迟
(1):等消息条数到固定条数
(2):一段时间发送一次
5)、数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩,压缩的好处就是减少传输的数据量,减轻
对网络传输的压力。
批量发送和数据压缩一起使用,单条做数据压缩的话,效果不太明显。消息发送时默认不会压缩,可使用compression.type来指定压缩方式,
可选的值为snappy、gzip和lz4
Kafka为什么使用消费组?
Kafka中一个topic可以有多个分区,一个分区只能被消费组中的一个消费者消费,而一个消费组中的消费者可以同时消费多个分区,所以topic的分区数不应小于消费组中消费者的数量,否则就会导致部分消费者消费不到消息。
消费组保证了一个分区只可以被消费组中的一个消费者所消费。下面是消费组的优点:
1、高性能,组内成员消费者分担多个分区的压力,提高消费性能
2、消费模式灵活,(1)一个消费组中可以只有一个消费者,那么多个消费组消费同一个分区就可以实现发布订阅模式(2)只使用一个消费组,消费组内消费者数量和分区数量一致,一个消费者消费一个分区,就可以实现单播即队列模式
3、故障容灾,只有一个消费者,若出现故障,则就麻烦了。消费组会对其成员进行管理,在有消费组加入或者退出后,消费者成员列表发生变化,消费组就会执行再平衡的操作。如其中一个消费者宕机后,之前分配给他的分区会重新分配给其他的消费者,实现消费者的故障容错
Kafka分区多副本机制:
通过增加副本可以提升容灾能力。同一个分区的不同副本中保存的是相同的信息(在同一时刻,副本之间并非完全一样),副本之间是一主多从的关系。其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中(topic的多个分区位于不同的broker中,同时,每个分区的副本也位于不同的broker中),当leader出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当kafka集群中某个broker失效时仍然能保证服务可用。
生产者和消费者只与leader副本进行交互,而follow副本只负责消息的同步,很多时候follower副本中的消息相对leader副本会有一定的滞后。
Kafka消费端也具备一定的容灾能力。Consumer使用pull 模式从服务端拉取消息,并且保存消费的具体位置,即offset,当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取需要的消息进行消费,这样就不会造成消息丢失。
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas),一定程度的同步是指可忍
受的滞后范围,可通过参数配置。与leader副本滞后过多的副本统称为OSR(Out-Sync Replicas),即AR=ISR+OSR。正常情况下,所有的follower副本都应该与leader副本保持一定
程度的同步,即AR=ISR,OSR集合为空。默认情况下,当leader发生故障时,只有ISR集合中的副本才有资格被选举为新的leader。
将分区看成一个日志文件,LSO(Log Start Offset):第一条消息的offset,队首的消息。HW(High Watermark):俗称高水位,标识了一个特定的消息偏移量,消费者只能拉取
到这个offset之前的消息。如HW为6的话,表示消费者只能拉取offset在0-5之间的消息,而offset为6的消息对消费者而言是不可见的。LEO(Log End Offset):标识当前日志文件中
下一条待写入消息的offset,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,
对消费者而言只能消费HW之前的消息。
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower副本都复制完,这条消息才被确认已成功提交,这种
复制方式极大地影响了性能。而在异步复制方式下,follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下,如果follower副本
都还没复制完而落后于leader副本,突然leader副本宕机,则会造成数据丢失。Kafka使用ISR的方式则有效地权衡了数据可靠性和性能之间的关系。
Kafka 消费者再均衡rebalance
将分区的所有权从一个消费者转移到其他消费者的行为称为重平衡(再均衡,rebalance)。重平衡非常重要,它为消费者群组带来了高可用性和伸缩性。可以添加消费者和移除消费者,
在重平衡期间,消费者无法读取消息,造成整个消费者组在重平衡期间都不可用。另外,当分区被重新分配给另外一个消费者时,消息当前的读取状态会丢失,它有可能还需要去刷新缓存,
在它重新恢复状态之前会拖慢应用程序。
消费者通过向组织协调者(kafka broker)发送心跳来维护自己是消费者组的一员并确认其拥有的分区。对于不同不的消费群体来说,其组织协调者可以是不同的。只要消费者定期发送
心跳,就会认为 消费者是存活的并处理其分区中的消息。当消费者检索记录或者提交它所消费的记录时就会发送心跳。
如果过了一段时间Kafka停止发送心跳了,会话(session)就会过期,组织协调者就会认为这个consumer已经死亡,就会触发一次重平衡。如果消费者宕机并且停止发送消息,组织协调
者会等待几秒钟,确认它死亡了才会触发重平衡。在这段时间里,死亡的消费者将不处理任何消息。在清理消费者时,消费者将通知协调者它要离开群组,组织协调者会触发一次重平衡,尽
量降低处理停顿。
重平衡是一把双刃剑,它为消费者群组带来高可用性和伸缩性的同时,还有有一些明显的缺点(bug),而这些 bug 到现在社区还无法修改。也就是说,在重平衡期间,消费者组中的消费者
实例都会停止消费(Stop The World),等待重平衡的完成。而且重平衡这个过程很慢。
触发再均衡的三种情况:
1、有新的消费者加入消费组
2、消费者超过session时间未发送心跳
3、一次poll()之后的消息处理时间超过了max.poll.interval.ms的配置时间,因为一次poll()处理完才会触发下次poll()
一次kafka重复消费的排查
重复消费问题1:
主要原因是因为使用了自动提交offset,定期提交offset的时间间隔设置不合理,导致的多次poll的消息记录是重复的。
详细信息:Kafka consumer使用自动提交,时间间隔为1000ms。另外,在遍历执行每条consumerRecord使用线程池异步执行。
问题原因:每次poll拉取多条 consumerRecords之后,全部交给线程池去执行,非同步执行,for循环很快执行结束然后进行下一次poll,两次poll之间间隔小于1000ms,
所以第二次poll时没有执行提交offset,两次poll的消息记录重复导致重复消费
解决办法:
1、减少定期自动提交offset的时间间隔小于两次poll的时间间隔,或者修改异步消息处理为同步
2、关闭自动提交offset,在for循环之后手动异步提交offset
重复消费问题2:
每次拉取的消息记录数max.poll.records为100,poll最大拉取间隔max.poll.interval.ms为 300s,消息处理过于耗时导致时长大于了这个值,导致再均衡发生重复消费
解决办法:
1、每次拉取的消息记录数和增大poll之间的时间间隔
2、拉取到消息之后异步处理
Kafka长文总结的更多相关文章
- 两万字长文,彻底搞懂Kafka!
1.为什么有消息系统 1.解耦合 2.异步处理 例如电商平台,秒杀活动. 一般流程会分为: 风险控制 库存锁定 生成订单 短信通知 更新数据 通过消息系统将秒杀活动业务拆分开,将不急需处理的业务放在后 ...
- Dubbo x Cloud Native 服务架构长文总结(很全)
Dubbo x Cloud Native 服务架构长文总结(很全) mercyblitz SpringForAll社区 3天前 分享简介 Cloud Native 应用架构随着云技术的发展受到业界特别 ...
- Kafka又出问题了!
写在前面 估计运维年前没有祭拜服务器,Nginx的问题修复了,Kafka又不行了.今天,本来想再睡会,结果,电话又响了.还是运营,"喂,冰河,到公司了吗?赶紧看看服务器吧,又出问题了&quo ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- .net windows Kafka 安装与使用入门(入门笔记)
完整解决方案请参考: Setting Up and Running Apache Kafka on Windows OS 在环境搭建过程中遇到两个问题,在这里先列出来,以方便查询: 1. \Jav ...
- kafka配置与使用实例
kafka作为消息队列,在与netty.多线程配合使用时,可以达到高效的消息队列
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
随机推荐
- day31—CSS Reset 与页面居中布局
转行学开发,代码100天——2018-04-16 报名的网易前端开发课程今天正式开课了,这也是毕业后首次付费进行的正式培训课程学习.以此,记录每天学习内容. 今天学了两个方面的知识: 1. CSS ...
- cannot be resolved to a type 错误解决方法
引言: eclipse新导入的项目经常可以看到“XX cannot be resolved to a type”的报错信息.本文将做以简单总结. 正文: (1)jdk不匹配(或不存在) ...
- canvas绘制随机颜色的柱形图
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【SD系列】SAP 跨年时更改销售凭证号码段
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[SD系列]SAP 跨年时更改销售凭证号码段 ...
- Bootstrap,Bagging and Random Forest Algorithm
Bootstrap Method:在统计学中,Bootstrap从原始数据中抽取子集,然后分别求取各个子集的统计特征,最终将统计特征合并.例如求取某国人民的平均身高,不可能测量每一个人的身高,但却可以 ...
- 洛谷P5018 对称二叉树——hash
给一手链接 https://www.luogu.com.cn/problem/P5018 这道题其实就是用hash水过去的,我们维护两个hash 一个是先左子树后右子树的h1 一个是先右子树后左子树的 ...
- CodeChef Mahesh and his lost array
Mahesh and his lost array Problem code: ANUMLA Submit All Submissions All submissions for this ...
- C# WCF 服务引用与Web引用
参考:https://blog.csdn.net/yelin042/article/details/82770205
- 攻防世界--dmd-50
测试文件:https://adworld.xctf.org.cn/media/task/attachments/7ef7678559ea46cbb535c0b6835f2f4d 1.准备 获取信息 6 ...
- 【JAVA】 05-String类和JDK5
链接: 笔记目录:毕向东Java基础视频教程-笔记 GitHub库:JavaBXD33 目录: <> <> 内容待整理: API-String 特点 String类: 1.St ...