python 学习分享-socketserver
SocketServer内部使用 IO多路复用 以及 “多线程” 和 “多进程” ,从而实现并发处理多个客户端请求的Socket服务端。即:每个客户端请求连接到服务器时,Socket服务端都会在服务器是创建一个“线程”或者“进 程” 专门负责处理当前客户端的所有请求。
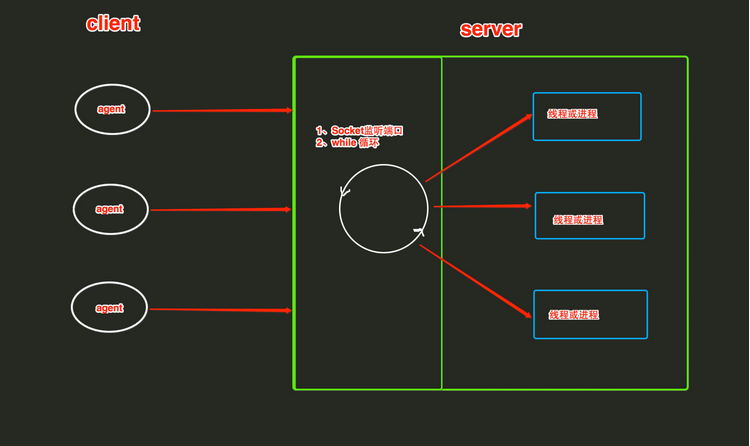
1.ThreadingTCPServer
ThreadingTCPServer实现的Soket服务器内部会为每个client创建一个 “线程”,该线程用来和客户端进行交互。
ThreadingTCPServer基础
使用ThreadingTCPServer:
创建一个继承自 SocketServer.BaseRequestHandler 的类
类中必须定义一个名称为 handle 的方法
启动ThreadingTCPServer
#server##########
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
conn = self.request
conn.sendall('我是多线程')
Flag = True
while Flag:
data = conn.recv(1024)
if data == 'exit':
Flag = False
elif data == '':
conn.sendall('您输入的是0')
else:
conn.sendall('请重新输入.')
if __name__ == '__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever() #client##########
import socket
ip_port = ('127.0.0.1',8009)
sk = socket.socket()
sk.connect(ip_port)
while True:
data = sk.recv(1024)
print 'receive:',data
inp = input('please input:')
sk.sendall(inp)
if inp == 'exit':
break
sk.close()
- 启动服务端程序
- 执行 TCPServer.init 方法,创建服务端Socket对象并绑定 IP 和 端口
- 执行 BaseServer.init 方法,将自定义的继承自SocketServer.BaseRequestHandler 的类 - MyRequestHandle赋值给 self.RequestHandlerClass
- 执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 ...
当客户端连接到达服务器 - 执行 ThreadingMixIn.process_request 方法,创建一个 “线程” 用来处理请求
- 执行 ThreadingMixIn.process_request_thread 方法
- 执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行 自定义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在该构造方法中又会调用 MyRequestHandler的handle方法)
ForkingTCPServer
ForkingTCPServer和ThreadingTCPServer的使用和执行流程基本一致,只不过在内部分别为请求者建立 “线程” 和 “进程”。
socketserver
"""Generic socket server classes. This module tries to capture the various aspects of defining a server: For socket-based servers: - address family:
- AF_INET{,6}: IP (Internet Protocol) sockets (default)
- AF_UNIX: Unix domain sockets
- others, e.g. AF_DECNET are conceivable (see <socket.h>
- socket type:
- SOCK_STREAM (reliable stream, e.g. TCP)
- SOCK_DGRAM (datagrams, e.g. UDP) For request-based servers (including socket-based): - client address verification before further looking at the request
(This is actually a hook for any processing that needs to look
at the request before anything else, e.g. logging)
- how to handle multiple requests:
- synchronous (one request is handled at a time)
- forking (each request is handled by a new process)
- threading (each request is handled by a new thread) The classes in this module favor the server type that is simplest to
write: a synchronous TCP/IP server. This is bad class design, but
save some typing. (There's also the issue that a deep class hierarchy
slows down method lookups.) There are five classes in an inheritance diagram, four of which represent
synchronous servers of four types: +------------+
| BaseServer |
+------------+
|
v
+-----------+ +------------------+
| TCPServer |------->| UnixStreamServer |
+-----------+ +------------------+
|
v
+-----------+ +--------------------+
| UDPServer |------->| UnixDatagramServer |
+-----------+ +--------------------+ Note that UnixDatagramServer derives from UDPServer, not from
UnixStreamServer -- the only difference between an IP and a Unix
stream server is the address family, which is simply repeated in both
unix server classes. Forking and threading versions of each type of server can be created
using the ForkingMixIn and ThreadingMixIn mix-in classes. For
instance, a threading UDP server class is created as follows: class ThreadingUDPServer(ThreadingMixIn, UDPServer): pass The Mix-in class must come first, since it overrides a method defined
in UDPServer! Setting the various member variables also changes
the behavior of the underlying server mechanism. To implement a service, you must derive a class from
BaseRequestHandler and redefine its handle() method. You can then run
various versions of the service by combining one of the server classes
with your request handler class. The request handler class must be different for datagram or stream
services. This can be hidden by using the request handler
subclasses StreamRequestHandler or DatagramRequestHandler. Of course, you still have to use your head! For instance, it makes no sense to use a forking server if the service
contains state in memory that can be modified by requests (since the
modifications in the child process would never reach the initial state
kept in the parent process and passed to each child). In this case,
you can use a threading server, but you will probably have to use
locks to avoid two requests that come in nearly simultaneous to apply
conflicting changes to the server state. On the other hand, if you are building e.g. an HTTP server, where all
data is stored externally (e.g. in the file system), a synchronous
class will essentially render the service "deaf" while one request is
being handled -- which may be for a very long time if a client is slow
to read all the data it has requested. Here a threading or forking
server is appropriate. In some cases, it may be appropriate to process part of a request
synchronously, but to finish processing in a forked child depending on
the request data. This can be implemented by using a synchronous
server and doing an explicit fork in the request handler class
handle() method. Another approach to handling multiple simultaneous requests in an
environment that supports neither threads nor fork (or where these are
too expensive or inappropriate for the service) is to maintain an
explicit table of partially finished requests and to use a selector to
decide which request to work on next (or whether to handle a new
incoming request). This is particularly important for stream services
where each client can potentially be connected for a long time (if
threads or subprocesses cannot be used). Future work:
- Standard classes for Sun RPC (which uses either UDP or TCP)
- Standard mix-in classes to implement various authentication
and encryption schemes XXX Open problems:
- What to do with out-of-band data? BaseServer:
- split generic "request" functionality out into BaseServer class.
Copyright (C) 2000 Luke Kenneth Casson Leighton <lkcl@samba.org> example: read entries from a SQL database (requires overriding
get_request() to return a table entry from the database).
entry is processed by a RequestHandlerClass. """ # Author of the BaseServer patch: Luke Kenneth Casson Leighton __version__ = "0.4" import socket
import selectors
import os
import errno
try:
import threading
except ImportError:
import dummy_threading as threading
from time import monotonic as time __all__ = ["BaseServer", "TCPServer", "UDPServer", "ForkingUDPServer",
"ForkingTCPServer", "ThreadingUDPServer", "ThreadingTCPServer",
"BaseRequestHandler", "StreamRequestHandler",
"DatagramRequestHandler", "ThreadingMixIn", "ForkingMixIn"]
if hasattr(socket, "AF_UNIX"):
__all__.extend(["UnixStreamServer","UnixDatagramServer",
"ThreadingUnixStreamServer",
"ThreadingUnixDatagramServer"]) # poll/select have the advantage of not requiring any extra file descriptor,
# contrarily to epoll/kqueue (also, they require a single syscall).
if hasattr(selectors, 'PollSelector'):
_ServerSelector = selectors.PollSelector
else:
_ServerSelector = selectors.SelectSelector class BaseServer: """Base class for server classes. Methods for the caller: - __init__(server_address, RequestHandlerClass)
- serve_forever(poll_interval=0.5)
- shutdown()
- handle_request() # if you do not use serve_forever()
- fileno() -> int # for selector Methods that may be overridden: - server_bind()
- server_activate()
- get_request() -> request, client_address
- handle_timeout()
- verify_request(request, client_address)
- server_close()
- process_request(request, client_address)
- shutdown_request(request)
- close_request(request)
- service_actions()
- handle_error() Methods for derived classes: - finish_request(request, client_address) Class variables that may be overridden by derived classes or
instances: - timeout
- address_family
- socket_type
- allow_reuse_address Instance variables: - RequestHandlerClass
- socket """ timeout = None def __init__(self, server_address, RequestHandlerClass):
"""Constructor. May be extended, do not override."""
self.server_address = server_address
self.RequestHandlerClass = RequestHandlerClass
self.__is_shut_down = threading.Event()
self.__shutdown_request = False def server_activate(self):
"""Called by constructor to activate the server. May be overridden. """
pass def serve_forever(self, poll_interval=0.5):
"""Handle one request at a time until shutdown. Polls for shutdown every poll_interval seconds. Ignores
self.timeout. If you need to do periodic tasks, do them in
another thread.
"""
self.__is_shut_down.clear()
try:
# XXX: Consider using another file descriptor or connecting to the
# socket to wake this up instead of polling. Polling reduces our
# responsiveness to a shutdown request and wastes cpu at all other
# times.
with _ServerSelector() as selector:
selector.register(self, selectors.EVENT_READ) while not self.__shutdown_request:
ready = selector.select(poll_interval)
if ready:
self._handle_request_noblock() self.service_actions()
finally:
self.__shutdown_request = False
self.__is_shut_down.set() def shutdown(self):
"""Stops the serve_forever loop. Blocks until the loop has finished. This must be called while
serve_forever() is running in another thread, or it will
deadlock.
"""
self.__shutdown_request = True
self.__is_shut_down.wait() def service_actions(self):
"""Called by the serve_forever() loop. May be overridden by a subclass / Mixin to implement any code that
needs to be run during the loop.
"""
pass # The distinction between handling, getting, processing and finishing a
# request is fairly arbitrary. Remember:
#
# - handle_request() is the top-level call. It calls selector.select(),
# get_request(), verify_request() and process_request()
# - get_request() is different for stream or datagram sockets
# - process_request() is the place that may fork a new process or create a
# new thread to finish the request
# - finish_request() instantiates the request handler class; this
# constructor will handle the request all by itself def handle_request(self):
"""Handle one request, possibly blocking. Respects self.timeout.
"""
# Support people who used socket.settimeout() to escape
# handle_request before self.timeout was available.
timeout = self.socket.gettimeout()
if timeout is None:
timeout = self.timeout
elif self.timeout is not None:
timeout = min(timeout, self.timeout)
if timeout is not None:
deadline = time() + timeout # Wait until a request arrives or the timeout expires - the loop is
# necessary to accommodate early wakeups due to EINTR.
with _ServerSelector() as selector:
selector.register(self, selectors.EVENT_READ) while True:
ready = selector.select(timeout)
if ready:
return self._handle_request_noblock()
else:
if timeout is not None:
timeout = deadline - time()
if timeout < 0:
return self.handle_timeout() def _handle_request_noblock(self):
"""Handle one request, without blocking. I assume that selector.select() has returned that the socket is
readable before this function was called, so there should be no risk of
blocking in get_request().
"""
try:
request, client_address = self.get_request()
except OSError:
return
if self.verify_request(request, client_address):
try:
self.process_request(request, client_address)
except:
self.handle_error(request, client_address)
self.shutdown_request(request)
else:
self.shutdown_request(request) def handle_timeout(self):
"""Called if no new request arrives within self.timeout. Overridden by ForkingMixIn.
"""
pass def verify_request(self, request, client_address):
"""Verify the request. May be overridden. Return True if we should proceed with this request. """
return True def process_request(self, request, client_address):
"""Call finish_request. Overridden by ForkingMixIn and ThreadingMixIn. """
self.finish_request(request, client_address)
self.shutdown_request(request) def server_close(self):
"""Called to clean-up the server. May be overridden. """
pass def finish_request(self, request, client_address):
"""Finish one request by instantiating RequestHandlerClass."""
self.RequestHandlerClass(request, client_address, self) def shutdown_request(self, request):
"""Called to shutdown and close an individual request."""
self.close_request(request) def close_request(self, request):
"""Called to clean up an individual request."""
pass def handle_error(self, request, client_address):
"""Handle an error gracefully. May be overridden. The default is to print a traceback and continue. """
print('-'*40)
print('Exception happened during processing of request from', end=' ')
print(client_address)
import traceback
traceback.print_exc() # XXX But this goes to stderr!
print('-'*40) class TCPServer(BaseServer): """Base class for various socket-based server classes. Defaults to synchronous IP stream (i.e., TCP). Methods for the caller: - __init__(server_address, RequestHandlerClass, bind_and_activate=True)
- serve_forever(poll_interval=0.5)
- shutdown()
- handle_request() # if you don't use serve_forever()
- fileno() -> int # for selector Methods that may be overridden: - server_bind()
- server_activate()
- get_request() -> request, client_address
- handle_timeout()
- verify_request(request, client_address)
- process_request(request, client_address)
- shutdown_request(request)
- close_request(request)
- handle_error() Methods for derived classes: - finish_request(request, client_address) Class variables that may be overridden by derived classes or
instances: - timeout
- address_family
- socket_type
- request_queue_size (only for stream sockets)
- allow_reuse_address Instance variables: - server_address
- RequestHandlerClass
- socket """ address_family = socket.AF_INET socket_type = socket.SOCK_STREAM request_queue_size = 5 allow_reuse_address = False def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
"""Constructor. May be extended, do not override."""
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.socket = socket.socket(self.address_family,
self.socket_type)
if bind_and_activate:
try:
self.server_bind()
self.server_activate()
except:
self.server_close()
raise def server_bind(self):
"""Called by constructor to bind the socket. May be overridden. """
if self.allow_reuse_address:
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.socket.bind(self.server_address)
self.server_address = self.socket.getsockname() def server_activate(self):
"""Called by constructor to activate the server. May be overridden. """
self.socket.listen(self.request_queue_size) def server_close(self):
"""Called to clean-up the server. May be overridden. """
self.socket.close() def fileno(self):
"""Return socket file number. Interface required by selector. """
return self.socket.fileno() def get_request(self):
"""Get the request and client address from the socket. May be overridden. """
return self.socket.accept() def shutdown_request(self, request):
"""Called to shutdown and close an individual request."""
try:
#explicitly shutdown. socket.close() merely releases
#the socket and waits for GC to perform the actual close.
request.shutdown(socket.SHUT_WR)
except OSError:
pass #some platforms may raise ENOTCONN here
self.close_request(request) def close_request(self, request):
"""Called to clean up an individual request."""
request.close() class UDPServer(TCPServer): """UDP server class.""" allow_reuse_address = False socket_type = socket.SOCK_DGRAM max_packet_size = 8192 def get_request(self):
data, client_addr = self.socket.recvfrom(self.max_packet_size)
return (data, self.socket), client_addr def server_activate(self):
# No need to call listen() for UDP.
pass def shutdown_request(self, request):
# No need to shutdown anything.
self.close_request(request) def close_request(self, request):
# No need to close anything.
pass class ForkingMixIn: """Mix-in class to handle each request in a new process.""" timeout = 300
active_children = None
max_children = 40 def collect_children(self):
"""Internal routine to wait for children that have exited."""
if self.active_children is None:
return # If we're above the max number of children, wait and reap them until
# we go back below threshold. Note that we use waitpid(-1) below to be
# able to collect children in size(<defunct children>) syscalls instead
# of size(<children>): the downside is that this might reap children
# which we didn't spawn, which is why we only resort to this when we're
# above max_children.
while len(self.active_children) >= self.max_children:
try:
pid, _ = os.waitpid(-1, 0)
self.active_children.discard(pid)
except ChildProcessError:
# we don't have any children, we're done
self.active_children.clear()
except OSError:
break # Now reap all defunct children.
for pid in self.active_children.copy():
try:
pid, _ = os.waitpid(pid, os.WNOHANG)
# if the child hasn't exited yet, pid will be 0 and ignored by
# discard() below
self.active_children.discard(pid)
except ChildProcessError:
# someone else reaped it
self.active_children.discard(pid)
except OSError:
pass def handle_timeout(self):
"""Wait for zombies after self.timeout seconds of inactivity. May be extended, do not override.
"""
self.collect_children() def service_actions(self):
"""Collect the zombie child processes regularly in the ForkingMixIn. service_actions is called in the BaseServer's serve_forver loop.
"""
self.collect_children() def process_request(self, request, client_address):
"""Fork a new subprocess to process the request."""
pid = os.fork()
if pid:
# Parent process
if self.active_children is None:
self.active_children = set()
self.active_children.add(pid)
self.close_request(request)
return
else:
# Child process.
# This must never return, hence os._exit()!
try:
self.finish_request(request, client_address)
self.shutdown_request(request)
os._exit(0)
except:
try:
self.handle_error(request, client_address)
self.shutdown_request(request)
finally:
os._exit(1) class ThreadingMixIn:
"""Mix-in class to handle each request in a new thread.""" # Decides how threads will act upon termination of the
# main process
daemon_threads = False def process_request_thread(self, request, client_address):
"""Same as in BaseServer but as a thread. In addition, exception handling is done here. """
try:
self.finish_request(request, client_address)
self.shutdown_request(request)
except:
self.handle_error(request, client_address)
self.shutdown_request(request) def process_request(self, request, client_address):
"""Start a new thread to process the request."""
t = threading.Thread(target = self.process_request_thread,
args = (request, client_address))
t.daemon = self.daemon_threads
t.start() class ForkingUDPServer(ForkingMixIn, UDPServer): pass
class ForkingTCPServer(ForkingMixIn, TCPServer): pass class ThreadingUDPServer(ThreadingMixIn, UDPServer): pass
class ThreadingTCPServer(ThreadingMixIn, TCPServer): pass if hasattr(socket, 'AF_UNIX'): class UnixStreamServer(TCPServer):
address_family = socket.AF_UNIX class UnixDatagramServer(UDPServer):
address_family = socket.AF_UNIX class ThreadingUnixStreamServer(ThreadingMixIn, UnixStreamServer): pass class ThreadingUnixDatagramServer(ThreadingMixIn, UnixDatagramServer): pass class BaseRequestHandler: """Base class for request handler classes. This class is instantiated for each request to be handled. The
constructor sets the instance variables request, client_address
and server, and then calls the handle() method. To implement a
specific service, all you need to do is to derive a class which
defines a handle() method. The handle() method can find the request as self.request, the
client address as self.client_address, and the server (in case it
needs access to per-server information) as self.server. Since a
separate instance is created for each request, the handle() method
can define other arbitrary instance variables. """ def __init__(self, request, client_address, server):
self.request = request
self.client_address = client_address
self.server = server
self.setup()
try:
self.handle()
finally:
self.finish() def setup(self):
pass def handle(self):
pass def finish(self):
pass # The following two classes make it possible to use the same service
# class for stream or datagram servers.
# Each class sets up these instance variables:
# - rfile: a file object from which receives the request is read
# - wfile: a file object to which the reply is written
# When the handle() method returns, wfile is flushed properly class StreamRequestHandler(BaseRequestHandler): """Define self.rfile and self.wfile for stream sockets.""" # Default buffer sizes for rfile, wfile.
# We default rfile to buffered because otherwise it could be
# really slow for large data (a getc() call per byte); we make
# wfile unbuffered because (a) often after a write() we want to
# read and we need to flush the line; (b) big writes to unbuffered
# files are typically optimized by stdio even when big reads
# aren't.
rbufsize = -1
wbufsize = 0 # A timeout to apply to the request socket, if not None.
timeout = None # Disable nagle algorithm for this socket, if True.
# Use only when wbufsize != 0, to avoid small packets.
disable_nagle_algorithm = False def setup(self):
self.connection = self.request
if self.timeout is not None:
self.connection.settimeout(self.timeout)
if self.disable_nagle_algorithm:
self.connection.setsockopt(socket.IPPROTO_TCP,
socket.TCP_NODELAY, True)
self.rfile = self.connection.makefile('rb', self.rbufsize)
self.wfile = self.connection.makefile('wb', self.wbufsize) def finish(self):
if not self.wfile.closed:
try:
self.wfile.flush()
except socket.error:
# A final socket error may have occurred here, such as
# the local error ECONNABORTED.
pass
self.wfile.close()
self.rfile.close() class DatagramRequestHandler(BaseRequestHandler): """Define self.rfile and self.wfile for datagram sockets.""" def setup(self):
from io import BytesIO
self.packet, self.socket = self.request
self.rfile = BytesIO(self.packet)
self.wfile = BytesIO() def finish(self):
self.socket.sendto(self.wfile.getvalue(), self.client_address)
python 学习分享-socketserver的更多相关文章
- python 学习分享-paramiko模块
paramiko模块学习分享 paramiko是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接.paramiko支持Linux, Solaris, BS ...
- python 学习分享-装饰器篇
本篇内容为偷窃的~哈哈,借用一下,我就是放在自己这里好看. 引用地址:http://www.cnblogs.com/rhcad/archive/2011/12/21/2295507.html 第一步: ...
- python 学习分享-rabbitmq
一.RabbitMQ 消息队列介绍 RabbitMQ也是消息队列,那RabbitMQ和之前python的Queue有什么区别么? py 消息队列: 线程 queue(同一进程下线程之间进行交互) 进程 ...
- python 学习分享-select等
首先列一下,sellect.poll.epoll三者的区别 select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组(在linux中 ...
- python 学习分享-进程
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程.Python提供了非常好用的多进程包multiprocessing,只需要定 ...
- python 学习分享-线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点: 使用线程可以把占据长时间的程序中的任务放到后台去处理. 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进 ...
- python 学习分享-实战篇高级的ftp
#server代码 import socketserver,os,hashlib Base_paht = os.path.dirname(os.path.dirname(os.path.abspath ...
- python 学习分享-面向对象2
面向对象进阶 静态方法 一种普通函数,就位于类定义的命名空间中,它不会对任何实例类型进行操作.使用装饰器@staticmethod定义静态方法.类对象和实例都可以调用静态方法: class Foo: ...
- python 学习分享-实战篇选课系统
# 角色:学校.学员.课程.讲师 # 要求: # 1. 创建北京.上海 2 所学校 # 2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开 # ...
随机推荐
- 使用shell脚本实现在liunx上进行svn的上传下载更新功能
最近有个功能,是需要从在liunx上拉取svn地址,并创建一个新文件进行提交,shell脚本如下 #!/bin/bash echo "Hello World !" myFile=& ...
- 使用shc加密bash脚本程序
摘要以前写看到别人写的脚本用shc加密的,我也有就了解了下. SHC代表shell script compiler,即shell脚本编译器.通过SHC编译过的脚本程序对普通用户而言是不读的,因此如果你 ...
- 问题 B: 投简历
题目描述 小华历经12寒窗苦读,又经历4年大学磨砺,终于毕业了,随着毕业季的到来,找工作也日益紧张起来.由于要面试不同的公司,因此小华需要准备不同的简历.当然最基本的信息是必不可少的,基本信息:姓名. ...
- apache以天为单位生成日志
编辑/etc/httpd/conf.d/vhost.conf,修改ErrorLog和CustomLog: ErrorLog "|rotatelogs /var/log/httpd/phpdd ...
- Javascript与C#中使用正则表达式
JavaScript RegExp 对象 新建一个RegExp对象 new RegExp(pattern,[attributes]) 注: \d需要使用[0-9]来代替 参数 参数 ...
- 当Java遇见了Html--Jsp九大内置对象篇
jsp内置对象对象是web容器创建的一组对象,不使用new关键词久可以使用的内置对象. 九大内置对象包括以下: out --JspWriter request --ServletRequest rep ...
- Data Warehouse 业务系统不入仓表
根据数据仓库的实施经验,凡符合如下特征的表,建议不入仓. ① 备份数据表 此类表是对现有表中某个时点数据的一份拷贝,根据需要进行数据恢复使用.因此,只需取当前表中的数据即可. ② 冗余数据表 同一类数 ...
- 交换机基础设置之vtp管理vlan设置
vtp的设置有三种模式1:server模式,负责创建,删除vlan(服务器模式) 2:client模式,负责接收并转发来自server的信息(客户机模式) 3:transparent模式,只负责转发, ...
- node服务端渲染(完整demo)
简介 nodejs搭建多页面服务端渲染 技术点 koa 搭建服务 koa-router 创建页面路由 nunjucks 模板引擎组合html webpack打包多页面 node端异步请求 服务端日志打 ...
- table选项卡
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...