elastic(7)bulk
转自:https://www.cnblogs.com/xing901022/p/5339419.html
bulk批量导入
批量导入可以合并多个操作,比如index,delete,update,create等等。也可以帮助从一个索引导入到另一个索引。
语法大致如下;
action_and_meta_data\n
optional_source\n
action_and_meta_data\n
optional_source\n
....
action_and_meta_data\n
optional_source\n需要注意的是,每一条数据都由两行构成(delete除外),其他的命令比如index和create都是由元信息行和数据行组成,update比较特殊它的数据行可能是doc也可能是upsert或者script,如果不了解的朋友可以参考前面的update的翻译。
注意,每一行都是通过\n回车符来判断结束,因此如果你自己定义了json,千万不要使用回车符。不然_bulk命令会报错的!
一个小例子
比如我们现在有这样一个文件,data.json:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }它的第一行定义了_index,_type,_id等信息;第二行定义了字段的信息。
然后执行命令:
curl -XPOST localhost:9200/_bulk --data-binary @data.json就可以看到已经导入进去数据了。
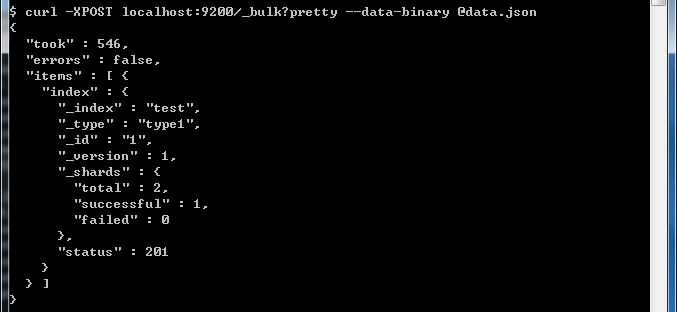
对于其他的index,delete,create,update等操作也可以参考下面的格式:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "type1", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "type1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "type1", "_index" : "index1"} }
{ "doc" : {"field2" : "value2"} }在Url中设置默认的index和type
如果在路径中设置了index或者type,那么在JSON中就不需要设置了。如果在JSON中设置,会覆盖掉路径中的配置。
比如上面的例子中,文件中定义了索引为test,类型为type1;而我们在路径中定义了默认的选项,索引为test333,类型为type333。执行命令后,发现文件中的配置会覆盖掉路径中的配置。这样也提供了统一的默认配置以及个性化的特殊配置的需求。

其他
由于bulk是一次性提交很多的命令,它会把这些数据都发送到一个节点,然后这个节点解析元数据(index或者type或者id之类的),然后分发给其他的节点的分片,进行操作。
由于很多命令执行后,统一的返回结果,因此数据量可能会比较大。这个时候如果使用的是chunk编码的方式,分段进行传输,可能会造成一定的延迟。因此还是对条件在客户端进行一定的缓冲,虽然bulk提供了批处理的方法,但是也不能给太大的压力!
最后要说一点的是,Bulk中的操作执行成功与否是不影响其他的操作的。而且也没有具体的参数统计,一次bulk操作,有多少成功多少失败。
扩展:在Logstash中,传输的机制其实就是bulk,只是他使用了Buffer,如果是服务器造成的访问延迟可能会采取重传,其他的失败就只丢弃了....
elastic(7)bulk的更多相关文章
- Nutch配置:nutch-default.xml详解
/×××××××××××××××××××××××××××××××××××××××××/ Author:xxx0624 HomePage:http://www.cnblogs.com/xxx0624/ ...
- Nutch的nutch-default.xml和regex-urlfilter.txt的中文解释
nutch-default解释.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl&qu ...
- Bulk API
承接上文,使用Java High Level REST Client操作elasticsearch Bulk API 高级客户端提供了批量处理器以协助批量请求 Bulk Request BulkReq ...
- Elastic数据迁移方法及注意事项
需求 ES集群Cluster_A里的数据(某个索引或某几个索引),需要迁移到另外一个ES集群Cluster_B中. 环境 Linux:Centos7 / Centos6.5/ Centos6.4Ela ...
- elastic客户端TransportClient的使用
关于TransportClient,elastic计划在Elasticsearch 7.0中弃用TransportClient,并在8.0中完全删除它.后面,应该使用Java高级REST客户端,它执行 ...
- ES bulk源码分析——ES 5.0
对bulk request的处理流程: 1.遍历所有的request,对其做一些加工,主要包括:获取routing(如果mapping里有的话).指定的timestamp(如果没有带timestamp ...
- 自定义Spark Partitioner提升es-hadoop Bulk效率
http://www.jianshu.com/p/cccc56e39429/comments/2022782 和 https://github.com/elastic/elasticsearch-ha ...
- java连接elastic search 9300
java连接elastic search 导入jar包:https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/_maven ...
- Elasticsearch之CURL命令的bulk批量操作
大家,也可去看看我下面的博客 Elasticsearch之批量操作bulk 官网上,是举例了新建一个requests文件. [hadoop@master elasticsearch-]$ pwd /h ...
随机推荐
- codeforces675D Tree Construction
本文版权归ljh2000和博客园共有,欢迎转载,但须保留此声明,并给出原文链接,谢谢合作. 本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/ ...
- 判断A字符串是B字符串的反转
先将其中一个字符串进行反转操作,然后两个字符串进行判断. 1.反转 /** * 字符串反转 * @param str * @return */ private static String conver ...
- 特殊字符处理(WPF)
WPF XAML 特殊字符(小于号.大于号.引号.&符号) - Andrew.Wangxu 时间 2013-09-07 18:14:00 博客园-所有随笔区原文 http://www.cn ...
- WebAPI序列化后的时间中含有“T”的解决方法
问题: { "name": "abc", "time": "2015-02-10T15:18:21.7046433+08:00&q ...
- lr中检查点的使用web_find()和web_reg_find()的区别
web_find()和web_reg_find()的区别:1. 这两个函数函数类型不同,web_find()是普通函数,web_reg_find()是注册函数;2. VU run time设置中的 “ ...
- JS开发页面小组件:table组件
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 剑指offer--17.第一个只出现一次的字符
map默认对key进行排序,unordered_map不对键或值进行排序,但是也不是默认插入的顺序 -------------------------------------------------- ...
- http请求 详解
- file_put_contents();
file_put_contents(); 用于获取文件中的内容,可以填写网址,但是需要以http://开头
- HihoCoder1366 逆序单词(字典树)
逆序单词 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 在英文中有很多逆序的单词,比如dog和god,evil和live等等. 现在给出一份包含N个单词的单词表,其中每 ...