TCP Nagle算法以及延迟确认(即延迟回复ACK)的学习
TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。
(一个连TCP接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。
Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。(尤其在广域网中)(减少大量小包的发送)
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。所谓“小段”,指的是小于MSS尺寸的数据块,
所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;(即关闭了Nagle算法了,可以立刻发)
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
Nagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停-等协议(停止等待ARQ协议),只不过它是基于包停-等的,而不是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低。 (好好理解这句话 就是如果ack回复的快 Nagle算法并不会来得急拼多大的包 虽然避免了网络拥塞,网络总体的利用率依然很低)
TCP_NODELAY 套接字选项
默认情况下,发送数据采用Negle 算法。这样虽然提高了网络吞吐量,但是实时性却降低了,在一些交互性很强的应用程序来说是不允许的,
使用TCP_NODELAY选项可以禁止Negale 算法。
延迟确认机制(TCP delayed acknowledgment)
全名Delayed Acknowledgment,简称延迟ACK,翻译为延迟确认。
与Nagle算法一样,延迟ACK的目的也是为了减少网络中传输大量的小报文数,但该报文数是针对ACK报文的。
一个来自发送端的报文到达接收端,TCP会延迟ACK的发送,希望应用程序会对刚刚收到的数据进行应答, 这样就可以用新数据将ACK捎带过去。 (就是对请求应答的时候稍带上ack,不单独进行确认 就是这个意思咯)
下面是讨论的重点!!!!!!
当Nagle算法遇到Delayed ACK
在一个有数据传输的TCP连接中,如果只有数据发送方启用Nagle算法,在其连续发送多个小报文时,Nagle算法机制会减少网络中的小报文数量。这就意味着,同样传输相同大小的应用数据,在网络上的报文个数却不同。
举个例子,发送端需要连续发送5个写操作(应用程序将数据写入到缓冲池的动作)的小报文,首先发送第一个,由于Nagle算法的作用,在未收到第一个报文确认前,发送端在等待写操作的同时进行读操作,接收端并未启用延迟确认(视TCP delay ACK时间为0),尽管刚收到该报文就发出确认,但由于网络延时的原因,在收集齐另外4个小报文后,发送方才收到了第一个报文的ACK,则后面的4个报文会一起发送出去(大小未超过MSS),接收端再次ACK。
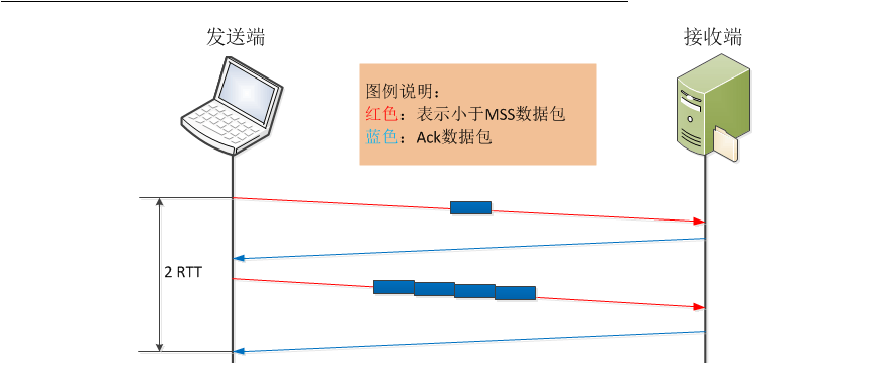
在上述发送5个小报文的过程中,只用了4个报文就实现了。
但如果发送端未启用Nagle算法,完成整个过程则至少需要8个报文或10个报文才能实现,这里接收端未启用延迟确认,如下图所示。启用Nagle算法和未启用Nagle算法的场景中,从完成数据发送的时间来看,未启用Nagle算法的方式花费的时间会更长一些,(也不一定吧个人觉得 还是要看网络环境 理论上是这样) 如下图所示。这里基本看到了Nagle算法的好处了。
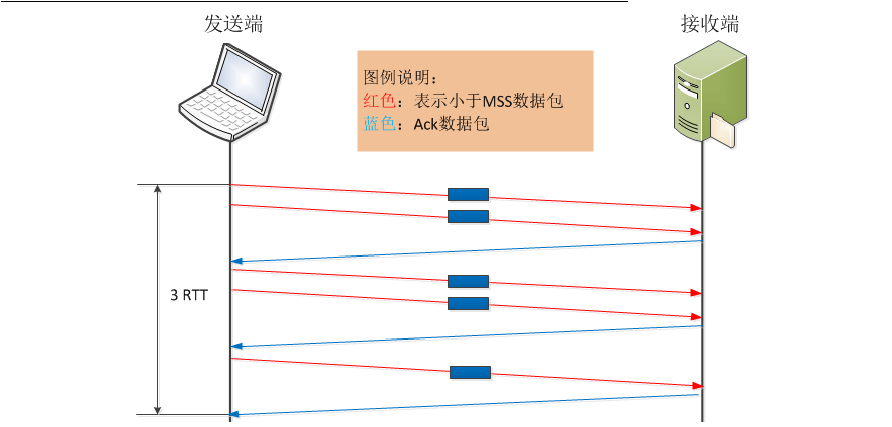
还是上述数据传输场景,发送端未启用Nagle算法,但接收端延迟确认默认时间为200ms,来看看这时的情况。 RFC 1122规定,Delayed ACK对单个的小报文可以延长确认的时间,但不允许有两个连续的小报文不被确认。所以,当发送端连续发送两个报文后,接收端必须给予确认。这时的数据传输情况如下图,只有当第5个报文到达后,接收端由于延迟确认机制,会导致200ms的延时存在。
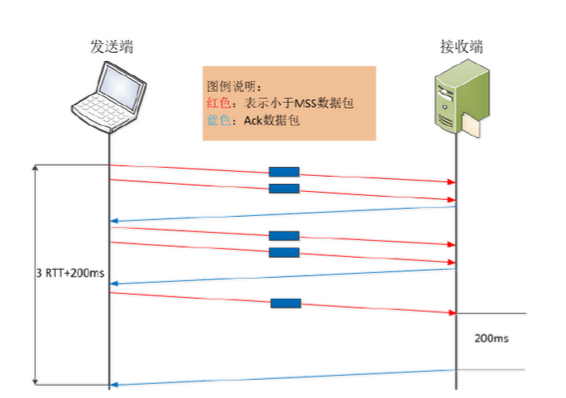
接下来看看,当Nagle算法遇到Delayed ACK时会是什么情况。按照常理推断,两种深思熟虑的功能设计,应该是1+1>2的效果。具体如何,还是请事实说话。
先继续看上面的假设场景,该场景要求发送端向接收端发送5个连续的写操作数据,但网络延时较大,同时发送端启用Nagle算法,接收端Delayed ACK默认为200ms。
发送方先发出一个小报文,接收端收到后,由于延迟确认的机制,等待发送方的下一个报文到达。而发送方由于Nagle算法机制,在未接收到第一个报文的确认前,不会发送已读取到的报文。 在这种场景下,暂不考虑应用处理时间,完成整个数据传输所需时间为2RTT+400ms,貌似情况不是特别糟糕。
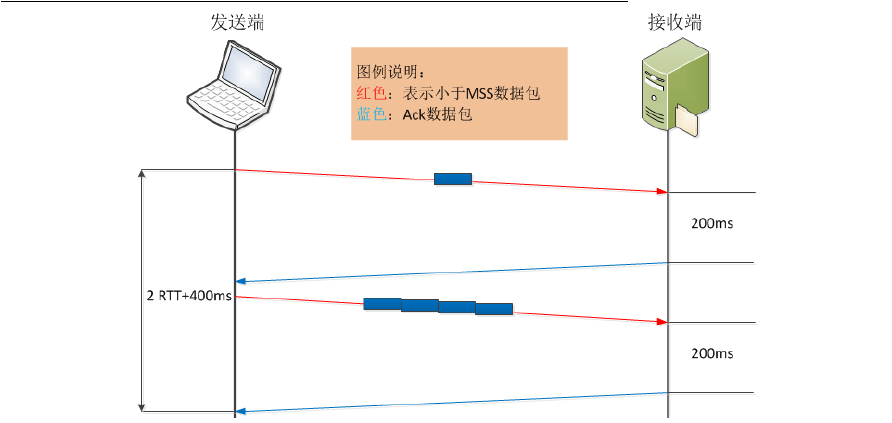
如果上述其他条件不变,发送方应用写操作延时稍微变大,或发送端的应用操作延时稍大,我们再看看,完成这个操作的延时情况。
发送方先发出一个小报文,接收端收到后,由于延迟确认的机制,等待发送方的下一个报文到达。由于发送方应用数据写操作延时较大,在经过RTT+200ms后,读取到了下一个需要发送的内容,此时接收到了第一个报文的确认,而网络中未有没被确认的报文,发送方需要再将第二个小报文发送出去,以此类推,直到最后一个小报文被发送,且接收到该报文的确认,此时整个数据传输过程完成。
在这种情景下,完成整个数据传输所需时间则为5RTT+5*200ms,明显增大了不少。如果相同情境下,有成千上万的小报文发送,则整体使用时间相当可观了。
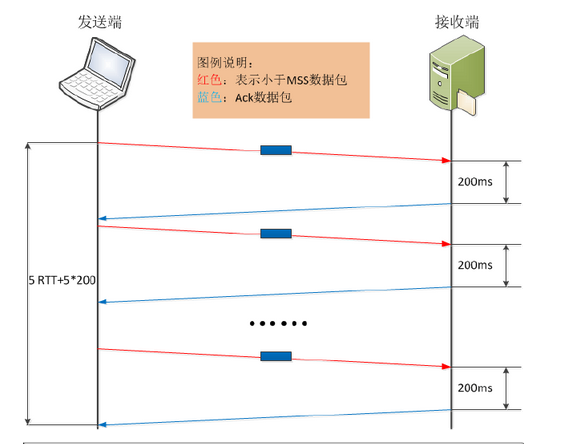
在实际情况下,如果发送方程序做了一系列的写、写、读操作的现象,这样的操作都会触发Nagle和延迟ACK算法之间的交互作用,应该尽量避免
TCP Nagle算法以及延迟确认(即延迟回复ACK)的学习的更多相关文章
- TCP Nagle算法&&延迟确认机制
TCP Nagle算法&&延迟确认机制 收藏 秋风醉了 发表于 3年前 阅读 1367 收藏 0 点赞 0 评论 0 [腾讯云]买域名送云解析+SSL证书+建站!>>> ...
- linux tcp Nagle算法,TCP_NODELAY和TCP_CORK 转载
转载自: http://www.cnhalo.net/2016/08/13/linux-tcp-nagle-cork/ http://abcdxyzk.github.io/blog/2018/07/0 ...
- TCP的ACK确认系列 — 延迟确认
主要内容:TCP的延迟确认.延迟确认定时器的实现. 内核版本:3.15.2 我的博客:http://blog.csdn.net/zhangskd 延迟确认模式 发送方在发送数据包时,如果发送的数据包有 ...
- Nagle算法&&延时确认
数据流分类 成块数据 交互数据 Rlogin需要远程系统(服务器)回显我们(客户)键入的字符 数据字节和数据字节的回显都需要对方确认 rlogin 每次只发送一个字节到服务器,而Telnet 可以 ...
- TCP/IP之Nagle算法与40ms延迟
Nagle算法是针对网络上存在的微小分组可能会在广域网上造成拥塞而设计的.该算法要求一个TCP连接上最多只能有一个未被确认的未完成的小分组,在该分组确认到达之前不能发送其他的小分组.同时,TCP收集这 ...
- 延迟确认和Nagle算法
前篇文章介绍了三次握手和四次挥手,了解了TCP是如何建立和断开连接的,文末还提到了抓包挥手时的一个“异常”现象,当时无法解释,特地查了资料,知道了数据传输中的延迟确认策略. 何谓延迟确认策略? WIK ...
- TCP之Nagle算法与延迟ACK
(一)Nagle算法 为了减少网络中小分组的数目,减少网络拥塞的情况.Nagle算法要求在一条TCP连接上最多只能有一个未被确认的未完成小分组,在该分组ACK到达之前不能够发送其他的小分组,发送端需要 ...
- TCP之Nagle算法&&延迟ACK
1. Nagle算法: 是为了减少广域网的小分组数目,从而减小网络拥塞的出现: 该算法要求一个tcp连接上最多只能有一个未被确认的未完成的小分组,在该分组ack到达之前不能发送其他的小分组,tcp需要 ...
- Linux下TCP延迟确认(Delayed Ack)机制导致的时延问题分析
版权声明:本文由潘安群原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/105 来源:腾云阁 https://www.qclo ...
随机推荐
- JavaPersistenceWithHibernate第二版笔记-第六章-Mapping inheritance-006Mixing inheritance strategies(@SecondaryTable、@PrimaryKeyJoinColumn、<join fetch="select">)
一.结构 For example, you can map a class hierarchy to a single table, but, for a particular subclass, s ...
- R: 绘图 pie & hist
问题: 绘制 pie .hist 图 解决方案: 饼图函数 pie( ) pie(x, labels = names(x), edges = 200, radius = 0.8, clockwise ...
- 关于用Date类计算活了多少天和用Calendar类计算闰年的demo
在javaSE阶段,Date类和Calendar类以后会经常用到 这两个类当中的一些常用方法 通过两个demo 进行学习和练习 第一个要求如下:让用户自己输入yyyy-MM-dd 格式的年月日 然后得 ...
- 操作系统--UNIX代码段和数据段分开
(1)代码段:代码段是用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像.代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作----它是不可写的. (2) ...
- CodeForces 566D Restructuring Company (并查集+链表)
题意:给定 3 种操作, 第一种 1 u v 把 u 和 v 合并 第二种 2 l r 把 l - r 这一段区间合并 第三种 3 u v 判断 u 和 v 是不是在同一集合中. 析:很容易知道是用并 ...
- Markdown语法简介 | Markdown Tutorial
Markdown是一种轻量级标记语言,允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的HTML文档. 与Word相比,使用Markdown最大的好处是可以使人们将注意力集中与文字本身而非排版 ...
- MATLAB数字图像处理(二)图像增强
1 图像增强 1.1 直方图均衡化 对于灰度图像,可以使用直方图均衡化的方法使得原图像的灰度直方图修正为均匀的直方图. 代码如下: I2=histeq(I1); ...
- const与define的区别
const与#define最大的差别,Const在堆栈分配了空间,而#define只是把具体数值 直接传递到目标变量罢了.或者说,const的常量是一个Run-Time的概念,他在程 序中确确实实的存 ...
- sina 接口 根据ip获取各个国家和地区
http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=json&ip=ip
- [hdu 2089] 不要62 数位dp|dfs 入门
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2089 题意:求[n, m]区间内不含4和62的数字个数. 这题有两种思路,直接数位dp和dfs 数位d ...