[搜索引擎]Sphinx的介绍和原理探索
What/Sphinx是什么
定义
Sphinx是一个全文检索引擎。
特性
- 索引和性能优异
- 易于集成SQL和XML数据源,并可使用SphinxAPI、SphinxQL或者SphinxSE搜索接口
- 易于通过分布式搜索进行扩展
- 高速的索引建立(在当代CPU上,峰值性能可达到10 ~ 15MB/秒)
- 高性能的搜索 (在1.2G文本,100万条文档上进行搜索,支持高达每秒150~250次查询)
Why/为什么使用Sphinx
遇到的使用场景
遇到一个类似这样的需求:用户可以通过文章标题和文章搜索到一片文章的内容,而文章的标题和文章的内容分别保存在不同的库,而且是跨机房的。
可选方案
A、直接在数据库实现跨库LIKE查询
优点:简单操作
缺点:效率较低,会造成较大的网络开销
B、结合Sphinx中文分词搜索引擎
优点:效率较高,具有较高的扩展性
缺点:不负责数据存储
使用Sphinx搜索引擎对数据做索引,数据一次性加载进来,然后做了所以之后保存在内存。这样用户进行搜索的时候就只需要在Sphinx服务器上检索数据即可。而且,Sphinx没有MySQL的伴随机磁盘I/O的缺陷,性能更佳。
其他典型使用场景
1、快速、高效、可扩展和核心的全文检索
- 数据量大的时候,比MyISAM和InnoDB都要快。
- 能对多个源表的混合数据创建索引,不限于单个表上的字段。
- 能将来自多个索引的搜索结果进行整合。
- 能根据属性上的附加条件对全文搜索进行优化。
2、高效地使用WHERE子句和LIMIT字句
当在多个WHERE条件做SELECT查询时,索引选择性较差或者根本没有索引支持的字段,性能较差。sphinx可以对关键字做索引。区别是,MySQL中,是内部引擎决定使用索引还是全扫描,而sphinx是让你自己选择使用哪一种访问方法。因为sphinx是把数据保存到RAM中,所以sphinx不会做太多的I/O操作。而mysql有一种叫半随机I/O磁盘读,把记录一行一行地读到排序缓冲区里,然后再进行排序,最后丢弃其中的绝大多数行。所以sphinx使用了更少的内存和磁盘I/O。
3、优化GROUP BY查询
在sphinx中的排序和分组都是用固定的内存,它的效率比类似数据集全部可以放在RAM的MySQL查询要稍微高些。
4、并行地产生结果集
sphinx可以让你从相同数据中同时产生几份结果,同样是使用固定量的内存。作为对比,传统SQL方法要么运行两个查询,要么对每个搜索结果集创建一个临时表。而sphinx用一个multi-query机制来完成这项任务。不是一个接一个地发起查询,而是把几个查询做成一个批处理,然后在一个请求里提交。
5、向上扩展和向外扩展
- 向上扩展:增加CPU/内核、扩展磁盘I/O
- 向外扩展:多个机器,即分布式sphinx
6、聚合分片数据
适合用在将数据分布在不同物理MySQL服务器间的情况。
例子:有一个1TB大小的表,其中有10亿篇文章,通过用户ID分片到10个MySQL服务器上,在单个用户的查询下当然很快,如果需要实现一个归档分页功能,展示某个用户的所有朋友发表的文章。那么就要同事访问多台MySQL服务器了。这样会很慢。而sphinx只需要创建几个实例,在每个表里映射出经常访问的文章属性,然后就可以进行分页查询了,总共就三行代码的配置。
介绍了Sphinx的工作原理,关于如何安装的文章在网上有很多,笔者就不再复述了,现在继续讲解Sphinx的配置文件,让Sphinx工作起来。
How/如何使用Sphinx
Sphinx工作流程图
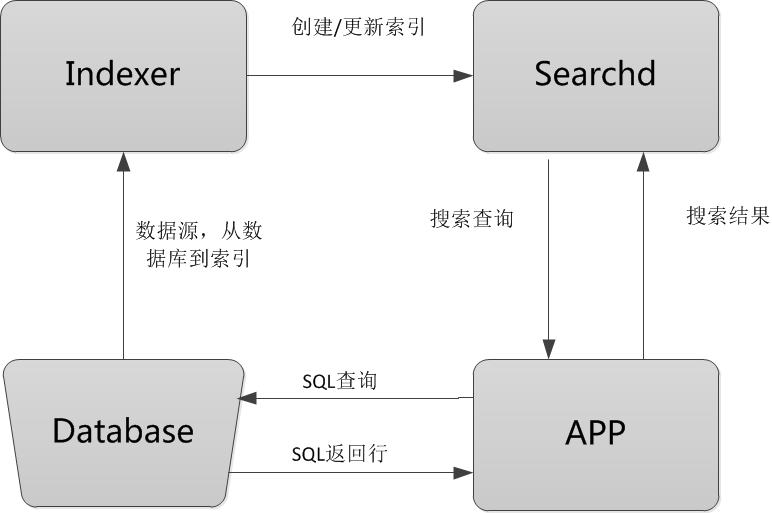
流程图解释
Database:数据源,是Sphinx做索引的数据来源。因为Sphinx是无关存储引擎、数据库的,所以数据源可以是MySQL、PostgreSQL、XML等数据。
Indexer:索引程序,从数据源中获取数据,并将数据生成全文索引。可以根据需求,定期运行Indexer达到定时更新索引的需求。
Searchd:Searchd直接与客户端程序进行对话,并使用Indexer程序构建好的索引来快速地处理搜索查询。
APP:客户端程序。接收来自用户输入的搜索字符串,发送查询给Searchd程序并显示返回结果。
Sphinx的工作原理
Sphinx的整个工作流程就是Indexer程序到数据库里面提取数据,对数据进行分词,然后根据生成的分词生成单个或多个索引,并将它们传递给searchd程序。然后客户端可以通过API调用进行搜索。
介绍了Sphinx工作原理以及Sphinx的配置之后,继续介绍在Sphinx中,负责做索引的程序Indexer是如何做索引的。
sphinx使用配置文件从数据库读出数据之后,就将数据传递给Indexer程序,然后Indexer就会逐条读取记录,根据分词算法对每条记录建立索引,分词算法可以是一元分词/mmseg分词。下面先介绍Indexer做索引时使用的数据结构和算法。
数据源配置
先来看一份数据源的配置文件示例:
1 source test
2 {
3 type = mysql
4
5 sql_host = 127.0.0.1
6 sql_user = root
7 sql_pass = root
8 sql_db = test
9 sql_port = 3306 # optional, default is 3306
10
11 sql_query_pre = SET NAMES utf8
12 sql_query = SELECT id, name, add_time FROM tbl_test
13
14 sql_attr_timestamp = add_time
15
16 sql_query_info_pre = SET NAMES utf8
17 sql_query_info = SELECT * FROM tbl_test WHERE id=$id
18 }
其中
source后面跟着的是数据源的名字,后面做索引的时候会用到;
type:数据源类型,可以为MySQL,PostreSQL,Oracle等等;
sql_host、sql_user、sql_pass、sql_db、sql_port是连接数据库的认证信息;
sql_query_pre:定义查询时的编码
sql_query:数据源配置核心语句,sphinx使用此语句从数据库中拉取数据;
sql_attr_*:索引属性,附加在每个文档上的额外的信息(值),可以在搜索的时候用于过滤和排序。设置了属性之后,在调用Sphinx搜索API时,Sphinx会返回已设置了的属性;
sql_query_info_pre:设置查询编码,如果在命令行下调试出现问号乱码时,可以设置此项;
sql_query_info:设置命令行下返回的信息。
索引配置
1 index test_index
2 {
3 source = test
4 path = /usr/local/coreseek/var/data/test 5 docinfo = extern
6 charset_dictpath = /usr/local/mmseg3/etc/
7 charset_type = zh_cn.utf-8
8 ngram_len = 1
9 ngram_chars = U+3000..U+2FA1F
10 }
其中
index后面跟的test_index是索引名称
source:数据源名称;
path:索引文件基本名,indexer程序会将这个路径作为前缀生成出索引文件名。例如,属性集会存在/usr/local/sphinx/data/test1.spa中,等等。
docinfo:索引文档属性值存储模式;
charset_dictpath:中文分词时启用词典文件的目录,该目录下必须要有uni.lib词典文件存在;
charset_type:数据编码类型;
ngram_len:分词长度;
ngram_chars:要进行一元字符切分模式认可的有效字符集。
中文分词核心配置
一元分词
1 charset_type = utf8 2 3 ngram_len = 1 4 5 ngram_chars = U+3000..U+2FA1F
mmseg分词
1 charset_type = utf8 2 3 charset_dictpath = /usr/local/mmseg3/etc/ 4 5 ngram_len = 0
运行示例
数据库数据
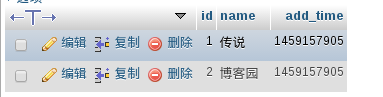
使用indexer程序做索引

查询

可以看到,配置文件中的add_time被返回了,如上图的1所示。而sql_query_info返回的信息如上图的2所示。
Sphinx的配置不是很灵活,此处根据工作流程给出各部分的配置,更多的高级配置可以在使用时查阅文档。
倒排索引
倒排索引是一种数据结构,用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
传统的索引是:索引ID->文档内容,而倒排索引是:文档内容(分词)->索引ID。可以类比正向代理和反向代理的区别来理解。正向代理把内部请求代理到外部,反向代理把外部请求代理到内部。所以应该理解为转置索引比较合适。
倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。
对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的不同单词,能否快速定位某个单词直接影响搜索时的响应速度,所以需要高效的数据结构来对单词词典进行构建和查找,常用的数据结构包括哈希加链表结构和树形词典结构。
倒排索引基础知识
- 文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。
- 文档集合(Document Collection):由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
- 文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
- 单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
Indexer程序就是根据配置好地分词算法,将获取到的记录进行分词,然后用倒排索引做数据结构保存起来。
分词算法
一元分词
一元分词的核心配置
charsey_type = zh_cn.utf8 ngram_len = ugram_chars = U+4E00..U+9FBF
ngram_len是分词的长度。
ngram_chars标识要进行一元分词切分模式的字符集。
原生的Sphinx支持的分词算法是一元分词,这种分词算法是对记录的每个词切割后做索引,这种索引的优点就是覆盖率高,保证每个记录都能被搜索到。缺点就是会生成很大的索引文件,更新索引时会消耗很多的资源。所以,如果不是特殊需求,而且数据不是特别少的时候,都不建议使用一元分词。
国人在sphinx的基础上开发了支持中文分词的Coreseek。Coreseek与Sphinx唯一的不同就是Coreseek还支持mmseg分词算法做中文分词。
mmseg分词
mmseg分词算法是基于统计模型的,所以算法的规则也是来自对语料库的分析和数学归纳,因为中文字符没有明确的分界,会导致大量的字符分界歧义,而且,中文里面,词和短语也很难界定,因此,算法除了要做统计和数学归纳之外,还要做歧义的解决。
在mmseg分词中,有一个叫chunk的概念。
chunk,是一句话的分词方式。包括一个词条数组和四个规则。
如:研究生命,有“研究/生命”和“研究生/命”两种分词方式,这就是两个chunk。
一个chunk有四个属性:长度、平均长度(长度/分词数)、方差、单字自由度(各单词条词频的对数之和)。
做好分词之后,会得到多种分词方式,这时候就要使用一些过滤规则来完成歧义的解决,以得到最终的分词方式。
歧义解决规则:
1、最大匹配
匹配最大长度的词。如“国际化”,有“国际/化”、“国际化”两种分词方式,选择后者。
2、最大平均词长度
匹配平均词最大的chunk。如“南京市长江大桥”,有“南京市/长江大桥”、“南京/市长/江大桥”三种分词方式,前者平均词长度是7/2=3.5,后者是7/3=2.3,故选择前者的分词方式。
3、最大方差
去方差最大的chunk。如“研究生命科学”,有“研究生/命/科学”、“研究/生命/科学“两种分词方式,而它们的词长都一样是2。所以需要继续过滤,前者方差是0.82,后者方差是0。所以选择第一种分词方式。
4、最大单字自由度
选择单个字出现最高频率的chunk。比如”主要是因为“,有”主要/是/因为“,”主/要是/因为“两种分词方式,它们的词长、方差都一样,而”是“的词频较高,所以选择第一种分词方式。
如果经过上述四个规则的过滤,剩下的chunk仍然大于一,那这个算法也无能为力了,只能自己写扩展完成。
最后的最后
当然,有人会说数据库的索引也可以做到sphinx索引,只是数据结构不一样而已,但是,最大的不同是sphinx就像一张没有任何关系查询支持的单表数据库。而且,索引主要用在搜索功能的实现而不是主要的数据来源。因此,你的数据库也许是符合第三范式的,但索引会完全被非规范化而且主要包含需要被搜索的数据。
另外一点,大部分数据库都会遭遇一个内部碎片的问题,它们需要在一个大请求里遭遇太多的半随机I/O任务。那就是说,考虑一个在数据库的索引中,查询指向索引,索引指向数据,如果数据因为碎片问题被分开在不同的磁盘中,那么此次查询将占用很长的时间。
总结
通过一个项目的实践,发现sphinx的使用要点主要在配置文件上,如果懂得配置了,那么基本用法很容易掌握。如果要深入研究,比如研究其工作原理,那就得查阅更多的资料。高级特性还没有用到,日后用到再做分享。最后,如果还想扩展sphinx,定制更强大的功能,可以直接阅读源代码,然后编写扩展。使用sphinx也有弊端,如果需要保证高质量的搜索,那么就要经常手动维护词库。如果不能保持经常更新词库,那么可以考虑百度搜索之类的插件。如果可以加入机器学习的话,那么会更好。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
如果本文对你有帮助,请点下推荐,写文章不容易。
[搜索引擎]Sphinx的介绍和原理探索的更多相关文章
- Sphinx的介绍和原理探索
What/Sphinx是什么 定义 Sphinx是一个全文检索引擎. 特性 索引和性能优异 易于集成SQL和XML数据源,并可使用SphinxAPI.SphinxQL或者SphinxSE搜索接口 易于 ...
- Sphinx 的介绍和原理探索——不存储原始数据,原始数据来源于SQL,而生成索引放在内存或者磁盘中
摘自:http://blog.jobbole.com/101672/ What/Sphinx是什么 定义:Sphinx是一个全文检索引擎. 特性: 索引和性能优异 易于集成SQL和XML数据源,并可使 ...
- [Node.js与数据库]node-mysql 模块介绍
[Node.js与数据库]node-mysql 模块介绍 转载至:https://itbilu.com/nodejs/npm/NyPG8LhlW.html#multiple-statement-q ...
- [干货]2017已来,最全面试总结——这些Android面试题你一定需要
地址.http://blog.csdn.net/xhmj12/article/details/54730883 相关阅读: 吊炸天!74款APP完整源码! [干货精品,值得收藏]超全的一线互联 ...
- Git之(一)Git是什么[转]
为什么使用Git 孔子曾经曰过的,名正则言顺 言顺则事成. 我们在学习一项新技术之前,弄清楚为什么要学它至关重要,至于为什么要学习Git,我用一段if-else语句告诉你原因: if(你相信我){ 我 ...
- 转载:AbstractQueuedSynchronizer的介绍和原理分析
简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础.使用的方法是继承,子类通过 ...
- [caffe]linux下安装caffe(无cuda)以及python接口
昨天在mac上折腾了一天都没有安装成功,晚上在mac上装了一个ParallelDesktop虚拟机,然后装了linux,十分钟就安装好了,我也是醉了=.= 主要过程稍微记录一下: 1.安装BLAS s ...
- [Swift]基础
[Swift]基础 一, 常用变量 var str = "Hello, playground" //变量 let str1="Hello xmj112288" ...
- [Ruby on Rails系列]4、专题:Rails应用的国际化[i18n]
1. 什么是internationalization(i18n)? 国际化,英文简称i18n,按照维基百科的定义:国际化是指在设计软件,将软件与特定语言及地区脱钩的过程.当软件被移植到不同的语言及地区 ...
随机推荐
- react-native 踩坑记
最近在使用react-native的时候遇到了很多坑,这里给大家分享下 一.样式 react-native 虽然支持flex布局,但是所有的样式均是css样式的一个很小的集合,尤其是在安卓机下问题尤为 ...
- NoSql数据库初探-mongoDB环境搭建
NoSQL数据库一改关系型数据库的缺点,更容易的集成.分布式.无模式.故障恢复等特点,正在一步步餐食关系型数据库的市场,作为一个与时俱进的码农了解一下新技术是必须的,尤其是在读了<NoSql精粹 ...
- OpenGL帧缓存对象(FBO:Frame Buffer Object)(转载)
原文地址http://www.songho.ca/opengl/gl_fbo.html 但有改动. OpenGL Frame BufferObject(FBO) Overview: 在OpenGL渲染 ...
- 初识node.js
Node.js不是一种语言:不是框架:也不是工具.它是用于运行基于JavaScript应用程序的运行时环境.
- Eclipse导入到最新版Android Studio详解
说到使用AndroidStudio,除了新建的项目,我们都会面临的问题是原先Eclipse的代码该怎么导入到AndroidStudio中使用.这方面相关的资料还比较少,自己摸索了一下,总结出这篇博客, ...
- C#改善程序的50种方法
作者: suyan010203 来源: 博客园 发布时间: 2011-07-09 14:47 阅读: 11976 次 推荐: 8 原文链接 [收藏] 从去年找工作以来,都没什么时间写博 ...
- FragmentActivity_左右滑动的碎片
test1.xml <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:an ...
- Vue - 在v-repeat中使用计算属性
1.从后端获取JSON数据集合后,对单条数据应用计算属性,在Vue.js 0.12版本之前可以在v-repeat所在元素上使用v-component指令 在Vue.js 0.12版本之后使用自定义元素 ...
- 分布式服务协调技术zookeeper笔记
本文主要学习ZooKeeper的体系结构.节点类型.节点监听.常用命令等基础知识,最后还学习了ZooKeeper的高可用集群的搭建与测试.希望能给想快速掌握ZooKeeper的同学有所帮助. ZooK ...
- gulp之压缩合并MD5清空替换加前缀以及自动编译自动刷新浏览器大全
gulp是基于流的前端构件化工具.目前比较火的前端构建化工具还是挺多的,grunt gulp fis3等等. 这个鬼东西有什么用?请参考https://www.zhihu.com/question/3 ...