Convolutional Neural Networks 笔记
1 Foundations of Convolutional Neural Networks
1.1 cv问题
图像分类、目标检测、风格转换。但是高像素的图片会带来许多许多的特征。
1.2 边缘检测(卷积操作)
图像和卷积核(滤波器)移动相乘。横向、纵向滤波器。过滤器里的值也是可以学习的。
1.3 Padding(补白)
卷积会使图像变小,丢掉部分边缘信息。所以需要将边缘补白,补充为0。
假设图片尺寸为n,卷积尺寸为f。卷积之后会变为n-f+1尺寸。
padd尺寸为p。valid convolution,不补白,会减小尺寸;same convolution,产生相同尺寸,p的计算公式如下。
\[
p=\frac{f+1}{2}
\]
f通常为奇数,原因一,如果f为偶数,padding是不对称的。原因二,将会有一个中心元素。
1.4 Strided convolution(跨距离卷积)
每次卷积移动的距离从1改变,stride的距离记为s
卷积后的尺寸为。不能整除时向下取整。过滤器必须全部落在原始图像或者填充图像之上,落在之外就舍弃。
\[
\frac{n+2p-f}{s}+1
\]
教课书上的卷积还需要对滤波器进行上下左右翻转。而实际在神经网络中使用的应该叫做cross-correlation(交叉相关)。
1.5 三维上卷积
例子:RGB图像的认为图像大小为(6,6,3),滤波器为(3,3,3),卷积结果为(4,4)。
(height,weight,channel),一般滤波器的channel和图像是一样的。
多个滤波器最后结果变为结果中的多个channel。channel也被叫做depth。
1.6 卷积网络层
卷积+bias->激活
参数就是滤波器的元素个数,无论输入多大,需要学习的参数都不变。
如果第l层是卷积层,则参数表示为。

1.7 简单的卷积网络例子
一层一层卷积,到最后一层把他铺平,然后加上一个逻辑回归或者softmax,得到预测值。
中间每层的f/s/p都是超参数
多数卷积网路都是由conv+pooling+fully connected
1.8 pooling层(池化)
1.8.1 max pooling
将原来的分为n个区域,由f和s确定。然后将每个区域中最大的拿出来。
可以理解为保留了最大的特征。但是人们常用最大池化是因为实际中好用。
不需要去学习参数,只需要调节f/s两个超参数。padding基本不用。
1.8.1 average pooling
求平均值,在卷积网络中,最大池化比平均池化用的多得多。
1.9 CNN例子
一般认为有权重的层才是一个层,这里将一个卷积层和一个池化层认为是一层。
超参数一般可以参考别人的论文。
结构一般是(1-n个)conv -> pooling ->(1-n个)conv -> pooling -> ... ->(1-n个) fully connected layer -> 输出
参数在卷积层不多,主要集中在全连接层。
activation size一般是慢慢缩小的,不会特别快。
1.10 为什么卷积
参数共享
需要训练的参数少
稀疏连接
每一个输出只和前一层的一块连接
1.11 卷积网路反向传播
1.11.1 卷积层
我的理解是使用过滤器和通过过滤器的结果Z的导数反推原来的层。
\[
dA+=\sum^{n_H}_{h=0}\sum^{n_W}_{w=0}W_c \times dZ_{hw}
\]
\[
dW_c+=\sum^{n_H}_{h=0}\sum^{n_W}_{w=0}a_{slice} \times dZ_{hw}
\]
\[
db=dW_c+=\sum^{n_H}_{h=0}\sum^{n_W}_{w=0}dZ_{hw}
\]
1.11.2 池化层
池化层没有参数,但是为了能计算其他参数的导数,还是需要计算池化层的反向传播。
最大池化
找出最大值所在的位置,生成一个和池化滤波器一样尺寸的矩阵(mask),只有最大位置为1,然后和池化后结果的导数相乘,就是最大池化的反向传播。
\[
X = \begin{bmatrix}
1 && 3 \\
4 && 2
\end{bmatrix} \quad \rightarrow \quad M =\begin{bmatrix}
0 && 0 \\
1 && 0
\end{bmatrix}
\]
\[
dZ_{pre} =dZ \times M
\]
平均池化
因为是平均的,所以每个的作用相同,所以将dZ评分,就是平均池化的反向传播。
\[
dZ = 1 \quad \rightarrow \quad dZ =\begin{bmatrix}
1/4 && 1/4 \\
1/4 && 1/4
\end{bmatrix}
\]
2 Case study
2.1 Classic Networks
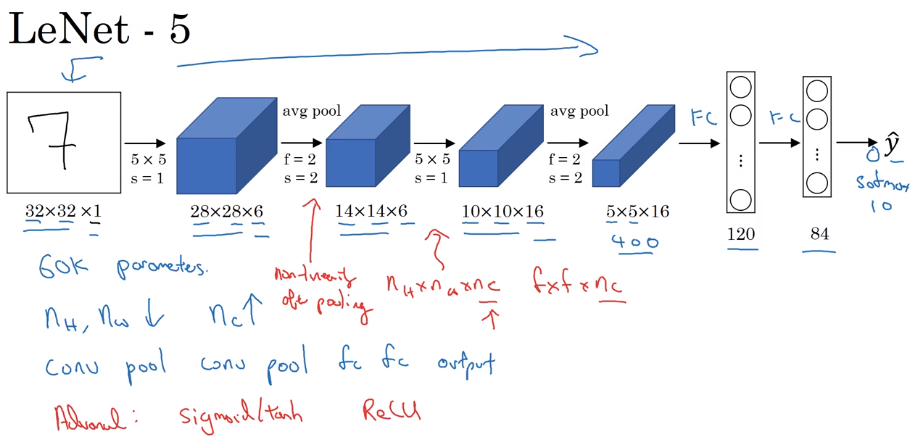
2.1.1 LeNet-5
已经使用了现在常用的conv -> pool -> conv -> pool -> fc -> fc -> output这种结构。
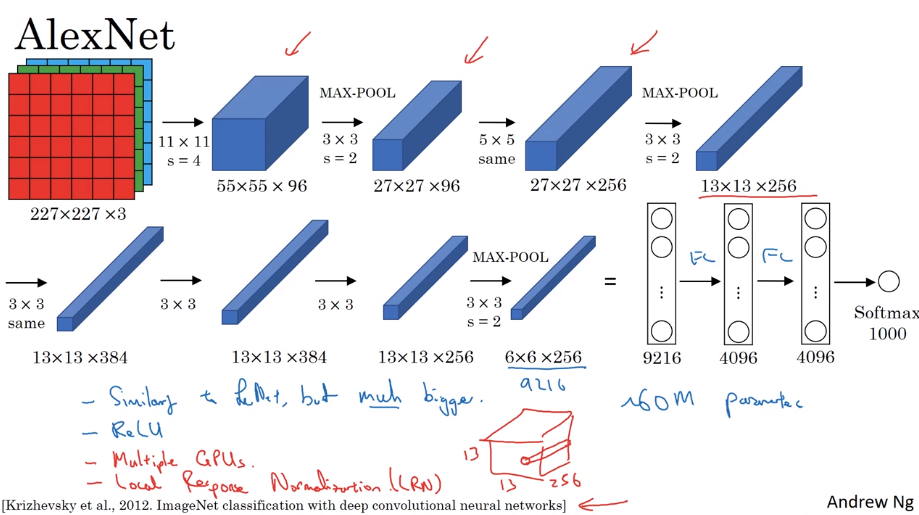
2.1.2 AlexNet
和LeNet相似,使用了ReLu
2.1.3 VGG-16
网络很深,结构简单,但很特殊。filter一直翻倍。

2.2 ResNets
2.2.1 定义
残差块(Residual block)
将前两层的内容内容通过short cut连接到本层激活函数之前。这样能够训练更深层的网络。将普通网络变为残差网络,就是将每两层变成一个残差块。
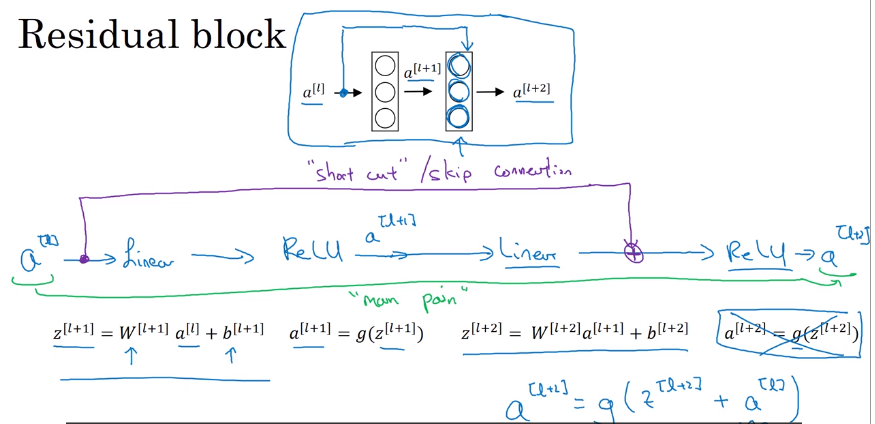
理论上纯神经网络的层数增加将减少训练误差,但是实际中当层数增加到一定成都,误差将会上升。
残差网络在实际中层数增加,训练误差就会减少。有利于训练深层网络。
2.2.2 为什么残差网络好用
残差网络使得加入的层不会有害于当前的结果。所以可以使网络层数增多。更多的情况是你增加的网络恰好识别到了一些新的特性,使得网络性能更好。
残差网络做shortcut需要相同的维度,卷积经常是same。如果维度不同,一般是加入一个新的变量使得维度相同,这个变量可以学习,也可以手动选择。一般变化维度是由pooling,需要加维度变量。
2.3 one by one 卷积
可以认为是个全连接层。也叫network in network。
用来减少层数(nC)。
2.4 Inception Network
2.4.1 动机
使用所有可能的卷积方法,让网络来选择用哪个。这个是inception block.
但是计算花费比较高,可以加入一个1*1卷积层,减少计算量。这里回影响性能么?吴恩达说不会影响。
2.4.2 建立
将inception block拼接起来。
还有一些side branch。使用隐层做全连接,然后softmax做预测。这个说明中间层对于预测结果来说也不算差,这是对inception network的正则化,防止过拟合。
这个网络用了盗梦空间做动机??
2.5 实际中的建议
2.5.1 使用开源实现
使用作者的开源代码,因为作者在文章中说的可能不够,有些在代码里。
2.5.2 迁移学习
使用作者预训练的网络做迁移学习。他人训练的网络可能花费了很多时间,算力。可以节约你的时间。另外,另外你的训练集很小。改变输出层,冻结前面的层,只训练输出层。数据越多,冻结的层可以更少,甚至可以不冻结。
2.5.3 数据扩增
镜像,随机裁剪,rotation,shering,local warping,color shifting(pca color augmentation,对于主要成分的颜色改变的多,次要的改变的少)
实际中,一般在训练中进行畸变,使用另外的线程来进行畸变,和训练并行进行。
2.6 CV现状
图像识别和目标检测还没有较多的数据。还需要更多的数据。所以需要人工设计。
数据越多,可以使用简单的算法并减少人工设计
2.6.1 在benchmark表现好的一些技巧
但是在实际中效果并不会特别好:
ensembling(集成):训练多个网络,然后平均输出。但是会用更长的时间。
multi-crop at test time :平均多次剪切的
使用开源代码:别人公开的结构、实现代码、预训练(调试)结果。
3 Object Detection
3.1 Object Localization(目标定位)
不仅要分类(classification),还需要对目标进行定位(localization)。
检测并定位目标位置(detection)。图片上会有多个目标。
定位输出包括分类和四个额外的数字,表达边界框bx,by,bh,bw。例子中,实际的y包括[pc,bx,by,bh,bw,c1,c2,c3]。pc表示是否有物体。pc是指chance of object的概率。
loss function:当y1=1时,使用y中的每一个计算loss。当y1=0时,只关心y1。y1表示图片中是否有物体。可以将y中每一项都使用L2 loss,也可以对于分类项使用log的loss。
3.2 Landmark Detection(地标检测)
landmark可以理解为标志点,例如面部识别时的眼角,嘴角这类。
选择许多个landmark,使用一个卷积网络训练,输出为是否有脸+许多landmark的坐标lx,ly。
landmark的顺序在训练中必须保持。
3.3 sliding windows detection
使用一个小的框,判断窗里的内容,然后滑动整个图,再增大,判断,滑动,重复。
滑动窗口检测的计算成本很大。之前分类器计算一个分类比较简单,所以可以用。现在的卷积网络计算比较复杂,会计算很慢很慢,而且只有使用很小的步长,才能获得精确的目标位置。
3.4 全连接层的卷积实现
假设l层想和l+1层全连接,将l层之后的滤波器的大小设置为l层的大小,然后个数n就是l+1的节点个数。然后卷积,实际上就和全连接一样。
3.4 滑动窗的卷积实现
将目标图像共享分类器权重,然后直接卷积,最后结果会是多个滑动窗的分类结果。可以将滑动过程变成一次计算。
3.5 边界框预测
上面使用卷积方式实现滑动窗可以简化计算,但是有边界框不准确的问题,过大,或者边界框只能包含目标的部分。
3.5.1 YOLO
全称是:You Only Look Once
将图片分块(19*19),然后输出特征变为[pc(是否存在目标中心点),bx,by,bh,bw,c1,c2,c3,...]。将输出层变为19*19*特征维度。将图片经过各种卷积、池化等,最终做到和目标输出层大小相同,然后训练。其中bx,by,bh,bw是相对于块的,bx,by取值0-1中间,bh,bw可以大于1,这个值是百分比。
使用目标中心点,可以让目标只出现在一个块。而且一个块中出现多个目标的概率变小。
yolo优点,第一,将直接输出准确的边界框,不受限于滑动窗的步长。第二,使用卷积网络,将直接输出所有块的结果,不需要再每一块上运行一遍。
3.6 Intersection Over Union(交并比)
解决计算定位框准确性问题。
计算两个边界框的交叉部分除以预测框大小。
\[
IoU=\frac{两个框交集大小}{两个框并集大小}
\]
一般认为当IoU>=0.5是预测正确。阈值0.5可以改,很少改为小于0.5的。
3.7 Non-max Suppression(非极大抑制)
进行目标检测时,一个目标可能被检测到多次,非最大抑制确保对每个对象只检测到一次。
抑制不是最大\(p_c\)的框。
目标检测会对一个目标产生几个可能的边界框,抑制其中可能性(\(p_c\))较小的,只保留最大的框。
实际操作:
- 找到\(p_c\)最大的框,输出为一个预测框
- 将所有与输出框\(IoU \ge 0.5\)的框都丢弃
循环上面两步操作。对于多分类问题,需要将每个分类单独做。
3.8 Anchor Boxes(锚盒)
解决重叠的问题。之前的想法只能一个格子一个物体,解决一个格子多个物体。
将y的特征描述扩展。设置两个不同方向的锚盒。对于一个格子,使用两个锚盒同时检测。获得两倍的y特征,分别表示两个锚盒的结果。
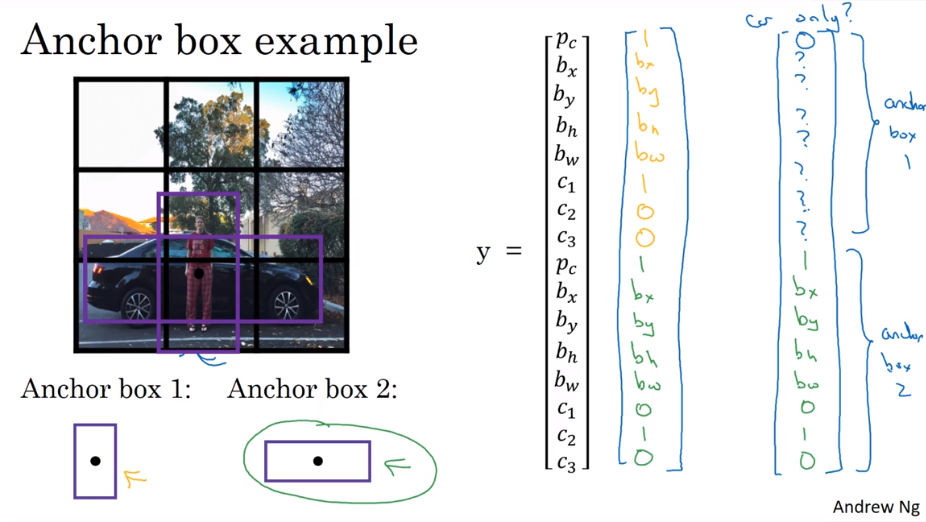
例子中,锚盒只能解决同一个格子中有两个不同方向的物体的检测。但是实际中,同一个格子有多个物体很少见。确切地说是只能解决和锚盒数量相同的重叠,且每个重叠的方向需要和锚盒尺寸相同,如果有两个都和同一个锚盒相同,也不能解决,锚盒可以选多个。
锚盒的选择有许多种,还可以用knn的方法自动选择。
3.9 YOLO算法流程
第一步,训练,使用锚盒。一个图像经过卷积最后变成期望的大小。
第二步,输出,然后做非最大抑制,得到结果。
3.10 Region proposals(候选区域)
不在使用滑动窗的方法,而是使用segmentation算法,发现图片中可能有目标的区域,然后对这些区域运行目标检测。叫R-CNN。
R-CNN。判断每一个候选区域,将输出给定区域的标签和边界框。
Fast R-CNN。将候选区域判断判断变成卷积算法。
Fster R-CNN,使用卷积方法获取候选区域。
吴恩达认为这个方法还是比YOLO慢。而且R-CNN将问题分成两步,不如YOLO一步完成好。
4 Special applications
4.1 Face Recognition介绍
百度的人脸识别+活体识别
对于人脸识别,一般分为人脸验证和人脸识别两部分。
验证:输入一个图片和id,判断图像和id是否匹配。1对1的
识别:有一个k人的数据库,输入一个图片,给出这个人的id/或不在数据库中。1对多的。将上面的验证应用到数据库的所有图片中,时间k倍,并且总识别率会降低。
吴恩达课程关注在验证上,当验证的正确率很高,识别正确率也会很高。
4.2 One Shot Learning(单样本学习)
人脸验证问题一般只给一个人一张图片,但是只有一个样本在深度学习里效果不好。如果输入图片,输出人的分类,样本少,而且不易加入新的人。
解决办法是学习相似性函数,输入两个图片,输出他们的不同(difference)。当输出d小于某个值,认为相同,大于认为不同。
4.3 Siamese Network
将图片输入到卷积网络,最后输出一组特征向量。比较两个图片的输出特征的距离。
\[
d \left( x ^ { ( 1 ) } , x ^ { ( 2 ) } \right) = \left\| f \left( x ^ { ( 6 ) } \right) - f \left( x ^ { 0.3 } \right) \right\| _ { 2 } ^ { 2 }
\]
怎么训练?
使相同人的特征距离近,不同人的特征距离远。
4.4 Triplet Loss(三元组损失)
训练上面的输出。学习目标是
让图片和相同人的距离近,不同人的距离远。如下面的公式所示。但是如果两个计算出来距离都为0,也会满足,所以加上一个α,被称为margin。α能够拉大正确的一对图片的距离和错误的图片距离差。公式中A表示ankle,P表positive,N表示negetive。
\[
\| f ( A ) - f ( P ) \| ^ { 2 } + \alpha \leqslant \| f ( A ) - f ( N ) \| ^ { 2 }
\]
\[
\| f ( A ) - f ( P ) \| ^ { 2 } - \| f ( A ) - f ( N ) \| ^ { 2 } + \alpha \leqslant 0
\]
4.4.1 Loss / Cost Function
loss function如下所示。若两个的距离为负数,则说明符合上面的不等式,loss为0。若两个距离为正数,表明不满足上面的不等式,则有loss。
\[
L ( A , P , N ) = \max \left( \left[ \| f ( A ) - f ( P ) \| ^ { 2 } - \| f ( A ) - f ( N ) \| ^ { 2 } + \alpha , 0 \right)\right.
\]
cost function如下所示。训练集需要每个人有多张照片。
\[
J=\sum^m_{i=1}L(A^{(i)},P^{(i)}, N^{(i)})
\]
4.4.2 如何选择A,P,N
如果随机选择,满足之前的不等式会很容易。应该选择d(A, P)和d(A, N)相近的,然后训练,是他们远离。
4.5 Face Verification and Binary Classification
将人脸验证训练为一个二分类问题,可以取代三元损失方法。就是在两个图片最后的特征后,加入一个二分类节点,然后训练。二分类的输入是两个特征相减。
\[
\hat { y } = \sigma \left( \sum _ { k = 1 } ^ { 128 } i _ { i } \left| f \left( x ^ { ( i ) } \right) _ { k } - f \left( x ^ { ( j ) } \right) _ { k } \right| + b \right)
\]
其中相减部分也可以换为
\[
\frac{(f(x^{(i)})_k-f(x^{(j)})_k)^2}{f(x^{(i)})_k+f(x^{(j)})_k}
\]
在实际系统中,不需要存储原始图片信息,可以之存储图像的特征。然后计算实际图片特征,然后进行二分类。
4.6 Neural Style Transfer介绍
使用原始图片(content[C])和一个风格图片(style[S]),生成一个使用风格画的原始图片的生成图片(generated[G])。
4.7 深度卷积网络在学习什么
取每一层使得某个隐层单元激活最大的9张图片,可以看出,层数越深,看到的特征越复杂,从最初的边/颜色,到之后的人/狗/车轮。
4.8 画风迁移的Cost Function
代价函数分为两部分,第一部分判断和内容图片的差距,第二部分判断和风格图片的差距。这里用了两个超参数来表示风格占比,起始可以用一个参数解决,只是作者用了两个。
\[
J(G)= \alpha J_{Content}(C, G)+ \beta J_{Style}(S, G)
\]
画风迁移的过程:随机初始化G,然后使用梯度下降让J减小。
4.8.1 Content Cost Function
选择隐层个数,不要太浅或者太深,如果太浅,会使得每个像素和原始图像非常接近;如果太深,会使得如果原始图像有条狗,生成图像一定会有。
使用预训练的网络
\[
J^{[l]}_{Content}(C, G) = \frac{1}{2}||a^{[l](C)}-a^{[l](G)}||^2
\]
其中\(a^{[l](C)}\)和\(a^{[l](G)}\)表示l层C和G的激活。如果相似,则a会相似。
4.8.2 Style Cost Funtion
计算不同通道的“互协方差”。但是这里的互协方差定义和一般定义有区别。
计算“互协方差”:
\[
G^{[l]}_{kk^{\prime}}=\sum^{n^{[l]}_H}_{i=1} \sum^{n^{[l]}_W}_{j=1} a^{[l]}_{ijk}a^{[l]}_{ijk^{\prime}}
\]
对于其中一层:
\[
J _ { \text {style} } ^ { [ l ] } ( S , G ) =||G _ { k k ^ { \prime } } ^ { [ l ] ( S ) }-G _ { k k ^ { \prime } } ^ { [ l ] ( G ) }||^2_F
\]
\[
J _ { \text {style} } ^ { [ l ] } ( S , G ) = \frac { 1 } { \left( 2 n _ { H } ^ { [ l ] } n _ { W } ^ { [ l ] } n _ { C } ^ { [ l ] } \right) ^ { 2 } } \sum _ { k } \sum _ { k ^ { \prime } } \left( G _ { k k ^ { \prime } } ^ { [ l ] ( S ) } - G _ { k k ^ { \prime } } ^ { [ l ] ( G ) } \right)
\]
总的代价函数可以将前面的都求和
\[
J_{Style}(S, G)=\sum_{l} \lambda^{[l]}(S,G)
\]
λ就是表示某一层占有的比重,通常使用单个隐藏层就可以了。
4.9 1D and 3D Generalizations(向1维和3维推广卷积)
类似心电/肌电,就是1维数据。将滤波器变成1维的。但是一般用RNN模型更常见。
3维数据相当于加入了depth,使用3维的滤波器。同时可以加入channel,滤波器变成4维数据。例如ct,也可以认为是电影数据,把每一帧认为是depth。
Convolutional Neural Networks 笔记的更多相关文章
- Bag of Tricks for Image Classification with Convolutional Neural Networks笔记
以下内容摘自<Bag of Tricks for Image Classification with Convolutional Neural Networks>. 1 高效训练 1.1 ...
- 深度学习笔记 (一) 卷积神经网络基础 (Foundation of Convolutional Neural Networks)
一.卷积 卷积神经网络(Convolutional Neural Networks)是一种在空间上共享参数的神经网络.使用数层卷积,而不是数层的矩阵相乘.在图像的处理过程中,每一张图片都可以看成一张“ ...
- 阅读笔记 The Impact of Imbalanced Training Data for Convolutional Neural Networks [DegreeProject2015] 数据分析型
The Impact of Imbalanced Training Data for Convolutional Neural Networks Paulina Hensman and David M ...
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 【论文笔记】Learning Convolutional Neural Networks for Graphs
Learning Convolutional Neural Networks for Graphs 2018-01-17 21:41:57 [Introduction] 这篇 paper 是发表在 ...
- 论文笔记——MobileNets(Efficient Convolutional Neural Networks for Mobile Vision Applications)
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications MobileNet由Go ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
随机推荐
- [原创]java WEB学习笔记02:javaWeb开发的目录结构
本博客为原创:综合 尚硅谷(http://www.atguigu.com)的系统教程(深表感谢)和 网络上的现有资源(博客,文档,图书等),资源的出处我会标明 本博客的目的:①总结自己的学习过程,相当 ...
- Charles进行HTTPS抓包(iOS为例)
各种抓包工具的原理都是一样的,使用方面也都是差不多的,因为最近在用Mac,所以抓包工具开始用Charles了,记录一下抓取HTTPS的步骤. 连接代理, 开启抓包工具, 手机设置代理服务器,端口号(默 ...
- EntityFramework 学习 一 Spatial Data type support in Entity Framework 5.0
MS SQl Server引进两种特殊的数据类型geography and geometry public partial class Course { public Course() { this. ...
- 算法(Algorithms)第4版 练习 2.2.9
package com.qiusongde; import edu.princeton.cs.algs4.In; import edu.princeton.cs.algs4.StdOut; publi ...
- SpringCloud-服务的消费者(rest+ribbon)
SpringCloud-服务的消费者(rest+ribbon) 在微服务架构中,业务都会被拆分成一个独立的服务,服务与服务的通讯是基于http restful的.Spring Cloud有两种服务调用 ...
- ffmpeg 获取视频宽高
int main(int argc, char *argv[]) { const char* file_name = "video.mp4"; int ret; unsigned ...
- WCF REST开启Cors 解决 No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://localhost' is therefore not allowed access. The response had HTTP status code 405.
现象: 编写了REST接口: [ServiceContract] public interface IService1 { [OperationContract] [WebInvoke(UriTemp ...
- Linux下开放防火墙端口
方法一:1.vi /etc/sysconfig/iptables 2.-A INPUT -m state --state NEW -m tcp -p tcp --dport 8080 -j ACCEP ...
- 一个基于特征向量的近似网页去重算法——term用SVM人工提取训练,基于term的特征向量,倒排索引查询相似文档,同时利用cos计算相似度
摘 要 在搜索引擎的检索结果页面中,用户经常会得到内容相似的重复页面,它们中大多是由于网站之间转载造成的.为提高检索效率和用户满意度,提出一种基于特征向量的大规模中文近似网页检测算法DDW(Det ...
- MyBaties--Mapper configuration
method one: <!-- Using classpath relative resources --> <mappers> <mapper resource=&q ...