机器学习Hands On Lab
fetch_data
fetch_mldata默认路径是在scikit_learn_data路径下,mnist的mat文件其实直接放置到scikit_lean/mldata下面即可通过fetch_mldata中获取;当然路径信息其实是fetch_home函数中定义的;
洗牌训练数据
为了避免数据的有序对于训练的影响,有的时候需要对于数据进行随机排列;比如对于7万个手写数字的样本,前60000个做训练集,这6万个需要通过np.random.permutation(60000)来进行随机重排,也成为洗牌(shuffle)。但是这种洗牌主要用于样本本身不具备顺序性;但是对于一些样本之间具有关联系,比如具有时间排序联系(股票,天气)则尽量避免洗牌操作,因为训练的本身就是具有训练时序性。
唉,在做手写体测试的时候,每次执行从洗牌到训练到验证(sdg_clf.predict([some_digit]))的时候发现经常执行结果不一样,有的时候能够识别some_digit为5,有的则识别不出来。
scores和predict的差别
注意模型的scores和predict的差别,前者其实是对于样本可能是某个值的一种可能值;后者则是直接根据X预测y,在分类算法里面,predict返回的就是分类类别,里面本质上是计算某个用例在各个分类中的概率,选择概率最大的那个;
用decision_function来代替predict,前者返回的内容scores;scores现在我的理解是对于二元/多元计分,通常是根据分值最大的那个分类作为predict的返回值(所以predict在内部实现是是先调用decision_function,然后再自行判断类别),所谓分值的阈值也是判断是否的分割线;那么对于多分类的处理是怎样的呢?
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
其中分值(scoring)的种类如下表所示:
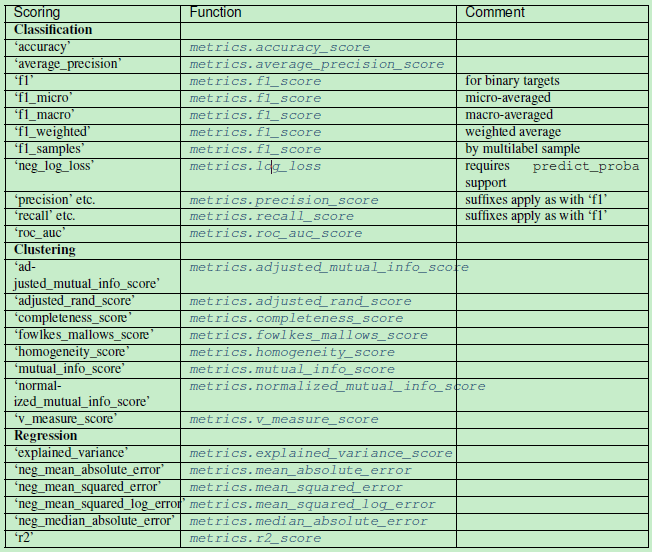
参考:
http://scikit-learn.org/stable/modules/model_evaluation.html
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42))
这个random_state是做什么的?一个算法只要指定了random_state,就可以保证每次产生的随机数都是一致的,可以保证多次运行产生的模型一致;很多时候是测试阶段为了获取稳定测试效果会如此处理;在生产环境很多场景是需要随记的;主要还是看应用场景,是否需要random_state。
机器学习Hands On Lab的更多相关文章
- 机器学习中jupyter lab的安装方法以及使用的命令
安装JupyterLab使用pip安装: pip install jupyterlab# 必须将用户级目录添加 到环境变量才能启动pip install --userbinPATHjupyter la ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 视觉机器学习------K-means算法
K-means(K均值)是基于数据划分的无监督聚类算法. 一.基本原理 聚类算法可以理解为无监督的分类方法,即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类.聚 ...
- paper 118:计算机视觉、模式识别、机器学习常用牛人主页链接
牛人主页(主页有很多论文代码) Serge Belongie at UC San Diego Antonio Torralba at MIT Alexei Ffros at CMU Ce Liu at ...
- 机器学习&数据挖掘笔记_13(用htk完成简单的孤立词识别)
最近在看图模型中著名的HMM算法,对应的一些理论公式也能看懂个大概,就是不太明白怎样在一个具体的机器学习问题(比如分类,回归)中使用HMM,特别是一些有关状态变量.观察变量和实际问题中变量的对应关系, ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- Leetcode 74
class Solution { public: bool searchMatrix(vector<vector<int>>& matrix, int target) ...
- Xshell如何设置,当连接断开时保留Session,保留原文字
Xshell [1] 是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议.Xshell 通过互联网到远程主机的安全连接以及它 ...
- SSM框架整合(实现从数据库到页面展示)
SSM框架整合(实现从数据库到页面展示) 首先创建一个spring-web项目,然后需要配置环境dtd文件的引入,环境配置,jar包引入. 首先让我来看一下ssm的基本项目配件.(代码实现) 1.首先 ...
- OC NSArray数组排序
一.一般排序 // 排序 NSArray *arr = @["]; NSArray *newarr = [arr sortedArrayUsingSelector:@selector(com ...
- Idea安装及其简介
Idea现有设置 Idea重新安装步骤 卸载开始 D:\devsoft\jet\env\maven\global\wonders\settings.xml ...
- 0001——初涉MySQL
MySQL是一个开源的关系型数据库管理系统. MySQL分为社区版本和企业版 MySQL安装方式: 1.MSI安装(Windows Installer) 2.ZIP安装 选择安装类型: 1.T ...
- cas AssertionThreadLocalFilter
AssertionThreadLocalFilter AssertionThreadLocalFilter作用很简单,就是将Assertion绑定到ThreadLocal. ThreadLocal 无 ...
- Thinking in Java笔记之类及对象的初始化
最近在看<Thinking in Java>这本书,之前一直对类及对象的初始化过程不太清楚,只是感到很模糊.看了这本书关于对象初始化的部分,终于搞明白了. 废话不多说,先上两个例子,实例摘 ...
- EXCEL FAQ
1.win7双击打开EXCEL07时显示停止工作,但是在打开方式中可以打开,怎么破? 加载项的问题,在选项-信任中心-信任中心设置-加载项-禁用所有应用程序加载项即可,但是这样会丧失一些功能,也可以把 ...
- L1-017 到底有多二
一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值.如果这个数是负数,则程度增加0.5倍:如果还是个偶数,则再增加1倍.例如数字-13142223336是个11位数,其中有3个2,并且是负 ...