Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例。
1.准备工作
首先需要在你电脑上安装jdk和scala以及开发工具Intellij IDEA,本文中使用的是win7系统,环境配置如下:
jdk1.7.0_15
scala2.10.4
scala官网下载地址:http://www.scala-lang.org/download/
如果是windows请下载msi安装包。
这两个可以在官网上下载jdk和scala的安装包就可以直接双击安装包运行安装即可。注意:如果以后是在本地编写好spark代码然后上传到spark集群上去运行的话,请一定保持两者的开发环境一致,不然会出现很多错误。
Intellij IDEA
在官网上下载一般选择右下角的Community版本,下载地址https://www.jetbrains.com/idea/download/#section=windows
2.在Intellij IDEA中安装scala插件
安装好Intellij IDEA并进入idea的主界面
(1)找到右下角的Configure选项中Plugins并打开

(2)点击左下角Browse repositories…

(3)在搜索框里搜scala,出现相对于的Scala插件,这里面我的已经安装完成了,没安装的会显示install的字样以及相对于的版本,这里面不建议在线安装插件,建议根据Updated
2014/12/18去下载离线的scala插件,比如本文中的IDEA
Updated日期是2014/12/18然后找到对应的插件版本是1.2.1,下载即可。下面是scala插件的离线下载地址。

scala插件离线下载地址:https://plugins.jetbrains.com/plugin/1347-scala
然后根据Update日期去找Intellij IDEA对应得scala插件,不同版本的IDEA对应的scala插件不一样,请务必下载对应的scala插件否则无法识别。

(4)离线插件下载完成后,将离线scala插件通过如下方式加入到IDEA中去:点击Install plugin from disk…,然后找到你scala插件的zip文件的本机磁盘位置,点ok即可

到这里,在Intellij IDEA中安装scala插件的步骤已经全部完成。接下来用IDEA来构建一个Maven工程,用来搭建spark开发环境。
3.Intellij IDEA通过Maven搭建spark环境
(1)打开IDEA新建一个maven项目,如下图:
注意:按照我步骤顺序即可。
注意:如果是第一次利用maven构建scala开发spark环境的话,这里面的会有一个选择scala SDK和Module SDK的步骤,这里路径选择你安装scala时候的路径和jdk的路径就可以了。

(2)填写GroupId和ArtifactId这里我就随便写了个名字,如下图,点Next。

(3)第三步很重要,首先是你的Intellij
IDEA里有Maven,一般的新版本都会自带maven,而且maven的目录在IDEA安装路径下plugins下就能找到,然后再Maven
home
directory地址中填写maven相对应的路径,本文中的IDEA版本比较老,是自己下的Maven安装上的(不会的可以百度下,很简单,建议使用新的IDEA,不需要自己下载maven)。然后这里面的User
settings file是你maven路径下conf里面的settings.xml文件,勾选上override即可,这里面的Local
repository路径可以不用修改,默认就好,你也可以新建一个目录。点击Next。
注意:截图的时候忘了,把Local repository前面的override也勾选上,不然构建完会报错,至少我的是这样。

(4)填写自己的项目名,随意即可。点击finish。

(5)到这里整个流程已经结束,完成后会显示如下界面:
右上角的import需要点击一下即可。

(6)接下来在pom.xml文件中加入spark环境所需要的一些依赖包。以代码的方式给出,方便复制。
这里是我的pom文件代码,请各位自行按照自己的需要删减或添加依赖包。
//注意这里面的版本一定要对应好,我这里的spark版本是1.6.0对应的scala是2.10,因为我是通过spark-core_${scala.version}是找spark依赖包的,前些日子有个同事按照这个去搭建,由于版本的不一样最后spark依赖包加载总是失败。请大家自行检查自己的版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xudong</groupId>
<artifactId>xudong</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>1.6.0</spark.version>
<scala.version>2.10</scala.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.39</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<!-- maven官方 http://repo1.maven.org/maven2/ 或 http://repo2.maven.org/maven2/ (延迟低一些) -->
<repositories>
<repository>
<id>central</id>
<name>Maven Repository Switchboard</name>
<layout>default</layout>
<url>http://repo2.maven.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
</build>
</project>这里要注意下几个小问题:
这里面会有src/main/scala和src/test/scala需要你自己在对应项目目录下构建这两个文件夹路径,若不构建会报错。

到这里,基于scala的一个spark开发环境就基本结束了。接下来,用scala编写一个spark的简单示例,wordcount程序,如果有的同学编写过MapReduce一定会很熟悉。
如果不能创建scala文件则
还是在Project Structure界面,操作如下。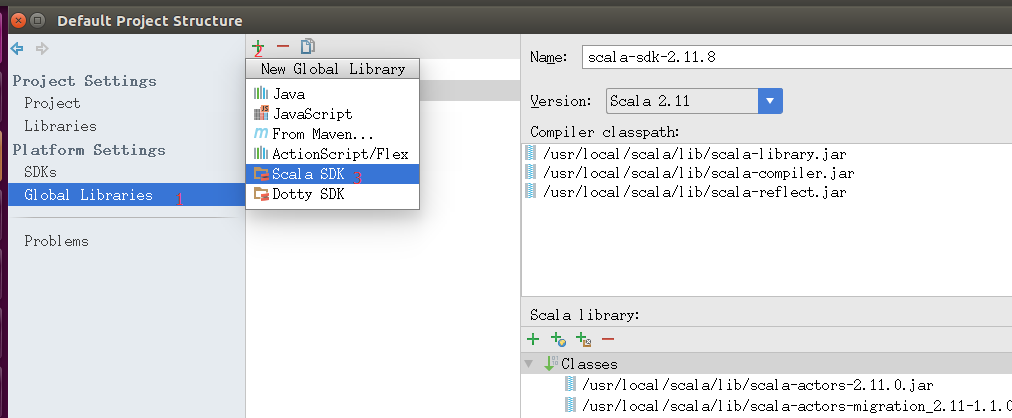
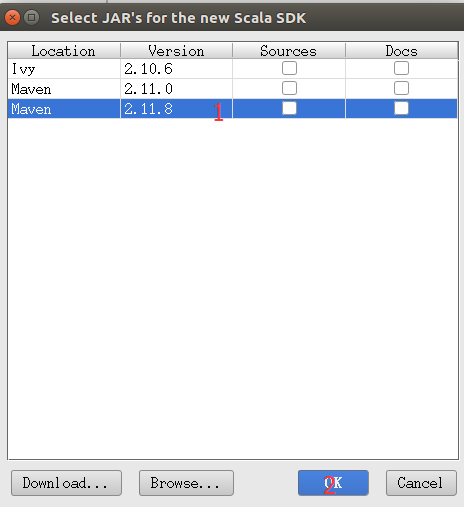
然后我们右键我们添加的SDK选择Copy to Project Libraries...OK确认。如图
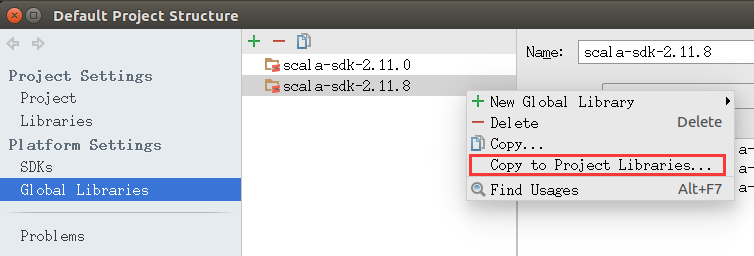
配置好后我们就可以创建工程文件了。
4.Spark简单示例Wordcount
src/main/scala文件夹下,右键新建Package,输入package的名字,我这里是com.xudong然后新建Scala class, 然后输入名字将类型改为object,如下图:

补充:
如果一开始没有在项目中加入scala的SDK,这个时候,新建Scala class会发现没有这个选项,这个时候你新建一个File文件,然后名字随便取一个,后缀改成 .scala* ,点ok后文件中空白区会显示没有scala的SDK,这个时候你点击提示信息就可以添加本地的scala SDK(提前你的电脑上已经安装了scala,这个时候它会自动的去识别SDK),以后新建Scala class就有这个选项,直接新建即可。*
创建完然后编写wordcount代码,代码如下(并注释了相关的解释):
package com.xudong
import org.apache.spark.mllib.linalg.{Matrices, Matrix}
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Administrator on 2017/4/20.
* xudong
*/
object WordCountLocal {
def main(args: Array[String]) {
/**
* SparkContext 的初始化需要一个SparkConf对象
* SparkConf包含了Spark集群的配置的各种参数
*/
val conf=new SparkConf()
.setMaster("local")//启动本地化计算
.setAppName("testRdd")//设置本程序名称
//Spark程序的编写都是从SparkContext开始的
val sc=new SparkContext(conf)
//以上的语句等价与val sc=new SparkContext("local","testRdd")
val data=sc.textFile("e://hello.txt")//读取本地文件
data.flatMap(_.split(" "))//下划线是占位符,flatMap是对行操作的方法,对读入的数据进行分割
.map((_,1))//将每一项转换为key-value,数据是key,value是1
.reduceByKey(_+_)//将具有相同key的项相加合并成一个
.collect()//将分布式的RDD返回一个单机的scala array,在这个数组上运用scala的函数操作,并返回结果到驱动程序
.foreach(println)//循环打印
}
}
创建数据集hello.txt测试文档如下:

启动本地spark程序,然后输出结果,可以在控制台查看结果:

如果能正确的打印出结果,说明spark示例运行成功。
到这里,Intellij IDEA使用Maven构建spark开发环境已经完全结束,如果有疑问或者本文档有什么错误,请指出,不甚感激。
spark 远程调试
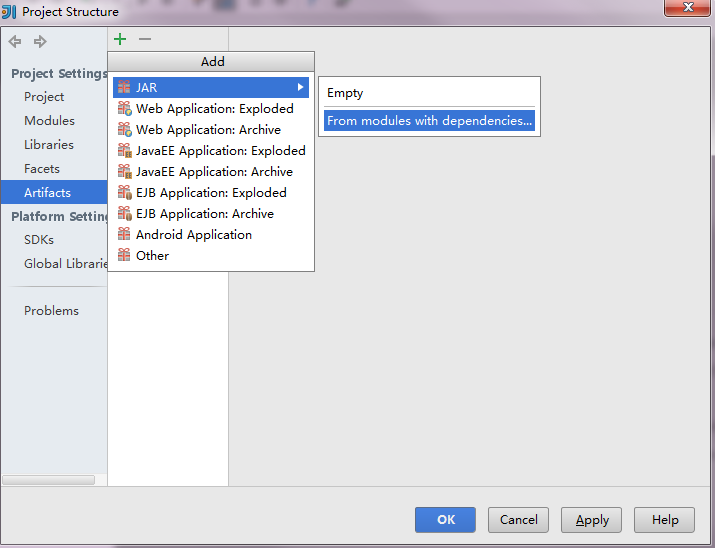
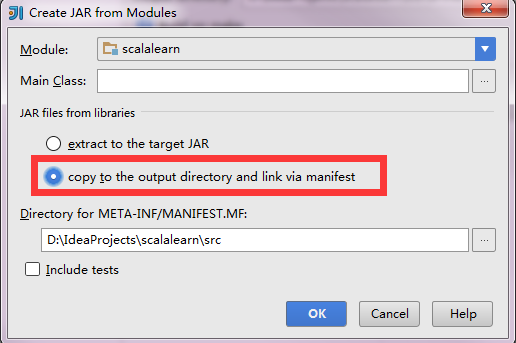
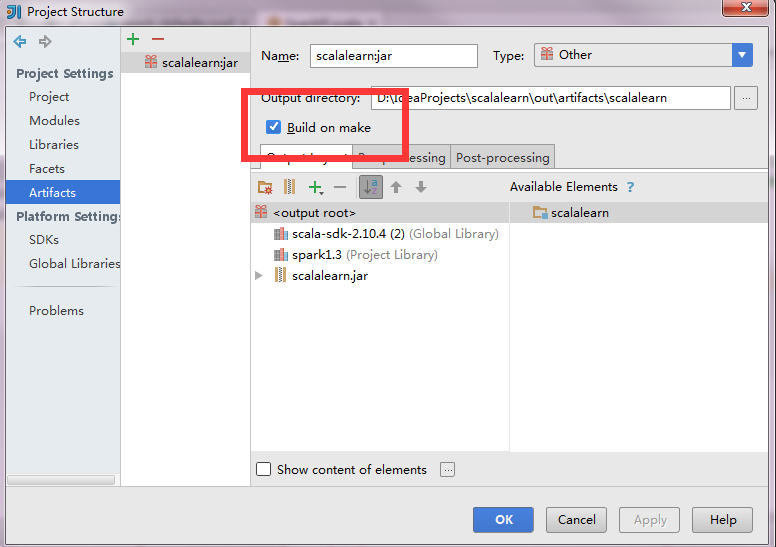
现在大功告成,设置Run 的Edit Configuration,点击+,Application,设置MainClass,点击OK!

点击Run即可运行程序了,程序会在刚才的路径生成对应的jar,然后会启动spark集群,去运行该jar文件
./hdfs dfs -chmod -R 755 /tmp
或者
在 hdfs-site.xml 总添加参数:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
改完后记得重启HDFS
null\bin\winutils.exe,这个错误很简单,是因为本win7压根就没装hadoop系统,解决办法是从集群上复制一份过来,放到F盘,并且配置好环境变量
HADOOP_HOME=F:\hadoop-2.6.0 Path=%HADOOP_HOME%\bin
接下来下载对应的版本的winutils放到 F:\hadoop-2.6.0\bin 文件夹下,应该就解决了
下载地址:https://github.com/steveloughran/winutils
问题如下:
java.lang.ClassNotFoundException: com.csu.basemods.Program
我的出错原因是:打包jar时,将本地的Spark、Scala等library也添加进了jar里,可能会导致jar默认使用jar包里的library。使得Spark集群的运行环境识别不到自己写的代码类,运行出错。
1.解决方法其实就是在打包jar时,去除集群环境中已有的library,如Spark、Scala等,只保留项目代码和其它自己额外添加的jar包,就可以了。
因为我们只是在Spark上运行的,所以我们要删除下图红框里多余的部分,保留WordCount.jar以及‘WordCount’ compile output。小提示,这里可以利用Ctrl+A全选功能,选中全部选项,然后,配合Crtl+鼠标左键进行反选,也就是按住Ctrl键的同时用鼠标左键分别点击WordCount.jar和‘WordCount’ compile output,从而不选中这两项,最后,点击页面中的删除按钮(是一个减号图标),这样就把其他选项都删除,只保留了WordCount.jar以及‘WordCount’ compile output。
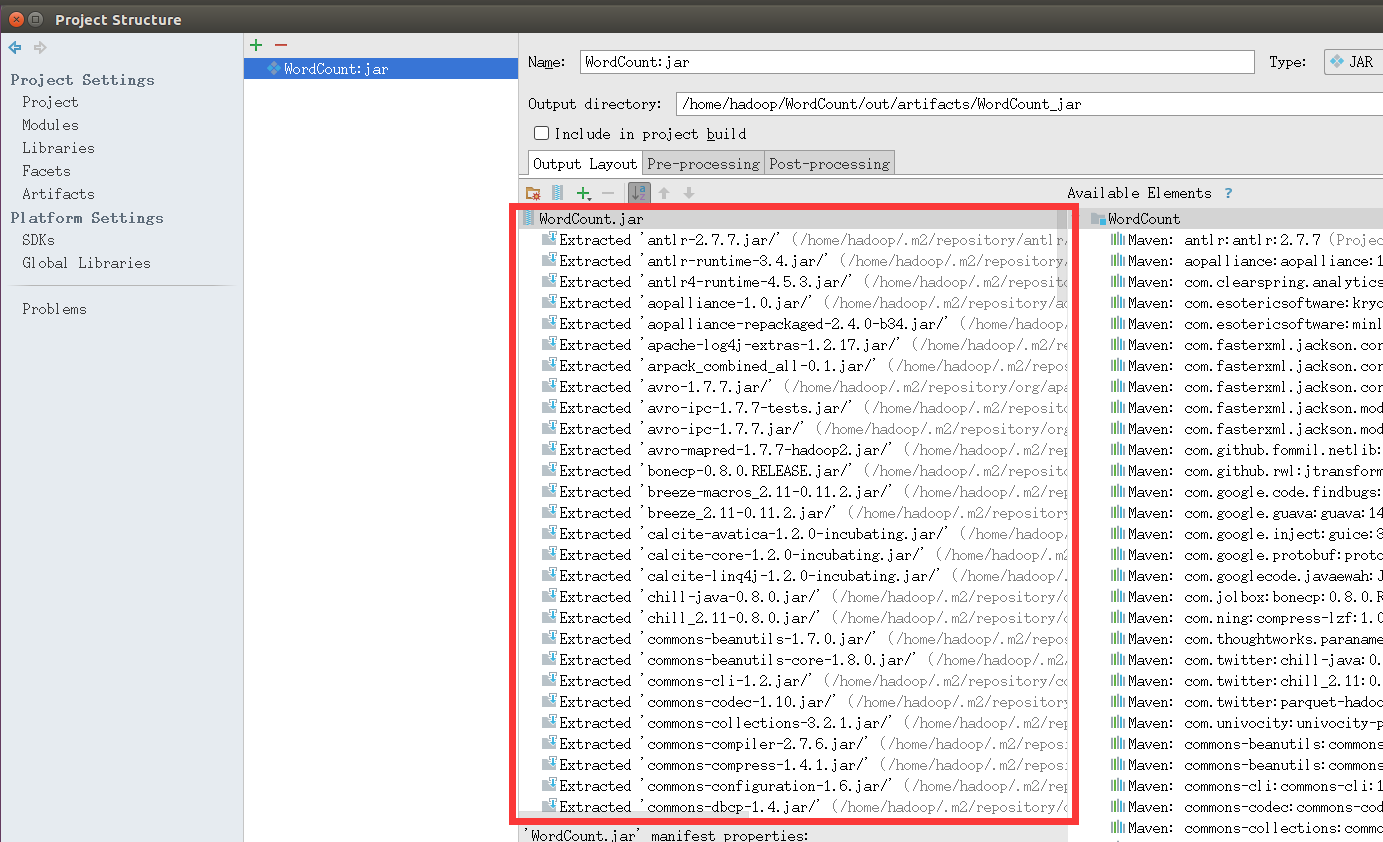
2.File=>Project Structure=>Modules 将该类所在的包设置为Sources
Intellij IDEA使用Maven搭建spark开发环境(scala)的更多相关文章
- PyCharm搭建Spark开发环境 + 第一个pyspark程序
一, PyCharm搭建Spark开发环境 Windows7, Java 1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop 2.7.6 通常情况下,Spark开发 ...
- Intellij Idea搭建Spark开发环境
在Spark高速入门指南 – Spark安装与基础使用中介绍了Spark的安装与配置.在那里还介绍了使用spark-submit提交应用.只是不能使用vim来开发Spark应用.放着IDE的方便不用. ...
- 大数据学习(25)—— 用IDEA搭建Spark开发环境
IDEA是一个优秀的Java IDE工具,它同样支持其他语言.Spark是用Scala语言编写的,用Scala开发Spark是最舒畅的.当然,Spark也提供Java和Python的API. Java ...
- Spark(八) -- 使用Intellij Idea搭建Spark开发环境
Intellij Idea下载地址: 官方下载 选择右下角的Community Edition版本下载安装即可 本文中使用的是windows系统 环境为: jdk1.6.0_45 scala2.10. ...
- spark学习10(win下利用Intellij IDEA搭建spark开发环境)
第一步:启动IntelliJ IDEA,选择Create New Project,然后选择Scala,点击下一步,输入项目名称wujiadong.spark继续下一步 第二步:导入spark-asse ...
- 服务器上搭建spark开发环境
1.安装相应的软件 (1)安装jdk 下载地址:http://www.Oracle.com/technetwork/java/javase/downloads/index.html (2)安装scal ...
- Maven搭建Hadoop开发环境
1.安装maven(用于管理仓库,jar包的管理) 1.解压maven安装包 2.把maven添加到环境变量/etc/profile 3.添加maven目录下的conf/setting.xml文件到- ...
- Mac上配置maven+eclipse+spark开发环境
1.安装jdk 2.下载scala-ide.官网:http://scala-ide.org 3.安装maven 4.在eclipse中,配置maven的安装了路径.偏好设置--->maven-- ...
- 【甘道夫】Eclipse+Maven搭建HBase开发环境及HBaseDAO代码演示样例
环境: Win764bit Eclipse Version: Kepler Service Release 1 java version "1.7.0_40" 第一步:Eclips ...
随机推荐
- Linux设置默认shell脚本效果
效果如图: 实现方法:在当前用户的家目录下新建文件.vimrc [root@nodchen-db01-test ~]# pwd/root [root@nodchen-db01-test ~]# fil ...
- centos-linux热拔插scsi硬盘
自己配置虚拟机,需要添加一块虚拟硬盘存放数据.虚拟机在更新软件,不想停机.学习了下热拔插硬盘的知识点 1. 在虚拟机中创建虚拟磁盘并添加. 2. 查看目前的磁盘信息cat /proc/scsi/scs ...
- JAVA的非对称加密算法RSA——加密和解密
原文转载至:https://www.cnblogs.com/OnlyCT/p/6586856.html 第一部分:RSA算法原理与加密解密 一.RSA加密过程简述 A和B进行加密通信时,B首先要生成一 ...
- Spring MVC 处理模型数据
SpringMVC 处理模型数据: 1 controller接收pojo: <form action="save" method="get"> &l ...
- python3调用C动态库
软硬件环境 OS X EI Capitan Python 3.5.1 GCC 4.9 前言 最近在做python3开发中,碰到了一个问题,需要通过调用C的一个动态链接库来获取相应的值.扒了扒网络,动手 ...
- uva-10047
我们考虑一个特殊情况,一个独轮车是一个圆环,独轮车靠这个圆环运动,这个圆环上涂有五个不同的颜色,如下图每个颜色段的圆心角是72度,这个圆环在MxN个方格的棋盘上运动,独轮车从棋盘中一个格子的中心点开始 ...
- UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position
python实现爬虫遇到编码问题: error:UnicodeEncodeError: 'gbk' codec can't encode character '\xXX' in position XX ...
- CUDA C Programming Guide 在线教程学习笔记 Part 2
▶ 纹理内存使用 ● 纹理内存使用有两套 API,称为 Object API 和 Reference API .纹理对象(texture object)在运行时被 Object API 创建,同时指定 ...
- PHP 程序员学数据结构与算法之《栈》
“要成高手,必练此功”. 要成为优秀的程序员,数据结构和算法是必修的内容.而现在的Web程序员使用传统算法和数据结构都比较少,因为很多算法都是包装好的,不用我们去操心具体的实现细节,如PHP的取栈 ...
- IIS ashx
win2008 IIS ashx http://127.0.0.1:801/testHandler.ashx 在服务器上用IE打开提示 HTTP 错误 404.17 - Not Found 请求的内容 ...