MySQL5.7 主从复制配置
一、主从复制原理
MySQL 主从复制是一个异步的复制过程,主库发送更新事件到从库,从库读取更新记录,并执行更新记录,使得从库的内容与主库保持一致。每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个 log dump 输出线程,每一个从库都有它自己的 I/O 线程和 SQL 线程。
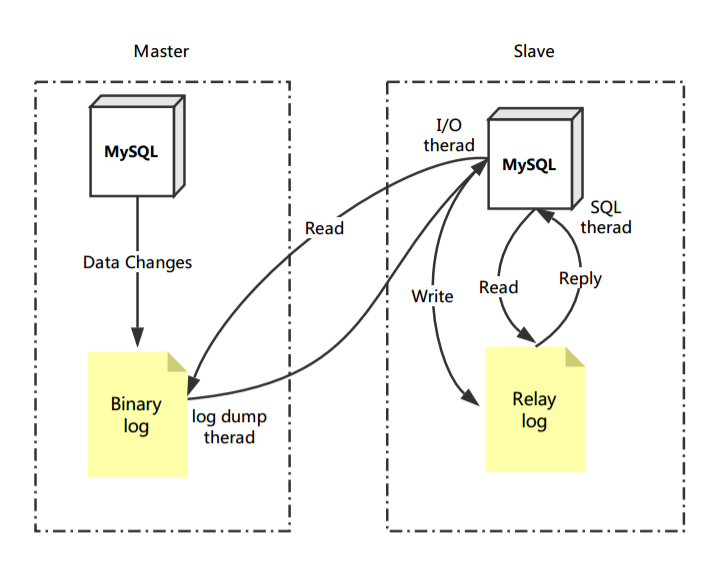
步骤:
1.主库会将所有的更新记录保存到 Binarylog 文件。
2.每当有从库连接到主库的时候,主库都会创建一个 log dump 线程发送 Binarylog 文件到从库。
3.当从库复制开始的时候,从库就会创建两个线程进行处理,一个 I/O 线程,一个 SQL 线程。
4.I/O 线程去请求主库的 Binarylog文件,并将得到的 Binarylog 文件写到 Relaylog 文件中。
5.SQL 线程会读取 Relaylog 文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致。
二、工具
VMware版本:12.0.0
Ubuntu版本:16.4
MySQL版本 :5.7.18
Master 服务器:192.168.128.1
Slave 服务器 :192.168.128.3
三、准备工作
1.安装 MySQL5.7 详见此处 ,我这里的配置是,master 是安装在本地windows环境下的mysql,slave是安装在虚拟机linux下的mysql
2.如果从服务器是克隆的主服务器,则修改 auto.cnf 文件中 server-uuid 值,不然后面主从复制会报 1593 错误,修改完记得重启MySQL

3.关闭主、从服务器防火墙:
root@ubuntu:/etc# ufw disable
4.修改主从配置文件(my.cnf):
## 192.168.128.1(master)
#打开日志
log_bin=mysql-bin
#这个id不要与从数据库id一样,改id一般取当前服务器ip地址最后一位
server_id=
binlog-do-db=cpa #要给从机同步的库
binlog-ignore-db=mysql #不要给从机同步的库
#自动清理1天前的log文件
expire_logs_days= ## 192.168.128.3(slave)
log_bin=mysql-bin
server_id=
重启主从 MySQL
注: server_id 必须唯一。
四、主从复制
1.master创建授权用户:192.168.128.1(master):
## 创建 test 用户,指定该用户只能在主库 192.168.128.3 上使用 MyPass1! 密码登录
mysql> create user 'test'@'192.168.128.3' identified by 'MyPass1!'; ## 为 test 用户赋予 REPLICATION SLAVE 权限。
mysql> grant replication slave on *.* to 'test'@'192.168.128.3'; ## 查看用户
mysql> select user,host from mysql.user; ## 查看 master 状态
mysql> show master status;
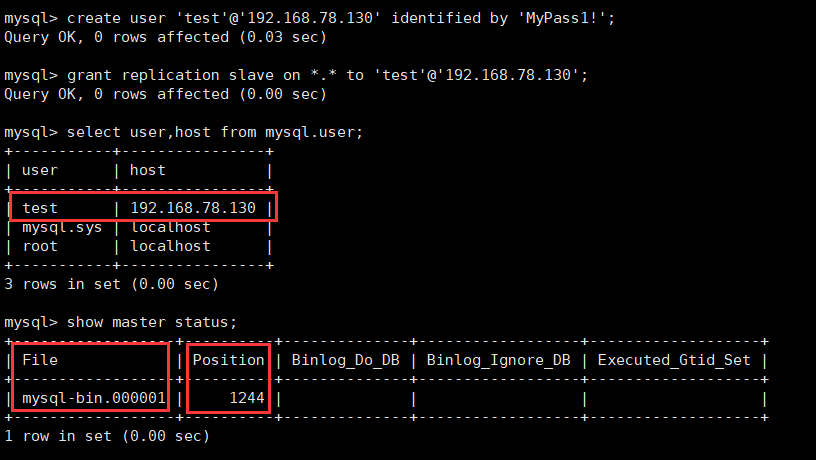
注:
这里的 mysql-bin.000001和 Position 值 slave 配置时需要用到。
2.将 master 中现有的数据信息导出:
$ mysqldump -u root -p --all-databases --master-data > all.sql
3.将 all.sql 发送到 slave 服务器 tmp 目录下:
$ scp all.sql root@192.168.78.130:/tmp
4.slave 导入 master 数据,使 master-slave 数据保持一致:
$ mysql -uroot -p < all.sql
注:2,3,4步主要作用是使主从数据库的数据保持一致,这里如果不会使用命令导出导入sql文件的话,可以借助工具实现,如Navicat
5.使 slave 与 master 建立连接,从而同步:
# 在slave上操作
mysql> change master to
-> master_host='192.168.128.1',
-> master_user='test',
-> master_password='MyPass1!',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=; mysql> start slave; mysql> show slave status \G

注:
master_log_file和master_log_pos值为主库上面执行show master status得到如果
Slave_IO_Running和Slave_SQL_Running都为Yes,说明配置成功如果其中一项不为
Yes,查看Last_IO_Errno错误码和错误信息,或者查看MySQL日志信息并查找对应问题
五、主从配置检验
master 插入一条数据,slave查看是否成功,
master 删除一条数据,slave查看是否成功,
六、监控主从同步状态
在从库机器上,执行 show slave status,查看Seconds_Behind_Master值,代表主从同步从库落后主库的时间,单位为秒,
若主从同步无延迟,这个值为0。Mysql主从延迟一个重要的原因之一是主从复制是单线程串行执行。 那如何为避免或解决主从延迟?我们做了如下一些优化: 优化Mysql参数,比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。 使用高性能CPU主机 数据库使用物理主机,避免使用虚拟云主机,提升IO性能 使用SSD磁盘,提升IO性能。SSD的随机IO性能约是SATA硬盘的10倍。 业务代码优化,将实时性要求高的某些操作,使用主库做读操作
七、主从配置恢复
今天测试的时候发现,主从之间不进行复制了,因为环境是window和虚拟机(中间肯定关机了);
然后在从数据库上使用命令:
mysql> start slave;
Query OK, rows affected, warning (0.02 sec)
启动后,发现还是不能同步数据
使用命令查看从数据库状态
mysql> show slave status \G;
发现其中的
Slave_IO_Running:No
之前也说了有两项参数十分重要,就包括这项参数,它的值为NO,肯定不能同步
经过一番折腾找到解决方法:
三个命令
mysql> start slave;
Query OK, rows affected, warning (0.02 sec) mysql> stop slave;
Query OK, rows affected (0.78 sec) mysql> reset slave;
Query OK, rows affected (0.68 sec) mysql> start slave;
Query OK, rows affected (0.70 sec)
再次查看状态,发现两项都为YES了,测试同步也正常,
当然这种解决方法,局限性肯定非常大,不过再遇到此类问题时,不妨先试试这种方法,如果可以解决那更好,不能解决在看mysql日志去解决

MySQL5.7 主从复制配置的更多相关文章
- centos 7 Mysql5.7 主从复制配置
1.环境 Centos 7 Mysql 5.7 Master 192.168.1.71 Slave01 192.168.1.72 2.分别配置master,slave01 # vi /etc/my. ...
- mysql5.7主从复制配置——读写分离实现
为什么使用主从架构?1.实现服务器负载均衡:2.通过复制实现数据的异地备份:3.提高数据库系统的可用性:4.可以分库[垂直拆分],分表[水平拆分]: 主从配置的前提条件1.MySQL版本一致:2.My ...
- MySQL5.7主从复制配置
1 my.cnf文件 配置 binlog_format = ROW log_bin_trust_function_creators=1 log-error = /usr/local/mysql/dat ...
- mysql5.7在windows下面的主从复制配置
目标:自动同步Master 服务器上面的Demo数据库到Slave 服务器的Demo数据库中. 对于一些操作系统比较强而使用频率又不高的东西,往往好久不去弄就忘记了,所以要经常记录起来,方便日后查阅. ...
- MySQL5.7 Replication主从复制配置教程
最近配置mysql5.7主从复制的时候碰到了些问题,老老实实按老版本的步骤配置会有错误,后来自己查看了官方文档,才解决了问题,在这里总结一下5.7的配置步骤, 大体步骤跟老版本的还是一样的,只是有一些 ...
- mysql5.7.26做主从复制配置
一.首先两台服务器安装好mysql数据库环境 参照linux rpm方式安装mysql5.1 https://www.cnblogs.com/sky-cheng/p/10564604.html 二.主 ...
- Docker安装mysql5.7并且配置主从复制
Docker安装mysql5.7并且配置主从复制 一.拉取mysql镜像 二.创建文件docker.cnf 2.1 mysql主机(192.168.21.55:3307) 2.1.1 创建文件夹 2. ...
- MySQL5.6主从复制最佳实践
MySQL5.6 主从复制的配置 环境 操作系统:CentOS-6.6-x86_64 MySQL 版本:mysql-5.6.26.tar.gz 主节点 IP:192.168.31.57 ...
- mysql5.7 主从复制的正常切换【转】
目前环境如下: master server IP:172.17.61.131 slave server IP:172.17.61.132 mysql version: mysql-5.7.21-lin ...
随机推荐
- 三羊献瑞|2015年蓝桥杯B组题解析第三题-fishers
三羊献瑞 观察下面的加法算式: 祥 瑞 生 辉 三 羊 献 瑞 三 羊 生 瑞 气 (如果有对齐问题,可以参看[图1.jpg]) 其中,相同的汉字代表相同的数字,不同的汉字代表不同的数字. 请你填写& ...
- 遍历GroupBox上的所有的textbox
foreach (Control c in groupBox1.Controls) { if (c is TextBox) { //这里写代码逻辑 } } 遍历的时候,需要用Control遍历: 如果 ...
- 【第十八章】 springboot + thymeleaf
代码结构: 1.ThymeleafController package com.xxx.firstboot.web; import org.springframework.stereotype.Con ...
- Codeforces Round #429 (Div. 2)
A. Generous Kefa One day Kefa found n baloons. For convenience, we denote color of i-th baloon as ...
- BZOJ 3555: [Ctsc2014]企鹅QQ
似乎大家全部都用的是hash?那我讲一个不用hash的做法吧. 首先考虑只有一位不同的是哪一位,那么这一位前面的位上的字符一定是全部相同,后面的字符也是全部相同.首先考虑后面的字符. 我们对n个串的反 ...
- [luogu2119]魔法阵 NOIP2016T4
很好的一道数学推导题 45分做法 $O(N^4)$暴力枚举四个材料 55分做法 从第一个约束条件可得到所有可行答案都是单调递增的,所以可以排序一遍,减少枚举量,可以拿到55分 100分做法 首先可以发 ...
- linq——group by
多列排序&&聚合函数 var result = from i in (from uh in db.UserHistories ...
- jq的attr()与prop()之间区别
1.attr() 一直存在,prop() 仅存在于 jq-1.6 及其之后 2.新版本jq使用细节: 2.1 自定义添加至dom节点的属性,用attr获取 2.2 表单类checked.selecte ...
- Linux中CentOS6.5 64位 系统下安装docker步骤
CentOS6.5 64位 (docker目前仅支持64位)内核必须在3.10及以上 1. uname -r 查看内核版本 2. 升级内核到3.10版本(带aufs模块) cd /etc ...
- 关于c#除法运算的问题
https://blog.csdn.net/yxt1522916229/article/details/51107569/ 下面的示例可以验证一下问题: 例如: int m = 2; ...