CUDA C Programming Guide 在线教程学习笔记 Part 1
▶ 编程接口。参考 http://chenrudan.github.io/
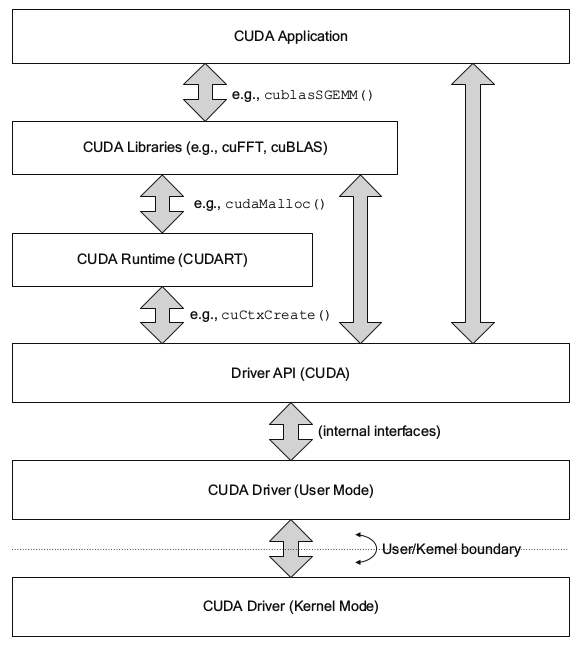
▶ Runtime API 为高层级管理接口,提供申请和释放设备内存,数据迁移,多 GPU 管理等。Driver API 为较低层级的控制接口,提供 CUDA 上下文(模拟设备主机进程),CUDA 模块(模拟设备动态加载库)等。软件层面 Runtime 比 Driver 封装的更好(Runtime 之上就是封装的更好的 cuFFT 等库)。这两个库的函数都是能直接调用的,Driver API 对底层硬件驱动的控制更直接、更方便,并且向后兼容支持老版本(Runtime 不行),运行速度上与 Runtime 差别不大。Driver API 的函数开头是 cu,而 Runtime API 的函数开头是 cuda,例如(选自《CUDA专家手册:GPU编程权威指南》)Runtime API 函数 cudaMalloc() 与 Driver API 函数 cuMemAlloc(),本质功能相同,其关系如下图所示。一般基于 Driver API 来写程序会比 Runtime API 要复杂。
▶ nvcc 编译时负责:主机代码与设备代码分离,编译设备代码,调整扩展主机代码,将主机代码交给其他编译器编译,链接 Runtime 函数,连接主机代码和设备二进制代码生成 PTX 或 .cubin,使用 Driver API,读取和执行 .cubin 代码 或PTX代码。
▶ 运行时编译(Just-in-Time Compilation,JIT)。是由设备驱动编译生成的,增加了程序的读取时间,但能更自由的加入编译器和设备驱动的新特性,这也是运行编译时不存在同一设备上的程序的唯一方法。
▶ nvcc 指定构架编译的 cubin 代码只能在同构架下向后兼容,不能向前兼容或跨构架兼容。如编译时使用选项 -code=sm_35 产生的代码只能被计算能力不低于 3.5,且不足 4.0 的设备运行。
▶ 设备驱动指定构架编译的 PTX 代码只能向后兼容,不能向前兼容。编译时使用选项 -arch=compute_30 产生的代码只能被计算能力不低于 3.0 的设备运行。
▶ nvcc 编译命令举例。指定生成同时兼容计算能力 3.5 和 5.0 的 cubin,以及计算能力 6.0 的 PTX 。
nvcc x.cu
-gencode arch=compute_35,code=sm_35
-gencode arch=compute_50,code=sm_50
-gencode arch=compute_60,code=\'compute_60,sm_60\'
▶ 使用宏 __CUDA_ARCH__ 来判断当前设备代码的计算能力。如用参数 -arch=compute_35 编译时,该宏等于 350 。
▶ CUDA 静态库为 cudart.lib 或 cudart.a ,动态库为 cudart.dll 或 cudart.so 。
▶ 线性设备内存支持 40 位的内存空间(1 TB)。
▶ 使用 cudaGetSymbolAddress() 和 cudaGetSymbolSize() 来获取有关常量内存的地址和尺寸。
//cuda_runtime_api.h
extern __host__ cudaError_t CUDARTAPI cudaGetSymbolAddress(void **devPtr, const void *symbol); extern __host__ cudaError_t CUDARTAPI cudaGetSymbolSize(size_t *size, const void *symbol);
● 示例代码:
#include <stdio.h>
#include <malloc.h>
#include <cuda_runtime_api.h>
#include "device_launch_parameters.h" __constant__ float constData[]; int main()
{
float *ptr;
size_t size; cudaGetSymbolAddress((void **)&ptr,constData);
cudaGetSymbolSize(&size, constData); printf("\n\t%u, %u\n", ptr, size);
getchar();
return ;
}
● 输出结果:
,
▶ 异构同步执行。
● CUDA中有五项任务是可以同步进行的:主机计算,设备计算,从主机到设备的内存拷贝,从设备到主机的内存拷贝,设备内部的内存拷贝,设备之间的内存拷贝
● 对主机来说设备上的五项任务是可以同步进行的:启用核函数,设备内部的内存拷贝,主机到设备的 64KB 以下的内存拷贝,Async 型的内存拷贝,内存管理类函数的调用。
● 可以通过设定环境值 CUDA_LAUNCH_BLOCKING = 1(没找到定义在那里?)来禁用同步计算(仅用于调试,否则大幅降低程序效率)。
● 使用程序分析器(XX Profiler)时核函数取消同步执行,涉及页锁定内存的拷贝时取消同步执行。
● 拥有不同上下文的两个核函数不能同步执行。
● 使用编译选项 --default-stream per-thread 或者在一包括 cuda 头文件之前定义宏 CUDA_API_PER_THREAD_DEFAULT_STREAM 可以使得主机每一条线程都有各自独立的默认流。
● 使用编译选项 --default-stream legacy 使得每一个设备都有一条称为 NULL stream 的默认流。
● 各种同步函数
■ cudaDeviceSynchronize() ,等待所有流中的任务都结束。
■ cudaStreamSynchronize(); ,等待指定流中的任务全部完成,同时允许其他流中的任务继续运行。
■ cudaStreamWaitEvent(); ,等待指定的流中指定的事件完成。给定流编号可以是0,使得所有流都等待给定的事件完成。
■ cudaStreamQuery(); ,判断给定的流中是否所有任务都已经完成。
▶ 当主机线程在流中使用以下操作时,不同的流之间不能并行执行(发生隐式同步):页锁定内存申请,设备内存申请,设备内存拷贝,设备内部内存拷贝,对 NULL 流的 CUDA 命令,L1 缓存与共享内存交换。
▶ (?) For devices that support concurrent kernel execution and are of compute capability 3.0 or lower, any operation that requires a dependency check to see if a streamed kernel launch is complete: Can start executing only when all thread blocks of all prior kernel launches from any stream in the CUDA context have started executing; Blocks all later kernel launches from any stream in the CUDA context until the kernel launch being checked is complete.
▶ 当流中核函数开始执行且该流中调用了 cudaStreamQuery() 函数时,流中任何其他操作都会要求依赖性检查。所以,为了提升程序的潜在并行执行效率,程序应该遵循两条规则:有依赖性的操作应该放到独立操作之后,尽量延迟使用任何种类的同步
▶ 操作重叠。对比了两种异步并行模式。
// 第一种,两部分任务执行顺序不能重叠(第 1 任务的 HostToDevice 不能发生在第 0 任务的 DeviceToHost 之前)
for (int i = ; i < ; ++i)
{
cudaMemcpyAsync(d_in + i * size, h_data + i * size, size, cudaMemcpyHostToDevice, stream[i]);
MyKernel << < >> > (d_out + i * size, d_in + i * size, size);
cudaMemcpyAsync(h_data + i * size, d_out + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
} // 第二种,两部分任务执行顺序可以重叠
for (int i = ; i < ; ++i)
cudaMemcpyAsync(d_in + i * size, h_data + i * size, size, cudaMemcpyHostToDevice, stream[i]);
for (int i = ; i < ; ++i)
MyKernel << < >> > (d_out + i * size, d_in + i * size, size);
for (int i = ; i < ; ++i)
cudaMemcpyAsync(h_data + i * size, d_out + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
▶ 回调函数中尽量不使用 CUDA API 函数,否则可能陷入 API -> callback -> API -> callback 的死循环中。
▶ 流的优先级。优先级较高的流中的任务会被优先调度。
// driver_types.h
#define cudaStreamDefault 0x00 // 默认流标志
#define cudaStreamNonBlocking 0x01 // 不与 NULL 流同步标志 // cuda_runtimt_api.h
extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaStreamCreateWithPriority(cudaStream_t *pStream, unsigned int flags, int priority);
extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority); // 使用方法
int priority_high, priority_low;
cudaStream_t st_high, st_low; cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high);
cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);
▶ (?)调用同步函数时,控制权转交主机线程,通过先前定义的 cudaSetDeviceFlags(); 来决定主机线程是否要抛弃、阻塞还是旋转处理。
▶ 流不能跨设备执行。选定设备 cudaSetDevice(); 以后(单设备情况下不用指定)创建的流默认在该设备上运行。需要创建在另一台设备上的流时,应该重新选定设备然后再创建。流中任务可以跨设备,例如可以在一台设备的流中指定发生在另一台设备上内存拷贝操作。每台设备都有自身的 NULL 流,各台设备的 NULL 可以并行执行。
▶ 与流和时间相关的函数性质。
● 当指定的流和时事件不在同一台设备上时 cudaEventRecord() 运行失败;但 cudaStreamWaitEvent() 仍可以运行成功,可以用于多设备之间的同步。
● 当指定两个事件不在同一台设备上时 cudaEventElapsedTime() 运行失败
● 当指定两个事件在同一台设备上(就算不是当前选定的设备)时, cudaEventSynchronize() 和 cudaEventQuery() 仍可以运行成功。
▶ 设备间通讯,两台设备之间可以直接进行内存访问。
// cuda_runtime_api.h
extern __host__ cudaError_t CUDARTAPI cudaDeviceCanAccessPeer(int *canAccessPeer, int device, int peerDevice);
extern __host__ cudaError_t CUDARTAPI cudaDeviceEnablePeerAccess(int peerDevice, unsigned int flags);
extern __host__ cudaError_t CUDARTAPI cudaDeviceDisablePeerAccess(int peerDevice); // 使用方法
{
cudaSetDevice(); // 正常使用 0 号设备
float* p0;
cudaMalloc(&p0, sizeof(float)*);
myKernel <<< , >>>(p0); cudaSetDevice(); // 选择 1 号设备 cudaDeviceEnablePeerAccess(, ); // 允许 0 号设备的 P2P 通讯 myKernel <<< , >>>(p0); // 可以在 1号设备上直接使用 0 号设备的内存进行运算 cudaDeviceDisablePeerAccess(); // 禁用 0 号设备的 P2P 通讯
}
● 设备之间的内存拷贝不能使用 cudaMemcpy(),而应该使用配套的 cudaMemcpyPeer(),cudaMemcpyPeerAsync(),cudaMemcpy3DPeer(),cudaMemcpy3DPeerAsync() 等
● 使用 NULL 流在两台设备之间进行内存拷贝时,会要求两设备先前任务全部执行完毕,且在拷贝完成以前不会继续执行后面的任务。
● 不同流的任务重叠性质在两台设备之间进行异步内存拷贝时也可以存在。
● 设备间内存拷贝可以不通过主机内存作为中介,运行速度较快。
// driver_types.h
struct __device_builtin__ cudaMemcpy3DPeerParms// 相对 cudaMemcpy3DParms 结构仅少了拷贝类型变量 enum cudaMemcpyKind kind;
{
cudaArray_t srcArray;
struct cudaPos srcPos;
struct cudaPitchedPtr srcPtr;
int srcDevice; cudaArray_t dstArray;
struct cudaPos dstPos;
struct cudaPitchedPtr dstPtr;
int dstDevice; struct cudaExtent extent;
}; // cuda_runtime_api.h
extern __host__ cudaError_t CUDARTAPI cudaMemcpyPeer(void *dst, int dstDevice, const void *src, int srcDevice, size_t count);
extern __host__ cudaError_t CUDARTAPI cudaMemcpyPeerAsync(void *dst, int dstDevice, const void *src, int srcDevice, size_t count, cudaStream_t stream __dv());
extern __host__ cudaError_t CUDARTAPI cudaMemcpy3DPeer(const struct cudaMemcpy3DPeerParms *p);
extern __host__ cudaError_t CUDARTAPI cudaMemcpy3DPeerAsync(const struct cudaMemcpy3DPeerParms *p, cudaStream_t stream __dv());
▶ 进程通讯。主机创建的设备指针和事件句柄可以被同一进程内的所有线程共享,但对于其他进程中的线程来说是无效的。可以使用进程通讯接口(Inter Process Communication API, IPC API)来共享指针和句柄信息,目前只在Linux系统上支持。可以使用 cudaIpcGetMemHandle() 来将句柄传递给另一个进程,使用 cudaIpcOpenMemHandle() 来检索给定的句柄下的设备指针。该通讯通常用于主进程任务发布和其他进程的任务执行。
▶ 错误信息检查。
● 一般 cuda 函数都会返回错误代码,使用 cudaGetLastError() 可以捕获错误代码,并将错误信息重置为 cudaSuccess 。
● 异步函数报错比较特殊,因为它执行完毕的时刻不固定(相对于完整的核函数调用或是 runtime 函数调用),需要使用额外、独立的 runtime 函数来检查和报告错误。 cudaDeviceSynchronize() 或其他同步函数可以用于检查异步函数错误。
● 调用核函数不会返回错误代码,需要在调用之后立即使用 cudaGetLastError() 或 cudaPeekAtLastError() 来检查是否存在错误。前者将系统的全局错误信息变量重置为 cudaSucces,后者不会变更。
// 错误相关函数,cuda_runtime_api.h
extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaGetLastError(void);
extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaPeekAtLastError(void);
extern __host__ __cudart_builtin__ const char* CUDARTAPI cudaGetErrorName(cudaError_t error);
extern __host__ __cudart_builtin__ const char* CUDARTAPI cudaGetErrorString(cudaError_t error); // 使用方法举例
cudaError_t error;
error = cudaGetLastError(); // 获取错误并将系统全局错误信息重置为 cudaSucces
// error = cudaPeekAtLastError(); // 获取错误,不变更全局错误信息
printf("%s", cudaGetErrorName(error)); // 仅报告错误名称
printf("%s", cudaGetErrorString(error));// 报告错误名称和所在函数
▶ 堆栈调用。使用 cudaDeviceGetLimit() 和 cudaDeviceSetLimit() 来设定设备的堆栈大小,当堆栈溢出时会抛出栈溢错误或核函数运行失败。
// cuda_runtime_api.h
extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaDeviceGetLimit(size_t *pValue, enum cudaLimit limit);
extern __host__ cudaError_t CUDARTAPI cudaDeviceSetLimit(enum cudaLimit limit, size_t value);
CUDA C Programming Guide 在线教程学习笔记 Part 1的更多相关文章
- CUDA C Programming Guide 在线教程学习笔记 Part 5
附录 A,CUDA计算设备 附录 B,C语言扩展 ▶ 函数的标识符 ● __device__,__global__ 和 __host__ ● 宏 __CUDA_ARCH__ 可用于区分代码的运行位置. ...
- CUDA C Programming Guide 在线教程学习笔记 Part 4
▶ 图形互操作性,OpenGL 与 Direct3D 相关.(没学过,等待填坑) ▶ 版本号与计算能力 ● 计算能力(Compute Capability)表征了硬件规格,CUDA版本号表征了驱动接口 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 2
▶ 纹理内存使用 ● 纹理内存使用有两套 API,称为 Object API 和 Reference API .纹理对象(texture object)在运行时被 Object API 创建,同时指定 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 10【坑】
▶ 动态并行. ● 动态并行直接从 GPU 上创建工作,可以减少主机和设备间数据传输,在设备线程中调整配置.有数据依赖的并行工作可以在内核运行时生成,并利用 GPU 的硬件调度和负载均衡.动态并行要求 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 13
▶ 纹理内存访问补充(见纹理内存博客 http://www.cnblogs.com/cuancuancuanhao/p/7809713.html) ▶ 计算能力 ● 不同计算能力的硬件对计算特性的支持 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 9
▶ 协作组,要求 cuda ≥ 9.0,一个简单的例子见 http://www.cnblogs.com/cuancuancuanhao/p/7881093.html ● 灵活调节需要进行通讯的线程组合 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 8
▶ 线程束表决函数(Warp Vote Functions) ● 用于同一线程束内各线程通信和计算规约指标. // device_functions.h,cc < 9.0 __DEVICE_FU ...
- CUDA C Programming Guide 在线教程学习笔记 Part 7
▶ 可缓存只读操作(Read-Only Data Cache Load Function),定义在 sm_32_intrinsics.hpp 中.从地址 adress 读取类型为 T 的函数返回,T ...
- CUDA C Programming Guide 在线教程学习笔记 Part 3
▶ 表面内存使用 ● 创建 cuda 数组时使用标志 cudaArraySurfaceLoadStore 来创建表面内存,可以用表面对象(surface object)或表面引用(surface re ...
随机推荐
- ASP.NET MVC开发基础
一.ASP.Net MVC的开发模式 (1)处理流程 在ASP.Net MVC中,客户端所请求的URL是被映射到相应的Controller去,然后由Controller来处理业务逻辑,或许要从Mode ...
- rabbitmq学习(五):springboot整合rabbitmq
一.Springboot对rabbitmq的支持 springboot提供了对rabbitmq的支持,并且大大简化了rabbitmq的相关配置.在springboot中,框架帮我们将不同的交换机划分出 ...
- 【vue】Mac上安装Node和NPM
http://bubkoo.com/2017/01/08/quick-tip-multiple-versions-node-nvm/ 作为前端开发者,node和npm安装必不可少.然而有时会因为安装新 ...
- java反射+java泛型,封装BaseDaoUtil类。供应多个不同Dao使用
当项目是ssh框架时,每一个Action会对应一个Service和一个Dao.但是所有的Ation对应的Dao中的方法是相同的,只是要查的表不一样.由于封装的思想,为了提高代码的重用性.可以使用jav ...
- test20181015 B君的第二题
题意 分析 考场85分 用multiset暴力,由于教练的机子飞快,有写priority_queue水过了的人. #include<cstdlib> #include<cstdio& ...
- 关联容器map(红黑树,key/value),以及所有的STL容器详解
字符串或串(String)是由数字.字母.下划线组成的一串字符.一般记为 s=“a1a2···an”(n>=0).它是编程语言中表示文本的数据类型.在程序设计中,字符串(string)为符号或数 ...
- linux和mac使用virtualenv使用和安装
virtualenv是python的三大神器之一,用于创建独立的python虚拟环境,多个python版本相互独立,互不影响,可以在一台电 脑上同时安装多个版本的python,而且不影响本机pytho ...
- FastAdmin composer json 版本说明
来源于 FastAdmin 执行 composer update 后将 ThinkPHP 升级到了 V5.1. FastAdmin 是基于 ThinkPHP 5.0.x 开发的,而 ThinkPHP ...
- protobuf生成
1,文件路径匹配好在src/main/proto下面 https://blog.csdn.net/u010939285/article/details/78538927
- Angular 4 父组件调用子组件中的方法
1. 创建工程 ng new demo3 2. 创建子组件 ng g component child 3. 在子组件中定义方法greeting 4. 父组件html(第三行是模板中调用子组件的方法) ...